03.InfluxDB系统化学习-MetaStore
概述
在《02.InfluxDB系统化学习-InfluxDB初始化》讲述了influxdb数据启动过程中加载的服务,其中在
cmd/influxdb/run/server.go中创建NewServer对象时有以下代码:
MetaClient: meta.NewClient(c.Meta)
该代码主要是完成Meta相关的初始化,本节主要是针对Meta做详细的介绍
Meta的作用
Meta中的信息存储在meta.db的数据文件中,具体配置信息参考《配置文件》章节。
meta 为InfluxDB的元数据服务,用于管理数据库的元数据相关内容;influxdb将meta数据库,包装成一个MetaClient对外提供数据,需要meta的模块都引用这个MetaCient。该meta.db 直接使用protobuf格式的数据作为持久化文件。meta加载持久化文件后,会将全部内容缓存在内存中。当有meta改写时, MetaClient会将更新后的数据序列化然后写入磁盘中。MetaClient一部分数据已slice的形式存储,很多api都会将该slice返回给调用方,从而脱离了其锁的保护,有数据并发竞争 访问的问题存在。meta.db中存储每个database的元数据(名称、过期策略、ContinuousQuery)和用户等信息。
配置文件
全部的配置文件参考《01.InfluxDB系统化学习-配置文件》,关于meta的配置信息如下所示:
###
### [meta]
### 存储有关InfluxDB集群元数据的 Raft consensus group 的控制参数将在下面被配置。
### Controls the parameters for the Raft consensus group that stores metadata
### about the InfluxDB cluster.
###
[meta]
# Where the metadata/raft database is stored
# 元数据/raft 数据库被存储的路径 即meta目录
dir = "/var/lib/influxdb/meta"
# Automatically create a default retention policy when creating a database.
# 当创建一个新的数据库时自动为其创建一个默认的rentention policy(保留策略)
# retention-autocreate = true
# If log messages are printed for the meta service
# 是否为meta服务打印日志
# logging-enabled = true代码分析
通过《02.InfluxDB系统化学习-InfluxDB初始化》中的说明,指导在服务启动过程中会初始化MetaClient并且打开加载相关文件,代码如下:
// NewServer returns a new instance of Server built from a config.
// 依据配置Server对象和它管理的各个组件
func NewServer(c *Config, buildInfo *BuildInfo) (*Server, error) {
。。。。。。
。。。。。。
bind := c.BindAddress
s := &Server{
buildInfo: *buildInfo,
err: make(chan error),
closing: make(chan struct{}),
BindAddress: bind,
Logger: logger.New(os.Stderr),
MetaClient: meta.NewClient(c.Meta),
reportingDisabled: c.ReportingDisabled,
httpAPIAddr: c.HTTPD.BindAddress,
httpUseTLS: c.HTTPD.HTTPSEnabled,
tcpAddr: bind,
config: c,
}
s.Monitor = monitor.New(s, c.Monitor)
s.config.registerDiagnostics(s.Monitor)
if err := s.MetaClient.Open(); err != nil {
return nil, err
}
。。。。。。
。。。。。。
return s, nil
}
MetaClient定义
定义在services/meta/client.go中,负责所有和meta data有关的操作和请求处理(核心定义是cacheData *Data):
// Client is used to execute commands on and read data from
// a meta service cluster.
// 负责所有和meta data有关的操作和请求处理
type Client struct {
logger *zap.Logger
mu sync.RWMutex
closing chan struct{}
changed chan struct{}
cacheData *Data //主要被处理的数据(meta信息的增,删,查,改操作)
// Authentication cache.
authCache map[string]authUser
path string
retentionAutoCreate bool
}
type authUser struct {
bhash string
salt []byte
hash []byte
}
// NewClient returns a new *Client.
func NewClient(config *Config) *Client {
return &Client{
cacheData: &Data{ // Data中定义了meta需要管理的信息
ClusterID: uint64(rand.Int63()),
Index: 1,
},
closing: make(chan struct{}),
changed: make(chan struct{}),
logger: zap.NewNop(),
authCache: make(map[string]authUser),
path: config.Dir,
retentionAutoCreate: config.RetentionAutoCreate,
}
}
Data定义
定义在services/meta/data.go中,详细记录了meta中存储的信息:
// Data represents the top level collection of all metadata.
type Data struct {
Term uint64 // associated raft term
Index uint64 // associated raft index
ClusterID uint64
Databases []DatabaseInfo
Users []UserInfo
// adminUserExists provides a constant time mechanism for determining
// if there is at least one admin user.
adminUserExists bool
MaxShardGroupID uint64
MaxShardID uint64
}
DatabaseInfo
定义数据库的名称,查询方式和回收策略
// DatabaseInfo represents information about a database in the system.
type DatabaseInfo struct { // 管理RetentionPolicies与ContinuousQueries
Name string
DefaultRetentionPolicy string
RetentionPolicies []RetentionPolicyInfo
ContinuousQueries []ContinuousQueryInfo
}
RetentionPolicyInfo
Influxdb是按时间写入数据的,每个DB都有自己的Retention Policy,这个Retention Policy规定了每两个ShardGroup之间的时间跨度ShardGroup Duration, 即每过一个ShardGrup Duration就会生产切换到下一个新的ShardGroup;
1.封装了Retention Policy: 包括了复本个数,数据保留时长,ShardGroup切分时长和当前节点的所有ShardGroup信息
2.定义了按时间和时间范围查找相应ShardGroup的方法
// RetentionPolicyInfo represents metadata about a retention policy.
type RetentionPolicyInfo struct {
Name string
ReplicaN int
Duration time.Duration
ShardGroupDuration time.Duration
ShardGroups []ShardGroupInfo
Subscriptions []SubscriptionInfo
}
ShardGroupInfo记载了当前ShardGroupInfo的信息,并且根据StartTime和EndTime,就可以按时间和时间范围来查找到相应的ShardGroup;
代码如下:
// ShardGroupInfo represents metadata about a shard group. The DeletedAt field is important
// because it makes it clear that a ShardGroup has been marked as deleted, and allow the system
// to be sure that a ShardGroup is not simply missing. If the DeletedAt is set, the system can
// safely delete any associated shards.
type ShardGroupInfo struct {
ID uint64
StartTime time.Time // 这个group 的最早时间
EndTime time.Time // 这个Group里最晚的时间
DeletedAt time.Time
// 这个ShardGroup包含的所有Shard,对于同一个ShardGroup,按Series key(Point key)不同散列写到不同的Shard中;
Shards []ShardInfo
TruncatedAt time.Time
}
// ShardInfo represents metadata about a shard.
type ShardInfo struct {
ID uint64
Owners []ShardOwner
}
// ShardOwner represents a node that owns a shard.
type ShardOwner struct {
NodeID uint64
}
ContinuousQueryInfo
// ContinuousQueryInfo represents metadata about a continuous query.
type ContinuousQueryInfo struct {
Name string
Query string
}
UserInfo
// UserInfo represents metadata about a user in the system.
type UserInfo struct { // 封装了用户信息:用户名,密码,对db的操作权限
// User's name.
Name string
// Hashed password.
Hash string
// Whether the user is an admin, i.e. allowed to do everything.
Admin bool
// Map of database name to granted privilege.
Privileges map[string]influxql.Privilege
}
数据加载
初始化MetaClient之后调用cmd/influxd/run/server.go中的NewServer()方法如下方法完成meta问价的加载和处理:
if err := s.MetaClient.Open(); err != nil {
return nil, err
}
调用services/meta/client.go中的Open()方法,核心方法是Load()和snapshot()
// Open a connection to a meta service cluster.
func (c *Client) Open() error {
c.mu.Lock()
defer c.mu.Unlock()
// Try to load from disk
// meta数据是会保存到磁盘的,influxdb启动时也会从磁盘上读取:
if err := c.Load(); err != nil {
return err
}
// If this is a brand new instance, persist to disk immediatly.
if c.cacheData.Index == 1 {
if err := snapshot(c.path, c.cacheData); err != nil {
return err
}
}
return nil
}
Load()
meta数据存储在磁盘meta.db文件中,influxdb在启动时会从磁盘中加载到内存中,代码参考如下:
// Load loads the current meta data from disk.
func (c *Client) Load() error {
file := filepath.Join(c.path, metaFile)
f, err := os.Open(file)
if err != nil {
if os.IsNotExist(err) {
return nil
}
return err
}
defer f.Close()
data, err := ioutil.ReadAll(f)
if err != nil {
return err
}
// 利用protocol buffer作反序列化,获取文件中的数据存入缓存中
if err := c.cacheData.UnmarshalBinary(data); err != nil {// services/meta/data.go
return err
}
return nil
}
services/meta/data.go
// unmarshal deserializes from a protobuf representation.
func (data *Data) unmarshal(pb *internal.Data) {
data.Term = pb.GetTerm()
data.Index = pb.GetIndex()
data.ClusterID = pb.GetClusterID()
data.MaxShardGroupID = pb.GetMaxShardGroupID()
data.MaxShardID = pb.GetMaxShardID()
data.Databases = make([]DatabaseInfo, len(pb.GetDatabases()))
for i, x := range pb.GetDatabases() {
data.Databases[i].unmarshal(x)
}
data.Users = make([]UserInfo, len(pb.GetUsers()))
for i, x := range pb.GetUsers() {
data.Users[i].unmarshal(x)
}
// Exhaustively determine if there is an admin user. The marshalled cache
// value may not be correct.
data.adminUserExists = data.hasAdminUser()
}
snapshot()
将meta数据写入磁盘,所有的meta信息都有对应的protocol buffer结构,依赖protocol buffer作序列化和反序列化
// snapshot saves the current meta data to disk.
func snapshot(path string, data *Data) error {
filename := filepath.Join(path, metaFile)
tmpFile := filename + "tmp"
f, err := os.Create(tmpFile)
if err != nil {
return err
}
defer f.Close()
var d []byte
// 利用protocol buffer作二进制的序列化
if b, err := data.MarshalBinary(); err != nil {
return err
} else {
d = b
}
// 写入文件
if _, err := f.Write(d); err != nil {
return err
}
if err = f.Sync(); err != nil {
return err
}
//close file handle before renaming to support Windows
if err = f.Close(); err != nil {
return err
}
return file.RenameFile(tmpFile, filename)
}
其他方法
Commit
influxdb运行时,所有的meta信息在内存里都缓存一分,当meta信息有改动时,通过此方法立即写入磁盘,同时更新内存里的缓存
// commit writes data to the underlying store.
// This method assumes c's mutex is already locked.
func (c *Client) commit(data *Data) error {
data.Index++
// try to write to disk before updating in memory
if err := snapshot(c.path, data); err != nil {
return err
}
// update in memory
c.cacheData = data
// close channels to signal changes
close(c.changed)
c.changed = make(chan struct{})
return nil
}
ShardGroupsByTimeRange和ShardsByTimeRange
按给定的时间查找已有的ShardGroup和Shard,和后续需要讲解的查询息息相关
// 按给定的时间查找已有的ShardGroup和Shard
// ShardGroupsByTimeRange returns a list of all shard groups on a database and policy that may contain data
// for the specified time range. Shard groups are sorted by start time.
func (c *Client) ShardGroupsByTimeRange(database, policy string, min, max time.Time) (a []ShardGroupInfo, err error) {
c.mu.RLock()
defer c.mu.RUnlock()
// Find retention policy.
// 先找到RetentionPolicyInfo
rpi, err := c.cacheData.RetentionPolicy(database, policy)
if err != nil {
return nil, err
} else if rpi == nil {
return nil, influxdb.ErrRetentionPolicyNotFound(policy)
}
groups := make([]ShardGroupInfo, 0, len(rpi.ShardGroups))
// 遍历RPI中的所有ShardGroup
for _, g := range rpi.ShardGroups {
if g.Deleted() || !g.Overlaps(min, max) {
continue
}
groups = append(groups, g)
}
return groups, nil
}
// ShardsByTimeRange returns a slice of shards that may contain data in the time range.
func (c *Client) ShardsByTimeRange(sources influxql.Sources, tmin, tmax time.Time) (a []ShardInfo, err error) {
m := make(map[*ShardInfo]struct{})
for _, mm := range sources.Measurements() {
groups, err := c.ShardGroupsByTimeRange(mm.Database, mm.RetentionPolicy, tmin, tmax)
if err != nil {
return nil, err
}
for _, g := range groups {
for i := range g.Shards {
m[&g.Shards[i]] = struct{}{}
}
}
}
a = make([]ShardInfo, 0, len(m))
for sh := range m {
a = append(a, *sh)
}
return a, nil
}
PrecreateShardGroups
预先创建ShardGroup, 避免在相应时间段数据到达时才创建ShardGroup
// 预先创建ShardGroup, 避免在相应时间段数据到达时才创建ShardGroup
// Influxdb定义了一个Service:Precreator Serivec(services/precreator/service.go),
// 实现比较简单,周期性的调用PrecreateShardGroups,看是否需要创建ShardGroup
// PrecreateShardGroups creates shard groups whose endtime is before the 'to' time passed in, but
// is yet to expire before 'from'. This is to avoid the need for these shards to be created when data
// for the corresponding time range arrives. Shard creation involves Raft consensus, and precreation
// avoids taking the hit at write-time.
func (c *Client) PrecreateShardGroups(from, to time.Time) error {
c.mu.Lock()
defer c.mu.Unlock()
data := c.cacheData.Clone()
var changed bool
// 遍历所有的DatabaseInfo信息
for _, di := range data.Databases {
for _, rp := range di.RetentionPolicies {
if len(rp.ShardGroups) == 0 {
// No data was ever written to this group, or all groups have been deleted.
continue
}
// ShardGroups中的所有ShardGroup已经是按时间排序好的,最后一个也就是最新的一个ShardGroup
g := rp.ShardGroups[len(rp.ShardGroups)-1] // Get the last group in time.
if !g.Deleted() && g.EndTime.Before(to) && g.EndTime.After(from) {
// Group is not deleted, will end before the future time, but is still yet to expire.
// This last check is important, so the system doesn't create shards groups wholly
// in the past.
// Create successive shard group.
// 计算出需要创建的ShardGroup的开始时间
nextShardGroupTime := g.EndTime.Add(1 * time.Nanosecond)
// if it already exists, continue
if sg, _ := data.ShardGroupByTimestamp(di.Name, rp.Name, nextShardGroupTime); sg != nil {
c.logger.Info("Shard group already exists",
logger.ShardGroup(sg.ID),
logger.Database(di.Name),
logger.RetentionPolicy(rp.Name))
continue
}
newGroup, err := createShardGroup(data, di.Name, rp.Name, nextShardGroupTime)
if err != nil {
c.logger.Info("Failed to precreate successive shard group",
zap.Uint64("group_id", g.ID), zap.Error(err))
continue
}
changed = true
c.logger.Info("New shard group successfully precreated",
logger.ShardGroup(newGroup.ID),
logger.Database(di.Name),
logger.RetentionPolicy(rp.Name))
}
}
}
if changed {
if err := c.commit(data); err != nil {
return err
}
}
return nil
}
Influxdb定义了一个Service:Precreator Serivec(services/precreator/service.go),实现比较简单,周期性的调用PrecreateShardGroups,看是否需要创建ShardGroup
// runPrecreation continually checks if resources need precreation.
func (s *Service) runPrecreation() {
defer s.wg.Done()
for {
select {
case <-time.After(s.checkInterval):
if err := s.precreate(time.Now().UTC()); err != nil {
s.Logger.Info("Failed to precreate shards", zap.Error(err))
}
case <-s.done:
s.Logger.Info("Terminating precreation service")
return
}
}
}
Cluster版本中的Meta
整体架构
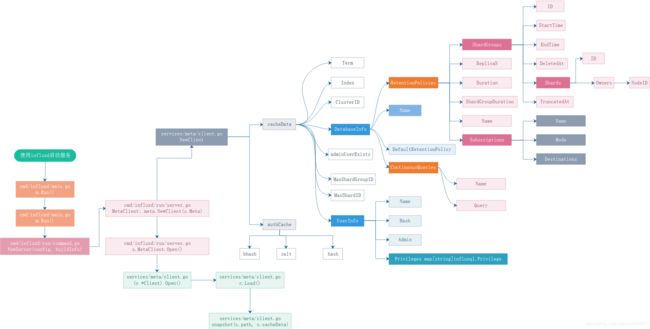
参考
InfluxMeta data分析db的
InfluxDB中文文档
Influxdb原理详解
Influxdb Cluster版本中的Meta
InfluxDB meta文件解析
InfluxDB源码目录结构和数据目结构
饿了么Influxdb实践之路
InfluxDB基本概念和操作