PythonCV学习记录11——人脸识别与训练
零之前言
搬运自大佬的博客:https://www.cnblogs.com/xp12345/p/9818435.html 对代码做了部分修改
我们还需要一些库:
这个图像处理包理论上是安装过的,pip试一下?
pip install pillow人脸识别包,用清华的源下载就很快
pip install https://pypi.tuna.tsinghua.edu.cn/simple opencv-contrib-python一.人脸识别
import numpy as np
import cv2
# 人脸识别分类器
faceCascade = cv2.CascadeClassifier(r'D:\PY3.7\Lib\site-packages\cv2\data\haarcascade_frontalface_default.xml')
# 开启摄像头
cap = cv2.VideoCapture("cxk.mp4")
ok = True
while ok:
# 读取摄像头中的图像,ok为是否读取成功的判断参数
ok, img = cap.read()
# 转换成灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 人脸检测
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(40, 40)
)
result = []
# 画矩形
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow('video', img)
k = cv2.waitKey(1)
if k == 27: # press 'ESC' to quit
break
cap.release()
cv2.destroyAllWindows()需要修改的地方:分类器的路径改成你的python安装目录下的。
把开启摄像头的文件改成你的视频或者直接用0开摄像头
二.收集人脸
import cv2
import os
# 调用笔记本内置摄像头,所以参数为0,如果有其他的摄像头可以调整参数为1,2
cap = cv2.VideoCapture(0)
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
face_id = input('\n enter user id:')
print('\n Initializing face capture. Look at the camera and wait ...')
count = 0
while True:
# 从摄像头读取图片
sucess, img = cap.read()
# 转为灰度图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_detector.detectMultiScale(gray, 1.3, 5)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+w), (255, 0, 0))
count += 1
# 保存图像
cv2.imwrite("Facedata/User." + str(face_id) + '.' + str(count) + '.jpg', gray[y: y + h, x: x + w])
cv2.imshow('image', img)
# 保持画面的持续。
k = cv2.waitKey(1)
if k == 27: # 通过esc键退出摄像
break
elif count >= 1000: # 得到1000个样本后退出摄像
break
# 关闭摄像头
cap.release()
cv2.destroyAllWindows()要修改的地方:分类器路径,
还需要在放代码的文件夹里新建一个Facedata
且对于开头输入的id从0开始就行。
收集的数量决定训练的效果和时间,也决定了本代码运行的时间
三.训练数据
import numpy as np
from PIL import Image
import os
import cv2
# 人脸数据路径
path = 'Facedata'
recognizer = cv2.face.LBPHFaceRecognizer_create()
detector = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
def getImagesAndLabels(path):
imagePaths = [os.path.join(path, f) for f in os.listdir(path)] # join函数的作用?
faceSamples = []
ids = []
for imagePath in imagePaths:
PIL_img = Image.open(imagePath).convert('L') # convert it to grayscale
img_numpy = np.array(PIL_img, 'uint8')
id = int(os.path.split(imagePath)[-1].split(".")[1])
faces = detector.detectMultiScale(img_numpy)
for (x, y, w, h) in faces:
faceSamples.append(img_numpy[y:y + h, x: x + w])
ids.append(id)
return faceSamples, ids
print('Training faces. It will take a few seconds. Wait ...')
faces, ids = getImagesAndLabels(path)
recognizer.train(faces, np.array(ids))
recognizer.write(r'face_trainer\trainer.yml')
print("{0} faces trained. Exiting Program".format(len(np.unique(ids))))需要新建一个文件夹:face_trainer
四.人脸检测
import cv2
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('face_trainer/trainer.yml')
cascadePath = "haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascadePath)
font = cv2.FONT_HERSHEY_SIMPLEX
idnum = 0
names = ['Allen', 'Bob']
cam = cv2.VideoCapture(0)
minW = 0.1*cam.get(3)
minH = 0.1*cam.get(4)
while True:
ret, img = cam.read()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.2,
minNeighbors=5,
minSize=(int(minW), int(minH))
)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
idnum, confidence = recognizer.predict(gray[y:y+h, x:x+w])
if confidence < 100:
idnum = names[idnum]
confidence = "{0}%".format(round(100 - confidence))
else:
idnum = "unknown"
confidence = "{0}%".format(round(100 - confidence))
cv2.putText(img, str(idnum), (x+5, y-5), font, 1, (0, 0, 255), 1)
cv2.putText(img, str(confidence), (x+5, y+h-5), font, 1, (0, 0, 0), 1)
cv2.imshow('camera', img)
k = cv2.waitKey(10)
if k == 27:
break
cam.release()
cv2.destroyAllWindows()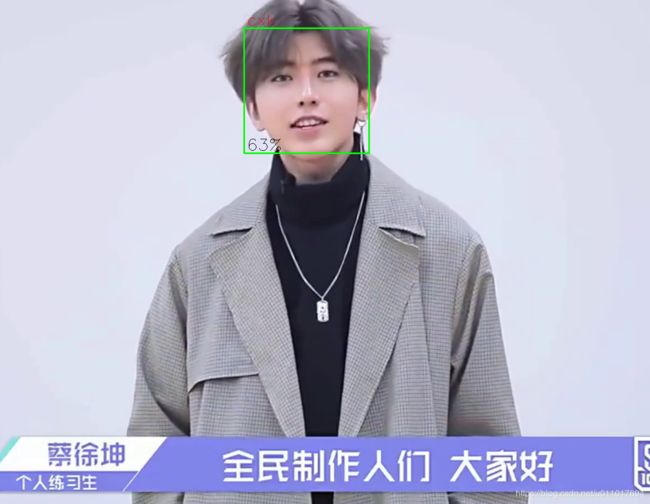
成功!
致此,代码就可以用了,可以自己试试。代码还得一条一条的看与理解,而且不难。