DRMM model
Paper 的引用:
Guo J, Fan Y, Ai Q, et al. A deep relevance matching model for ad-hoc retrieval[C]//Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. ACM, 2016: 55-64.
Retrieval or Matching
论文中说到:
However, we argue that the ad-hoc retrieval task is mainly about relevance matching while most NLP matching tasks concern semantic matching, and there are some fundamental differences between these two matching tasks.
理解这句话,就是ad-hoc是根据query去找到相关性更大的documents, 这里的相关性可以理解为 相同关键字,相同主旨等等,但是句式(问句&答句),长短(短查询&长文本)等等可能都不相同;
而NLP的matching tasks则是指两句话的大意相同,或者不严谨的说,两句话出现的语境(上下文)相似。
所以NLP的matching tasks其实是更严谨的一种matching
Histogram & Matching matrix
paper中说到,这个模型更像是interaction-focused model 而不是 representation-focused model
A major problem is that the size of local interactions is not fixed due to the varied lengths of queries and documents.
传统的Attention 用到的其实是Matching matrix, 这也导致了其实我们在实现的时候有时候是很受限的
例如:

那么Matching matrix的优点在于:preserving the sequential term orders
Clearly the matching matrix is a position preserving representation, which is useful if the learning task is position related.
那么对于Ad-hoc的查询来说,可能相匹配的关键词出现的position就没那么重要(尤其是考虑到doc的长度问题)
所以这个Paper提出了一种Histogram的方法:
可以将query和document的term两两比对,计算一个相似性。再将相似性进行统计成一个直方图的形式。例如:
Query:”car” ;
Document:”(car,rent, truck, bump, injunction,runway)。
两两计算相似度为(1,0.2,0.7,0.3,-0.1,0.1)
将[-1,1]的区间分为{[−1,−0.5], [−0.5,−0], [0, 0.5], [0.5, 1], [1, 1]} 5个区间。
可将原相似度进行统计,可以表示为[0,1,3,1,1]。
*这里引用自 http://www.sohu.com/a/131458518_505880
这样用query中的每个word去查询document的时候都是得到一个等长的vector,为后面的处理也就做好了铺垫。
所以这样的话,其实对于每个query(length 为 l l ),得到的就是一个 l∗s l ∗ s 的一个矩阵,( s s 是区间的个数)
这个维度是和query的length相关的
Model
形式化表示:
有一个query q={w(q)1,...,w(q)M} q = { w 1 ( q ) , . . . , w M ( q ) }
和一个document d={w(d)1,...,w(d)N} d = { w 1 ( d ) , . . . , w N ( d ) }
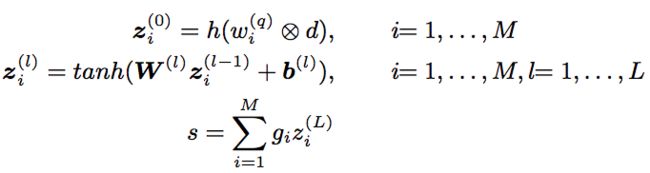
那这里的 ⨂ ⨂ 代表interaction,也就是matching function for each pair of word vectors; h() h ( ) 就是上述的将相似度映射到一个fixed length histogram vector的函数了。
将上述的处理结果过L个feed forward layer之后;
最后的 s s 就是一个query对一个特定的document的匹配分数。
那其实这里对于这个query, 还有个参数权重 gi (i=1,...,M) g i ( i = 1 , . . . , M )
是通过一个Term Gating Network 得到的;
Term Gating Network
In this way, our model can explicitly model query term importance. This is achieved by using the term gating network, which produces an aggregation weight for each query term controlling how much the relevance score on that query term contributes to the final relevance score.
如文中所说,这个Term Gating Network是为了衡量query中term的importances的权重。
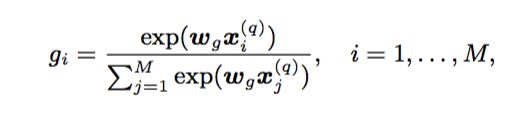
例如本文的一种方法就是用query中每个term的idf值(上述公式中的 x(q)i x i ( q ) 来做softmax, 这里公式里的 wg w g 就是一个常数参数了。
训练 & 实现 & 场景
Since the ad-hoc retrieval task is fundamentally a ranking problem, we employ a pairwise ranking loss such as hinge loss to train our deep relevance matching model. Given a triple (q, d+, d−), where document d+ is ranked higher than document d− with respect to query q,the loss function is defined as:
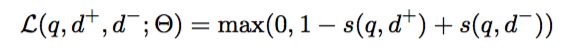
这个loss实现我暂时找到了一个链接:
Pytorch如何自定义损失函数(Loss Function)? - vector的回答 - 知乎
https://www.zhihu.com/question/66988664/answer/247952270
先闭着眼睛相信只要loss能正向跑,backward()就肯定work
接下来简单实现试一下。
这个Model在IR中很合适,因为基本上是query based的方法,model中的中间变量的参数也大多和query有关
如上文中:Histogram中的 z z 的维度是和query的length相关
如果也将这种方法迁移到NLP的pairwised matching problems上,可能不太合适(因为毕竟是一对多,而不是装好的pairs),但是如果要做,就要好好考虑一下如何装数据。