cgroup-blkio子系统分析
1 概述
Cgroup中的blkio子系统的主要功能是实现对磁盘i/o带宽的可定制化控制。目前支持的控制策略只要有两种:BLKIO_POLICY_PROP和BLKIO_POLICY_THROTL,即基于权重方式和基于流量方式。权重方式依赖于内核原生的CFQ i/o调度算法,i/o调度算法本身是工作在i/o调度层的,因此在使用上有一定的局限性,即被控制的设备必须使用cfq调度算法;为了弥补这方面的局限性,内核后来引入了基于内核 iothrottle的基于绝对流量的控制策略(虽然也有基于cfq的iops绝对控制,但是性能不佳),同时它还分为基于bps和iops的子策略类型,它工作在通用块层,与调度算法无关,因此具有更广的使用范围,但是绝对流量的策略是一种硬性限制,也有一定的弊端,即对io带宽的利用率上存在一定的问题,不能像权重控制那样将带宽使用率最大化。
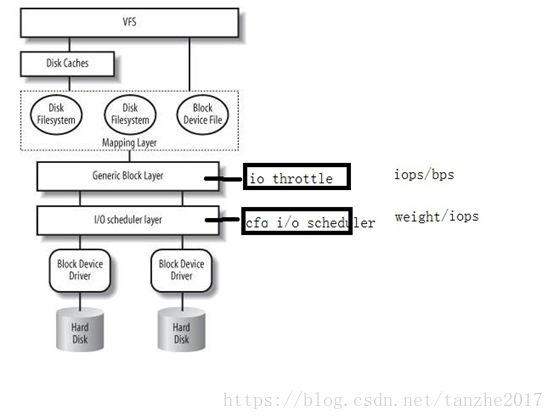
2 blkcg文件接口
blk_cgroup文件系统主要提供以下文件共用户进行流量和权重控制
流量:
blkio.throttle.read_bps_device 限制对某块设备读带宽
blkio.throttle.read_iops_device 限制对某块设备读的次数
blkio.throttle.write_bps_device 限制对某块设备写带宽
blkio.throttle.write_iops_device 限制对某块设备写的次数
权重:
blkio.weight 本cgroup在系统内的权重[101000]
blkio.weight_device 本cgroup对应某设备的权重[10 1000]
3 实现
blkio子系统现有支持三种io带宽控制策略:weight、iops和bps,而且此三种策略在功能上相互独立,可以并存且不互相干扰,因为工作在不同的层次和纬度。
Blkio子系统内核中的对应核心数据结构为struct blkio_cgroup
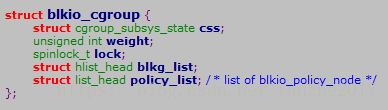
-css 对应cgroup子系统状态描述符
-weight cgroup组的总权重
-blkg_list 连接blkio_group(per device)的链表节点
-policy_list 所有策略对应的策略节点的链表
blkio_cgroup维护了两个链表,blkg_list和policy_list。blkg_list用于链接每个设备上的blkio_group结构;policy_list用于链接设定的所有策略的策略节点blkio_policy_node
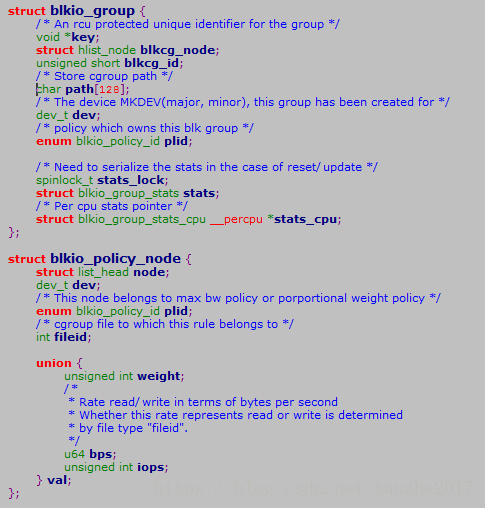
可以看出以上这两个结构都是与设备对应的,blkio_group是一个per cgroup per device 的结构, 它与策略节点blkio_policy_node是一种松耦合的关系,通过blkio_group的dev和plid可以确定与之关联的策略节点(可能有两个)。但需要唯一确定一个blkio_group则需要dev、plid和field三个字段才可以确定,因为I/O流向的原因策略通常包含两个,即读和写,field字段就是用来描述策略的流向的。
3.1 权重weight控制方式
权重(weight)控制方式是基于cfq i/o调度算法的一种blkio控制策略,也是使用最为广泛的控制策略,在实现上主要依赖cfq的组调度机制,即属于每一个cgroup的进程都属于一个组,组内的进程对于一个指定的块设备有相同的权重。权重weight用于当cgroup组与组之间存在io竞争时的带宽分配,带宽的分配按照参与竞争的每一个cgroup组的blkio权重值进行分配的,因此权重大的cgroup在同一个io调度周期内被调度服务的机会越大,最直观的现象就是占用的io带宽越大。
Blkio_cgroup结构维护一个blkg_list链表,链表节点对应一个blkio_group结构,blkio_group是每个设备一个的描述符结构,对于权重方式而言,blkio_group对应一个cfq_group结构,权重值的设定和修改最终会反映在cfq_group结构上
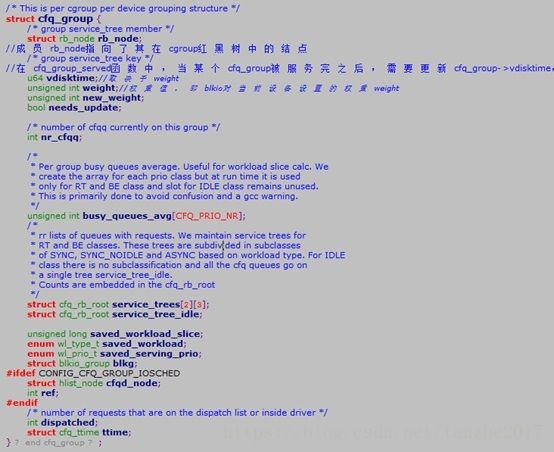
通过第二章的介绍我们知道权重控制的对外借口有两个:blkio.weight和blkio. weight_device,前者是设备无关的,后者是设备有关的,对于没有在blkio. weight_device中指定的设备将使用blkio. weight作为默认的权重值。
blkio.weight和blkio. weight_device的读写操作集的定义如下:
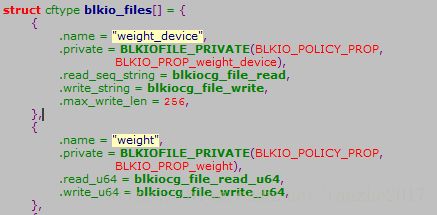
对blkio. weight_device新增或者修改权重策略配置,最终会通过文件系统的接口调用注册的操作函数blkiocg_file_write,首先会根据newpn->dev, plid, fileid找到对应的策略节点,如果尚未有此策略节点,则增加此策略节点,否则就更新已有的策略节点的权重:
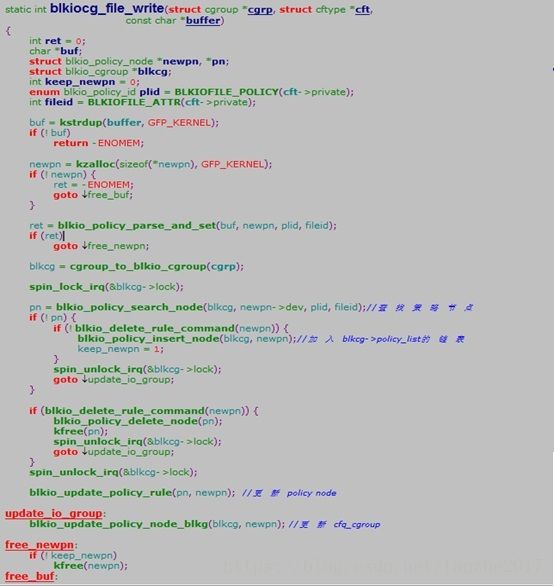
主要流程:
->blkiocg_file_write
->blkio_update_policy_node_blkg
-> blkio_update_blkg_policy
->blkio_update_group_weight
-> cfq_update_blkio_group_weight
cfq_update_blkio_group_weight()是cfs调度器的函数,也是权重调度中最本质的函数

cfqg->new_weight = weight; 更新cfs调度组的权重。
对blkio.weight的更新或者设置,最终会通过文件系统的借口调用注册的操作函数blkiocg_file_write_u64其内部实现是调用blkio_weight_write(blkcg,val)函数来完成的,与weight_device非常类似,但因为blkio.weight是默认的权重,因此它会到策略节点链表中去更新不是通过blkio.weight_device方式设置的策略节点,完成之后同样会将新的权重更新到每一个策略节点所作用到的cfq_group上。
3.2 Iops和bps绝对带宽控制
通常来讲衡量一个块设备的io性能会从两个纬度,即iops和bps,顾名思义即每秒能传输的io请求数和每秒能够传输的字节数,显然传输是双向的,因此又分为read/write。基于iops和bps的带宽控制目前是基于内核的block io throttle机制,虽然iops也有基于cfq的,但是性能跟适用范围有所限制,这里暂不讨论。
blockio throttle机制简称blk-throttle,是一种工作在块层的io控制机制,它提供了一套可用的控制接口,可以在块层上对iops/bps进行限制以起到io控制的效果,因为其实现在通用块层,因此与调度算法无关,相较于weight权重控制适用范围更广,特别是在数据库等一些使用noop或者deadline调度算法的场景下,能发挥出很好的io控制能力。
现在io层的统一接口是submit_bio,上层系统封装好了bio后就调用这个函数发送到底层的设备,submit_bio会调用generic_make_request,generic_make_request会调用q->request_fn,如果设备的驱动实现了自己的request_fn,那么就会脱离通用的block层,直接发起设备的IO,如果是使用通用的request函数,则会进入调度器的队列。由此可见,io throttle要想工作,只能在q->request_fn之前。在代码中,generic_make_request会首先调用blk_throtl_bio来进行throttle工作。blk_throtl_bio就很简单了,它维护了读写两个队列并保存了一些统计信息,当bio进来的时候,它会检测当前分配的iops或者bps是否已经用完,没有用完就直接发送了。如果用完了,就根据读写加入不同的队列,同时维护了一个定时器,计算一个新的可以发送时间,到时间了再发送这个bio。
blk_throtl_bio这个函数比较长,我只贴核心的部分:

某个bio进来后,先调用tg_may_dispatch,进行bps和iops的判断,如果满足用户的设置直接返回true,随后bio将会被插入到请求队列进行正常的io处理流程。 其中tg_with_in_bps_limit是进行bps判断, tg_with_in_iops_limit是进行iops判断。

如果不满足bps和iops会调用throtl_add_bio_tg对io请求进行延迟处理。
由此可见基于blk-throttle的iops和bps控制其实实现上非常简洁,即在提交bio的时候做一些iops/bps的阀值检查,以及传输数据的统计。