一句Python,一句R︱pandas模块——高级版data.frame
先学了R,最近刚刚上手python,所以想着将python和R结合起来互相对比来更好理解python。最好就是一句python,对应写一句R。
pandas可谓如雷贯耳,数据处理神器。
---
目录
一、Series 和 DataFrame构成
1、series构造
2、dataframe构造
二、以某规则重排列.reindex
1、series
2、dataframe
三、切片与删除、增加操作与选中
1、切片-定位
2、删除
3、增加
四、排序与排名
1、排序
2、排名rank
五、简单统计量/计数
六、缺失值处理
七、其他
1、组合相加
2、dataframe应用函数
3、inplace 用法
4、DataFrame转换为其他类型
5、pandas中字符处理
6、时间序列
延伸应用一:dataframe如何横向、纵向合并?
延伸二:DataFrame横向合并/拼接 出现不可合并问题的
延伸三:dataframe、series的索引删除与创建问题
延伸四:使用 Cut 函数进行分箱
pd.qcut()和pd.cut()区别:
延伸五:实战中的内容拼接pd.concat
延伸六:空缺值NaN如何填补
延伸七:dataframe去重
延伸八:read_csv,数据读入
延伸九:dataframe 抽样 sample
延伸十:跟mysql一样文字规则查询
以下符号:
=R=
代表着在R中代码是怎么样的。
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包
类似于 Numpy 的核心是 ndarray,pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的 。Series 和 DataFrame 分别对应于一维的序列和二维的表结构。pandas 约定俗成的导入方法如下:
神奇的axis=0/1 :
合并的时候,axis=0代表rbinb,axis=1代表cbind;
单个dataframe时候,axis=0代表列,axis=1代表行
预先加载:
from pandas import Series,DataFrame
import pandas as pd

本图来源于:https://s3.amazonaws.com/assets.datacamp.com/blog_assets/PandasPythonForDataScience+(1).pdf
————————————————————————————————————-
一、Series 和 DataFrame构成
1、series构造
s = Series([1,2,3.0,'abc']) #object可以多格式,像list(c(1,2,3.0,'abc'));dtppe为单种格式
s = Series(data=[1,3,5,7],index = ['a','b','x','y']) #其中Index=rownames
s.index #=R=rownames(s)
s.values #=R=s
s.name #colnames列名之上名字
s.index.name #rownames行名之上名字
python很看重index这个属性,相比之下R对于索引的操作明显要弱很多。在延伸中提到对索引的修改与操作。
2、dataframe构造
data = {'state':['Ohino','Ohino','Ohino','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
大括号代表词典,有点像list,可以自定义数列的名字。
df=DataFrame(data)
其中DataFrame(data=None,index=None,columns=None)其中index代表行名称,columns代表列名称其中df.index/df.columns分别代表行名称与列名称:
df.index #行名
df.columns #列名
其中index也是索引,而且不是那么好修改的。
————————————————————————————————————-
二、以某规则重排列.reindex
1、series
series.reindex(index,method,fill_values)
s.reindex(index=[2,1,3,6]) #类似order重排列 此时,按照2,1,3的顺序重新排列
s.reindex(index=[2,1,3,6],fill_value=0) #fill_value插补方式,默认NaN,此时为0
s.reindex(index=[2,1,3,6],fill_value=0,method="backfill")
#method:{'backfill', 'bfill', 'pad', 'ffill', None}(ffill = pad,bfill = back fill,分别指插值时向前还是向后取值)
2、dataframe
#dataframe索引,匹配,缺失值插补
dataframe.reindex(index,columns,method,fill_values) #插值方法 method 参数只能应用于行,即轴 0
state = ['Texas','Utha','California']
df.reindex(columns=state,method='ffill') #只能行插补
df.T.reindex(index=[1,6,3],fill_value=0).T #列插补技巧
————————————————————————————————————-
三、切片与删除、增加操作与选中
dataframe实质是numpy的高阶表现形式。如果选中也是很讲究,这个比R里面的dataframe要复杂一些:
两列:用irow/icol选中单个;用切片选择子集 .ix/.iloc
选择列:
#---1 利用名称选择列---------
data['w'] #选择表格中的'w'列,使用类字典属性,返回的是Series类型
data.w #选择表格中的'w'列,使用点属性,返回的是Series类型
data[['w']] #选择表格中的'w'列,返回的是DataFrame类型
data[['w','z']] #选择表格中的'w'、'z'列
#---2 利用序号寻找列---------
data.icol(0) #取data的第一列
data.ix[:,1] #返回第2行的第三种方法,返回的是DataFrame,跟data[1:2]同
利用序号选择的时候,注意[:,]中的:和,的用法
选择行:
#---------1 用名称选择-----------------
data['a':'b'] #利用index值进行切片,返回的是**前闭后闭**的DataFrame,
#即末端是包含的
data[0:2] #返回第1行到第2行的所有行,前闭后开,包括前不包括后
#--------跟data.table一样,可以不加逗号选中-----------
data[1:2] #返回第2行,从0计,返回的是单行,通过有前后值的索引形式,
#如果采用data[1]则报错
data.ix[1,:] #返回第2行的第三种方法,返回的是DataFrame,跟data[1:2]同
data.irow(0) #取data的第一行
data.iloc[-1] #选取DataFrame最后一行,返回的是Series
data.iloc[-1:] #选取DataFrame最后一行,返回的是DataFrame
其中跟R中的data.table有点像的是,可以通过data[1],就是选中了第一行。
1、切片-定位
python的切片要是容易跟R进行混淆,那么现在觉得区别就是一般来说要多加一个冒号:
R中:
data[1,]
python中:
data[1,:]
一开始不知道切片是什么,其实就是截取数据块。其中还有如何截取符合条件的数据列。
s[1:2] #x[2,2]
df.ix[2,2] #df[3,3]
df.ix[2:3,2:3]
df.ix[2,"pop"] #可以用列名直接定位
df["pop"]
df[:2] #横向第0行,第1行
df[df["pop"]>3] #df[df$pop>3]
跟R很大的区别,就是python中是从0开始算起。
同时定位的时候需要加入data.ix这个.ix很容易被忽略。
其中注意:
负向切片是需要仔细了解的:
L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
>>> L[-2:]
['Bob', 'Jack']
>>> L[-2:-1]
['Bob']
2、删除
s.drop(1) #去掉index为1的行
df.drop(names,axis=0) #axis=0代表rbind,=1代表cbind;names代表列名(colnames)或者行名(rownames)
axis=0) #axis=0代表rbind,=1代表cbind;names代表列名(colnames)或者行名(rownames)
drop(colnames/rownames,axis=0/1)代表按rbind、cbind删除。
3、增加
df.ix[5,:]=[3,"Nevada",3000]
选中之后,填入数据,当然数值很多情况下,应该用合并的操作了。————————————————————————————————————-
四、排序与排名
1、排序
foo.order(ascending=False) #按值,降序,ascending=True代表升序
foo.sort(ascending=False) #按index
也有两个,order和sort。其中sort_index是按照Index进行排列。
Series 的 sort_index(ascending=True) 方法可以对 index 进行排序操作,ascending 参数用于控制升序或降序,默认为升序。若要按值对 Series 进行排序,当使用 .order() 方法,任何缺失值默认都会被放到 Series 的末尾。在 DataFrame 上,.sort_index(axis=0, by=None, ascending=True) 方法多了一个轴向的选择参数与一个 by 参数,by 参数的作用是针对某一(些)列进行排序(不能对行使用 by 参数)。
df.sort(axis=0,ascending=False,by=None)
#按index,比series 多了axis,横向纵向的功能
#by默认为None,by 参数的作用是针对某一(些)列进行排序(不能对行使用 by 参数)
#by两个,df.sort_index(by=['California','Texas'])axis=0,ascending=False,by=None)
#按index,比series 多了axis,横向纵向的功能
#by默认为None,by 参数的作用是针对某一(些)列进行排序(不能对行使用 by 参数)
#by两个,df.sort_index(by=['California','Texas'])
dataframe的排序
2、排名rank
Series.rank(method='average', ascending=True)
#返回的是名次的值value
#处理平级项,方法里的 method 参数就是起这个作用的,他有四个值可选:average, min, max, first
dataframe.rank(axis=0, method='first', ascending=True) #按行给出名次axis=0, method='first', ascending=True) #按行给出名次
排名(Series.rank(method='average', ascending=True))的作用与排序的不同之处在于,他会把对象的 values 替换成名次(从 1 到 n)。这时唯一的问题在于如何处理平级项,方法里的 method参数就是起这个作用的,他有四个值可选:average, min, max, first。
排序应用一:多维复杂排序
pandas中有sort和rank,这个就跟R里面是一样的了。
rank(axis=0,ascending=Flase,method = 'first')
其中axis代表0为rbind,1代表cbind,ascending=True代表升序(从小到大)、Flase代表降序(从大到小);有一个method选项,用来规定下标的方式
sorted(data.ix[:,1])
# 数据排序
a=data.rank(axis=0,ascending=False)
#数据求秩
data.ix[:,1][a.ix[:,1]-1] data.ix[:,1]代表选中第一列,然后sorted代表对第一列进行排序;
a.ix[:,1]-1 代表排好的秩,-1就还原到数据可以认识的索引。
如果想要在同一表中实现按某列重排,使用sort_index:
data.sort_index(by='index')
————————————————————————————————————-
五、简单统计量/计数
df.mean(axis=0,skipna=True) =R=apply(df,2,mean) #df中的pop,按列求均值,skipna代表是否跳过均值axis=0,skipna=True) =R=apply(df,2,mean) #df中的pop,按列求均值,skipna代表是否跳过均值
这个跟apply很像,返回的是按列求平均。其他常用的统计方法有:
| ######################## | ****************************************** |
| count | 非 NA 值的数量 |
| describe | 针对 Series 或 DF 的列计算汇总统计 |
| min , max | 最小值和最大值 |
| argmin , argmax | 最小值和最大值的索引位置(整数) |
| idxmin , idxmax | 最小值和最大值的索引值 |
| quantile | 样本分位数(0 到 1) |
| sum | 求和 |
| mean | 均值 |
| median | 中位数 |
| mad | 根据均值计算平均绝对离差 |
| var | 方差 |
| std | 标准差 |
| skew | 样本值的偏度(三阶矩) |
| kurt | 样本值的峰度(四阶矩) |
| cumsum | 样本值的累计和 |
| cummin , cummax | 样本值的累计最大值和累计最小值 |
| cumprod | 样本值的累计积 |
| diff | 计算一阶差分(对时间序列很有用) |
| pct_change | 计算百分数变化 |
其中df.describe()还是挺有用的,对应R的summary:
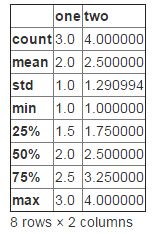
1、频数统计
R中的table真的是一个逆天的函数,那么python里面有没有类似的函数呢?
data2=pd.DataFrame([1,2,3,4,1],index=["a","b","c","d","e"]);data2
data2[0].value_counts()
Out[174]:
1 2
4 1
3 1
2 1
Name: 0, dtype: int64还有交叉计数的情况,直接看效果:
df = pd.DataFrame({'A':['foo', 'bar', 'foo', 'bar','foo', 'bar', 'foo', 'foo'],'B':['one', 'one', 'two', 'three','two', 'two', 'one', 'three'],'C':np.arange(8),'D':np.arange(8,16)})
df
Out[200]:
A B C D
0 foo one 0 8
1 bar one 1 9
2 foo two 2 10
3 bar three 3 11
4 foo two 4 12
5 bar two 5 13
6 foo one 6 14
7 foo three 7 15以上是数据:
df.groupby('A').sum()#按照A列的值分组求和
Out[202]:
C D
A
bar 9 33
foo 19 59
df.groupby(['A','B']).sum()##按照A、B两列的值分组求和
Out[203]:
C D
A B
bar one 1 9
three 3 11
two 5 13
foo one 6 22
three 7 15
two 6 22还有分组计数:
groups['C'].count()##按照A列的值分组B组计数
Out[210]:
A
bar 3
foo 5
Name: C, dtype: int64import pandas as pd
import numpy as np
ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings',
'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'],
'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
'Points':[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
# 根据某一列汇总
df.groupby('Team')
# 查看分组
df.groupby('Team').groups
# 根据多列汇总
df.groupby(['Team','Year']).groups
# 遍历分组:
grouped = df.groupby('Team')
for name,group in grouped:
print(name)
print(group)
Devils
Team Rank Year Points
2 Devils 2 2014 863
3 Devils 3 2015 673
Kings
Team Rank Year Points
4 Kings 3 2014 741
6 Kings 1 2016 756
7 Kings 1 2017 788
Riders
Team Rank Year Points
0 Riders 1 2014 876
1 Riders 2 2015 789
8 Riders 2 2016 694
11 Riders 2 2017 690
Royals
Team Rank Year Points
9 Royals 4 2014 701
10 Royals 1 2015 804
kings
Team Rank Year Points
5 kings 4 2015 812
可以选取某个:
#选取某一个分组
grouped = df.groupby('Year')
print(grouped.get_group(2014))
Team Rank Year Points
0 Riders 1 2014 876
2 Devils 2 2014 863
4 Kings 3 2014 741
9 Royals 4 2014 701如何groupby分组统计结果转换成Dataframe?
import pandas as pd
import numpy as np
# 创建dataframe
data = pd.DataFrame({"key": list("abbcaabac"),
"value": [1, 2, 3, 4, 5, 6, 7, 8, 9]})
# 按key分组
data_group = data.groupby(data["key"])
new_data = pd.DataFrame(columns=["key", "value"])
print(new_data)
# 循环拼接
for key, value in data_group:
new_data = pd.concat([new_data, value])
print(new_data)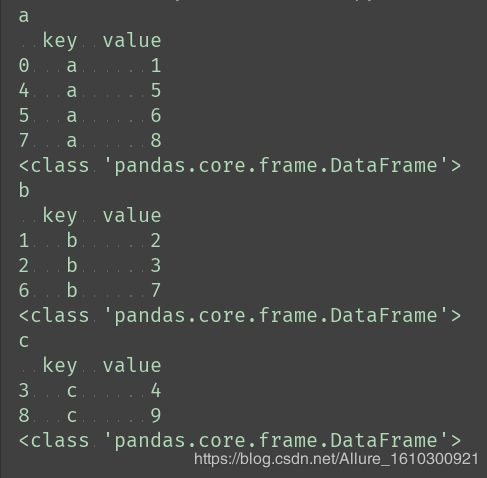
来看一下data.groupby(data["key"])之后,是一个LIST型,
类型是:(key1,dataframe1),(key2,dataframe2)
如果要拼接起来,可以pd.concat起来
聚合函数Aggregations:
(可参考:https://www.tutorialspoint.com/python_pandas/python_pandas_groupby.htm)
聚合多个:
grouped = df.groupby('Team')
print(grouped['Points'].agg([np.sum, np.mean, np.std]))
sum mean std
Team
Devils 1536 768.000000 134.350288
Kings 2285 761.666667 24.006943
Riders 3049 762.250000 88.567771
Royals 1505 752.500000 72.831998
kings 812 812.000000 NaNTransformations
grouped = df.groupby('Team')
score = lambda x: (x - x.mean()) / x.std()*10
print(grouped.transform(score))
Rank Year Points
0 -15.000000 -11.618950 12.843272
1 5.000000 -3.872983 3.020286
2 -7.071068 -7.071068 7.071068
3 7.071068 7.071068 -7.071068
4 11.547005 -10.910895 -8.608621
5 NaN NaN NaN
6 -5.773503 2.182179 -2.360428
7 -5.773503 8.728716 10.969049
8 5.000000 3.872983 -7.705963
9 7.071068 -7.071068 -7.071068
10 -7.071068 7.071068 7.071068
11 5.000000 11.618950 -8.157595Filtration
print(df.groupby('Team').filter(lambda x: len(x) >= 3))
Team Rank Year Points
0 Riders 1 2014 876
1 Riders 2 2015 789
4 Kings 3 2014 741
6 Kings 1 2016 756
7 Kings 1 2017 788
8 Riders 2 2016 694
11 Riders 2 2017 690
文本聚合:
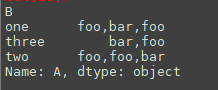
df = pd.DataFrame({'A':['foo', 'bar', 'foo', 'bar','foo', 'bar', 'foo', 'foo'],'B':['one', 'one', 'two', 'three','two', 'two', 'one', 'three'],'C':np.arange(8),'D':np.arange(8,16)})
df.groupby(['B'])['A'].agg(','.join)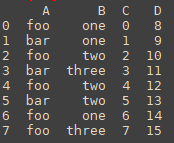
聚合之后为:
两个内容聚合合并:
这里的ID可能一个人有很多个,所以需要合并:
# 先groupby聚合起来
data1 = pd.DataFrame( main_data.groupby(['hyper_id'])['id_type'].agg(dict ) )
# 然后合并
def dict2rbind(_dict):
t_dict = {}
for k1,v1 in _dict.items():
for k2,v2 in v1.items():
t_dict[k2] = v2
return t_dict
list(data['id_type'].map(dict2rbind ))
2、Apply 函数
在向数据框的每一行或每一列传递指定函数后,Apply 函数会返回相应的值。
#Create a new function:
def num_missing(x):
return sum(x.isnull())
#Applying per column:
print "Missing values per column:"
print data.apply(num_missing, axis=0) #axis=0 defines that function is to be applied on each column = rbind
#Applying per row:
print "nMissing values per row:"
print data.apply(num_missing, axis=1).head() #axis=1 defines that function is to be applied on each row =cbindaxis=0) #axis=0 defines that function is to be applied on each column = rbind
#Applying per row:
print "nMissing values per row:"
print data.apply(num_missing, axis=1).head() #axis=1 defines that function is to be applied on each row =cbind
可以传入函数,跟R里面apply一样。
————————————————————————————————————-
六、缺失值处理
df.isnull #=R=is.na()
df.dropna #去掉缺失值
df.fillna(value=None, method=None, axis=0) #填充方法,method
df.notnull #跟isnull一样,=R=is.na()axis=0) #填充方法,method
df.notnull #跟isnull一样,=R=is.na()
fillna() 函数可一次性完成填补功能。它可以利用所在列的均值/众数/中位数来替换该列的缺失数据。下面利用“Gender”、“Married”、和“Self_Employed”列中各自的众数值填补对应列的缺失数据。
from scipy.stats import mode
mode(data['Gender'])
输出结果为:ModeResult(mode=array([‘Male’], dtype=object), count=array([489]))
输出结果返回了众数值和对应次数。需要记住的是由于可能存在多个高频出现的重复数据,因此众数可以是一个数组。通常默认使用第一个众数值:
mode(data['Gender']).mode[0]
现在可以进行缺失数据值填补并利用#2方法进行检查。
#Impute the values:
data['Gender'].fillna(mode(data['Gender']).mode[0], inplace=True)
data['Married'].fillna(mode(data['Married']).mode[0], inplace=True)
data['Self_Employed'].fillna(mode(data['Self_Employed']).mode[0], inplace=True)
#Now check the #missing values again to confirm:
print data.apply(num_missing, axis=0)axis=0)
至此,可以确定缺失值已经被填补。请注意,上述方法是最基本的填补方法。包括缺失值建模,用分组平均数(均值/众数/中位数)。
————————————————————————————————————-
七、其他
1、组合相加
两个数列,返回的Index是两个数据列变量名称的;value中重复数据有值,不重复的没有。 #series dataframe的算术
foo = Series({'a':1,'b':2})
bar = Series({'b':3,'d':4})
foo+bar #merge(foo,bar,by=index)匹配到的数字相加,未匹配到的用NaN表示
2、dataframe应用函数
#函数——apply族的用法
f = lambda x:x.max()-x.min() #numpy的附函数
df.apply(f) #.apply(func,axis=0,args,kwds)默认为axis=0情况下按rbind操作函数faxis=0,args,kwds)默认为axis=0情况下按rbind操作函数f
3、inplace 用法
DataFrame(data,inplace=False)
Series 和 DataFrame 对象的方法中,凡是会对数组作出修改并返回一个新数组的,往往都有一个 replace=False 的可选参数。如果手动设定为 True,那么原数组就可以被替换。
参考文献:Python 数据分析包:pandas 基础
4、DataFrame转换为其他类型
参考:pandas.DataFrame.to_dict
df.to_dict(orient='dict')outtype的参数为‘dict’、‘list’、‘series’和‘records’。 dict返回的是dict of dict;list返回的是列表的字典;series返回的是序列的字典;records返回的是字典的列表:
data2=pd.DataFrame([1,2,3,4],index=["a","b","c","d"])
data2.to_dict(orient='dict')
Out[139]: {0: {'a': 1, 'b': 2, 'c': 3, 'd': 4}}
data2.to_dict(orient='list')
Out[140]: {0: [1, 2, 3, 4]}
data2.to_dict(orient='series')
Out[141]:
{0: a 1
b 2
c 3
d 4
Name: 0, dtype: int64}
data2.to_dict(orient='records')
Out[142]: [{0: 1}, {0: 2}, {0: 3}, {0: 4}]单列数据转化类型,用astype函数:
data2=pd.DataFrame([1,2,3,4],index=["a","b","c","d"])
type(data2[0])
data2[0].astype(float)
Out[155]:
a 1.0
b 2.0
c 3.0
d 4.0
Name: 0, dtype: float64
dict转化为dataframe:
example['a'] = {'bb':2, 'cc':3}
eee = pd.DataFrame(example)
numpy.ndarray转化为dataframe:
pd.DataFrame(example)
5、pandas中字符处理
pandas提供许多向量化的字符操作,你可以在str属性中找到它们
s.str.lower()
s.str.len()
s.str.contains(pattern)
6、时间序列
时间序列也是Pandas的一个特色。时间序列在Pandas中就是以Timestamp为索引的Series。
pandas提供to_datetime方法将代表时间的字符转化为Timestamp对象:
s = '2013-09-16 21:00:00'
ts = pd.to_datetime(s)
有时我们需要处理时区问题:
ts=pd.to_datetime(s,utc=True).tz_convert('Asia/Shanghai')
构建一个时间序列:
rng = pd.date_range('1/1/2012', periods=5, freq='M')
ts = pd.Series(randn(len(rng)), index=rng)
Pandas提供resample方法对时间序列的时间粒度进行调整:
ts_h=ts.resample('H', how='count')#M,5Min,1s
以上是将时间序列调整为小时,还可以支持月(M),分钟(Min)甚至秒(s)等。
参考博客:《Python中的结构化数据分析利器-Pandas简介》
几个时间序列处理的CASE:
action['end_date'] = '2017-02-01'
order['end_date'] = pd.to_datetime(order['end_date'])
action['end_date'] = pd.to_datetime(action['end_date'])
#实际购买时间和end_date相差的月数
order['date_diff'] = order['end_date']-order['o_date']
action['date_diff'] = action['end_date']-action['a_date']
#实际购买时间和end_date相差的月数
order['month_diff'] = (order['end_date'].dt.year - order['o_date_y'])*12+(order['end_date'].dt.month - order['o_date_m'])
action['month_diff'] = (action['end_date'].dt.year - action['a_date_y'])*12+(action['end_date'].dt.month - action['a_date_m'])
其中,字符型的时间格式是'2017-02-01'
order['end_date'].dt.year,就可以定位到年份,2017
如果是时序格式的时间差,只能这么:order['date_diff']<=timedelta(days=14)比大小;不能order['date_diff']<=14
6、Crosstab 函数
该函数用于获取数据的初始印象(直观视图),从而验证一些基本假设。例如在本例中,“Credit_History”被认为会显著影响贷款状态。这个假设可以通过如下代码生成的交叉表进行验证:
pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True)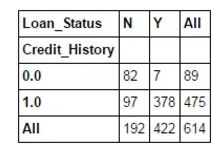
以上这些都是绝对值。但百分比形式能获得更为直观的数据结果。使用 apply 函数可实现该功能:
def percConvert(ser):
return ser/float(ser[-1])
pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True).apply(percConvert, axis=1)axis=1)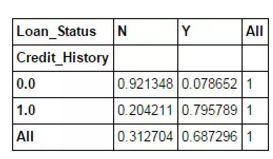
————————————————————————————————————-
延伸应用一:dataframe如何横向、纵向合并?
1、横向合并,跟R一样,用merge就可以。
merge(data1,data2,on="id",, how='left'/'right')
merge(data1,data2,left_on='id1', right_on='id2', how='left'/'right') #如果两个数据集Key不一样,也可以合并
D1 = pd.DataFrame({'id':[801, 802, 803,804, 805, 806, 807, 808, 809, 810], 'name':['Ansel', 'Wang', 'Jessica', 'Sak','Liu', 'John', 'TT','Walter','Andrew','Song']})
D2 = pd.DataFrame({'id':[803, 804, 808,901], 'save': [3000, 500, 1200, 8800]})
merge(D1, D2, on='id')
还可以:
user_fea=user_info.merge(user_fea,right_index=True,left_index=True,how='left')
2、纵向合并、堆砌——concat
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True)axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True)concat不会去重,要达到去重的效果可以使用drop_duplicates方法。
1、objs 就是需要连接的对象集合,一般是列表或字典;
2、axis=0 是连接轴向join='outer' 参数作用于当另一条轴的 index 不重叠的时候,只有 'inner' 和 'outer' 可选(顺带展示 ignore_index=True 的用法),axis=1,代表按照列的方式合并。
3、join_axes=[] 指定自定义索引
4、参数ignore_index=True 重建索引
同时,可以标识出来, keys=[ , ] 来标识出来,基本语句为:concat([D1,D2], keys=['D1', 'D2'] )
同时,concat也可以暴力的横向合并:concat([D1,D2], axis=1)
注意:
特别是参数ignore_index=True,一定要带上,因为不带上会出现索引都是0000,那么就不能方便地使用切片,而发生切片都是“0”
参考:【原】十分钟搞定pandas
————————————————————————————————————-
延伸二:DataFrame横向合并/拼接 出现不可合并问题的
尤其是两个数据集需要横向合并的情况,索引一般会出现较大的问题。如果自定义了索引,自定的索引会自动寻找原来的索引,如果一样的,就取原来索引对应的值,这个可以简称为“自动对齐”。
那么这样的两列数:
data1=pd.Series([1,2,3,4],index=["a","b","c","d"])
data2=pd.Series([3,2,3,4],index=["e","f","g","h"])
pd.concat([pd.DataFrame(data1).T,pd.DataFrame(data2).T])
Out[11]:
a b c d e f g h
0 1.0 2.0 3.0 4.0 NaN NaN NaN NaN
0 NaN NaN NaN NaN 3.0 2.0 3.0 4.0那么由于索引不一样,就会出现合并起来的时候,不对齐。
这时候就需要对索引进行修改,以下就是纵向/横向修改:
data1.T.columns=["e","f","g","h"]
data1.index=["e","f","g","h"]
只有索引修改完之后才能进行合并,不然就会出现文不对题的情况。
其中注意:
series没有转置的情况
series没有转置的情况,我在尝试Series之间的横向合并的时候,只能纵向拼接。所以,需要转化成dataframe格式才能进行纵向拼接。
data1=pd.Series([1,2,3,4],index=["a","b","c","d"])
data2=pd.Series([3,2,3,4],index=["e","f","g","h"])
pd.concat([data1.T,data2.T])
Out[31]:
a 1
b 2
c 3
d 4
e 3
f 2
g 3
h 4
dtype: int64
————————————————————————————————————-
延伸三:dataframe、series的索引删除与创建问题
可以看到,延伸三里面提到了因为索引而不方便进行数据操作的问题。那么如何在pandas进行索引操作呢?索引的增加、删除。
创建的时候,你可以指定索引。譬如:
pd.DataFrame([1,2],index=("a","b"),columns=("c"))
pd.Series([1,2],index=("a","b"))从上面的内容,可以看出dataframe可以指定纵向、横向的索引。而series只能指定一个维度的索引。
(1)pd.DataFrame+pd.Series不能通过(index=None)来消除index:
所以,DataFrame/series也是不能通过以下的办法来取消索引:
data1=pd.Series([1,2,3,4],index=["a","b","c","d"])
pd.Series(data1,index=None)
Out[44]:
a 1
b 2
c 3
d 4
dtype: int64以及
data2=pd.DataFrame([1,2,3,4],index=["a","b","c","d"])
pd.DataFrame(data2,index=None,columns=None)
Out[45]:
0
a 1
b 2
c 3
d 4
(2)通过reset_index来消除index
官方地址
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
#inplace,是否删除原索引
#drop,删除原索引后,时候生成新的Index列可以来看一下这个函数的效果:
data2=pd.DataFrame([1,2,3,4],index=["a","b","c","d"])
data2.reset_index(inplace=True,drop=False);data2
Out[125]:
index 0
0 a 1
1 b 2
2 c 3
3 d 4来看看开启inplace+关闭drop的效果,把Index列单独加入了数列中。
data2=pd.DataFrame([1,2,3,4],index=["a","b","c","d"])
data2.reset_index(inplace=True,drop=True);data2
Out[126]:
0
0 1
1 2
2 3
3 4inplace开启+开启drop的效果,单独把index都删除了。
————————————————————————————————————-
延伸四:使用 Cut 函数进行分箱
有时将数值数据聚合在一起会更有意义。例如,如果我们要根据一天中的某个时间段(单位:分钟)建立交通流量模型模型(以路上的汽车为统计目标)。与具体的分钟数相比,对于交通流量预测而言一天中的具体时间段则更为重要,如“早上”、 “下午”、“傍晚”、“夜晚”、“深夜(Late Night)”。以这种方式建立交通流量模型则更为直观且避免了过拟合情况的发生。
cut使用方式有以下几种(来源:pandas 数据规整):
(1)按序列划分,序列:按序列的元素间隔划分 x,返回 x 各个元素的分组情况
>>> bins = [0,3,6,9]
>>> ser = Series(np.random.randint(1,10,6))
>>> ser
0 5
1 5
2 1
3 4
4 3
5 4
dtype: int32
>>> cats = pd.cut(ser,bins,labels=['small','middle','large'])
>>> cats
middle
middle
small
middle
small
middle
Levels (3): Index(['small', 'middle', 'large'], dtype=object)
(2)整数分段:整数:以 x 的上下界等长划分,可用 precision 参数调节精度
>>> ser = Series([2,6,7,3,8])
>>> pd.cut(ser,3,precision=1)
(2, 4]
(4, 6]
(6, 8]
(2, 4]
(6, 8]
Levels (3): Index(['(2, 4]', '(4, 6]', '(6, 8]'], dtype=object)(3)pd.qcut() 函数与 cut 类似,但它可以根据样本的分位数对数据进行面元划分:
>>> ser = np.random.randint(0,100,1000)
>>> cats = pd.qcut(ser,10)
>>> pd.value_counts(cats)
(61, 70] 112
(41, 52] 104
[0, 9] 104
(20.8, 31] 103
(77, 88] 102
(31, 41] 100
(88, 99] 97
(9, 20.8] 96
(52, 61] 94
(70, 77] 88
dtype: int64
一个案例:
下面的例子中定义了一个简单的可重用函数,该函数可以非常轻松地实现任意变量的分箱功能。
#Binning:
def binning(col, cut_points, labels=None):
#Define min and max values:
minval = col.min()
maxval = col.max()
#create list by adding min and max to cut_points
break_points = [minval] + cut_points + [maxval]
#if no labels provided, use default labels 0 ... (n-1)
if not labels:
labels = range(len(cut_points)+1)
#Binning using cut function of pandas
colBin = pd.cut(col,bins=break_points,labels=labels,include_lowest=True)
return colBin
#Binning age:
cut_points = [90,140,190]
labels = ["low","medium","high","very high"]
data["LoanAmount_Bin"] = binning(data["LoanAmount"], cut_points, labels)
print pd.value_counts(data["LoanAmount_Bin"], sort=False)
参考:Python 数据处理:Pandas 模块的 12 种实用技巧
pd.qcut()和pd.cut()区别:
来源:Pandas —— qcut( )与cut( )的区别
qcut是根据这些值的频率来选择箱子的均匀间隔,即每个箱子中含有的数的数量是相同的
cut将根据值本身来选择箱子均匀间隔,即每个箱子的间距都是相同的
(1)qcut
| 参数 | 说明 |
|---|---|
| x | ndarray或Series |
| q | integer,指示划分的组数 |
| labels | array或bool,默认为None。当传入数组时,分组的名称由label指示;当传入Flase时,仅显示分组下标 |
| retbins | bool,是否返回bins,默认为False。当传入True时,额外返回bins,即每个边界值。 |
| precision | int,精度,默认为3 |
传入q参数
>>> pd.qcut(factors, 3) #返回每个数对应的分组
[(1.525, 2.154], (-0.158, 1.525], (1.525, 2.154], (-2.113, -0.158], (-2.113, -0.158], (1.525, 2.154], (-2.113, -0.158], (-0.158, 1.525], (-0.158, 1.525]]
Categories (3, interval[float64]): [(-2.113, -0.158] < (-0.158, 1.525] < (1.525, 2.154]]
>>> pd.qcut(factors, 3).value_counts() #计算每个分组中含有的数的数量
(-2.113, -0.158] 3
(-0.158, 1.525] 3
(1.525, 2.154] 3传入lable参数
>>> pd.qcut(factors, 3,labels=["a","b","c"]) #返回每个数对应的分组,但分组名称由label指示
[c, b, c, a, a, c, a, b, b]
Categories (3, object): [a < b < c]
>>> pd.qcut(factors, 3,labels=False) #返回每个数对应的分组,但仅显示分组下标
[2 1 2 0 0 2 0 1 1]传入retbins参数
>>> pd.qcut(factors, 3,retbins=True)# 返回每个数对应的分组,且额外返回bins,即每个边界值
[(1.525, 2.154], (-0.158, 1.525], (1.525, 2.154], (-2.113, -0.158], (-2.113, -0.158], (1.525, 2.154], (-2.113, -0.158], (-0.158, 1.525], (-0.158, 1.525]]
Categories (3, interval[float64]): [(-2.113, -0.158] < (-0.158, 1.525] < (1.525, 2.154],array([-2.113, -0.158 , 1.525, 2.154]))如果有重复的问题:
qcut(x, q, labels=None, retbins=False, precision=3, duplicates='raise')Parameters
----------
x : 1d ndarray or Series
q : integer or array of quantiles
Number of quantiles. 10 for deciles, 4 for quartiles, etc. Alternately
array of quantiles, e.g. [0, .25, .5, .75, 1.] for quartiles
labels : array or boolean, default None
Used as labels for the resulting bins. Must be of the same length as
the resulting bins. If False, return only integer indicators of the
bins.
retbins : bool, optional
Whether to return the (bins, labels) or not. Can be useful if bins
is given as a scalar.
precision : int, optional
The precision at which to store and display the bins labels
duplicates : {default 'raise', 'drop'}, optional
If bin edges are not unique, raise ValueError or drop non-uniques.
.. versionadded:: 0.20.0
(2)cut函数
| 参数 | 说明 |
|---|---|
| x | array,仅能使用一维数组 |
| bins | integer或sequence of scalars,指示划分的组数或指定组距 |
| labels | array或bool,默认为None。当传入数组时,分组的名称由label指示;当传入Flase时,仅显示分组下标 |
| retbins | bool,是否返回bins,默认为False。当传入True时,额外返回bins,即每个边界值。 |
| precision | int,精度,默认为3 |
传入bins参数
>>> pd.cut(factors, 3) #返回每个数对应的分组
[(0.732, 2.154], (-0.69, 0.732], (0.732, 2.154], (-0.69, 0.732], (-2.117, -0.69], (0.732, 2.154], (-0.69, 0.732], (-0.69, 0.732], (0.732, 2.154]]
Categories (3, interval[float64]): [(-2.117, -0.69] < (-0.69, 0.732] < (0.732, 2.154]]
>>> pd.cut(factors, bins=[-3,-2,-1,0,1,2,3])
[(2, 3], (0, 1], (1, 2], (-1, 0], (-3, -2], (2, 3], (-1, 0], (0, 1], (1, 2]]
Categories (6, interval[int64]): [(-3, -2] < (-2, -1] < (-1, 0] < (0, 1] (1, 2] < (2, 3]]
>>> pd.cut(factors, 3).value_counts() #计算每个分组中含有的数的数量
Categories (3, interval[float64]): [(-2.117, -0.69] < (-0.69, 0.732] < (0.732, 2.154]]
(-2.117, -0.69] 1
(-0.69, 0.732] 4
(0.732, 2.154] 4传入lable参数
>>> pd.cut(factors, 3,labels=["a","b","c"]) #返回每个数对应的分组,但分组名称由label指示
[c, b, c, b, a, c, b, b, c]
Categories (3, object): [a < b < c]
>>> pd.cut(factors, 3,labels=False) #返回每个数对应的分组,但仅显示分组下标
[2 1 2 1 0 2 1 1 2]传入retbins参数
>>> pd.cut(factors, 3,retbins=True)# 返回每个数对应的分组,且额外返回bins,即每个边界值
([(0.732, 2.154], (-0.69, 0.732], (0.732, 2.154], (-0.69, 0.732], (-2.117, -0.69], (0.732, 2.154], (-0.69, 0.732], (-0.69, 0.732], (0.732, 2.154]]
Categories (3, interval[float64]): [(-2.117, -0.69] < (-0.69, 0.732] < (0.732, 2.154]], array([-2.11664951, -0.69018126, 0.7320204 , 2.15422205]))有一种应用场景是分好类别之后,如何对新数据进行分类,切割:
'''
bins
array([ 0. , 9.9, 19.8, 29.7, 39.6, 49.5, 59.4, 69.3, 79.2,
89.1, 99. ])
qcut_data
[[0, [0.0, 9.9000000000000004]],
[1, [9.9000000000000004, 19.800000000000001]],
[2, [19.800000000000001, 29.700000000000003]],
[3, [29.700000000000003, 39.600000000000001]],
[4, [39.600000000000001, 49.5]],
[5, [49.5, 59.400000000000006]],
[6, [59.400000000000006, 69.300000000000011]],
[7, [69.300000000000011, 79.200000000000003]],
[8, [79.200000000000003, 89.100000000000009]],
[9, [89.100000000000009, 99.0]]]
'''
import pandas as pd
y_train = list(range(100))
labels,bins = pd.qcut(y_train,10,labels = False,retbins = True)
def get_score(new_data,qcut_data):
out = 0
for qcd in qcut_data:
if new_data == qcut_data[0][1][0]:
out = qcut_data[0][0]
elif new_data == qcut_data[-1][1][1]:
out = qcut_data[-1][0]
elif qcd[1][0] < new_data <= qcd[1][1]:
out = qcd[0]
return out
get_score(9,qcut_data)
——————————————————————————————
延伸五:实战中的内容拼接pd.concat
data=pd.concat([data,pd.DataFrame([list[i],] + temp[2].tolist()).T],ignore_index=True)
以上的语句中:concat需要用[]拼接起来,然后想“无缝”拼接两个list,如果不是list,需要data.tolist()进行格式转化。最后的ignore_index不能忘记,因为python里面对索引的要求很高,所以重叠的索引会删除新重复的内容。
ImageVector=pd.concat([data,pd.DataFrame([list[i],] + ('NA '*359).split(' ') ).T ],ignore_index=True)
其中这里想接入一条空白信息,但是没有R里面的rep函数,于是这边用了带空格的NA,最后用split隔开来达到批量获得某条符合要求的空白数据集。
————————————————————————————————————————————————————
延伸六:空缺值NaN如何填补
前面提到的dataframe中填补缺失值可以使用.fillna,除了缺失值其实还有NaN的形式,dataframe好像不是特别能处理,于是自己写了一个函数来处理。
输入dataframe,输出dataframe,用0填补。当然可以自己改一下,调整成自己的想要的数值。
def which_NaN(object_n):
return object_n != object_n
def fillNaN(data):
for i in range(data.shape[1]):
data.ix[:,i][which_NaN(data.ix[:,i])] = 0
return data
延伸七:dataframe去重
来源: Python对多属性的重复数据去重
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
keep : {‘first’, ‘last’, False}, default ‘first’ 删除重复项并保留第一次出现的项
>>> import pandas as pd
>>> data={'state':[1,1,2,2],'pop':['a','b','c','d']}
>>> frame=pd.DataFrame(data)
>>> frame
pop state
0 a 1
1 b 1
2 c 2
3 d 2
>>> IsDuplicated=frame.duplicated()
>>> print IsDuplicated
0 False
1 False
2 False
3 False
dtype: bool
>>> frame=frame.drop_duplicates(['state'])
>>> frame
pop state
0 a 1
2 c 2
>>> IsDuplicated=frame.duplicated(['state'])
>>> print IsDuplicated
0 False
2 False
dtype: bool
>>>
延伸八:read_csv,数据读入
http://pandas.pydata.org/pandas-docs/version/0.20/generated/pandas.read_table.html
pandas.read_table(filepath_or_buffer, sep='\t', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=False, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, skip_footer=0, doublequote=True, delim_whitespace=False, as_recarray=False, compact_ints=False, use_unsigned=False, low_memory=True, buffer_lines=None, memory_map=False, float_precision=None)
如果读入有问题,可以跳过:
设置:
error_bad_lines=False
如果报错:
ParserError: Error tokenizing data. C error: Buffer overflow caught - possible malformed input file.解决方式:
import pandas as pd
df = pd.read_csv(open('data.csv','rU'), sep="\t")https://github.com/pandas-dev/pandas/issues/11166
延伸九:dataframe 抽样 sample
# n 要抽取的行数
df.sample(n=3,random_state=1)
# 抽取行的比例
df.sample(frac=0.8, replace=True, random_state=1)延伸十:跟mysql一样文字规则查询
dataframe['col'].str.contains('关键词')
dataframe['col'].str.contains('关键词|关键词3') # 或
dataframe['col'].str.contains('关键词&关键词3') # 并其中该函数为:
参考:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.str.contains.html
Series.str.contains(self, pat, case=True, flags=0, na=nan, regex=True)

来看一下如何匹配多个字符,并且是按照,并集,或者交集的方式:
# 交集的方式
##可行的是下面的这种:
data[data['col'].str.contains('(?=.*组合)(?=.*衣物)^.*$' , regex=True )]****
##不可行的有:
data[data['col'].str.contains('组合(.*?)衣物' , regex=True )]
data[data['col'].str.contains('组合*衣物' , regex=True )]
data[data['col'].str.contains('组合+衣物' , regex=True )]
data[data['col'].str.contains('.*[(组合)(衣物)].*' , regex=True )]
# 并集的方式
select_dataframe[select_dataframe['original_src_text'].str.contains('组合|衣物' , regex=True )]延伸十一:idxmin() 和 idxmax()
参考:Pandas 3个不为人知却好用的函数
Pandas 里面的 idxmin 、idxmax函数与Numpy中 argmax、argmin 用法大致相同,这些函数将返回第一次出现的最小/最大值的索引。在下面代码中,我们构建了一个DataFrame,通过idxmin() 函数帮助我们找到了每列的最小值所对应的索引。
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(12).reshape(3,4),columns=list('abcd'))
df
df.idxmin(axis=0)idxmin() 函数接受一个可选参数axis, 可以用来控制是按照行还是列的维度查找最小值的索引,默认是axis=0。

延伸十二:分组累加
参考:Pandas 3个不为人知却好用的函数
#cumcount() 和 cumsum()
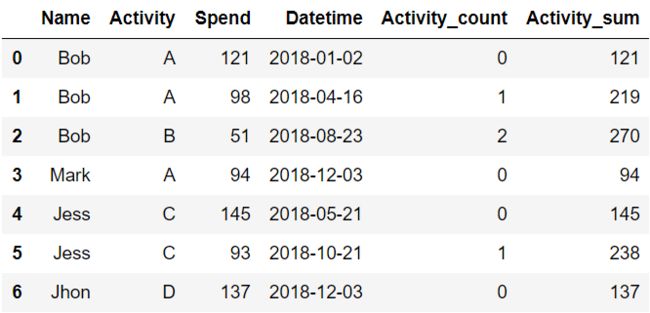
data = {
'Name': ['Bob','Bob','Bob', 'Mark', 'Jess', 'Jess','Jhon'],
'Activity': ['A', 'A', 'B','A','C','C','D'],
'Spend': [121, 98, 51,94,145,93,137],
}
df = pd.DataFrame(data)
df
df['Activity_count'] = df.groupby('Name')['Activity'].cumcount()
df['Activity_sum'] = df.groupby('Name')['Spend'].cumsum()
df
这是两个非常酷的内建函数,用于分组累加计数和累加求和,可以为您提供许多帮助。我们还是基于上一节中的活动费用表,来进行演示。
现在我们想完成以下几个功能:
•按照Name分组统计,每个人累计参加活动次数•按照Name分组统计,每个人累计参加活动费用
延伸十三:利用`isin`进行数据筛选与清理
参考:中文文档,https://www.pypandas.cn/docs/user_guide/indexing.html#用放大设定
考虑一下isin()方法Series,该方法返回一个布尔向量,只要Series元素存在于传递列表中,该向量就为真。这允许您选择一列或多列具有所需值的行:
s = pd.Series(np.arange(5), index=np.arange(5)[::-1], dtype='int64')
s.isin([2, 4, 6])
Out[157]:
4 False
3 False
2 True
1 False
0 True
dtype: bool
s[s.isin([2, 4, 6])]
Out[158]:
2 2
0 4
dtype: int64
Index对象可以使用相同的方法,当您不知道哪些搜索标签实际存在时,它们非常有用:
他可以,如果没有匹配到的,则不会显示;而reindex则不行!
In [159]: s[s.index.isin([2, 4, 6])]
Out[159]:
4 0
2 2
dtype: int64
# compare it to the following
In [160]: s.reindex([2, 4, 6])
Out[160]:
2 2.0
4 0.0
6 NaN
dtype: float64DataFrame也有一个isin()方法。调用时isin,将一组值作为数组或字典传递。如果values是一个数组,则isin返回与原始DataFrame形状相同的布尔数据框,并在元素序列中的任何位置使用True。
In [165]: df = pd.DataFrame({'vals': [1, 2, 3, 4], 'ids': ['a', 'b', 'f', 'n'],
.....: 'ids2': ['a', 'n', 'c', 'n']})
.....:
In [166]: values = ['a', 'b', 1, 3]
In [167]: df.isin(values)
Out[167]:
vals ids ids2
0 True True True
1 False True False
2 True False False
3 False False False通常,您需要将某些值与某些列匹配。只需将值设置dict为键为列的位置,值即为要检查的项目列表。
In [168]: values = {'ids': ['a', 'b'], 'vals': [1, 3]}
In [169]: df.isin(values)
Out[169]:
vals ids ids2
0 True True False
1 False True False
2 True False False
3 False False False结合数据帧的isin同any()和all()方法来快速选择符合给定的标准对数据子集。要选择每列符合其自己标准的行:
In [170]: values = {'ids': ['a', 'b'], 'ids2': ['a', 'c'], 'vals': [1, 3]}
In [171]: row_mask = df.isin(values).all(1)
In [172]: df[row_mask]
Out[172]:
vals ids ids2
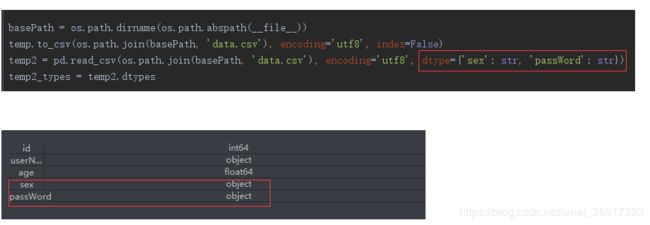
0 1 a a延伸十四:read_csv保存 - 读入报错不能转化成为数字
Pandas: ValueError: cannot convert float NaN to integer看一下这篇文章:
https://blog.csdn.net/yhyr_ycy/article/details/80383060
所以在基于pandas操作csv文件时,需要特别注意这种情况。如果在后续的分析中,需要保留原始数据集中的数据类型,则在读取csv文件时,需要显示的指定dtype参数,从而保证数据类型的前后统一。
延伸十五:数据透视表
参考:https://www.cnblogs.com/huangchenggener/p/10983516.html
pd.pivot_table(df,index=["Manager","Rep"],values=["Price","Quantity"],
columns=["Product"],aggfunc=[np.sum],fill_value=0)其中,index是索引,values是数值;columns是横向的索引;fill_values是填补值
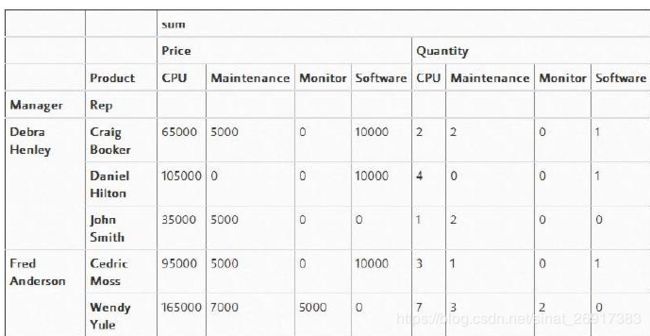
其中,aggfunc中的nunique:
temp.pivot_table(index='user_id',values='o_id',aggfunc={'o_id':'nunique'})
# 可直接统计dataframe中每列的不同值的个数,也可用于series,但不能用于list.返回的是不同值的个数.