Anchor Loss论文学习
论文名称:Anchor Loss: Modulating Loss Scale based on Prediction Difficulty
发布时间:2019.09.24
作者:加州理工
论文地址:https://arxiv.org/abs/1909.11155v1
摘要:
作者提出了一种根据预测难度自动调整cross entropy比例的loss。
在预测结果中,我们只会选择最高置信分作为输出,而不会考量这个目标本身的预测难度。本文的思想是根据正样本与负样本的预测分值的gap,做为预测难度属性,结合难度属性的信息动态的调整loss的比例。
作者主要在分类网络和人体姿态估计网络中试验了这种方法,都取得了不错的效果。
简介
![]() 是anchor probability,anchor loss会参考
是anchor probability,anchor loss会参考![]() 来评价背景类别(不是目标的类别都是背景类别)的难易程度。如果背景类别的分值大于
来评价背景类别(不是目标的类别都是背景类别)的难易程度。如果背景类别的分值大于![]() ,则认为这个背景类别为难学,如果背景类别的分值小于
,则认为这个背景类别为难学,如果背景类别的分值小于![]() ,则认为这个背景类别容易学。
,则认为这个背景类别容易学。
这里![]() 一般会使用正确类别的预测分值。
一般会使用正确类别的预测分值。

因为左右身体的对称性,网络常常很难区分左右,或者说网络对于相似的物体比较难区分。虽然在正确类别上的分值可能也不低,但是最终会取最高的分值,可能导致预测错误。AL就是要对类别预测错误,并且有比较高的分值时,给更多的惩罚。左图如果背景倍识别为某个类别,AL与CE的比较曲线。可以看出当预测分值大于0.5后loss会很快的增加,这样对于预测错误的高分值有很快的抑制作用。

本文本文的主要贡献是:
方法介绍
Anchor Loss

分类网络的应用
为了应用AL,这里会使用sigmoid-binary cross entropy作为基础loss。sigmoid-binary cross entropy loss是用来做多标签识别任务,可以判断一张图片中有哪些物体,将每个类别作为二分类进行学习。

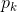 代表
k
类别的标签,
代表
k
类别的标签, -delta
,
t
代表
-delta
,
t
代表 =1
对应的
index
,
delta=0.05
,就是说
代表正样本的分值。增加
delta
是为了考虑当正负样本分值一样的时候增加一点惩罚。
=1
对应的
index
,
delta=0.05
,就是说
代表正样本的分值。增加
delta
是为了考虑当正负样本分值一样的时候增加一点惩罚。

比如上面这个例子,如果按照公式计算,class1就是简单案例,负样本前的权重不考虑delta是1+0.25-0.75=0.5.class2是临界值的例子,这里会增加一个delta微微增加惩罚,所以前面的权重是1.05.class3和class4就是难例,不考虑delta的话前面的权重是1+0.75-0.25=1.5,1+0.9-0.1=1.8.显而易见,对难例增加了惩罚。
人体姿态估计的应用
人体姿态估计是要识别人体的关键点,与以前方法一样,对每个关键点做一个高斯分布的真值。Anchor Loss只应用在 =0的位置,就是高斯范围内的负样本不使用。因此可以做一个Mask来判定那些像素位置使用Anchor Loss。
=0的位置,就是高斯范围内的负样本不使用。因此可以做一个Mask来判定那些像素位置使用Anchor Loss。


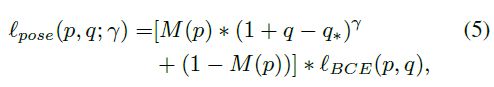
与其他loss函数的关系
Anchor Loss与Focal Loss,binary cross entropy之间的关系。

![]() 代表的是真实类别的预测值,如果
代表的是真实类别的预测值,如果![]() =1,FL可以更新为
=1,FL可以更新为
![]()
此时FL与Anchor Loss等同。
再如果=0,那么就等同于binary cross entropy。FL也等同于CE
梯度分析
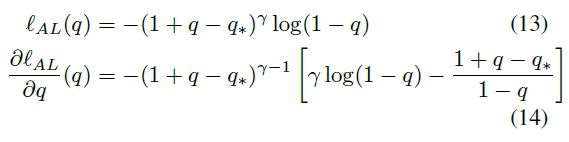

从以上比较可以看出AL比FL更灵活,会在不同的范围loss和梯度都有不同的变化。
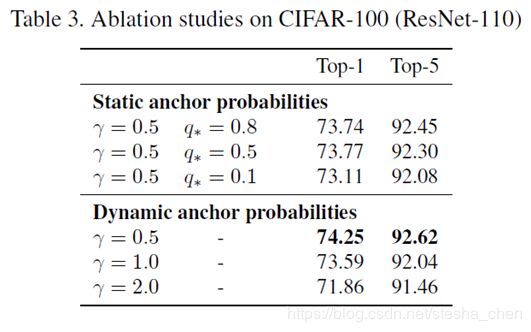
实验
图像分类

人体姿态估计
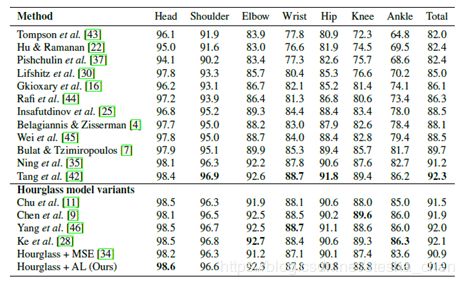
上图是MPII数据集的验证结果

上图是PCK数据集的验证结果

AL与MSE对比试验

超参数的选择试验

第一行左边是MSE loss,右边是Anchor Loss
第二行是预测人体另一半稍微遮挡的效果
总结
本文提出了一种新颖的Loss,叫做Anchor Loss。Anchor Loss会考虑预测难度来调整CE loss的权重。并且作者在图像分类和人体姿态识别问题中都验证了Anchor Loss的有效性。
作者设计的权重有点想早期的Hinge Loss,但是Hinge Loss会有一个margin,比如它会希望正样本的预测值比负样本的预测值高出一个margin,margin可以设置为0.1,0.2之类。本文的loss或许也可以尝试增加个margin,但是是否有效还需要看实验效果。