深度构建用户画像|数据标签,关联分析,RFM,用户体系
无论是提供商品还是服务,用户画像都是数据挖掘工作的重要一环。一个准确和完整的用户画像甚至可以说是许多互联网公司赖以生存的宝贵财富。我们也已经听过了无数用户画像的神奇功能和成功案例,比如亚马逊,淘宝的机器学习团队使用用户的浏览行为,购物车状态和购买记录开发关联推荐系统,使点击率和销量大幅提升;比如应用市场根据过往APP安装记录记对每个使用者进行精准推荐;再比如音乐,图书和新闻网站通过协同过滤的方式为用户呈现个性化的定制内容。
对于消费品公司而言,虽说用户行为数据的丰富程度和互联网产品相比稍显逊色,但也拥有庞大的用户信息和交易数据沉淀散落在各个IT系统中,而且更真实,噪音更少。只不过在传统消费品公司里会编程,会处理数据的人要比互联网公司少太多太多。在我们深入了解了这些用户信息和交易数据,并对它们进行了清洗,汇总,打通之后,发现数据质量要比我们想象的好很多,可以支撑许多有意思的用户画像的建立。在这里我会分享一些画像的流程和思路,供大家参考。
1、数据标签化
用户画像的底层是机器学习,那么无论是要做客户分群还是精准营销,都先要将用户数据进行规整处理,转化为相同维度的特征向量,诸多华丽的算法才可以有用武之地,像是聚类,回归,关联,各种分类器等等。对于结构化数据而言,特征提取工作往往都是从给数据打标签开始的,比如购买渠道,消费频率,年龄性别,家庭状况等等。好的特征标签的选择可以使对用户刻画变得更丰富,也能提升机器学习算法的效果(准确度,收敛速度等)。
我们在项目中根据不同维度提取了数十个多个标签,图7展示了其中的一部分。这些标签主要有三个来源:
第一类是在IT系统中可以取得的信息,比如办会员卡时留下的信息(性别,年龄,生日),购买渠道,积分情况等;
第二类是可以通过计算或是统计所获得的,比如用户对某类促销活动的参与程度,对某种颜色/款式商品的偏好程度,是否进行过跨品牌的购买等;
第三类则是通过推测所得,比如送货地址中出现“宿舍”,“学校”,“大学”等字样,则用户身份可以推测为学生,出现“腾讯大厦”,“科技园”等信息时,则可判断是上班族,并有很大概率是技术从业者。
在标签的设计上也带有较强的行业性,比如是否偏好购买当季爆款或是新品多于经典款(时尚度);是否更倾向购买低价或打折商品(价格敏感度);是否喜欢购买高价商品或限量版(反向价格敏感度)。

对于已经打好的标签,根据不同的分析场景进行离散化,或将分类类型的标签拆成多个0/1标签,就可以进行一些机器学习的建模了,比如聚类,分类,预测,或者关联性分析,最终生成的向量维度在数千个。
2、关联性分析
关联性分析(Association rule learning)是在零售行业中应用最广泛的一种机器学习方法,营销学里经典的“啤酒/尿布”(超市里购买尿布的消费者往往同时购买啤酒)案例也已经是家喻户晓。虽然后来被证实这是一个为了教学目的而虚构出来的案例,但从其上镜率也可以看得出关联性分析在零售领域的重要程度,或许这个例子在国内改成“泡面/火腿肠”会更亲切。
关联性分析的相关文章有非常多,支持度(Support),置信度(Confidence)和增益(Lift)这些基本概念的介绍在这里就不赘述了,各位如果有兴趣可以参见Wikipedia的 Association rule learning 页面。
和购物篮关联规则不同,我们数据挖掘过程中的基本单位是用户,而特征向量则是基于提取出的用户标签而构建的,下表是一个简单的示例。
第一个例子

我们获得了一个NxM的特征矩阵,N为用户数,量级在百万级,M为特征维度,约数千个的二元标签。基于这个特征矩阵我们使用了最基础的Apriori算法计算相关度,并在支持度,置信度和增益三个层面设置threshold,输出符合要求的关联规则。
由于输出的关联规则可能涉及到客户隐私,在这里仅做一个示例。下表中的前项(antecedent)为用户的所在地,后项(consequent)为最高的活动敏感度, 结果如下:
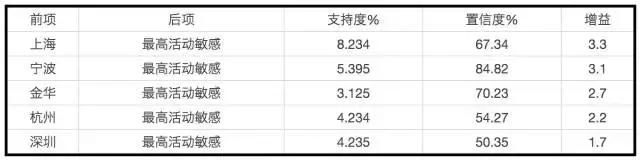
可见上以及江浙地区对于促销活动的敏感度和参与度是最高的,增益均高于两倍,而上海则是达到了3.3倍之多。
第二个例子
另一个例子是颜色的关联规则,下表展示了用户对于不同颜色的产品以及SKU之间的偏好特征,可见某些用户是有较强的颜色偏向的,比如金色和银色之间,咖啡色和绿色之间等等。如果运用到商业实践,因为在买过紫色和杏色的用户中,接下来会比较会买金色;把这些数据给到地面团队或者线上团队,这时候推荐颜色以及配货就比较轻松一些。
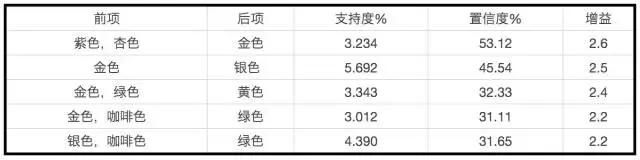
值得注意的是,做关联分析时要确保前后项以及的独立性(independence)。由于在提取特征时有些维度本身就是从相同或相关的字段提取出来的,比如用户的星座以及出生月份,如果不做控制的话就会得出“11月出生的天蝎座特别多”这样让人啼笑皆非的规则。
3、RFM Model
RFM模型是用户价值研究中的经典模型,基于近度(Recency),频度(Frequency)和额度(Monetory)这3个指标对用户进行聚类, 找出具有潜在价值的用户, 从而辅助商业决策,提高营销效率。如果对RFM模型的细节感兴趣可以参见Wikipedia中有关 RFM模型的页面。
RFM建模所需要的数据源是相对简单的,只用到了购买记录中的时间和金额这两个字段。我们基于交易数据中用户的最后一次的购买时间,购买的次数以和频率,以及平均/总消费额对每个用户计算了三个维度的标准分。然后我们对于三个维度赋予了不同的权重,再基于加权后的分值应用K-Means进行聚类,根据每种人群三个维度与平均值之间的高低关系,确定哪些是需要保持用户,哪些是需要挽留的用户,哪些是需要发展的用户等。
在将这些客户圈出之后,便可以对不同客户群使用不同针对性地营销策略(引导,唤醒等),提高复购率与转化率。值得注意的是,三个维度的权重制定并没有统一的标准,比较通用的方法是用层次分析法(AHP),再结合行业以及具体公司的特点进行优化。
图8是通过RFM模型进行用户聚类后的结果,可以清楚看到几个人群用户的数量以及比例。同时这些分群也会作为标签重新输入至用户画像以及CRM当中,作为圈定特定用户群以及营销的入口。

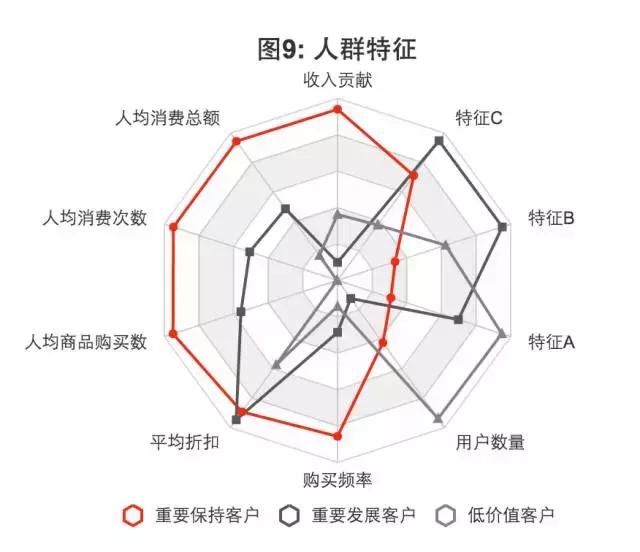
图9展示了用户群之间在各个维度上的分布。消费,金额,频率这些模型直接相关的标签上自然有非常显著的差异,同时在一些垂直(orthogonal)的特征维度上也有很大的不同。
4、用户体系
最后,对消费品公司而言,所有在数据挖掘和用户画像方面的投入,根本目的还是要提升业务表现,所以如何将数据挖掘的结果进行落地就变成了尤为关键的一环。对于用户画像所输出的所有标签和关联规则,都需要通过某种渠道抵达用户群。
这种渠道可以是一个强大的CRM系统,可以通过不同的标签圈定用户群,定向发布营销方案;也可以是一个会员客户端,推送个性化的打折券或新品推荐;甚至是自营电商,实现像天猫京东一样的数据自生产和自消费的循环。