PyTorch(五)——PyTorch源码修改之增加ConvLSTM层
目录连接
(1) 数据处理
(2) 搭建和自定义网络
(3) 使用训练好的模型测试自己图片
(4) 视频数据的处理
(5) PyTorch源码修改之增加ConvLSTM层
(6) 梯度反向传递(BackPropogate)的理解
(7) 模型的训练和测试、保存和加载
(8) pyTorch-To-Caffe
(总) PyTorch遇到令人迷人的BUG
PyTorch的学习和使用(五)
卷积(convolution)LSTM网络首次出现在Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting,并且在处理视频这种具有时间和空间关系的数据时具有较好的效果。
通过扩展torch.nn的方式增加ConvLSTM在github-rogertrullo中有实现,但是由于LSTM是由多个cell组成,当处理连续数据和多层网络时,需要把cell串起来,代码中使用list.append()和for循环的方式实现,不同于tensorflow中提供了tf.nn.dynamic_rnn()函数可以动态加载自定的cell,因此需要手动实现。
在PyTorch中有处理LSTM的机制,因此可以直接使用该机制,修改源码的方式实现ConvLSTM,而且有助于理解LSTM和convolution的具体实现.
通过以下几步实现:
- PyTorch自带LSTM实现分析
- ConvLSTM接口增权重初始化和forward实现
- ConvLSTM测试结果
PyTorch自带LSTM实现分析
PyTorch中的所有层的实现都是首先在nn.modules.*中进行定义、参数说明和参数初始化,然后通过其定义的backend调用nn._functions.*中的具体实现,在 PyTorch(二)——搭建和自定义网络中也是通过这种顺序增加自定义的损失函数。(ps:这应该是设计模式中的一种,但是不太了解,以后补上,有毒,在卷积里又没有这样使用,直接通过F.conv2d()调用的)
首先定义一个LSTM,通过断点的方式理解其函数传递方式与顺序
首先给出LSTM执行的顺序图和时序图(大概意思对,不是专业的,画不好_!)
执行顺序图:
时序图:
1. 定义一个LSTM并输入值测试,使用官方文档的例子,具体参数含义可以查看官方文档。
rnn = nn.LSTM(10, 20, 2) # 定义一个LSTM(初始化)
input = Variable(torch.rand(5, 3, 10))
h0= Variable(torch.rand(2, 3, 20))
c0= Variable(torch.rand(2, 3, 20))
output, hn = rnn(input, (h0, c0)) # 使用LSTM测试
2. LSTM定义时调用nn.modules.rnn.py中的LSTM类。
class LSTM(RNNBase):
def __init__(self, *args, **kwargs):
super(LSTM, self).__init__('LSTM', *args, **kwargs)
3. 该类通过调用父类构造器进行初始化,具体代码就不贴了,主要进行参数的初始化工作。
class RNNBase(Module):
def __init__(self, mode, input_size, hidden_size,
num_layers=1, bias=True, batch_first=False,
dropout=0, bidirectional=False):
# see details for http://pytorch.org/docs/master/_modules/torch/nn/modules/rnn.html#LSTM
4. 当使用LSTM进行前向传播时调用基类(RNNBase)的forward()方法,该方法中主要通过_backend调用nn._functions.rnn.py中的RNN类。
def forward(self, input, hx=None):
# see details for http://pytorch.org/docs/master/_modules/torch/nn/modules/rnn.html#LSTM
func = self._backend.RNN(
self.mode,
self.input_size,
self.hidden_size,
num_layers=self.num_layers,
batch_first=self.batch_first,
dropout=self.dropout,
train=self.training,
bidirectional=self.bidirectional,
batch_sizes=batch_sizes,
dropout_state=self.dropout_state,
flat_weight=flat_weight
)
return output, hidden
5. nn._functions.rnn.py中的RNN类选择GPU的调用。
def RNN(*args, **kwargs):
def forward(input, *fargs, **fkwargs):
if cudnn.is_acceptable(input.data):
func = CudnnRNN(*args, **kwargs)
else:
func = AutogradRNN(*args, **kwargs)
return func(input, *fargs, **fkwargs)
return forward
6. 我们没有使用GPU测试,因此调用AutogradRNN函数,该函数通过StackedRNN实现多个cell的连接, 并且根据是否有batch_sizes输入选择不同的LSTM处理方式。
def AutogradRNN(mode, input_size, hidden_size, num_layers=1, batch_first=False,
dropout=0, train=True, bidirectional=False, batch_sizes=None,
dropout_state=None, flat_weight=None):
# see detials for https://github.com/pytorch/pytorch/blob/master/torch/nn/_functions/rnn.py
if batch_sizes is None:
rec_factory = Recurrent
else:
rec_factory = variable_recurrent_factory(batch_sizes)
func = StackedRNN(layer,
num_layers,
(mode == 'LSTM'),
dropout=dropout,
train=train)
7. StackedRNN则对每一层调用Recurrent或者variable_recurrent_factory对每层进行处理。
def StackedRNN(inners, num_layers, lstm=False, dropout=0, train=True):
# see details for https://github.com/pytorch/pytorch/blob/master/torch/nn/_functions/rnn.py
for i in range(num_layers):
all_output = []
for j, inner in enumerate(inners):
l = i * num_directions + j
hy, output = inner(input, hidden[l], weight[l])
next_hidden.append(hy)
all_output.append(output)
8. Recurrent对输入的时序数据进行处理, 调用LSTMCell具体实现。
def Recurrent(inner, reverse=False):
# see details for https://github.com/pytorch/pytorch/blob/master/torch/nn/_functions/rnn.py
for i in steps:
hidden = inner(input[i], hidden, *weight)
# hack to handle LSTM
output.append(hidden[0] if isinstance(hidden, tuple) else hidden)
9. LSTMCell实现LSTM操作。
def LSTMCell(input, hidden, w_ih, w_hh, b_ih=None, b_hh=None):
if input.is_cuda:
igates = F.linear(input, w_ih)
hgates = F.linear(hidden[0], w_hh)
state = fusedBackend.LSTMFused()
return state(igates, hgates, hidden[1]) if b_ih is None else state(igates, hgates, hidden[1], b_ih, b_hh)
hx, cx = hidden
gates = F.linear(input, w_ih, b_ih) + F.linear(hx, w_hh, b_hh) # 合并计算
ingate, forgetgate, cellgate, outgate = gates.chunk(4, 1) #拆分各个门
ingate = F.sigmoid(ingate)
forgetgate = F.sigmoid(forgetgate)
cellgate = F.tanh(cellgate)
outgate = F.sigmoid(outgate)
cy = (forgetgate * cx) + (ingate * cellgate)
hy = outgate * F.tanh(cy)
return hy, cy
首先,LSTM的公式如下:
g ( t ) = ϕ ( W g x x ( t ) + W g h h ( t − 1 ) + b g ) i ( t ) = σ ( W i x x ( t ) + W i h h ( t − 1 ) + b i ) f ( t ) = σ ( W f x x ( t ) + W f h h ( t − 1 ) + b f ) o ( t ) = σ ( W o x x ( t ) + W o h h ( t − 1 ) + b o ) s ( t ) = g ( t ) ⊙ i ( t ) + s ( t − 1 ) ⊙ f ( t ) h ( t ) = ϕ ( s ( t ) ) ⊙ o ( t ) g^{(t)} = \phi(W^{gx} x^{(t)} + W^{gh} h^{(t-1)} + b_g) \\ i^{(t)} = \sigma(W^{ix} x^{(t)} + W^{ih} h^{(t-1)} + b_i) \\ f^{(t)} = \sigma(W^{fx} x^{(t)} + W^{fh} h^{(t-1)} + b_f) \\ o^{(t)} = \sigma(W^{ox} x^{(t)} + W^{oh} h^{(t-1)} + b_o) \\ s^{(t)} = g^{(t)} \odot i^{(t)} + s^{(t-1)} \odot f^{(t)} \\ h^{(t)} = \phi(s^{(t)}) \odot o^{(t)} g(t)=ϕ(Wgxx(t)+Wghh(t−1)+bg)i(t)=σ(Wixx(t)+Wihh(t−1)+bi)f(t)=σ(Wfxx(t)+Wfhh(t−1)+bf)o(t)=σ(Woxx(t)+Wohh(t−1)+bo)s(t)=g(t)⊙i(t)+s(t−1)⊙f(t)h(t)=ϕ(s(t))⊙o(t)
公式来自A Critical Review of Recurrent Neural Networks for Sequence Learning, 其中 ϕ \phi ϕ 为tanh激活函数, σ \sigma σ 为sigmoid激活函数。
由于 σ \sigma σ为各个门之间的激活函数,用于判断多少信息量可以通过,取值为0~1,因此选用sigmoid激活函数 ,而 ϕ \phi ϕ为状态和输出的激活函数,可以选择其他的,比如ReLU等。
从公式中也可发现,其中有4个操作是重复的,都为Wx + Wh +b,因此在计算是可以合并计算,然后在分开得到各个门的值,如上述代码所示。
###ConvLSTM接口增加
由于convolution LSTM把原始的LSTM门之间的操作改为了卷积操作,因此在传入参数时需要额外增加卷积核的大小,由于时序数据每时刻输入数据尺度相同,因此卷积后的大小与输入大小相同,则padding=(kernel - 1)/2.
主要做的工作有三个:
- 在
nn/_functions/rnn.py中增加ConvLSTm的具体实现
通过输入和数据,实现ConvLSTM的前向传播 - 在
nn/nodules/rnn.py修改RNNBase(Module)的传入参数和卷积权重初始化
由于卷积和线性传播的参数尺寸和个数不同,因此需要定义参数的初始化和增加kernel传入参数接口 - 修改
nn/_functions/rnn.py相应的参数接口
由于根据不同的RNN种类需要进行不同的处理
接下来详细的实施每一步,和 PyTorch(二)——搭建和自定义网络中增加自定损失函数相同。
1. 在nn/_functions/rnn.py中增加ConvLSTm的具体实现
实现代码如下:
# define convolutional LSTM cell
def ConvLSTMCell(input, hidden, weight, bias=None):
hx, cx = hidden
combined = torch.cat((input, hx), 1)
# in this way the output has the same size of input
padding = (weight.size()[-1] - 1)/2
gates = F.conv2d(combined, weight, bias=bias, padding=padding)
ingate, forgetgate, cellgate, outgate = gates.chunk(4, 1)
ingate = F.sigmoid(ingate)
forgetgate = F.sigmoid(forgetgate)
cellgate = F.tanh(cellgate)
outgate = F.sigmoid(outgate)
cy = (forgetgate * cx) + (ingate * cellgate)
hy = outgate * F.tanh(cy)
是不是很简单,只是把之前的线性操作换成了卷积操作,其中F.con2d的参数为:(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1),权重(weight)为:(out_channels, in_channels/groups, kH, kW),详见:
2. 在nn/modules/rnn.py中增加ConvLSTM的扩展
使通过nn.ConvLSTM()可以调用。
class ConvLSTM(RNNBase):
r"""Applies a convolution multi-layer long short-term memory (ConvLSTM) RNN to an input sequence.
Examples::
>>> rnn = nn.LSTM(3, 10, 2, kernel_size=3)
>>> input = Variable(torch.randn(4, 10, 3, 25, 25))
>>> h0 = Variable(torch.randn(2, 10, 10, 25, 25))
>>> c0 = Variable(torch.randn(2, 10, 10, 25, 25))
>>> output, hn = rnn(input, (h0, c0))
"""
def __init__(self, *args, **kwargs):
super(ConvLSTM, self).__init__('ConvLSTM', *args, **kwargs)
和LSTM简直一模一样,都是调用父类构造其初始化。
3. 在nn/modules/rnn.py中针对ConvLSTM修改RNNBase的初始化和参数传入
每个RNNBase的子类都通过('mode', *args, **kwargs)的方式传入参数,因此增加参数时只需要修改其父类的定义即可,因此在最后增加kernel_size的传入,并且使用utils中的_pair进行初始化(即,from .utils import _pair):kernel_size = _pair(kernel_size)。
卷积的权重为out_channels × in_channels × kernel_h × kernel_w,偏置为out_channels,通过查看卷积初始化的源码:

从源码中也可以看到起权重和偏置的组成,并且权重初始化为关于输入通道乘核大小(in_channels x kernel)的一个分布,我们再看LSTM的权重初始化:

权重初始化是关于隐层大小(hidden_szie)的一个分布,因此需要做一些调整。
(PS:从源码中也可看出,卷积在reset_parameters给权重赋值函数里判断是否给偏置初始化,而LSTM是在init中先判断是否有偏置参数,在进行初始化,两种不同编码风格,应该不是一个人写的 _!)
最后对LSTM的初始化代码进行修改,结果如下:
(PS: 由于ConvLSTM在实现是把input和hidden拼在一起进行卷积计算,因此使用一个权重weight和偏置bias表示计算过程)
def __init__(self, mode, input_size, hidden_size,
num_layers=1, bias=True, batch_first=False,
dropout=0, bidirectional=False, kernel_size=3):
super(RNNBase, self).__init__()
self.kernel_size = kernel_size
num_directions = 2 if bidirectional else 1
kernel_size = _pair(kernel_size)
# init parameters
self.n = hidden_size
self._all_weights = []
for layer in range(num_layers):
for direction in range(num_directions):
layer_input_size = input_size if layer == 0 else hidden_size * num_directions
if mode == 'LSTM':
gate_size = 4 * hidden_size
elif mode == 'ConvLSTM':
weight = Parameter(torch.Tensor(4*hidden_size, layer_input_size + hidden_size, *kernel_size))
bias = Parameter(torch.Tensor(4*hidden_size))
self.n = layer_input_size
for k in kernel_size:
self.n *= k
suffix = '_reverse' if direction == 1 else ''
weights = ['weight_l{}{}', 'bias_l{}{}']
weights = [x.format(layer, suffix) for x in weights]
setattr(self, weights[0], weight)
if bias:
setattr(self, weights[1], bias)
self._all_weights += [weights]
else:
self._all_weights += [weights[:1]]
continue
这里只贴了部分代码,其他代码与原始相同。
同时 ,也需要修改下面的forward()代码:
if hx is None:
if self.mode == 'ConvLSTM':
feature_size = input.size()[-2:]
num_directions = 2 if self.bidirectional else 1
hx = torch.autograd.Variable(input.data.new(self.num_layers *
num_directions,
max_batch_size,
self.hidden_size,
feature_size[0],
feature_size[1]).zero_())
hx = (hx, hx)
else:
num_directions = 2 if self.bidirectional else 1
hx = torch.autograd.Variable(input.data.new(self.num_layers *
num_directions,
max_batch_size,
self.hidden_size).zero_())
if self.mode == 'LSTM':
hx = (hx, hx)
4. 修改nn/_functions/rnn.py相应的参数接口
需要针对不同种类的RNN进行处理,主要在nn/_functions/rnn.py的AutogradRNN中增加ConvLSTMCell的调用。

5. 最后在nn/modules/init.py和nn/backends/thnn.py中增加声明
如同 PyTorch(二)——搭建和自定义网络,增加ConvLSTm的声明定义。
修改thnn.py:

修改init.py:

测试结果
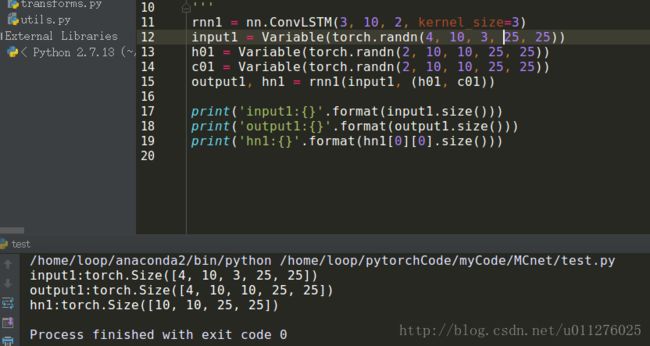
最后对于输入通道为3,隐层通道为10,网络层数为2, 卷积核为3的ConvLSTM进行测试,
输入数据为(4, 10, 3, 25, 25)分别为序列长度、batch_size、输入通道、图片尺寸
隐层和cell为(2, 10, 10, 25, 25)分别为网络层、通道数、batch_szie、特征尺寸。
最后到输出尺寸为4, 10, 10, 25, 25
(PS:最后,可以看到调用网络结构有2种不同的方式,拿卷积来说,有nn.Conv2d和F.conv2d两种,两种输入的参数不同,简单来讲,第一种需要不需要输入权重参数进行初始化,第二种可以传入初始化后的权重)
2017/11/20更新
由于使用在实现WGAN-GP时会使用到Higher-order gradients,本来不想更新的PyTorch2也必须更新了,同时也使用了python3.6,代码改动较小,主要是权重初始化时的编码风格改变了需要调整,主要修改如下: