维特比 decode 算法 - 矩阵计算
def viterbi_decode(self, text):
"""
:param text: 一段文本string
:return: 最可能的隐状态路径
"""
# 得到序列长度
seq_len = len(text)
# 初始化T1和T2表格
T1_table = np.zeros([seq_len, self.tag_size])
T2_table = np.zeros([seq_len, self.tag_size])
# 得到第1时刻的发射概率
start_p_Obs_State = self.get_p_Obs_State(text[0])
# 计算第一步初始概率, 填入表中
T1_table[0, :] = self.pi + start_p_Obs_State
T2_table[0, :] = np.nan
for i in range(1, seq_len):
# 维特比算法在每一时刻计算落到每一个隐状态的最大概率和路径
# 并把他们暂存起来
p_Obs_State = self.get_p_Obs_State(text[i])
p_Obs_State = np.expand_dims(p_Obs_State, axis=0)
prev_score = np.expand_dims(T1_table[i-1, :], axis=-1)
# 发射概率和转移概率广播 + 转移概率
curr_score = prev_score + self.transition + p_Obs_State
# 存入T1 T2中
T1_table[i, :] = np.max(curr_score, axis=0)
T2_table[i, :] = np.argmax(curr_score, axis=0)
# 回溯
best_tag_id = int(np.argmax(T1_table[-1, :]))
best_tags = [best_tag_id, ]
for i in range(seq_len-1, 0, -1):
best_tag_id = int(T2_table[i, best_tag_id])
best_tags.append(best_tag_id)
return list(reversed(best_tags))解析一下 decode 具体的矩阵运算是怎样的,“新华社在中国的北京”

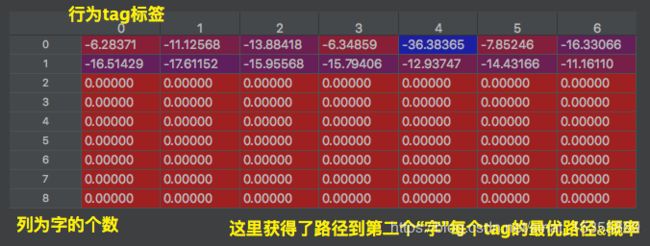
最后一个截图有误,应该是按列取每列的最大,思考一下,
前面两项是 上一个的概率【1】+trans的概率【2】 ok + 然后再加上【3】每个tag生成该字的概率
【3】这里是表示“华”生成每种tag的概率,over
举例-5.44068 需要分别加上【1】+【2】后的结果,如第二行第一列结果-39.42862表示 前一个tag从tag1转移到tag0的概率,同时再加上tag0生成字“华”的概率-5.44068 = -44.86931,所以,根据多条路径,最终得到,最大的概率来自于tag3=-16.51429 ,上述过程为红线部分,下图中的是0.028,同理

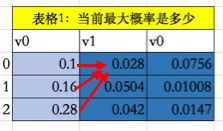
相当于 一次把v1这一列都给算了~,
刚开始第一步结束后


然后变化了

最后,

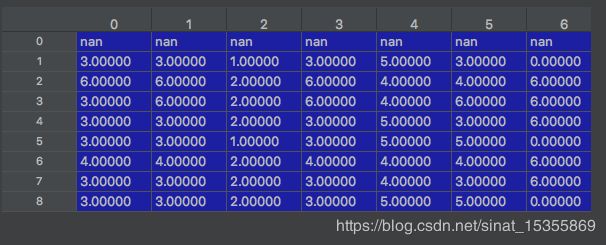
从表1最后一行,取最大的概率哪个tag节点,最后一行最大为-45.29800,tag=4,就是下面列表的最后一个元素,继续往前早,看表2,上面记录了最大的来自于7行的tag5,所以5 -》往前看6行的格子5里面记录的是3 ---> 以此类推,然后逆向返回。
[0, 6, 6, 3, 5, 4, 3, 5, 4]
以上是HMM里面的 decode代码,下面来看一下 tensorflow中的crf代码,本质上是一样的。
def viterbi_decode(score, transition_params):
"""Decode the highest scoring sequence of tags outside of TensorFlow.
This should only be used at test time.
Args:
score: A [seq_len, num_tags] matrix of unary potentials.
transition_params: A [num_tags, num_tags] matrix of binary potentials.
Returns:
viterbi: A [seq_len] list of integers containing the highest scoring tag
indices.
viterbi_score: A float containing the score for the Viterbi sequence.
"""
trellis = np.zeros_like(score)
backpointers = np.zeros_like(score, dtype=np.int32)
trellis[0] = score[0]
for t in range(1, score.shape[0]):
v = np.expand_dims(trellis[t - 1], 1) + transition_params
trellis[t] = score[t] + np.max(v, 0)
backpointers[t] = np.argmax(v, 0)
viterbi = [np.argmax(trellis[-1])]
for bp in reversed(backpointers[1:]):
viterbi.append(bp[viterbi[-1]])
viterbi.reverse()
viterbi_score = np.max(trellis[-1])
return viterbi, viterbi_score正常的score 维度举例为 [?, 23, 109] 23是句子长度,109是tag数量,输入2为 transition matrix。
输出为[?, 23], 最后一个字最大的score,
之前HMM需要3个参数 A, B, π,实际上tensorflow只需要B就ok,因为bilstm输出的发射概率就是单字的π,而且初始化表格1时候,只需要取score[0] 就ok了,结束~