XZ_Python之使用关键词抓取京东搜索页面数据
爬虫的基本步骤:访问网络、访问特定的网站、抓取所需要的页面或者json文件,抓取到本地,按照需求进行格式化,然后写入数据库,以备以后分析。
爬虫的第一步是分析
首先在京东的页面,搜索任意想买的东西,我搜索的是“裤子”,在火狐浏览器当前页面中,右键-查看页面元素,找到商品的部分代码,分析想要抓取的部分的代码,例如我抓取的数据是所有的裤子的返回数据,获取url、title、钱数等生成一个json数据,首先就需要分析一个商品的HTML代码是什么,如下图:
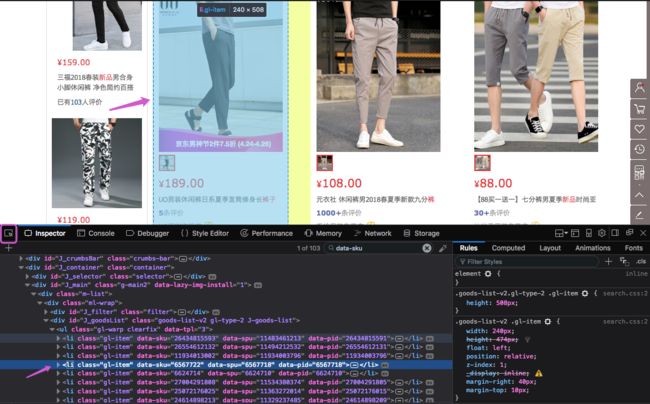
点击左侧框选部分,然后,鼠标移动到底下的代码,就可以快速定位到商品的位置,或者鼠标移动到商品,定位代码的位置。这样就找到了我们需要抓取的代码的格式。
从网页数据中,抓取到 class 为 gl-item 的列表,拿到里面的链接、价格、标题和商品id,并以json的格式存放数据。
Python3的代码实现:
import urllib
import json
from urllib import parse,request
from bs4 import BeautifulSoup
# 根据页数和keywords采集内容
def get_content_from_keyword(keyword,page=1):
# keyword_encode = parse.quote(keyword) # unquote 解码
# url = "https://search.jd.com/s_new.php?keyword=%s&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%s&page=%d&s=51&click=0"%(keyword_encode,keyword_encode,page)
# r = request.urlopen(url)
params = {'keyword':keyword,'page':page,'enc':'utf-8','area':1,'wq':keyword}
data = parse.urlencode(params)
opener = request.urlopen("https://search.jd.com/Search?"+data)
content = opener.read()
opener.close()
return content # .decode('utf-8')
# 分析数据,生成字典 res
if __name__ == '__main__':
keyword = '裤子'
content = get_content_from_keyword(keyword,3)
soup = BeautifulSoup(content,"html.parser")
goods_info = soup.select(".gl-item")
res = []
for good_info in goods_info:
data = {}
good_info_dict = good_info.select(".p-name.p-name-type-2 a")[0].attrs
data['data_sku'] = good_info.attrs['data-sku']
data['title'] = good_info_dict['title']
data['href'] = good_info_dict['href']
data['price'] = good_info.select('.p-price')[0].text.strip()
res.append(data)
print("\n\n\n商品信息:\n\n\n",goods_info,"\n\n\n格式化数据:",json.dumps(res,sort_keys=True, indent=2))抓取结果为:

如果我们想获得页面的请求网址,点击“Network”一栏,可以清晰的看到请求头、请求的URL、请求参数等,如下图:
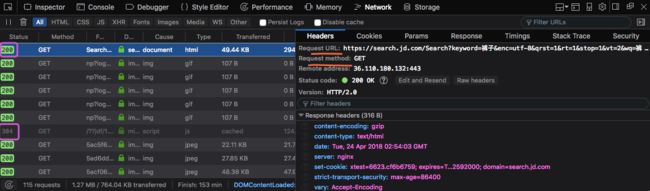
从上图中,可以清楚地查看到请求的URL和请求的方式(GET/POST),其中Status为200的表示请求成功,Status为304的表示有缓存,不需要重新发送所请求的资源。