修改pytorch提供的resnet接口实现Kaggle猫狗识别
一,数据集
Kaggle猫狗大战的数据集下载链接:https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition

二,导入resnet(以resnet18为例)
from torchvision.models.resnet import resnet18
resnet = resnet18(pretrained=True)pretrained = True,表示该resnet的参数已经用Imagenet训练好了,pretrained = False则表示resnet没被训练过。
三,打印resnet18
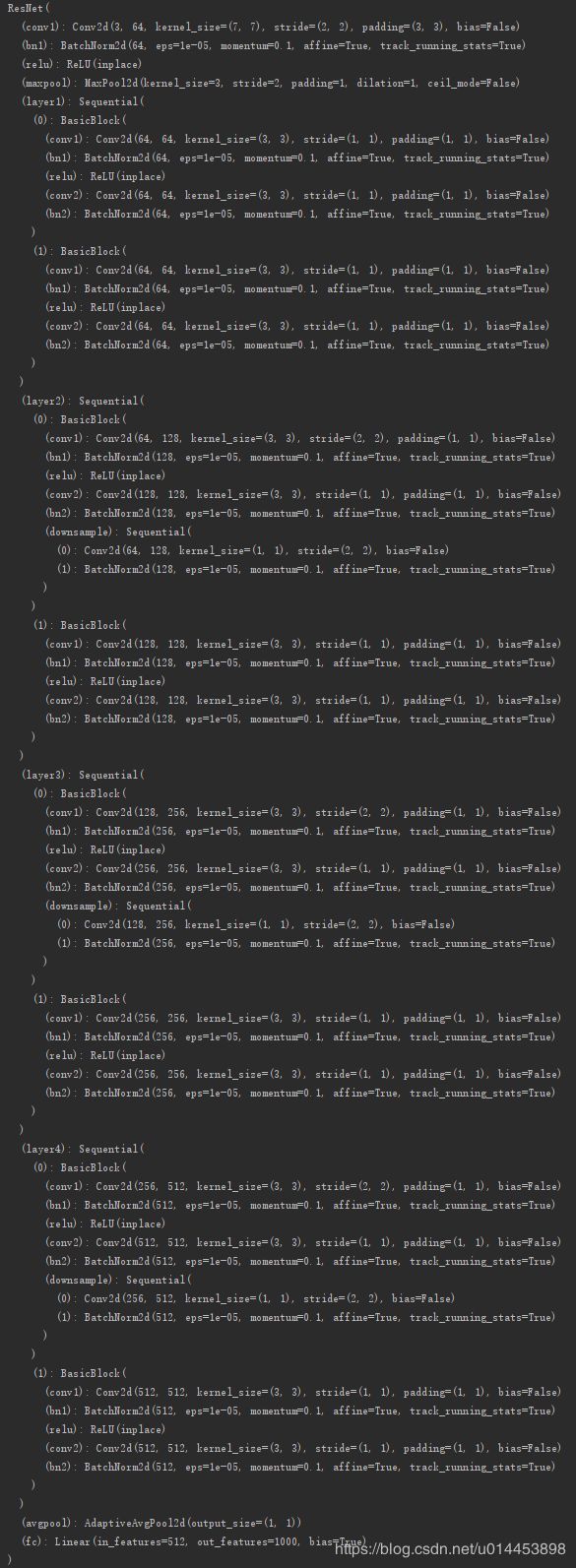
我们可以看到,pytorch的resnet18接口的最后一层fc层的输出维度是1000。这明显不符合猫狗大战数据集,因为猫狗大战数据集是二分类的,所以最后一层fc输出的维度已经是2才对。因此我们需要对resnet18进行最后一层的修改。
四,修改resnet
一个继承nn.module的model它包含一个叫做children()的函数,这个函数可以用来提取出model每一层的网络结构,在此基础上进行修改即可,修改方法如下(去除后一层):
resnet_layer = nn.Sequential(*list(model.children())[:-1])然后再加回一层参数正确的fc层即可:
class Net(nn.Module):
def __init__(self, model):
super(Net, self).__init__()
# 取掉model的后1层
self.resnet_layer = nn.Sequential(*list(model.children())[:-1])
self.Linear_layer = nn.Linear(512, 2) #加上一层参数修改好的全连接层
def forward(self, x):
x = self.resnet_layer(x)
x = x.view(x.size(0), -1)
x = self.Linear_layer(x)
return x
resnet = resnet18(pretrained=True)
model = Net(resnet)打印修改后的resnet18看看:(print(model))

可以看到,最后一层变成了输出维度为2的fc层。
五,完整训练代码:
from torchvision.models.resnet import resnet18
import os
import random
from PIL import Image
import torch.utils.data as data
import numpy as np
import torchvision.transforms as transforms
import torch
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torch.optim.lr_scheduler import *
import torchvision.transforms as transforms
import numpy as np
import os
class DogCat(data.Dataset):
def __init__(self, root, transform=None, train=True, test=False):
self.test = test
self.train = train
self.transform = transform
imgs = [os.path.join(root, img) for img in os.listdir(root)]
# test1: data/test1/8973.jpg
# train: data/train/cat.10004.jpg
if self.test:
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-2].split('/')[-1]))
else:
imgs = sorted(imgs, key=lambda x: int(x.split('.')[-2]))
imgs_num = len(imgs)
if self.test:
self.imgs = imgs
else:
random.shuffle(imgs)
if self.train:
self.imgs = imgs[:int(0.7 * imgs_num)]
else:
self.imgs = imgs[int(0.7 * imgs_num):]
# 作为迭代器必须有的方法
def __getitem__(self, index):
img_path = self.imgs[index]
if self.test:
label = int(self.imgs[index].split('.')[-2].split('/')[-1])
else:
label = 1 if 'dog' in img_path.split('/')[-1] else 0 # 狗的label设为1,猫的设为0
data = Image.open(img_path)
data = self.transform(data)
return data, label
def __len__(self):
return len(self.imgs)
# 对数据集训练集的处理
transform_train = transforms.Compose([
transforms.Resize((256, 256)), # 先调整图片大小至256x256
transforms.RandomCrop((224, 224)), # 再随机裁剪到224x224
transforms.RandomHorizontalFlip(), # 随机的图像水平翻转,通俗讲就是图像的左右对调
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.2225)) # 归一化,数值是用ImageNet给出的数值
])
# 对数据集验证集的处理
transform_val = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 若能使用cuda,则使用cuda
trainset = DogCat(r'F:\dataset\Cats_Dogs\train\all', transform=transform_train)
valset = DogCat(r'F:\dataset\Cats_Dogs\train\all', transform=transform_val)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=20, shuffle=True, num_workers=0)
valloader = torch.utils.data.DataLoader(valset, batch_size=20, shuffle=False, num_workers=0)
def get_acc(output, label):
total = output.shape[0]
_, pred_label = output.max(1)
num_correct = (pred_label == label).sum().item()
return num_correct / total
def train(epoch):
print('\nEpoch: %d' % epoch)
scheduler.step()
model.train()
train_acc = 0.0
for batch_idx, (img, label) in enumerate(trainloader):
image = Variable(img.cuda())
label = Variable(label.cuda())
optimizer.zero_grad()
out = model(image)
#print('out:{}'.format(out))
#print(out.shape)
#print('label:{}'.format(label))
loss = criterion(out, label)
loss.backward()
optimizer.step()
train_acc = get_acc(out, label)
print("Epoch:%d [%d|%d] loss:%f acc:%f" % (epoch, batch_idx, len(trainloader), loss.mean(), train_acc))
def val(epoch):
print("\nValidation Epoch: %d" % epoch)
model.eval()
total = 0
correct = 0
with torch.no_grad():
for batch_idx, (img, label) in enumerate(valloader):
image = Variable(img.cuda())
label = Variable(label.cuda())
out = model(image)
_, predicted = torch.max(out.data, 1)
total += image.size(0)
correct += predicted.data.eq(label.data).cpu().sum()
print("Acc: %f " % ((1.0 * correct.numpy()) / total))
class Net(nn.Module):
def __init__(self, model):
super(Net, self).__init__()
# 取掉model的后1层
self.resnet_layer = nn.Sequential(*list(model.children())[:-1])
self.Linear_layer = nn.Linear(512, 2) #加上一层参数修改好的全连接层
def forward(self, x):
x = self.resnet_layer(x)
x = x.view(x.size(0), -1)
x = self.Linear_layer(x)
return x
if __name__ =='__main__':
resnet = resnet18(pretrained=True)
model = Net(resnet)
model = model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=5e-4) # 设置训练细节
scheduler = StepLR(optimizer, step_size=3)
criterion = nn.CrossEntropyLoss()
for epoch in range(1):
train(epoch)
val(epoch)
torch.save(model, 'modelcatdog.pth') # 保存模型
直接训练 一个epoch效果就很好了。
运行结果:
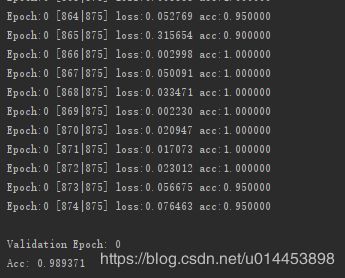
可以看到训练完后,验证的正确率约有0.99。
六,预测代码:
import torch
import cv2
import torch.nn.functional as F
from dogcat import Net ##重要,虽然显示灰色(即在次代码中没用到),但若没有引入这个模型代码,加载模型时会找不到模型
from torchvision import datasets, transforms
from PIL import Image
classes = ('cat', 'dog')
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = torch.load('modelcatdog.pth') # 加载模型
model = model.to(device)
model.eval() # 把模型转为test模式
img = cv2.imread("cat2.jpg") # 读取要预测的图片
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
trans = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
img = trans(img)
img = img.to(device)
img = img.unsqueeze(0) # 图片扩展多一维,因为输入到保存的模型中是4维的[batch_size,通道,长,宽],而普通图片只有三维,[通道,长,宽]
output = model(img)
prob = F.softmax(output, dim=1) # prob是2个分类的概率
print(prob)
value, predicted = torch.max(output.data, 1)
print(predicted.item())
print(value)
pred_class = classes[predicted.item()]
print(pred_class)
效果:
从网上找到一张猫的图片输入:cat.jpg

结果:

可以看到,第一个(即猫)的概率为0.99902,第二个(狗)的概率为0.00097612。效果还是 挺不错的。