Hive基础总结及练习(自己总结的精华,基础复习只看这一篇就够了)
重点内容:
Hive的数据类型
Hive的Tables(External 和 Internal)
Hive的Partitions(Static和Dynamic)
选择掌握 Hive Bucket Tables
期间我要穿插一些练习,因为上课时做的练习完全不够。
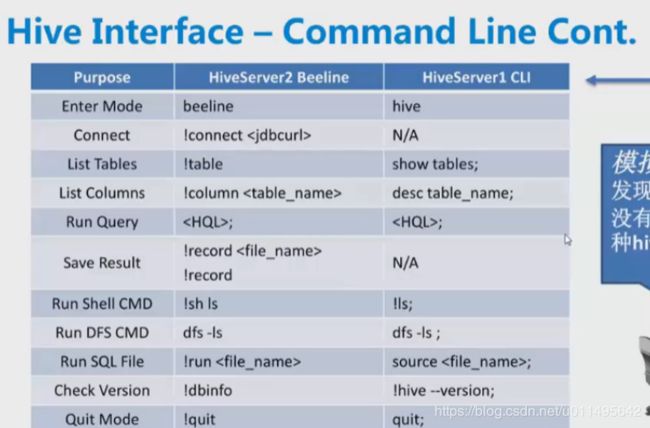
1. 两种连接Hive的工具
(1)通过beeline
(2)通过command Line命令行
使用方法如下图

解释:
-e 表示执行sql语句
-f 表示从一个文件中执行sql语句
beeline --hivevar key=value 定义hive的变量,这样变量就可以在hive语句中使用了。
两种模式
命令行模式:执行一个命令,返回一个结果,整个过程是阻塞的。
生产环境绝大部分采用命令行模式来部署。
你比如hive -e ' select * from table a ' 这就是命令行模式
交互模式:进入就停在hive模式(类似进入python模式)
如果没有输入-e或者-f ,它就会自动进入shell交互模式。
Beeline和CLI方式 两者命令比较
beeline方式的命令大部分要加!
实践:
Beeline登陆hive,都需要一个jdbc的url :
beeline -u "jdbc:hive2://localhost:10000/default" (生产环境没这么短)
10000是连接hive 1.2.1
10500是连接hive 2.1.0
10016是连接spark sql
2. Data type
主要的4种原始数据类型:INT DECIMAL(小数) DOUBLE STRING
为什么主要是STRING,因为大数据环境对char和varchar类型支持的不太好。
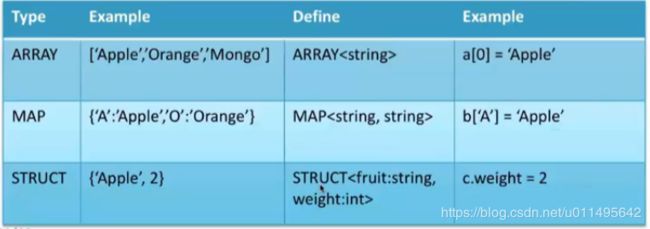
复杂数据类型:
STRUCT 通过“.”来访问
MAP和ARRAY访问方式类似
模拟面试:
大数据数据建模在数据类型方面的最佳实践(对比数据仓库)?
Hive数据建模很简单,不再纠结数据类型的使用空间,而是关注使用场合以及对函数的兼容程度。
(就是刚才说的为什么用string,不用char和varchar)
3.元数据总结
Hive有哪些元数据,
包括database table partition buckets row column views index

面试题:如何知道当前所在数据库?
命令:select current_database();
4. hive sql基础命令
(1)database
create database myhivebook; 建数据库
show databases; 查看有哪些数据库
use myhivebook; 切换到该数据库
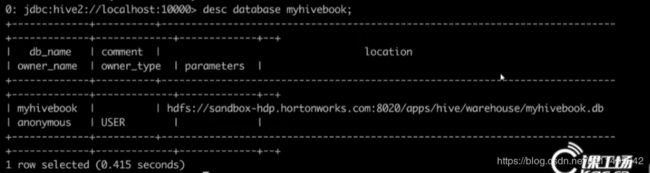
desc database myhivebook; 显示数据库信息
可以看到这个database的位置,Hive默认是把数据库创建在 /user/hive/warehouse目录下的,
你是内部表的话,默认都会在这个目录下,如果是default数据库的内部表就在此目录下。
如果是其他数据库的内部表,创建了数据库,比如叫a,那就会在这个目录下创建一个叫a.db的目录下,以后内部表就放在a.db下。
drop database myhivebook; 删除数据库
默认情况:
[root@data1 ~]# hdfs dfs -ls /user/hive/warehouse/
Found 7 items
drwxrwxrwt - root hive 0 2017-04-07 14:24 /user/hive/warehouse/a.db
drwxrwxrwt - root hive 0 2017-03-27 14:13 /user/hive/warehouse/abc
drwxrwxrwt - root hive 0 2017-04-07 14:22 /user/hive/warehouse/b.db
drwxrwxrwt - root hive 0 2017-04-03 16:30 /user/hive/warehouse/bonus
drwxrwxrwt - root hive 0 2017-03-24 13:18 /user/hive/warehouse/department
drwxrwxrwt - hive hive 0 2017-04-04 23:12 /user/hive/warehouse/dept
drwxrwxrwt - root hive 0 2017-04-03 16:50 /user/hive/warehouse/emp
指定一个库:
[root@data1 ~]# hdfs dfs -ls /user/hive/warehouse/a.db
Found 2 items
drwxrwxrwt - hive hive 0 2017-04-07 13:55 /user/hive/warehouse/a.db/dept
drwxrwxrwt - root hive 0 2017-04-07 14:25 /user/hive/warehouse/a.db/dept1
指定分区:
目录名以“分区键名=分区值”的形式命名。如下图,表dept1中,设置了v1和v2两个名为a的分区。
[root@data1 ~]# hdfs dfs -ls /user/hive/warehouse/a.db/dept1
Found 2 items
drwxrwxrwt - root hive 0 2017-04-07 14:24 /user/hive/warehouse/a.db/dept1/a=v1
drwxrwxrwt - root hive 0 2017-04-07 14:25 /user/hive/warehouse/a.db/dept1/a=v2
5. Hive Tables
(1)External Tables:
1. 外部表是存在于非默认路径下的,建立外部表时需要指定LOCATION,也就是它存在的位置。
2. 当我们删除一个外部表时,他得数据不会删除,这是对数据的一种保护。
(不可管理)
(2)Internal Tables:
1.内部表存在于默认路径下,比如 /user/hive/warehouse/employee
2. 表删了,数据也会跟着没了。
从应用场景上说:
一句话总结:客户共享的数据,我们读入数据建立外部表。数据清洗和转换时,我们建立内部表进行处理,最终得到的结果我们保存在外部表,分享给其他用户。
外部表
(1)基于外部表的只读特性,客户给你的数据(源数据)放在外部表,以免开发人员删除和改动。
(2)数据共享时,外部表的数据路径可以直接分享给别人。(内部表数据路径很敏感,不能分享)
内部表
(1)数据转换、数据清洗时,复杂连续的过程,需要对数据进行修改,对数据完全的控制。还有些功能不支持外部表。
(3)建表语句
非常简单

自己敲一下
show tables; 看看表
create external table if not exists employee_external(
name string,
work_place ARRAY
sex_age STRUCT
skills_score MAP
depart_title MAP
)
COMMENT 'This is an external table'
ROW FORMAT DELIMITED //记着这句话必须加就好
FIELDS TERMINATED BY '.' //如何定义列分隔符
COLLECTION ITEMS TERMINATED BY ',' //MAP和集合如何分隔符
MAP KEY TERMINATED BY ':'
STORED AS TEXTFILE //文件格式用TEXT文本
LOCATION '/user/dayongd/employee' //外部表存在哪里
// SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。序列化作用序列化是对象转换为字节序列的过程。反序列化是字节序列恢复为对象的过程.
6. Storage SerDe
SerDe相比于直接建表语句的优势在于:还支持quoteChar、escapeChar等,功能更强大。
本质上和TERMINATED BY这种定义分隔符的方式,没什么区别。
常用支持的数据格式,SERDE就是数据格式。
TEXTFILE、SEQUENCEFILE(二进制数据,体积较小) ,ORC是基于列的,还支持CSV格式的。
它的用法是这样的:
create table my_table(a string, b string,....)
ROW FORMAT
SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerDe' //指定SERDE的类,不同的java类支持存储成不同的数据格式。
WITH SERDEPROPERTIES( //用WITH来连接SERDE的属性
"separatorChar" = "\t" , 路径区分符
"quoteChar" = "", 引用符
"escapeChar" = "\\" 转义符
)
STORED AS TEXTFILE;

7.练习:
desc formatted比desc更详细。
desc formatted external_employee; //查看此外部表的location,但是目前这是个空表,它对应的hdfs路径下没数据的。
hdfs dfs -ls /user/dayongd/employee //查看外部表所在的hdfs路径
hdfs dfs -put employee.txt /user/dayongd/employee //传文件到该路径
上传成功之后,查看employee.txt上传成功
select * from employee_external; //有数据了,查询自然有结果了
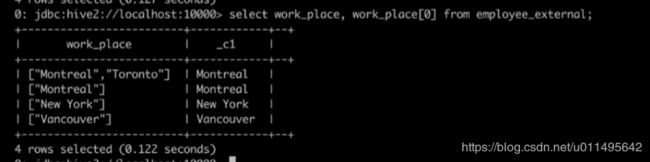
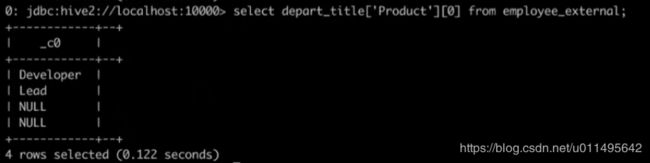
复杂数据类型查询
ARRAY类型
比如查某个字段,它是一个数组类型,可以查它数组的第一个元素。
MAP类型
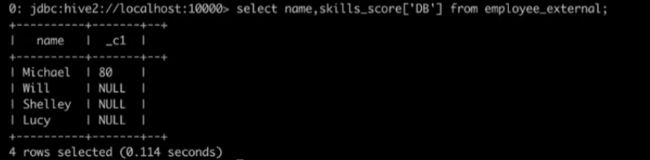
STRUCT类型
用“.”类访问它的值。
嵌套的就是两层中括号。
8. Hive高阶语句
CTAS and WITH
(1)Create Table As Select :把查询的值建立成新表。
例子:create table ctas_employee as SELECT * FROM employee
(2)不适用于partition,external,bucket table。 外部表 分区 分桶都不适合用查询直接建表。
(3) CTAS with CTE (Common Table Expression)
这东西牛逼就牛逼在于,你看我标黑的地方不就是CTAS么,他CTE就是加了个WITH。
本来一堆子查询嘛,但是子查询嵌套好乱的。
所以就用Common Table Expression,
我把每个临时表我提前定义好,比如说定义好r2,我r1的定义里就可以引用r2。
最终还是通过一个查询来建立新表。
例子:
CREATE TABLE cte_employee AS
WITH
r1 AS (SELECT name FROM r2 WHERE name = 'Michael'),
r2 AS (SELECT name FROM employee WHERE sex_age.sex='Male'),
r3 AS (SELECT name FROM employee WHERE sex_age.sex='Female')
SELECT * FROM r1 UNION ALL SELECT * FROM r3 ;
(4)通过LIKE建立空表
create table employee_like LIKE employee 直接复制一个表(空表,并不带数据过来)
9. Temporary Table 临时表
create temporary table tmp_table_name1(c1 string);
create temporary table tmp_table_name2 AS..
create temporary table tmp_table_name3 LIKE..
临时表在用户连接断开后会自动删除,路径就存在 /tmp/hive-
注意临时表名字尽量不要和现有表冲突,否则它会优先拿临时表。
临时表的建立过程和普通表没有任何区别,除了加TEMPORARY关键字,可以直接建表,也可以从查询语句中建表,或者是LIKE建立空表。
也不支持partition,因为是临时的。
10. 对表的其他操作
(1)DROP TABLE IF EXISTS employee //如果最后不加PERGE的话,就不会把内部表彻底删除,还可以从回收站找回。
回收站在HDFS的user目录下的.Trash文件夹。
(2)TRUNCATE TABLE employee 保留表和字段,清除表中所有数据
(3)ALTER
常用
ALTER TABLE employee RENAME TO new_employee 数据备份(老数据改个名字)
ALTER TABLE eomployee CHANGE old_name new_name STRING [BEFORE|AFTER] sex_age
把sex_age列名修改,并改为STRING类型
ALTER TABLE c_employee ADD COLUMNS(work string) 添加新列叫work string类型
ALTER TABLE c_employee REPLACE COLUMNS(name string) 替换列叫work string类型
这个例子比较极端,给替换成只剩1列了。
不重点掌握
ALTER TABLE employee_internal SET SERDEPROPERTIES(‘filed.delim’ = '$')
可以改SerDe的属性,包括哪些分隔符等等。
ALTER TABLE c_employee SET FILEFORMAT RCFILE
把文件格式改成RCFILE,但只是元数据层面!!并不真的把数据改成RCFILE!
11. Partitions
通过分区来提高查询性能,因为它会把你某些列根据值来建立文件夹。
定义分区表:
和建立普通表没有任何区别,就多了一行PARTITIONED BY(year INT,month INT)
两层,一层是year,一层是month,本质都是文件夹。

我们现在已经成功建立分区表了,目录有两层year和month,我们现在增加静态分区
添加静态分区步骤:
ALTER TABLE employee_pratitioned ADD
PARTITION(year=2014,month=12)
PARTITION(year=2014,month=11)
添加成功之后就多了两个文件夹,然后查看分区表。
查看分区表
show partitions employee_partirioned;

删除分区
DROP IF EXISTS PARTITION(year=2014,month=11);
查看分区表的结构
desc employee_paritition;
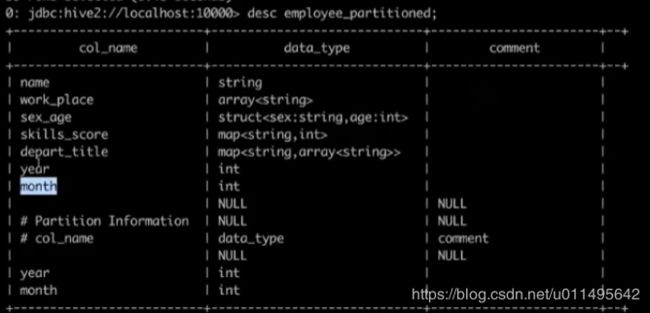
可以看到有两个year和month,分区和正常字段是一样的。他只是为了检索方便。
去hdfs的目录下去看,就可以看到建立成功。
静态partition缺点:每次都需要手动建立,
自动建立大量的就需要用动态partition。
动态partition步骤总结:
1. SET hive.exec.dynamic.partition=true;
2. SET hive.exec.dynamic.partition.mode=nonstrict; //使能
通过以上两步打开动态分区
3. 创建分区标
hive> create table d_part(
> name string
> )
> partitioned by(value string)
> row format delimited fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile;
目前partition没有数据。
4. 检查一下,确实没数据,不管查分区,还是查分区表里所有字段。
hive> show partitions d_part;
OK
hive> select * from d_part;
OK
5. 自己用insert插入数据,后面接一个select来告诉hive我插入哪些数据。
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrick;
hive> insert overwrite table d_part
partition(value)
> select name,
> addr as value
> from testtext;
6.检查有没有数据了,已经有了
hive> select * from d_part;
OK
wer 46
weree 78
wer 89
rr 89
Time taken: 0.732 seconds
hive> show partitions d_part;
OK
value=46
value=78
value=89
Time taken: 0.142 seconds
————————————————————————————
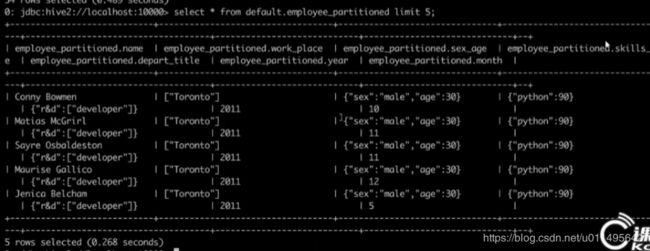
例子:
INSERT INTO TABLE employee_partitioned
PARTITION(year,month) //依然是按两列来分两层
SELECT name,
array('Toronto') as work_place,
named_struct("sex","Male","age",30) as sex_age,
map("Python",90) as skill_score,
year(start_date) as year
month(start_date) as month
FROM employee_hr eh;
我发现这语句好神奇,是在select里面插字段了吗,莫名其妙插入一个array又插入一个map。
反正这个partition就建立好了,都是按year和month来建的。
然后后这些字段也成功插入了,而且year和month还自动从start_date中分离出来了。
智能爆了。。。。??
效果如图:
动态分区和静态分区应用场景:
大批量导入肯定是动态分区方便,以及不知道怎么分区的时候,需要通过后面的查询语句来分去。
有几个参数,要认识一下:
set hive.exec.dynamic.partition=true// 使用动态分区
set hive.exec.dynamic.partition.mode=nonstrick//无限制模式
如果模式是stric,则必须有一个静态分区,且放在最前面
set hive.exec.max.dynamic.partitions.pernode=10000;//每个节点生成动态分区的最大个数
set hive.exec.max.created.files=150000;//一个任务最多可以创建的文件数目
set dfs.datanode.max.xcievers=8192;//限定一次最多打开的文件数
9.分桶:所有分桶都是动态加载的。
没法对现有文件进行分桶,你必须通过insert语句调用mapreduce来进行动态分桶。
分桶步骤:
1. SET hive.enforce.bucketing = true; //开启分桶
2. 建分桶表
和建分区表区别不大,主要就是多加了一行
CLUSTERED BY (employee_id) INTO 2 BUCKETS //分2个桶
分桶个数必须是2的n次方
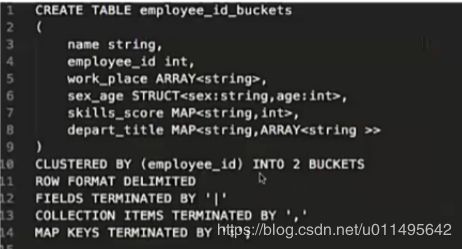
和分区表最大的区别在于:
分桶表这个CLUSTERED BY (employee_id) 分桶列名是真的出现在列定义中的。
而不是像分区表,分区的列都是我们自己创造出来的,并不是真正存在的列。
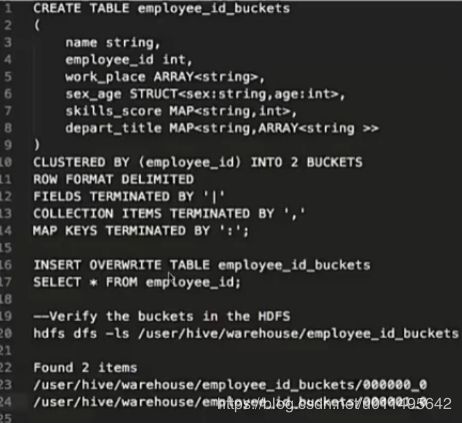
3. 往分桶表插入数据
INSERT OVERWRITE/INTO TABLE employee_id_buckets
SELECT * FROM employee_id;
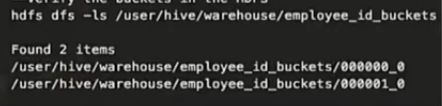
4. 验证HDFS中的分桶情况
这是我们按列分桶
hdfs dfs -ls /user/hive/warehouse/employee_id_buckets
结果是:
查到了两个文件。因为我指定了2个桶,你就得给我生成了2个文件。
分桶总结:
1. 分桶的column是TABLE中实际存在的column,不是凭空生成的。
2.分桶的个数是2的n次方
3. 分桶需要通过insert语句来动态查询
4.分桶是按照column组织成多个文件,文件的个数由分桶决定。
5.使用分桶时要SET hive.enforce.bucketing= true 来开启分桶
不要试图在数据文件中找分区列的数据!!!