堆溢出个人学习总结
Unlink
ctf wiki中有个地方困扰了我很久:
// fd bk
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
为了绕过fd和bk的检查,资料中说{
但是,如果我们使得 expect value+8 以及 target_addr 等于 P,那么我们就可以执行
- *P= expect value = P - 8
- *P = target addr -12 = P - 12
即改写了指针 P 的内容,将其指向了比自己低 12 的地址处。
}
其实我感觉是有点跳跃了,详细点理解就是:
1、为了让FD->bk == p,就是让*(*(p+8)+12)==p,因此*(p+8)就会等于p-12,换句话说就要让p->fd == p-12
2、同样的,为了让BK->fd == p,就是让*(*(p+12)+8)==p,因此*(p+12)就会等于p-8,换句话说就要让p->bk == p-8
这样就构成了资料中chunk的结构
利用unlink的关键在于构造fake chunk绕过检查后的设置指针指令,即
P->fd->bk = P->bk
P->bk->fd = P->fd因为在检查的时候p->fd->bk和p->bk->fd都指向了p,第二句的执行结果会覆盖第一句的执行结果,因此只需要关注第二句。这样unlink的赋值结果就是将这个chunk的指针修改为p->fd的地址,而由于p->fd通常赋值为p-12(64位下为p-0x18),故套路就自然是将chunk3的指针修改为chunk0,这样以后修改chunk3就相当于修改chunk0。
参考资料:https://ctf-wiki.github.io/ctf-wiki/pwn/linux/heap/unlink/#_2
Use After Free
内存块被释放后,其对应的指针没有被设置为NULL,但是在它下一次使用之前,有代码对这块内存进行了修改,那么当程序再次使用这块内存时,就很有可能会出现奇怪的问题。
一般思路:
通过堆溢出,将system等关键函数的地址覆盖在下一个已经free掉的chunk的某些功能对应的字节处(例如:put,free等),这样由于这个chunk没有被赋值为NULL,还能继续调用其结构中的成员函数,而因为该函数已被system等关键函数覆盖了,实际上就会调用我们想要的函数。
参考资料:https://ctf-wiki.github.io/ctf-wiki/pwn/heap/use_after_free/
Fastbin Double Free
int main(void) {
void *chunk1,*chunk2,*chunk3;
chunk1=malloc(0x10);
chunk2=malloc(0x10);
free(chunk1);
free(chunk2);
free(chunk1);
return 0;
}第一次free :

第二次free :
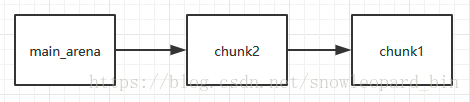
第三次free:

第三次free之后,chunk1的fd都修改指向为chunk2,我们可以通过分配一个堆块chunk1,编辑chunk1的fd,使得仍处在fastbin中的chnk1的fd指向我们想要的地址,这样在chunk1分配后再分配一个堆块,就能指向我们指定的地址。
free后分配chunk1进行编辑后达到的效果:main_arena->chunk2->chunk1->(addr)
int main(void) {
void *chunk1,*chunk2;
chunk1=malloc(0x10);
chunk2=malloc(0x10);
free(chunk1);
free(chunk2);
free(chunk1);
chunk_a = malloc(0x10);//chunk1
*chunk_a = (addr);//看情况
malloc(0x10);//chunk2
malloc(0x10);//chunk1
chunk_b = malloc(0x10);//addr
return 0;
}值得注意的是,_int_malloc会对欲分配位置的 size 域进行验证,如果其 size 与当前 fastbin 链表应有 size 不符就会抛出异常。
Alloc to Stack
该技术的核心点在于劫持 fastbin 链表中 chunk 的 fd 指针,把 fd 指针指向我们想要分配的栈上,从而实现控制栈中的一些关键数据,比如返回地址等。
typedef struct _chunk
{
long long pre_size;
long long size;
long long fd;
long long bk;
} CHUNK,*PCHUNK;
int main(void)
{
CHUNK stack_chunk;
void *chunk1;
void *chunk_a;
stack_chunk.size=0x21;
chunk1=malloc(0x10);
free(chunk1);
*(long long *)chunk1=&stack_chunk;
malloc(0x10);
chunk_a=malloc(0x10);
return 0;
}
首先把chunk1的fd内容指向stack_chunk,而后第一次malloc分配chunk1,第二次malloc就会分配stack_chunk栈上的地址。
注意栈上需要有符合size条件的变量。
Arbitrary Alloc
原理同Alloc to Stack,只是目标地址不止是栈地址,还可以是heap、bss
Arena溢出
修改全局变量global_max_fast,使得所有的size的chunk都放入fastbin,这样当我们free一个size很大的块的时候,就会通过
unsigned int idx = fastbin_index(size);//获取到fastbin的index
fb = &fastbin (av, idx);//fb获取到fastbin相应index的地址,该队列的头指针从main_arena溢出到相应的位置。
常用的方法是修改stdout泄露libc:free大小为0x1651的chunk,使得 _IO_write_base写入该堆块的地址,同时还要free大小为0x1631大小的chunk,使得_IO_read_end与_IO_write_base相同才能输出。注意要先写入_IO_write_base再写_IO_read_end,否则将不能输入。
偏移计算方法:每0x10字节大小的size就会对应8个字节的数组,因此0x1651对应的是0x1650/2=main_arena+0xb28偏移的位置。
另外可以通过修改stdout_vtable_offset = 0x17c1,控制程序流。
_IO_read_ptr = 0x7f4264a516a3 <_IO_2_1_stdout_+131> "\n",
_IO_read_end = 0x5622062ae230 "",
_IO_read_base = 0x7f4264a516a3 <_IO_2_1_stdout_+131> "\n",
_IO_write_base = 0x5622062ae230 "",
_IO_write_ptr = 0x7f4264a516a3 <_IO_2_1_stdout_+131> "\n",
_IO_write_end = 0x7f4264a516a3 <_IO_2_1_stdout_+131> "\n",
_IO_buf_base = 0x7f4264a516a3 <_IO_2_1_stdout_+131> "\n",
_IO_buf_end = 0x7f4264a516a4 <_IO_2_1_stdout_+132> "", 参考资料:
https://ctf-wiki.github.io/ctf-wiki/pwn/heap/fastbin_attack/
后续学习内容,将稍后补充。