【爬虫】获取新郑机场出租车实时数据
原文链接:http://www.changxuan.top/?p=463
八月十五的晚上,一个同学来找我要机场出租车的数据!Excuse me,我们不生产数据、只做数据的搬运工 。
随后我在各大平台上都没找到合适的数据集,找到一些之前其他比赛的数据集,但是针对特定机场的出租车数据除了“飞常准”上有一份浦东机场的就没找到别的!想想也是,谁没事统计这个东西!不过知乎上的大神就是多啊,我找着找着看到一个人给了个链接:
http://www.whalebj.com/xzjc/default.aspx?tdsourcetag=s_pctim_aiomsg
打开后如下图所示,
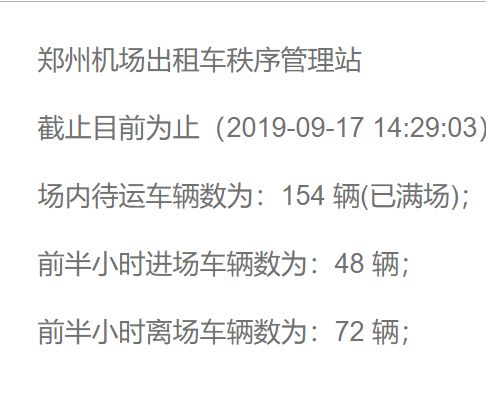
看样子这个数据应该可以应付一下了!在频繁的刷新网页之后,初步判断没有反爬虫措施就马上打开 PyCharm 开始写程序(写的仓促,能跑即可)
import requests
from lxml import etree
import time
import csv
import re
header = ['时间', '场内待运车辆数', '前半小时进场车辆数', '前半小时离场车辆数']
with open('./taxi_info_xzjc.csv', encoding='UTF-8', mode='w') as f:
f_csv = csv.writer(f)
f_csv.writerow(header)
f.close()
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
}
def save_data(data):
with open('./taxi_info_xzjc.csv', encoding='UTF-8', mode='a+') as f:
f_csv = csv.writer(f)
f_csv.writerow(data)
f.close()
def get_info(url):
res = requests.get(url, headers=headers)
if res.status_code == 200:
selector = etree.HTML(res.text)
at_time = selector.xpath('//*[@id="Label_Msg"]/text()[3]')[0][7:].rstrip(')').lstrip()
car_num_in_room = selector.xpath('//*[@id="Label_Msg"]/text()[5]')[0]
car_num_in_room_num = re.search(r"\d+", car_num_in_room).group()
before_half_hour_in_car = selector.xpath('//*[@id="Label_Msg"]/text()[7]')[0]
before_half_hour_in_car_num = re.search(r"\d+", before_half_hour_in_car).group()
before_half_hour_out_car = selector.xpath('//*[@id="Label_Msg"]/text()[9]')[0]
before_half_hour_out_car_num = re.search(r"\d+", before_half_hour_out_car).group()
tup = (at_time, car_num_in_room_num, before_half_hour_in_car_num, before_half_hour_out_car_num)
save_data(tup)
if __name__ == '__main__':
url = "http://www.whalebj.com/xzjc/default.aspx?tdsourcetag=s_pctim_aiomsg"
while 1:
get_info(url)
time.sleep(10)
测试可以抓取数据之后,便扔到服务器上执行下面的命令,便可以安心睡觉了!
setsid python -u getTaxiInfo.py > run.log 2>&1
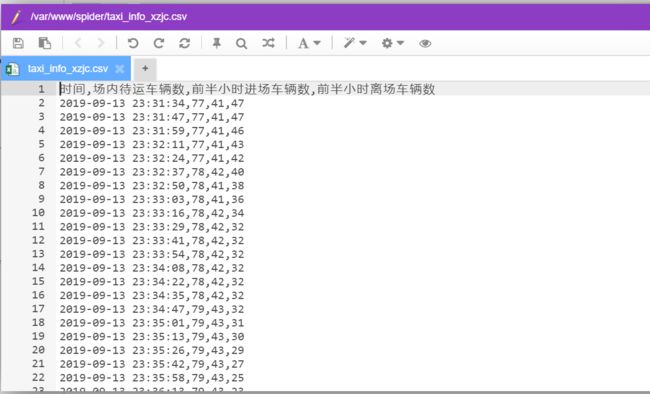
第二天早晨,查看一下结果:
微信订阅号
——Worldhello 给你说些好玩的事情
