新视角带你认识Python可视化库(附代码&资源)

作者:Dan Saber
翻译:笪洁琼
校对:梁傅淇
本文约16196字,建议阅读20+分钟。
本文中,作者借助拟人化的形式,让Python中值得一提的可视化库共同出演了一出戏剧,形象、生动地展现了不同可视化库的特点。
本文最初发表于丹·萨伯的博客(https://dsaber.com/2016/10/02/a-dramatic-tour-through-pythons-data-visualization-landscape-including-ggplot-and-altair/)我们觉得很有意思,所以问他是否可以转载,他慷慨地答应了!
关于丹:我叫丹·萨伯。我毕业于加州大学洛杉矶分校的数学系,我在Coursera上从事数据科学工作(在此之前,我在金融行业工作)。我喜欢写作、音乐、编程,还有——经过美国教育系统的最佳培训——统计。

为什么还要去尝试,朋友们?
最近,我尝试了Brian Granger和 Jake VanderPlas开发的Altair,这是一个新的、很有前景的可视化库。Altair库似乎能够满足Python用户对于ggplot库的需求,而且它建立在JavaScript的Vega-Lite语法规范之上,随着后者开发新的功能(例如:工具提示和缩放),Altair也能受益——而且毫不费力!
事实上,我对Altair库印象是如此深刻以至于这篇文章最初的主题是:“哟,用Altair吧!”
然后我开始反思自己使用Python来进行可视化的编码习惯,经过痛苦的自我反省,之后,我意识到我自己总是以任务为标准来采用一堆杂七杂八的工具和杂乱的技术之中(通常是我第一次用来完成这个任务的库) 。
这并不好。就像老话说的那样:“ 未经检验的图表不值得导出成PNG格式。”
因此,我将Altair库放到一个次要的位置——用以探索Python的统计可视化工具是如何结合在一起的。我希望这次探索对你也有帮助。
接下来如何做?
这篇文章的构思将会是:“你要做事件X,你要如何使用matplotlib、Pandas库/ Seaborn库/ ggpy库/ Altair库做事件X?”在使用不同的工具做事件X的情况下,我们将列出一个合理的利弊列表,或者至少是一串可能有用的代码。
(警告:这一切都可能以两幕剧的形式出现。)
工具(按照主观感觉按复杂度降序排序)
首先,欢迎我们的朋友们:
Matplotlib库
http://matplotlib.org/
这只重达800磅的大猩猩,和大多数800磅重的大猩猩一样,除非你真的需要它的力量,比如说制作一个定制化的或可供出版的图表,否则我们应该避免使用它来。
(正如我们将看到的,当涉及到统计可视化时,首选的方法可能是:“使用舒适的工具,比如以下要谈到的四个工具轻松地做尽可能多的事情,然后用matplotlib做剩下的事情”。)
Pandas库
http://pandas.pydata.org/pandas-docs/stable/visualization.html
“为了数据框而来,为被比其所取代的matplotlib编码要令人愉悦的便利的可视化函数而留下。”。——未被采用的Pandas标语
(花边新闻:Pandas开发团队里面一定包括一些可视化迷,因为这个库中包含了像RadViz图还有Andrews曲线这样我在其他地方都没有看到过的东西。)
Seaborn库
http://seaborn.pydata.org/
Seaborn库长期以来一直是我常用的数据可视化库;它自我总结道:
“如果matplotlib’试图让简单的事情变得更加容易,困难的事情变得可能’,那么Seaborn库则是试图将一套明确定义的复杂的东西也变得简单起来。”
yhat的ggpy库
https://github.com/yhat/ggpy
非常棒的声明式ggplot2库在Python中的实现,这并非一个“ggplot2的特性一对一移植”,而是在原功能的基础上有很强的增强。
(作为一名偶尔使用R的用户,我认为主要的geoms功能基本都实现了。)
Altair库
https://github.com/ellisonbg/altair
一个新东西,Altair是一个带有使用体验令人非常棒的应用程序接口的“声明式统计可视化库”。
太棒了。现在我们的客人已经抵达并且放好了他们的外套,让我们安稳地坐下来,开始我们的晚餐谈话吧。我们的节目已经开场了......
Python可视化库的小剧场(所有的库都出演它自己)
第一幕:线条和圆点
(在场景1中,我们将处理一个名为ts的“整洁”数据集。它由三列组成:一个dt列(date:日期);value列(值);还有一个kind列,它有四个不同的水平:A、B、C和D,数据集长这个样子:)
dt |
kind |
value |
|
0 |
2000-01-01 |
A |
1.442521 |
1 |
2000-01-02 |
A |
1.981290 |
2 |
2000-01-03 |
A |
1.586494 |
3 |
2000-01-04 |
A |
1.378969 |
4 |
2000-01-05 |
A |
-0.277937 |
场景1:你如何在同一张图上绘制多个时间序列?
Matplotlib(MPL):哈!哈哈!简直不能更简单了。虽然我可以用许多复杂的方法来完成这项任务,但我知道,你们那脆弱的大脑会在他们精巧的重压下崩溃。因此,我将其简化,向你们展示两个简单的方法。在第一种方法中,我循环使用你们虚构的矩阵——我相信你们这些家伙把它叫做“数据”“框架”——并将其子集传递给相关的时间序列。接下来,我调用plot方法,传入该子集中的相关列。
# MATPLOTLIB
fig, ax = plt.subplots(1, 1,
figsize=(7.5, 5))
for k in ts.kind.unique():
tmp = ts[ts.kind == k]
ax.plot(tmp.dt, tmp.value, label=k)
ax.set(xlabel='Date',
ylabel='Value',
title='Random Timeseries')
ax.legend(loc=2)
fig.autofmt_xdate()
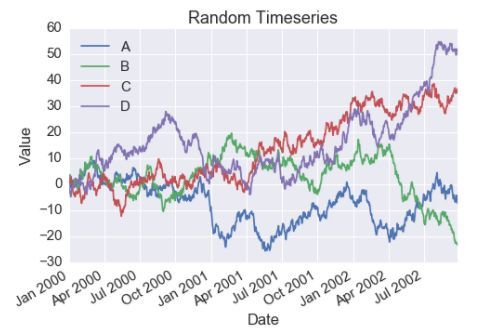
MPL:接下来,我让这个大笨蛋(指了指Pandas)把这个“数据”的“框架”做轴向旋转,之后它就长这个样子......
# the notion of a tidy dataframe matters not here(Markdown 代码编辑部分)
dfp = ts.pivot(index='dt', columns='kind', values='value')
dfp.head()
kind |
A |
B |
C |
D |
dt |
||||
2000-01-01 |
1.442521 |
1.808741 |
0.437415 |
0.096980 |
2000-01-02 |
1.981290 |
2.277020 |
0.706127 |
-1.523108 |
2000-01-03 |
1.586494 |
3.474392 |
1.358063 |
-3.100735 |
2000-01-04 |
1.378969 |
2.906132 |
0.262223 |
-2.660599 |
2000-01-05 |
-0.277937 |
3.489553 |
0.796743 |
-3.417402 |
MPL:通过将数据转换为一个包含4列的索引——每一列代表一条我想画出的线——我可以一下子完成所有的事情(例如,调用一次我的“绘图”功能)。
# MATPLOTLIB
fig, ax = plt.subplots(1, 1,
figsize=(7.5, 5))
ax.plot(dfp)
ax.set(xlabel='Date',
ylabel='Value',
title='Random Timeseries')
ax.legend(dfp.columns, loc=2)
fig.autofmt_xdate()

Pandas(看起来很胆小):太好了,Mat,真的很棒。感谢你提到我。我也做同样的事——希望能跟你一样好?(弱弱地微笑)
# PANDAS
fig, ax = plt.subplots(1, 1,
figsize=(7.5, 5))
dfp.plot(ax=ax)
ax.set(xlabel='Date',
ylabel='Value',
title='Random Timeseries')
ax.legend(loc=2)
fig.autofmt_xdate()
Pandas:看起来完全一样,所以我就不展示了。
Seaborn(抽一支烟,调整着贝雷帽):嗯。区区一个折线图就让你们做了这么多的数据处理。我的意思是,for循环和旋转?这不是90年代微软的Excel。我在国外的时候有学到一个被称为“FacetGrid”的东西。你们可能从未听说过。
# SEABORN(代码部分)
g = sns.FacetGrid(ts, hue='kind', size=5, aspect=1.5)
g.map(plt.plot, 'dt', 'value').add_legend()
g.ax.set(xlabel='Date',
ylabel='Value',
title='Random Timeseries')
g.fig.autofmt_xdate()

SB:看到没?你把未处理的“整洁”数据交给了FacetGrid。在这时,将kind传递给hue参数,意味着你将绘制四条不同的行——一一对应于kind字段中的每一个水平。而你要实际上去画出这四条不同的线,就得把是把我的FacetGrid映射到这个庸人(示意matplotlib)的plot函数,并传递x和y参数。显然,你得记住一些东西,就像添加图例一样,但是也不会太难。好吧,对我们中间有些人来说,没有什么东西有挑战性……
Ggpy(GG):哇,整洁!我也做过类似的事情,但我做的方式像我的大哥哥。你听说过他吗?非常酷——
SB:谁邀请了那个孩子?
GG:让我们来看看吧!
# GGPY
fig, ax = plt.subplots(1, 1, figsize=(7.5, 5))
g = ggplot(ts, aes(x='dt', y='value', color='kind')) + \
geom_line(size=2.0) + \
xlab('Date') + \
ylab('Value') + \
ggtitle('Random Timeseries')
g

GG(拿起 Hadley Wickham 写的 《ggplot2》读出声来):每一幅图都由数据(比如 ts),图形映射(比如 x,y 和 color)和几何图形(比如 geom_line)组成,而后者将数据和图形映射转换成真正的可视化。
Altair:是的,我也这么做。
# ALTAIR
c = Chart(ts).mark_line().encode(
x='dt',
y='value',
color='kind')
c

ALT:你给我Chart类一些数据,告诉它你想要什么样的视觉效果:这里是“mark_line”。接下来,你将指定图形映射:我们的x轴对应 “date”,y轴对应“value”;我们想要以kind进行分组,所以我们将“kind”传递给“color”。就像你一样,GG(弄乱GG的头发)。哦,顺便说一下,采用和你们同样的配色方案也不是问题。
# ALTAIR
# cp corresponds to Seaborn's standard color palette
c = Chart(ts).mark_line().encode(
x='dt',
y='value',
color=Color('kind', scale=Scale(range=cp.as_hex())))
c

MPL害怕又惊讶地凝视着。
分析场景1
除了Matplotlib头脑简单以外,还有一些主题出现了:
在 Matplotlib库和Pandas库中,你必须对“plot”函数进行多次调用(例如,在每个for循环里),要么你就得对数据进行处理才能更好适用于 plot 函数(比如轴向旋转)。(也就是说,我们在第二场景中会看到另一种技术。)
(坦白地说,我从来没想过这是件大事,但后来我遇到了使用R的人,他们对这种操作都惊呆了。)
相反地,ggplot 和 Altair 用的是类似声明式“图形语法”的方法去解决这种简单问题:给“主”函数 (ggplot 中的 ggplot 和 Altair 中的 Chart)传入整洁的数据集。然后定义一组图形映射(x,y 和 color)来说明数据该如何映射到图形上(比如视觉标记做了很多努力以便更好地传达信息)。
只要使用这些图形(ggplot 的 geom_line 和 Altair 的 mark_line),数据和图形映射就会被转换成便于人类理解的视觉形象,这样一来就大功告成了。
实际上,你可以——而且可能应该(?)——透过同样的视角看待 Seaborn 的 FacetGrit;但是并不是完全一致。FacetGrid 除了数据集之外还需要预先提供 hue 参数,然后才需要 x 和 y 参数。这种映射并不是图形映射,只是函数映射:数据集中的每一个 hue 都会调用 matplotlib 的 plot 函数,dt 和 value 分别传给 x 和 y 参数。for 循环是不可见的底层实现。
也就是说,尽管图形映射需要两个独立的步骤,比起命令式的思维方式,我还是更喜欢图形映射(至少在画图时如此)。
数据说明
(在场景2到场景4,我们将处理著名的“iris”数据集,尽管我们在代码中称它为“df”。它由四个数字列组成,对应不同的测量值,以及一个表明它对应于三种鸢尾花中哪一种的类别列。数据长这样......)
petalLength |
petalWidth |
sepalLength |
sepalWidth |
species |
|
0 |
1.4 |
0.2 |
5.1 |
3.5 |
setosa |
1 |
1.4 |
0.2 |
4.9 |
3.0 |
setosa |
2 |
1.3 |
0.2 |
4.7 |
3.2 |
setosa |
3 |
1.5 |
0.2 |
4.6 |
3.1 |
setosa |
4 |
1.4 |
0.2 |
5.0 |
3.6 |
setosa |
场景2:你如何制作一个散点图?
MPL(看起来有点震惊):我的意思是,你可以再次用for循环。当然,这样就可以了。当然可以。看到了吗?(降低声音说)只要记得明确地设置颜色参数否则这些点都是蓝色的......
# MATPLOTLIB
fig, ax = plt.subplots(1, 1, figsize=(7.5, 7.5))
for i, s in enumerate(df.species.unique()):
tmp = df[df.species == s]
ax.scatter(tmp.petalLength, tmp.petalWidth,
label=s, color=cp[i])
ax.set(xlabel='Petal Length',
ylabel='Petal Width',
title='Petal Width v. Length -- by Species')
ax.legend(loc=2)

MPL:但是,额,(假装很自信)我有个更好的方法!看!
# MATPLOTLIB
fig, ax = plt.subplots(1, 1, figsize=(7.5, 7.5))
def scatter(group):
plt.plot(group['petalLength'],
group['petalWidth'],
'o', label=group.name)
df.groupby('species').apply(scatter)
ax.set(xlabel='Petal Length',
ylabel='Petal Width',
title='Petal Width v. Length -- by Species')
ax.legend(loc=2)

MPL:这里,我定义了一个名为scatter的函数。它用 pandas 的 groupby 对象得到分组,然后在 x 轴上画出花瓣长度,y 轴则是花瓣宽度。每组都如此处理一次!厉害吧!
P:太好了,Mat!太棒了!本质上,我要做的事情是一样的,所以我就不展示了。
SB(咧嘴笑):这次没有轴向旋转?
P:嗯,在这种情况下,轴向旋转是复杂的。我们不像处理时间序列数据集的时候一样有一个通用的索引,所以——
MPL:嘘!我们不需要向她解释。
SB:不管。不管怎样,在我看来,这个问题和上一个问题是一样的。构建另一个FacetGrid,但借用plt.scatter而非plt.plot。
# SEABORN(代码部分)
g = sns.FacetGrid(df, hue='species', size=7.5)
g.map(plt.scatter, 'petalLength', 'petalWidth').add_legend()
g.ax.set_title('Petal Width v. Length -- by Species')

GG:是的!是的!同样!你只要把geom_line换成geom_point就行了!
# GGPY
g = ggplot(df, aes(x='petalLength',
y='petalWidth',
color='species')) + \
geom_point(size=40.0) + \
ggtitle('Petal Width v. Length -- by Species')
g
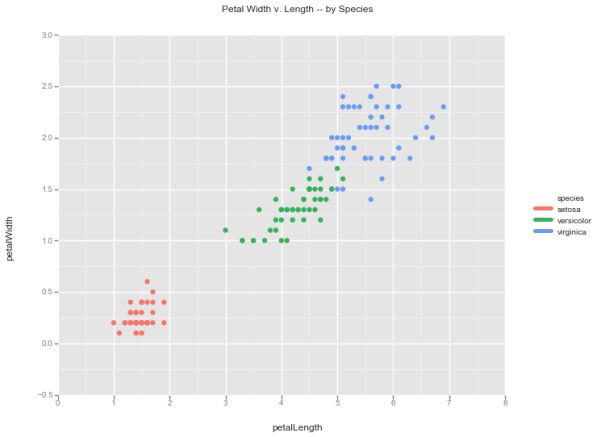
ALT(看起来很困惑):是的,把我们的mark_line换成mark_point。
# ALTAIR
c = Chart(df).mark_point(filled=True).encode(
x='petalLength',
y='petalWidth',
color='species')
c
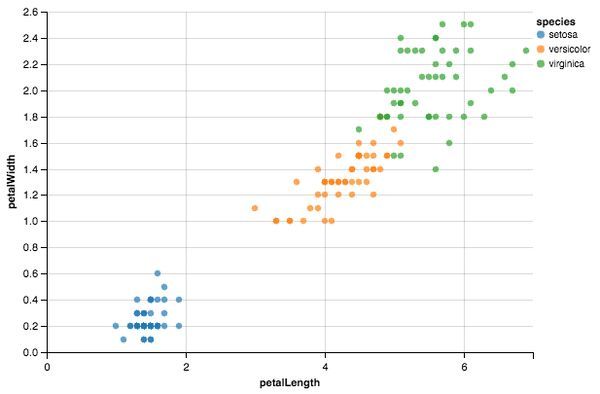
分析场景2
在这里,从你的数据之中构建API的潜在的复杂性变得清晰了。虽然Pandas的旋转技巧对于时间序列来说是非常方便的,但它在这个例子中并不能很好地应用。
公平地说,group by方法是具有普适性的,而for循环方法的普适性很强;然而,它们需要更多的自定义逻辑,而自定义逻辑需要自定义工作: Seaborn已经做好了,要不然你还得自己造个轮子。
相反,Seaborn、ggpy和Altair都意识到,散点图很大程度上就是没有假设的折线图(不管这些假设是多么的无害)。因此,我们在场景1中的代码可以很大程度上被重用,但是使用新的geom(ggpy/altair的geom_point/mark_point)
或新方法(Seaborn的plt.scatter)。在这个组合中,似乎哪一个工具表现得比其他的便利更多,尽管我喜欢Altair的优雅简洁。
场景三:你将如何画分面的散点图?
MPL:嗯,一旦你掌握了for循环——显然我已经掌握了——那么这就只需要对我之前的代码做出一个的简单调整。我不是用我的subplot方法构建一个坐标轴,而是构建三个。
接下来,我像以前一样遍历一遍,采用取数据子集的办法来取Axes对象的子集
(信心恢复)我敢打赌你们之中没人能提出一个更简单的方法——举起手臂,在这一过程中几乎击中了Pandas。
# MATPLOTLIB
fig, ax = plt.subplots(1, 3, figsize=(15, 5))
for i, s in enumerate(df.species.unique()):
tmp = df[df.species == s]
ax[i].scatter(tmp.petalLength, tmp.petalWidth, c=cp[i])
ax[i].set(xlabel='Petal Length',
ylabel='Petal Width',
title=s)
fig.tight_layout()

SB和ALT对视了一眼,ALT开始笑了;GG仿佛像听见什么笑话一样大笑起来。
MPL:怎么了?
Altair:检查你的x轴和y轴,老兄。你所有的图表的坐标轴取值范围都不一样。
MPL(脸变红了):啊,当然,这只是确认你们是否集中注意力的一个测试。你可以,呃,通过在subplot函数中指定坐标轴范围,来确保所有的子图中坐标轴都有相同的范围。
# MATPLOTLIB
fig, ax = plt.subplots(1, 3, figsize=(15, 5),
sharex=True, sharey=True)
for i, s in enumerate(df.species.unique()):
tmp = df[df.species == s]
ax[i].scatter(tmp.petalLength,
tmp.petalWidth,
c=cp[i])
ax[i].set(xlabel='Petal Length',
ylabel='Petal Width',
title=s)
fig.tight_layout()

P(叹息):我也会这么做。跳过我吧。
SB:改写FacetGrid以应用于这种情况很简单。就像hue参数一样,我们可以简单地添加一个“col”参数。这会让FacetGrid不仅为每个种类分配了一种唯一的颜色,而且还将每个种类画在唯一的子图上,按列排列。(我们可以通过将col参数换成row参数,就可以按行来排列它们)
# SEABORN
g = sns.FacetGrid(df, col='species', hue='species', size=5)
g.map(plt.scatter, 'petalLength', 'petalWidth')

GG:哦,这和我做的不一样。(再次拿起ggplot2开始读)看,分面和图形映射本质上是两个不同的步骤,我们不应该一时疏忽把它们混为一谈。因此,我们接着用之前的代码,这次加上 facet_grid 层,也就是显式地用类别进行分面。(开心地合上书)至少我大哥是这么说的!你们听说过他吗?他真酷啊。
# GGPY
g = ggplot(df, aes(x='petalLength',
y='petalWidth',
color='species')) + \
facet_grid(y='species') + \
geom_point(size=40.0)
g

ALT:我在这里采用了一种类似于Seaborn的方式。具体来说,我只是在encode函数中加入一个column参数。也就是说,我在这里也做了一些新东西:
(A)虽然 column 参数可以接受一个简单的字符串变量,但我实际上传给它的是 Column 对象,如此我可以自定义标题了;
(B)我用了configure_cell 方法,如果不用的话,子图会变得太大了。
# ALTAIR
c = Chart(df).mark_point().encode(
x='petalLength',
y='petalWidth',
color='species',
column=Column('species',
title='Petal Width v. Length by Species'))
c.configure_cell(height=300, width=300)
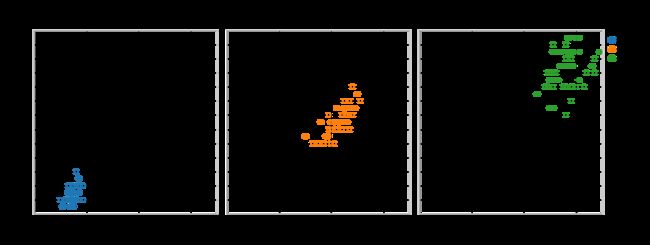
分析场景3
Matplotlib说得很好:在这种情况下,他的代码根据分类对数据进行分面的思路和上面的其他方案是一样的;假如你的脑袋可以搞清楚那些 for 循环的话,你可以再试试下面这段代码。但是我可没有让他再搞出更复杂的东西出来,比如 2 x 3 的网格。不然他就得像下面这样干:
# MATPLOTLIB
fig, ax = plt.subplots(2, 3, figsize=(15, 10), sharex=True, sharey=True)
# this is preposterous -- don't do thisfor i, s in enumerate(df.species.unique()):
for j, r in enumerate(df.random_factor.sort_values().unique()):
tmp = df[(df.species == s) & (df.random_factor == r)]
ax[j][i].scatter(tmp.petalLength,
tmp.petalWidth,
c=cp[i+j])
ax[j][i].set(xlabel='Petal Length',
ylabel='Petal Width',
title=s + '--' + r)
fig.tight_layout()

使用正规的可视化表达:使用Altair的话,这一切都会非常简单:
# ALTAIR
c = Chart(df).mark_point().encode(
x='petalLength',
y='petalWidth',
color='species',
column=Column('species',
title='Petal Width v. Length by Species'),
row='random_factor')
c.configure_cell(height=200, width=200)

只比上面的encode函数多一个参数!
希望在你的可视化库框架中植入分面功能的好处已经明晰了。
第二幕:分布和条形图
场景四:你会如何可视化数据分布?
MPL(信心明显动摇):嗯,如果我们想要一个箱形图——我们想要一个箱形图吗?
——我有一个方法。它很愚蠢,你会讨厌它:我将数组组成的数组传递到boxplot方法中,这就会为每个子数组生成一个箱线图。你得自己手动给X轴标刻度。
# MATPLOTLIB
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
ax.boxplot([df[df.species == s]['petalWidth'].values
for s in df.species.unique()])
ax.set(xticklabels=df.species.unique(),
xlabel='Species',
ylabel='Petal Width',
title='Distribution of Petal Width by Species')

MPL:如果我们想要一个直方图——我们想要一个直方图吗?我也有一个方法,你可以用之前提到的for循环或group by来生成。
# MATPLOTLIB
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
for i, s in enumerate(df.species.unique()):
tmp = df[df.species == s]
ax.hist(tmp.petalWidth, label=s, alpha=.8)
ax.set(xlabel='Petal Width',
ylabel='Frequency',
title='Distribution of Petal Width by Species')
ax.legend(loc=1)

P(看起来异常自豪):哈!哈哈哈!这是我的时刻!你们都以为我不过是matplotlib库的附庸,虽然我到目前为止还只是套用他的plot方法,但我也有一些能够处理箱型图和直方图的函数——这些都使得可视化数据分布变得非常简单。
你只需要两个东西:
(A)你想用以分类的列名;
(B)你想用以统计分布的列名。将它们作为“by”和“column”的参数输入,你就立刻可以画出来!
# PANDAS
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
df.boxplot(column='petalWidth', by='species', ax=ax)

# PANDAS
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
df.hist(column='petalWidth', by='species', grid=None, ax=ax)
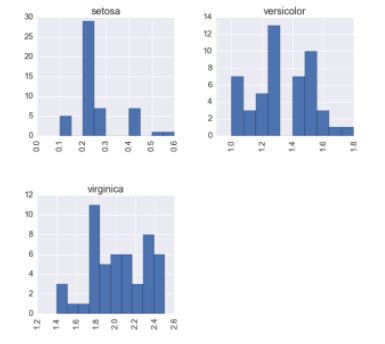
GG和ALT击掌祝贺P:“太棒了!”,“就该这样!”,“就这么干!”。
SB(假装热情):哇。很棒。在我的世界里,分布非常重要,所以我为它们准备了一些特殊的函数。例如,我的boxplot方法需要一个x参数、一个y参数和数据,结果如下:
# SEABORN
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
g = sns.boxplot('species', 'petalWidth', data=df, ax=ax)
g.set(title='Distribution of Petal Width by Species')

SB:这个,我是说,有些人告诉我这个很漂亮……不管了。我还有一种特殊的分布方法,叫做“distplot”,它超越了直方图(傲慢地看着Pandas)。你可以用它来画直方图,KDEs,和轴须图(rugplots),甚至是画到一块。比如说,通过与FacetGrid结合,我可以为每一种鸢尾花都画出直方轴须图:
# SEABORN
g = sns.FacetGrid(df, hue='species', size=7.5)
g.map(sns.distplot, 'petalWidth', bins=10,
kde=False, rug=True).add_legend()
g.set(xlabel='Petal Width',
ylabel='Frequency',
title='Distribution of Petal Width by Species')

SB:但是......不管了。
GG:这个只不过是新的geom而已!用GEOM_BOXPLOT来画箱型图,用GEOM_HISTOGRAM来画直方图!换用它们就可以了!(开始绕着餐桌跑来跑去)
# GGPY
g = ggplot(df, aes(x='species',
y='petalWidth',
fill='species')) + \
geom_boxplot() + \
ggtitle('Distribution of Petal Width by Species')
g
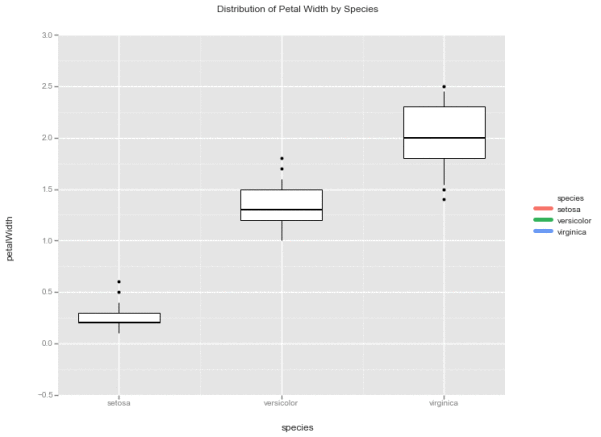
# GGPY
g = ggplot(df, aes(x='petalWidth',
fill='species')) + \
geom_histogram() + \
ylab('Frequency') + \
ggtitle('Distribution of Petal Width by Species')
g

ALT(看起来很有信心和自信):我……我要忏悔……
沉默降临——GG停止奔跑,使得盘子掉到了地上。
ALT:(深呼吸)我……我……我不能做箱型图。我从来没有真正学会怎么画,但是我相信我的源语言JavaScript的语法不支持箱型图是有理由的。我倒是可以画一个均值直方图。
# ALTAIR
c = Chart(df).mark_bar(opacity=.75).encode(
x=X('petalWidth', bin=Bin(maxbins=30)),
y='count(*)',
color=Color('species', scale=Scale(range=cp.as_hex())))
c
ALT:乍一看,代码可能很奇怪,但不要惊慌。这实际上是说,直方图实际上就是条形图。X轴对应着间距,我们可以用Bin类来定义;与此同时Y轴对应落入相应间距的数据量,用SQL语言来说,就是y就是“count(*)”。
分析场景四
在工作中,我发现pandas库的功能非常便利方便;然而,我承认确实有一些记忆上的负担,那就是pandas库制作箱型图和直方图时包含参数“by”,但折线图却没有。
我将第1幕与第2幕分开的原因有几个,其中最重要的原因是:第2幕中使用matplotlib库的时候特别麻烦。例如,当你想要一个箱型图的时候,你还得记得用一个独立的界面,这完全不适合我。
说到第一幕和第二幕,有一个有趣的故事:我实际上是它丰富的“专利级”可视化函数(如,displot,小提琴图,回归图等)才从matplotlib/pandas库转向Seaborn的。虽然后来我喜欢上了FacetGrid,但我坚持认为第2幕所呈现的这些功能才是Seaborn的杀手锏。只要我还在绘图,我就还是Seaborn的粉丝。
(此外,我需要说明:Seaborn实现了很多被小型库忽略的极好的可视化功能;如果你正好需要其中一两种,那么Seaborn就是你唯一的选择。)
这些例子真的能够让你体会到ggpy的geom系统的力量。使用几乎相同的代码(更重要的是,连思维过程都基本相同),我们创建了一个完全不同的图。我们不是通过调用一个完全独立的函数,而仅仅是改变图形映射到视图的方式,比如说将geom换成另一个。
类似地,即使是在第二幕的世界里,Altair库的API接口也具有非同寻常的一致性。即使是对于不太寻常的操作操作,Altair库的API接口也很简单、优雅,令人印象深刻。
数据说明
survived |
pclass |
sex |
age |
fare |
class |
|
0 |
0 |
3 |
male |
22.0 |
7.2500 |
Third |
1 |
1 |
1 |
female |
38.0 |
71.2833 |
First |
2 |
1 |
3 |
female |
26.0 |
7.9250 |
Third |
3 |
1 |
1 |
female |
35.0 |
53.1000 |
First |
4 |
0 |
3 |
male |
35.0 |
8.0500 |
Third |
在最后一个场景中,我们将处理“泰坦尼克”,这是另一个著名的数据集,不过,在我们的代码中,我们称它为“df”。预览如下:
在这个例子中,我们将研究所付票费的均值,通过阶层和是否幸存进行分类。很明显,你可以使用pandas库来做这个。
dfg = df.groupby(['survived', 'pclass']).agg({'fare': 'mean'})
dfg
fare |
||
survived |
pclass |
|
0 |
1 |
64.684008 |
2 |
19.412328 |
|
3 |
13.669364 |
|
1 |
1 |
95.608029 |
2 |
22.055700 |
|
3 |
13.694887 |
这又有什么乐趣呢?这可是一个关于可视化的帖子,让我们以条形图的形式来呈现吧!
场景5:你如何画条形图?
MPL(表情冷酷):无可奉告。
# MATPLOTLIB
died = dfg.loc[0, :]
survived = dfg.loc[1, :]
# more or less copied from matplotlib's own# api example
fig, ax = plt.subplots(1, 1, figsize=(12.5, 7))
N = 3
ind = np.arange(N) # the x locations for the groups
width = 0.35 # the width of the bars
rects1 = ax.bar(ind, died.fare, width, color='r')
rects2 = ax.bar(ind + width, survived.fare, width, color='y')
# add some text for labels, title and axes ticks
ax.set_ylabel('Fare')
ax.set_title('Fare by survival and class')
ax.set_xticks(ind + width)
ax.set_xticklabels(('First', 'Second', 'Third'))
ax.legend((rects1[0], rects2[0]), ('Died', 'Survived'))
def autolabel(rects):
# attach some text labels
for rect in rects:
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()/2., 1.05*height,
'%d' % int(height),
ha='center', va='bottom')
ax.set_ylim(0, 110)
autolabel(rects1)
autolabel(rects2)
plt.show()
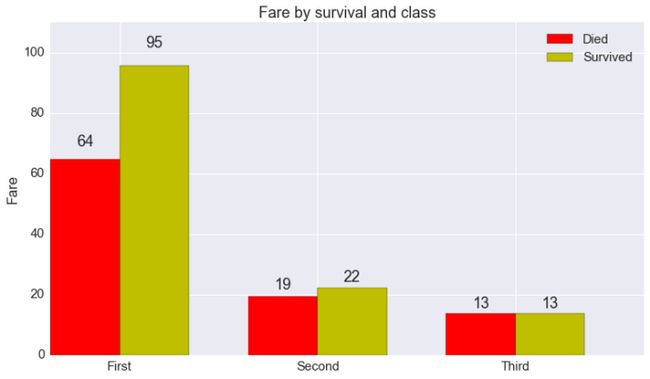
其他人都摇了摇头。
P:我需要先做一些数据处理——也就是group by和pivot——只要这样做了,我就有一种非常酷的方式来画条形图了——比上面的那个乱码要简单得多!哇,我感觉更有信心了,我把他们都比下去了!
# PANDAS
fig, ax = plt.subplots(1, 1, figsize=(12.5, 7))# note: dfg refers to grouped by# version of df, presented above
dfg.reset_index().\
pivot(index='pclass',
columns='survived',
values='fare').plot.bar(ax=ax)
ax.set(xlabel='Class',
ylabel='Fare',
title='Fare by survival and class')

SB:我恰好觉得这样的任务是极其重要的。因此,我实现了一个名为“factorplot”的特殊函数来解决这个问题:
# SEABORN
g = sns.factorplot(x='class', y='fare', hue='survived',
data=df, kind='bar',
order=['First', 'Second', 'Third'],
size=7.5, aspect=1.5)
g.ax.set_title('Fare by survival and class')
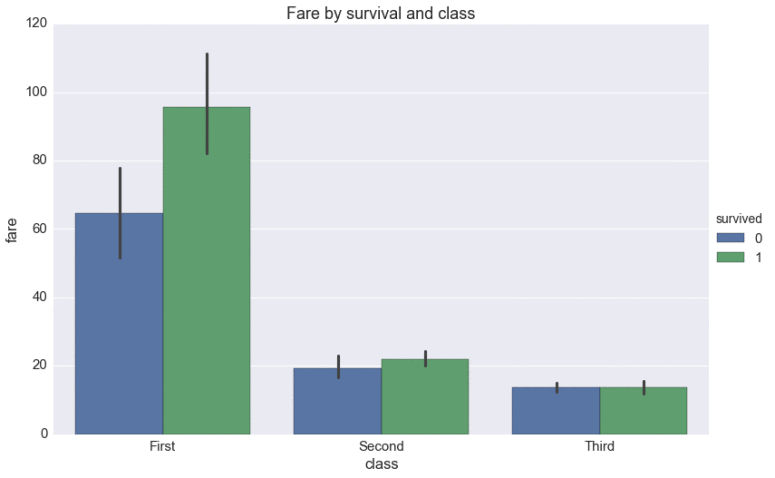
SB:跟之前一样,先将未处理的数据传给数据框。接下来,再说明你将用什么进行分组——在本例中,它是“Class”(阶级)和“Survived”(是否幸存),对应x和hue变量。接下来,说明你想要进行统计的数据列,这里是“Fare”(费用),所以这就变成了我们的y参数。默认的汇总统计是计算平均值,但是factorplot提供了一个名为estimator的参数,可以通过这个参数制定函数,例如,求和、标准差、中值等等,所选择的函数将决定每个条形的高度。
当然,有很多方法能够可视化这些信息,条形只是其中一种。因此,我还有一个参数“kind”用以制定不同的可视化方式。
最后,我们中有一些人比较关心统计上的准确性,所以在默认情况下,我会加上误差线,这样你就可以看到,不同的阶级和幸存率与所付票费是否有关系。(压低声音说)希望你们之中任何一个能做得比我还好。
ggplot2停下他的兰博基尼车,走了进来。
ggplot2:嘿,你们都看到了——
GG:嘿,兄弟。
GG2:嘿,小家伙。我们得走了。
GG:等等,我得快点儿把这个条形图画好,但是我被难住了。你会怎么做?
GG2(阅读说明):啊,像这样:
# GGPLOT2
# in R, I believe you'd do something like this:
ggplot(df, aes(x=factor(survived), y=fare)) +
stat_summary_bin(aes(fill=factor(survived)),
fun.y=mean) +
facet_wrap(~class)
# damn ggplot2 is awesome...

GG2:看到了吗?你要像我们一直所说的那样定义好图形映射,但是你得将y映射到平均费用上。为了做到这一点,就得叫我的朋友“stat_summary_bin”来做这件事,我只需要“mean”传递给“fun.y”参数就好了。
GG(眼睛瞪得大大的):哦,哇。我还没有“stat_summary_bin”呢。我猜——pandas,你能帮我一下吗?
P:哦,当然。
GG:耶!
# GGPY
g = ggplot(df.groupby(['class', 'survived']).\
agg({'fare': 'mean'}).\
reset_index(), aes(x='class',
fill='factor(survived)',
weight='fare',
y='fare')) + \
geom_bar() + \
ylab('Avg. Fare') + \
xlab('Class') + \
ggtitle('Fare by survival and class')
g

GG2:哈,不完全是图形式的语法,但是我想,只要Hadley(译者注:Hadley Wickham,ggplot2的开发者)没发现的话,(使用ggplot2)也能够良好运行。特别指出,你不应该在可视化之前就汇总数据。我也很困惑在这种语境下“weight”是什么意思。
GG:好吧,默认情况下,我的柱形对象使用简单计数,所以如果没有“weight”,所有的柱形高度都为1。
GG2:啊,我明白了。我们以后再谈吧。
GG和GG2说了再见,离开了宴会。
ALT:啊,这可是我的安身立命之道呢。很简单的。
# ALTAIR
c = Chart(df).mark_bar().encode(
x='survived:N',
y='mean(fare)',
color='survived:N',
column='class')
c.configure_facet_cell(strokeWidth=0, height=250)

ALT:我希望所有的参数都是直观的:我想以阶级进行分面,然后按照幸存与否进行分类,画出平均的价格。于是“幸存与否”就是x的参数,“平均数(费用)”作为y的参数,和“阶级”作为column的参数(我还指定了color参数,这样画面更飘逸一点)。注意,我在x和color参数的“survived”字符串后面加了“:N”,这是给我自己加的注释,代表“这是一个名义上的变量”。我把它放在这儿,是因为“survived”看上去像是定量变量,而定量变量会让这个图变得有点丑。不要被吓到,一直以来都是这样——只是没有明说而已。比如说,在上面的时间序列图中,如果我不知道“dt”是一个临时变量,我就会假设它们是名义变量,就会变得很尴尬(至少在我添加“:T”来清除这些变量之前)。另外,我调用我的configure_facet_celll协议,使我的三个子图看起来更加统一。
分析场景5
不要想太多:我再也不用matplotlib库画柱形图,而且要弄清楚,这并不是我一个人的观点!事实是:与其他库不同,matplotlib库不具备对所接收数据做出推测的功能。有时,这意味着你得写严格的命令式代码。
(当然,正是这种数据不可知论使得matplotlib库成为了构建其他Python可视化库的基础。)
相对而言,每当我需要汇总统计和误差线时,我总是会使用Seaborn库。
(这可能是不公平的,我选择了一个仿佛为Seaborn库的一个函数量身定做的例子,不过它在我的工作中经常出现,嘿,这篇博客可是我写的。)
我既没有发现pandas库的特别优势,也没有发现ggpy库具有特别的优势。
然而,就pandas库而言,即使是画简单的条形图,也得用group by和pivot,看上去有点儿傻。
同样,我觉得这是yhat开发的ggpy库的主要漏洞——要找到一个“stat_summary”的替代函数来全面完善功能还有很长一段路要走。
与此同时,Altair库依然让人印象深刻!这个例子中代码的直观程度让我印象深刻。即使你以前从未见过Altair库,我也能想象你能凭直觉知道发生了什么。这种思考、代码和可视化的一一对应正是我最喜爱之处。
总结
你知道,有时候我觉得心怀感激是很重要的:我们有很多很棒的可视化库可以选择,我喜欢深入挖掘它们!
(是的,这只是一种逃避。)
虽然我在matplotlib库上碰到了一点困难,它还是很有趣的(每一部戏都需要喜剧效果)。
这不仅是因为matplotlib库是pandas、Seaborn和ggpy库的基础,还因为它能够给予你必不可少的细粒度的控制权。这篇文章不涉及这个内容,但是在不使用altair的情况下,我都使用matplotlib来调整图形。但是——这是一个很重要的“但是”——matplotlib库是纯声明式的,非常仔细地指定可视化的方方面面会变得很乏味(参见:柱形图)。
确实,可能还有这种结果:“用统计可视化能力来评价matplotlib是不公平的,你这个刻薄的家伙。你在使用它的某一个用例和其他库的主要用例进行比较。这些方法显然需要协同工作。你可以使用自己喜欢的方便的/陈述性表示层——pandas库、Seaborn库、ggpy或者Altair(见下文)——来完成那些基础性的工作。然后你可以使用matplotlib库来完成非基础的部分。如果你穷尽了其他的库的力量,你会很高兴地发现拥有无限的力量的matplotlib就在你的身边,你这个不知感恩的业余绘图的。”
我想说的是:是的!这很有道理,但却是脱离现实的。尽管只是说这并不足以构成一篇博客文章的主要内容。
另外,要是我就不会骂人。
与此同时,在时间序列图中,轴向旋转加上pandas就非常好用。考虑到pandas对时间序列的支持范围更广,我还会接着用。此外,下一次如果要画RadViz
https://link.juejin.im/?target=http%3A%2F%2Fpandas.pydata.org%2Fpandas-docs%2Fstable%2Fvisualization.html%23radviz
图时,我就知道怎么做了。也就是说,虽然pandas确实通过提供基本的声明式语法(见柱形图)来改进matplotlib的命令式范式,但它仍然是matplotlib式的。

继续:如果你想要做更多偏向统计的事情,就用Seaborn吧(她在国外确实学到了很多很酷的东西)。学习她的API接口——factorplot、regplot、displot等等——然后爱上她。这将是值得的。至于分面,我认为FacetGrid是很有用的。要不是我使用Seaborn库那么长时间了,我可能会更喜欢ggpy或Altair库的。
说到声明式的优雅,我一直很喜欢ggplot2,而且对Python的ggpy印象深刻。我肯定会继续关注这个项目。(更自私的说,我希望它能阻止那些使用R语言的同事取笑我。)
最后,如果你想要做的事情是Altair可以完成的(对不起了,箱型图的使用者),用它吧!它拥有一个异常简单和好用的API接口。如果你需要额外的动力,想想以下几点:Altair库一个令人兴奋的特性是——除了即将对其基层的Vega-Lite语法进行改进之外——从技术上讲,它并不是一个可视化库。它会输出符合Vega-Lite标准的JSON对象,在笔记本(IPython Notebook)中可以用IPython Vega渲染得很好。
为什么这令人兴奋?在底层,Altair的可视化看上去都是这样的:
当然,看起来并不令人兴奋,但请考虑它的含义:如果其他库对此感兴趣,他们也可以直接开发将这些JSON对象转化为可视化结果的新方法。这意味着你可以在Altair上搞定基本的工作,然后再深入底层,用matplotlib以获得更多的控制权。
我已经对此期待万分了。
说完这一切,再说一些临别的话:在Python里的可视化比任何一个男人、女人或者尼斯湖水怪都要宏伟,你得有选择地接受我上面所说的一切——包括代码和观点。记住:互联网上的一切都是谎言、谎言和统计数据。
我希望你喜欢这个书呆子气十足的“疯帽子”(注:爱丽丝中的疯帽子)的茶话会,也希望你学到了一些事情可以用到自己的工作中。
和往常一样,代码在GitHub
https://link.juejin.im/?target=https%3A%2F%2Fgithub.com%2Fdsaber%2Fpy-viz-blog
注释
感谢Thomas Caswell
https://link.juejin.im/?target=https%3A%2F%2Fplus.google.com%2F%2BThomasCaswell
他写的关于matplotlib库的特性上地评论,你绝对要读一读。这样你就能一睹远比我上面所提供的优雅得多的matplotlib代码了。
我写这篇文章的时候,yhat将库的的名字从“ggplot”改为“ggpy”。我(认为我)相应地改变了所有的参考资料。
严格地说,这个故事不是真的。我几乎总是用Seaborn库,但是在需要定制的时候,我就会深入到matplotlib库。也就是说,我只是觉得这个matplotlib设定更为引人入胜,毕竟我们生活在一个后真相社会。
马上解释一下,你都生我的气了,所以请允许我解释一下:我爱bokeh和plotly。实际上,我在提交分析之前最爱做的一件事就是把图像传给相关的 bokeh/plotly 函数,获得自由的交互性;但是我对它俩都不是特别熟,没法做更高级的操作。(老实说,这篇文章已经够长了。)显然,如果你需要的是交互式可视化(而非统计可视化),那么你就得找它们。
请注意:这只是为了好玩。我没有用业余的拟人化手法评价任何库。我相信显示生活中的 matplotlib 是非常可爱的。
坦率地说,我不是完全确定单独进行分面操作是为了意识形态上的纯洁,或者只是单纯出于实用的考虑。虽然我的 ggplot 角色声称他是前者(他的理解来自匆匆读完的这篇论文(https://link.juejin.im/?target=http%3A%2F%2Fvita.had.co.nz%2Fpapers%2Flayered-grammar.pdf),也有可能是因为(实际上) ggplot2 对分面的支持太丰富了,所以需要当作是独立的步骤。如果我描述的角色违反了任何图形语法规则,请务必告诉我,我会去找个新的。
这个故事绝对没有任何道德含义。
译者简介

笪洁琼,中南财大MBA在读,目前研究方向:金融大数据。目前正在学习如何将py等其他软件广泛应用于金融实际操作中,例如抓包预测走势(不会预测股票/虚拟币价格)。可能是金融财务中最懂建筑设计(风水方向)的长腿女生。花式调酒机车冲沙。上赛场里跑过步开过车,商院张掖丝路挑战赛3天徒步78公里。大美山水心欲往,凛冽风雨信步行。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”拥抱组织