Word2Vec+CNN+tensorflow实现恶意网页链接的检测
一、综述
恶意网页链接的检测方案有很多
例如http://fsecurify.com/using-machine-learning-detect-malicious-urls/
该文使用了机器学习逻辑回归算法
但是该算法存在一些问题,一个是用TFIDF方法来获取词频,该方法的缺陷就是只能获取单词在整段文字的词频信息,
没办法获取上下文语境的信息
本文从自然语言的角度解析URL链接,恶意链接与文本恰有一些相似之处,所以尝试了自然语言处理的
方法来检测网页
本文将会简单介绍一些算法
二、算法介绍
1)典型的利用CNN进行文本分类的思路
卷积神经网络用于NLP的检测已经有很多实践以及论文支持,
比如http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
利用CNN横向连接实现文本情感分析,本博文也是基于该原理,实现恶意网页检测。
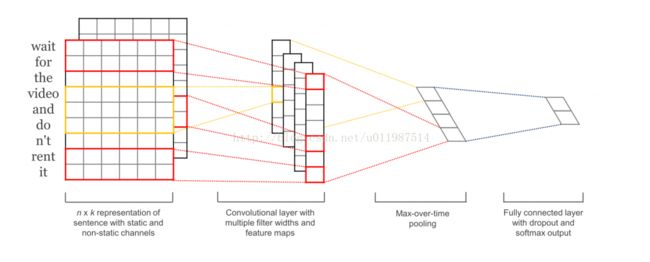
第一层进行一层低维词嵌入,把单词句子表示成向量形式,比较常用的词嵌入手段是word2vec,
第二层在词向量上进行卷积操作,可以多次使用不同尺寸的filter, 这样每次划过的单词数量就不同,
可以利用该特性自动抽取到上下文之间的关系特征。
第三层进行max-pooling。
2)重新思考URL检测问题
从文本分类上获得启发,能否借鉴它的这种想法,利用到URL上来?
博主把借鉴了这套网络,把它迁到url上来,对URL结构进行了分析。
这里以一条链接举例说明url的低维嵌入方法,请看
https://q.taobao.com/?spm=a21bo.50862.201859.7.spjPF3
一般url分成三部分 : 协议//主机名+域名/参数
三段之间是用" / "分割的,主机名和域名之间又是用"." 分割,参数之间的传递
常用的分割符有"?", "=" ,"&" ,"-" ,"."等
一般钓鱼的链接会在域名和主机名之间作文章,进行一些域名混淆的恶意行为
而恶意用户请求会从请求参数作文章,比如进行恶意SQL注入
博主用了这六个分隔符,实现了url的切割,可以获取到整条url重要字段的信息。
需要注意的是,为了获取各个字段之间的位置关系,
提取的时候不可随意将顺序调换或者随意删除重复字段,
这是本文与综述中提到的文章所用的取词方法极大的不同之处,
本文更强调的是字段与字段之间的关系,同时也兼顾了字段的出现频率。
3)word2vec
有了分割好的字段,就可以进行词向量训练了。
简单描述下word2vec算法的思想
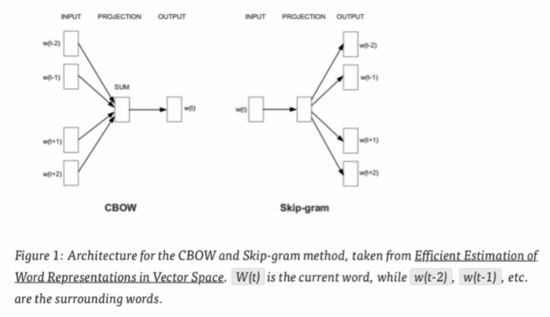
Word2Vec实际上是两种不同的方法:ContinuousBag of Words (CBOW) 和Skip-gram。
CBOW的目标是根据上下文来预测当前词语的概率。
Skip-gram刚好相反:根据当前词语来预测上下文的概率(如图 )
这实际上也是一种联系上下文的特征提取
可以通过调节window来设置上下文的范围,其他还有很多调参细节,这里不再细说
博主主要用它来实现切割好的单词的低维嵌入。
接下来接入前文所描述的卷积结构。
最后实现的结构如图所示
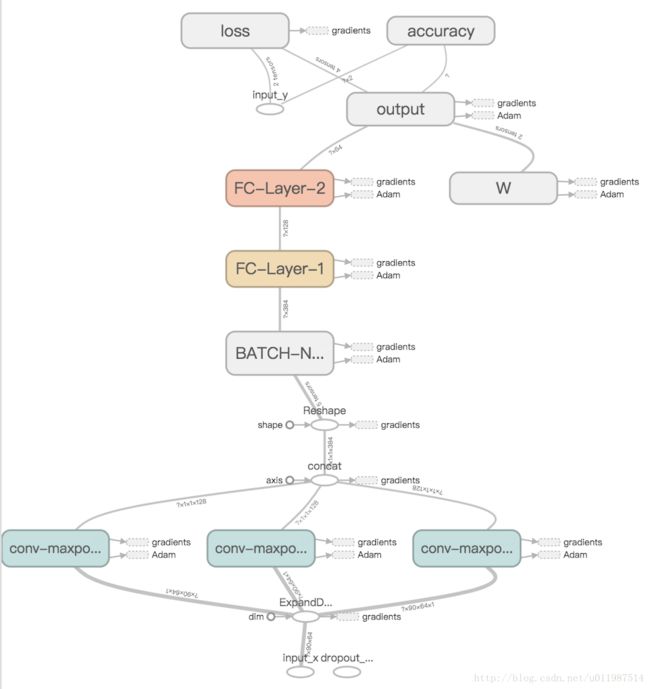
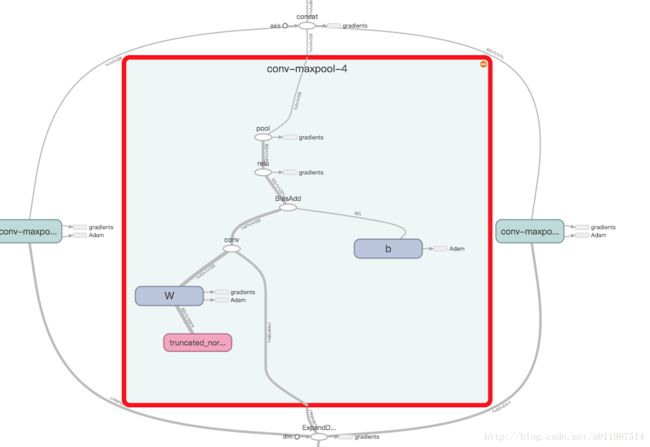
对于字段之间的位置关系的记忆,LSTM也可以做到,但又是基于不同的原理,与本文讨论的思路不同
博主后面有时间可能会尝试对比一下。
三、核心代码
import tensorflow as tf
import numpy as np
class URLCNN(object):
def __init__(
self, sequence_length, num_classes,
embedding_size, filter_sizes, num_filters, l2_reg_lambda=0.0):
# Placeholders for input, output, dropout
self.input_x = tf.placeholder(tf.float32, [None, sequence_length, embedding_size], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# Keeping track of l2 regularization loss (optional)
l2_loss = tf.constant(0.0)
# Embedding layer
self.embedded_chars = self.input_x
self.embedded_chars_expended = tf.expand_dims(self.embedded_chars, -1)
# Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expended,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding="VALID",
name="pool")
pooled_outputs.append(pooled)
# Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
# Add Batch Normalization
epsilon = 1e-3
with tf.name_scope("BATCH-NORM"):
batch_mean,batch_var = tf.nn.moments(self.h_pool_flat,[0])
scale = tf.Variable(tf.ones([384]))
beta = tf.Variable(tf.zeros([384]))
self.BN = tf.nn.batch_normalization(self.h_pool_flat,batch_mean,batch_var,beta,scale,epsilon)
# Add 2-layer-MLP
h1_units=128
h2_units=64
with tf.name_scope("FC-Layer-1"):
W = tf.Variable(tf.truncated_normal(shape=[384,h1_units], stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[h1_units]), name="b")
self.hidden_1 = tf.nn.relu(tf.nn.xw_plus_b(self.BN,W,b,name="fc1"))
with tf.name_scope("FC-Layer-2"):
W = tf.Variable(tf.truncated_normal(shape=[h1_units,h2_units], stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[h2_units]), name="b")
self.hidden_2 = tf.nn.relu(tf.nn.xw_plus_b(self.hidden_1,W,b,name="hidden"))
# Final scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
# shape=[num_filters_total, num_classes],
shape=[h2_units,num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes], name="b"))
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.hidden_2, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
# Calculate Mean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss
# Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
GitHub : https://github.com/paradise6/DetectMaliciousURL