CIKM-2016-DRMM-A Deep Relevance Matching Model for Ad-hoc Retrieval
A Deep Relevance Matching Model for Ad-hoc Retrieval
DRMM by Jiafeng Guo, Yixing Fan, Qingyao Ai and W.Bruce Croft for CIKM2016
文章目录
- A Deep Relevance Matching Model for Ad-hoc Retrieval
- 摘要(Abstract)
- 1.概述(Introduction)
- Machine learning for IR
- Deep learning for IR
- deep models for ad-hoc retrieval
- 2.Ad-hoc检索作为一个匹配问题
- Ad-hoc retrieval ——(formalize)—— > text matching problem
- 两类深度匹配模型
- 以表示为中心的模型(representation-focused model)
- 以交互为中心的模型(representation-focused model)
- 存在的问题
- 提出的问题
- 3.语义匹配 VS. 相关性匹配
- 4.本文的模型架构DRMM
- 模型架构
- 形式化描述
- 本文采用的词嵌入
- 三个组成部分
- 实验效果
- 主要贡献
- 5.总结
摘要(Abstract)
-
关键词:相关性匹配,语义匹配,神经模型,Ad-hoc检索,排序模型
-
背景:DNN在语音识别、计算机视觉和NLP任务中取得了极大的突破,但是在ad-hoc检索任务并没有取得多少积极的结果。
-
关键:在ad-hoc检索任务和NLP匹配任务中有根本上的不同,在于ad-hoc检索任务主要是关于相关性匹配(relevance matching),而NLP匹配任务更多地是考虑语义匹配(semantic matching)。
一个好的相关性匹配需要正确处理精确匹配信号,查询项重要性和多种多样的匹配需求。
-
本文研究工作:
- 提出深度相关匹配模型(Deep Relevance Matching Model, DRMM)
- 主要组成部分:匹配直方图映射(matching histogram mapping), 前馈匹配网络(feed forward matching network)以及词项门控网络( term gating network),以解决以上上个问题。
-
数据集及表现:
TREC——Robust04 和ClueWeb-09-Cat-B,与传统的检索模型和state-of-the-art深度匹配模型相比,很有竞争力。
1.概述(Introduction)
应用于信息检索的方法:Machine learning methods -> Deep learning models
Machine learning for IR
近年来,机器学习方法已成功应用于信息检索(IR)。通常排序函数(ranking function)可以基于一系列人为定义的特征,对于一个给定的查询和文档对给出相关性分数。然而手工设置的特征存在有以下几个缺点:
- 耗时(time-consuming)
- 不完整(incomplete)
- 过于精确(over-specified)
Deep learning for IR
而另一方面,深度神经网络,作为一个表示学习(representation learning)工具,有能力从训练数据的隐藏结构和抽象的不同层级的特征中发现对任务有用的特征。深度学习目前已经被成功应用于语音设别(speech recognition,2011),计算机视觉(computer vision,2013)以及自然语言处理(Natural Language Processing,NLP,2015),并且已经产生了显着的性能改进。鉴于这些领域深度学习的成功,深度学习似乎应该对IR产生重大影响。然而,到目前为止,关于IR任务的深度模型,特别是ad-hoc 检索任务的积极结果很少。
deep models for ad-hoc retrieval
当将深度模型应用于ad-hoc检索时,检索任务一般会被形式化为两段文本(也就是查询query和文档document)的匹配问题。这种匹配问题通常被认为是通用的,因为它既可以涵盖ad-hoc检索任务,也可以涵盖许多NLP任务,如释义识别(paraphrase identification),问答(question answering,QA)和自动对话(automatic conversation)。
2.Ad-hoc检索作为一个匹配问题
Ad-hoc retrieval ——(formalize)—— > text matching problem
Ad-hoc检索的核心问题是对于一个给定的查询,计算文档的相关性,因此可以被形式化为一个文本匹配问题如下。给定两个文本 T 1 T_{1} T1和 T 2 T_{2} T2 ,衡量它们的相似度得分可以由一个打评分函数(scoring function)基于每个文本的表示计算得分:
m a t c h ( T 1 , T 2 ) = F ( ϕ ( T 1 , ϕ ( T 2 ) ) ) match(T_{1},T_{2})=F(\phi(T_{1},\phi(T_{2}))) match(T1,T2)=F(ϕ(T1,ϕ(T2)))
其中, ϕ \phi ϕ是一个函数,用于将每一个文本映射至一个表示向量;
F F F是一个评分函数,基于两个文本之间的交互
这样一个文本匹配问题通常会被当作NLP任务的描述来考虑,大量深度匹配模型的提出要么是针对具体的ad-hoc检索任务或者是为了通用匹配问题。
两类深度匹配模型
已经有多种多样的深度匹配模型被提出,用于解决这个匹配问题,根据它们的模型结构(也就是对以上两种函数的选择),现由的深度匹配模型可以分为以下两类:
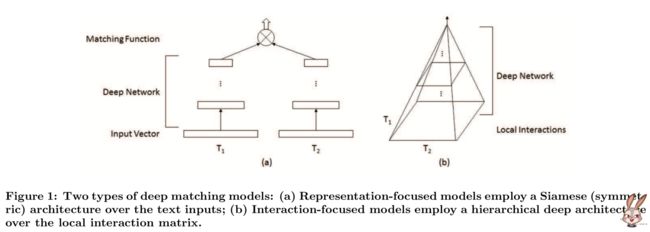
以表示为中心的模型(representation-focused model)
用深度神经网络为单个文本建立一个好的表示,然后在文本的组合和抽象文本表示之间进行匹配。如:DSSM, C-DSSM 和 ARC-I。
-
两种函数的选择
在该方法中, ϕ \phi ϕ是一个复杂表示的映射函数,而 F F F是一个相对简单的匹配函数。
-
具体模型案例
model ϕ \phi ϕ F F F DSSM 前馈神经网络 余弦相似度函数 C-DSSM 卷积神经网络(CNN) 余弦相似度函数 ARC-I 卷积神经网络(CNN) 多层感知机(MLP)
以交互为中心的模型(representation-focused model)
首先在两段文本之间建立本地交互(local interactions),也就是本地匹配信号(local matching signals)。然后用深度神经网络去学习匹配的分层交互模式(hierarchical interaction patterns) .如DeepMatch, ARC-II 和 MatchPyramid。
-
两种函数的选择
在该方法中, ϕ \phi ϕ是一个简单的映射函数,而 F F F是一个复杂的深度模型。
-
具体模型案例
model ϕ \phi ϕ F F F DeepMatch 将文本映射为词序列的简单映射函数 前馈神经网络 ARC-II 简单映射函数 卷积神经网络(CNN) MatchPyramid 简单映射函数 卷积神经网络(CNN)
存在的问题
尽管在这样的一般匹配问题形式化下已经提出了各种深度匹配模型,但是大多数模型仅被证明对一系列NLP任务有效,在ad-hoc检索方面有积极作用的很少。甚至是专门为Web搜索设计的深度模型(如DSSM和C-DSSM),也仅仅能够在<查询,文档标题>对上进行评估,这些不是典型的ad-hoc检索设置。如果我们直接将这些深度匹配模型应用于某些基准检索集合,如TREC语料库集合中,我们会发现性能不如传统的排序模型如语言模型和BM25。
提出的问题
基于以上观察,我们可以提出一些问题如下:
- 在ad-hoc中的匹配事都真的和NLP任务中的匹配完全一样?
- 现存的深度匹配模型是否适合于ad-hoc检索任务?
3.语义匹配 VS. 相关性匹配
很多NLP任务和ad-hoc检索任务的匹配问题从根本上是不同的!
- Matching in NLP tasks
大多数NLP任务关注于语义匹配,即识别语义和推断两段文本之间的语义关系
- Matching in ad-hoc retrieval tasks
而ad-hoc检索任务主要是关于相关性匹配,即识别文档是否与给定查询相关。
-
语义匹配(Semantic Matching)
在这些语义匹配任务中,两个文本通常是同质的并且有很少的自然语言句子组成,如问答句子或对话。为了推断自然语言句子之间的语义关系,语义匹配强调以下3个因素:
- Similarity matching signals:不同的项表达着相似的意思或者具有推断关系等相关的意思。
- Compositional meanings:更关注语法结构而非词的集合/词的序列,同时明确的语法结构对该NLP任务至关重要。
- Global matching requirement:考虑文本的整体信息。
-
相关性匹配(Relevance Matching)
在相关性匹配任务中,查询文本通常很短并且基于关键词,而文档的长度是变化的,从几十个词到上千上万个词。为了检验查询和文档之间的相关性,相关性匹配主要关注于以下三个:
- Exact matching sigals:尽管词项的错误匹配在ad-hoc检索中是一个重要问题,并且已经用不同的语义相似度信号来处理。但由于现代搜索引擎中的索引和搜索范例,文档和查询中的精确匹配项仍然是最重要的信号。先前的研究表明原始查询项匹配的相关性得分总是不低于多次对语义相关的项进行匹配。这也解释了为什么一些传统的检索模型,例如BM25,可以完全基于精确匹配信号很好地工作。
- Query term importance:在Ad-hoc检索中,通常比较短的query没有复杂的语法结构,主要包括一些关键词。所以query的term的重要性值得考虑。
- Diverse matching requirement:Verbosity Hypothesis认为长文档和短文档类似,也包括一个相似的范围;Scope Hypothesis认为长文档是不相关的短文档的集合,所以文章不一定要整个与query相关。
4.本文的模型架构DRMM
模型架构
本文提出一种深度相关匹配模型(deep relevance matching model,DRMM),它是一个以交互为中心的模型,为了实现相关性匹配在查询项级别部署了一个联结深度架构(joint deep architecture)。
具体来说,我们首先在查询和基于词项嵌入的文档中的每一对词项之间构建本地交互。对于每一个查询项,我们将可变长度的本地交互(variable-length local interactions)映射至固定长度的匹配直方图(fixed-length matching histogram)。基于这个固定长度的匹配直方图,我们部署一个前馈匹配网络来学习分层匹配模式并产生一个匹配分数。最后,整体匹配分数由每一个查询项和词项门控网络计算得到总权重进行聚合得到。模型架构如下图所示:

形式化描述
假设查询和文档都被表示成一系列词项向量的集合,标注如下:
查询项向量的集合 q = { w 1 ( q ) , … , w M ( q ) } q=\{w_{1}^{(q)},…,w_{M}^{(q)}\} q={w1(q),…,wM(q)} ,每一个查询项向量 w i ( q ) , i = 1 , … , M w_{i}^{(q)},i=1,…,M wi(q),i=1,…,M
文档项向量的集合 d = { w 1 ( d ) , … , w N ( d ) } d=\{w_{1}^{(d)},…,w_{N}^{(d)}\} d={w1(d),…,wN(d)} ,每一个文档项向量 w j ( d ) , j = 1 , … , N w_{j}^{(d)},j=1,…,N wj(d),j=1,…,N
我们用 s s s表示最终的相关性得分,有:
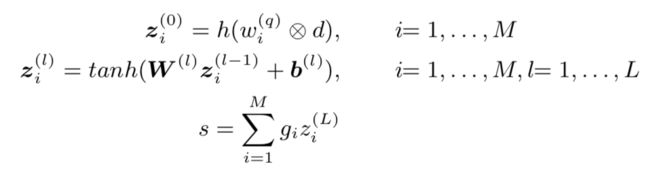
其中, ⨂ \bigotimes ⨂表示一个查询项和文档项之间的交互操作
h h h表示从本地交互到匹配直方图的映射函数
z i ( l ) , l = 0 , … , L z_{i}^{(l)},l=0,…,L zi(l),l=0,…,L 表示对于第 i i i个查询项中间的隐藏层
g i , i = 1 , … , M g_{i},i=1,…,M gi,i=1,…,M 表示由词项门控网络产生的聚合权重
W ( l ) W^{(l)} W(l)表示第 l l l个权重矩阵,而 b ( l ) b^{(l)} b(l)表示第 l l l个偏置项
它们在不同的额查询项之间交叉共享。注意,我们采用余弦相似度作为查询和文档中每对术语向量之间的交互操作符。
本文采用的词嵌入
本文假设术语向量是使用现有的神经嵌入模型(如Word2Vec)先验学习的。本文在深度相关性匹配模型中没有学习词向量,原因如下:1)可以从大规模的未标记文本集合中获取可靠的词项表示,而不是从有限的真实数据中进行ad-hoc检索; 2)通过使用先验学习的词项向量,我们可以将模型的学习集中在相关性匹配模式上,并且可以大大降低模型的复杂性。
三个组成部分
-
本文的主要模型设计包括:
- 匹配直方图映射(matching histogram mapping)
- 一个前馈匹配网络(a feed forward matching network)
- 一个词项门控网络(a term gating network)
解决了ad-hoc检索中相关性匹配的三个关键问题。
实验效果
我们基于两个代表性的ad-hoc检索基准集合(benchmark collections)来评估所提出的DRMM的有效性。为了进行比较,我们考虑了一些众所周知的传统检索模型,以及几种最先进的深度匹配模型,这些模型是为一般匹配问题而设计的,或者是专门为特殊检索任务而提出的。实证结果表明,现有的深度匹配模型无法与这些基准集合中的传统检索模型竞争,而我们的模型在所有评估指标方面可以显着优于所有基线模型。
主要贡献
-
指出了语义匹配和相关性匹配之间的三个主要不同,导致了深度匹配模型的架构设计显著不同。
-
本文通过明确解决相关性匹配的三个关键因素,提出了一种用于临ad-hoc检索的新的深度相关匹配模型。
-
本文对基准集合中最先进的检索模型进行了严格的比较,并分析了现有深度匹配模型的缺陷和DRMM的优势。
5.总结
该论文是在Interaction-focused模型基础之上进行修改,得到一个新的网络模型DRMM。之前基于Interaction-focused的模型保留了位置信息,比如ARC-II中生成的交互矩阵,然后在此之上构建前向网络。但是在实际情况中,query中的词和文档中的词不具有位置上的对应关系。基于此,该文提出的DRMM是基于值的大小对matrix中的单元重新分类(即该文中所提到的直方图)。
该文首先用query中的每个单词和文档的每个单词构建成为一个词对(word pair),再基于词向量,将一个词对映射到一个局部交互空间(local interactions,该文用了余弦相似度)。然后将每一个局部交互空间映射到长度固定的匹配直方图中。引用文中的例子,将相似度[-1, 1]分为五个区间{[-1,-0.5), [-0.5,-0), [0,0.5), [0.5,1), [1,1]} 。给定query中的一个词“car”以及一篇文档(car, rent, truck, bump, injunction, runway), 得到对应的局部交互空间为(1, 0.2, 0.7, 0.3, -0.1, 0.1),最后我们用基于计数的直方图方法得到的直方图为[0,1, 3, 1, 1]。对于每一个query的词得到一个直方图分布后,在此之上构建一个前向匹配网络并且产生query和文档的匹配分值,最后在将query中所有词合并的时候加入gating参数(比较类似于attention机制)。