突破淘宝登录滑块验证反爬,防止识别为Chrome自动控制
文章首发于慕课网手记,已同步到个人博客:https://www.donlex.cn
上次的文章《在爬100万数据的时候,我发现了爬虫的进阶之路》 ,有“怂恿”大家伙去突破淘宝的登录反爬,不知道有没有试了的。反正我是试了,也找到了三种方法。在这里分享一下
- 账号密码登录(有滑块)
- 微博第三方账号登录(无滑块)
- 扫码登录
上面都是使用 Selenium 进行模拟登录的,这样就可以不用手动添加各种Cookie或者Session,少了很多工作。
# 淘宝账号登录
一般直接使用Selenium自动控制登录,都会无法通过滑块验证。所以解决的策略就是让这些网站识别不出来你是用了Selenium,因此需要将模拟浏览器设置为开发者模式,这样就可以防止被网站识别出来。
只需要在初始化时,添加下面这条语句,就可以设置为开发者模式。
# 此步骤很重要
options.add_experimental_option('excludeSwitches'['enable-automation'])
browser = webdriver.Chrome(options=options)
只需要多加一行代码,就能突破淘宝登录滑块,效果如下:

当然这只是让Selenium通过淘宝的滑块验证而已,至于如何滑动还是需要自己动手撸代码才能实现真正的自动。。。
# 微博账号登录
在淘宝网的登录页面,有第三方登录的入口,试了一下,发现绑定微博的账号跟淘宝更配哦。直接通过Selenium控制,输入微博账号和密码,不需要滑块验证,不需要滑块验证,不需要滑块验证(重要的事情说**,直接就可以登录。

# 扫码登录
还有一种方法:扫码登录,这种方式检测出是使用自动化工具,但是扫码登录能减去所有的验证环节,并且不需要写登录代码,只需要在扫码的页面停留几秒,等待手机淘宝扫码验证完成。接着就可以继续下面的工作了,不过这有一个缺点,就是不能设置不加载图片,如果设置了不加载图片的话,二维码就显示不了,就别谈登录了,这样一来,爬取的速度肯定会受到影响。
代码:
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(5)
def scan_login(url):
driver.get(url)
# 等待扫码登录
sleep(15)
# 进入之后开始其他操作
if __name__ == '__main__':
url = 'https://login.taobao.com/member/login.jhtml'
scan_login(url)
效果:
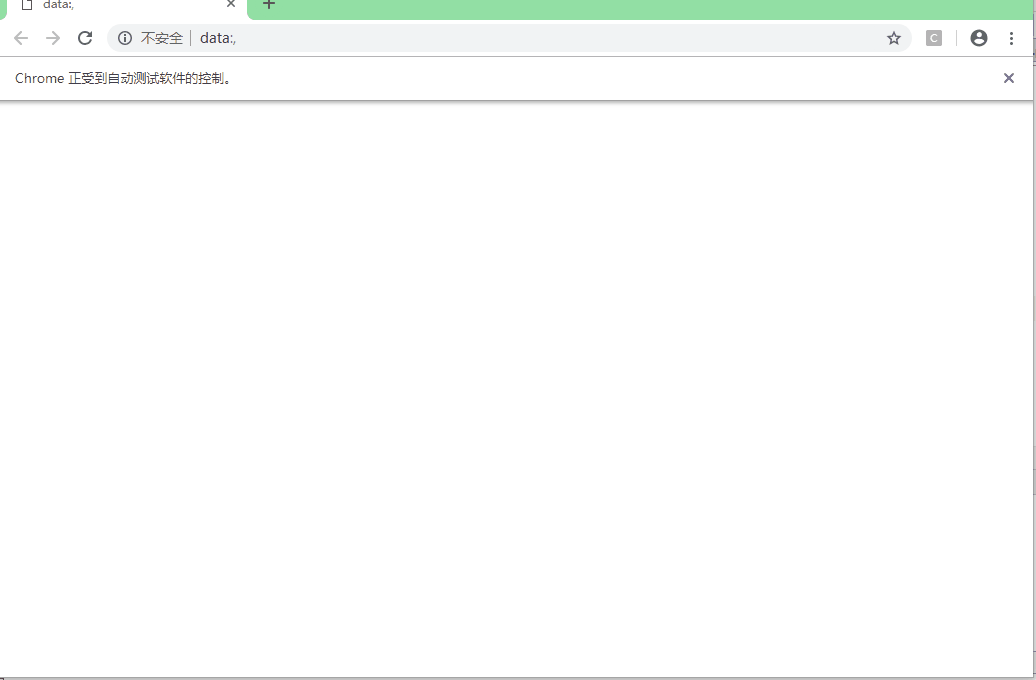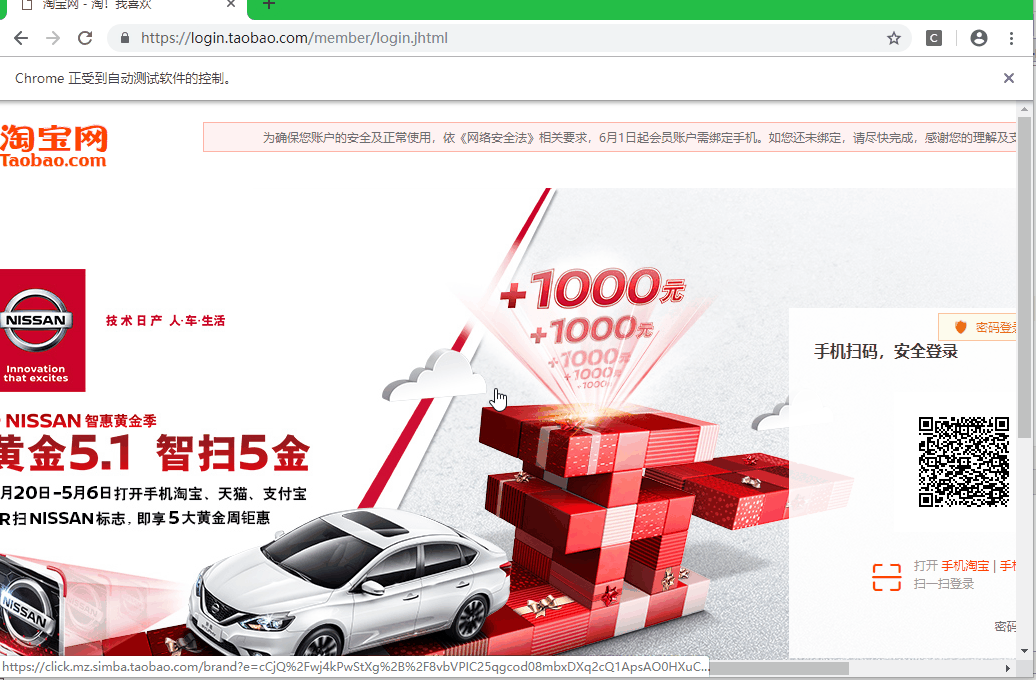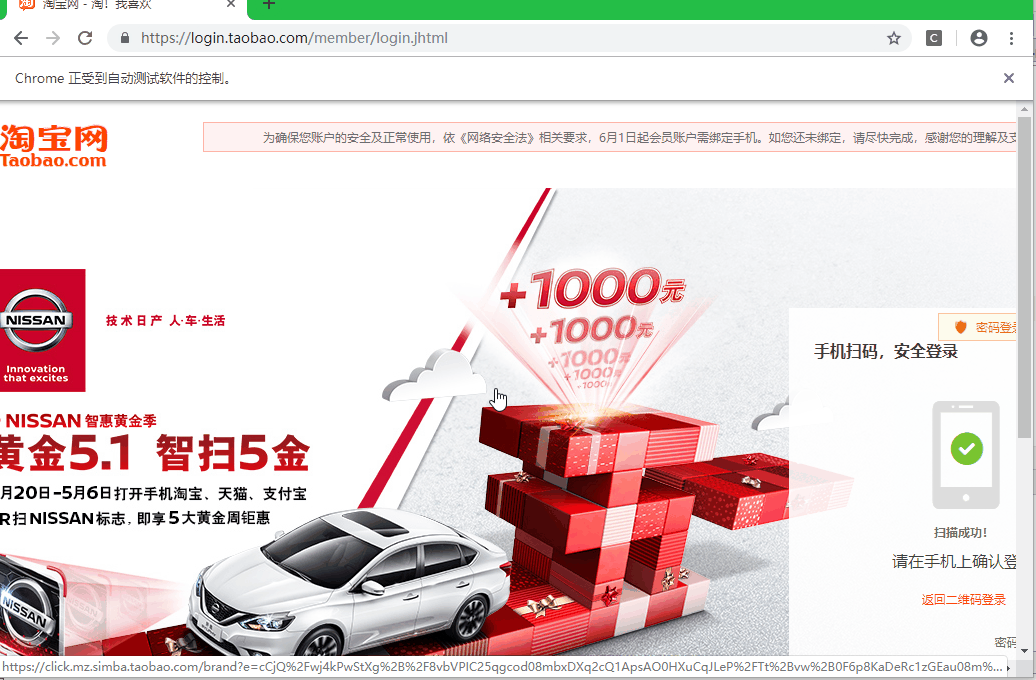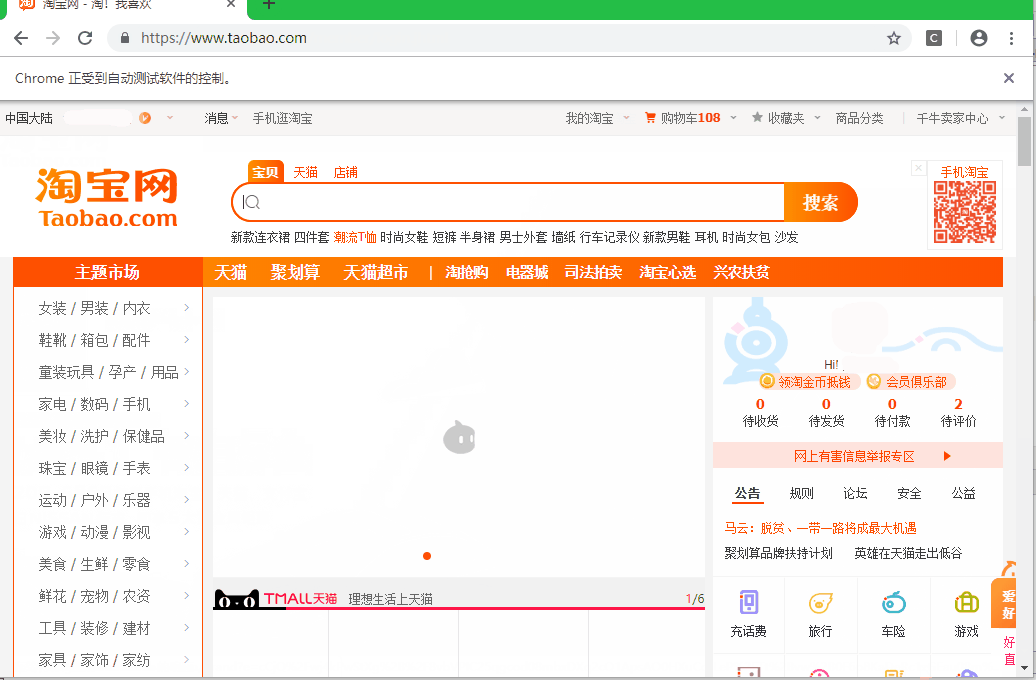
# 最后
个人感觉在需要突破登录部分的反爬措施,直接使用 Selenium 是最通用的,当然得看具体的情况。如果你正在练习登录这方面的爬虫,希望能够对你帮助!如果你有好的方法,也可以后台交流一下!
ps:文中部分代码点击『阅读原文』获取;仅供技术交流使用,请不要用作其他用途!
# 附:
点击获取,源码地址
如果对你有帮助记得Star!