用PCA,LDA,KNN对MNIST数据集分类(Python)
主成分分析
对于高维空间中 x x x, 我们寻求线性变换,
y = W T x , w h e r e x ∈ R n , W ∈ R m × d , y ∈ R d , d < m . y=W^Tx,\quad where \; x\in \mathbb{R}^n,W\in \mathbb{R}^{m\times d},y\in\mathbb{R}^d,d
我们采用可重构性观点, 即样本到此超平面的距离都足够近。\
假设投影变换是正交变换,设样本点 x i x_i xi 在新坐标系下的坐标为:
y i = ( y i 1 , y i 2 , ⋯ , y i d ) T ∈ R d y_i=(y_{i1},y_{i2},\cdots, y_{id})^T\in \mathbb{R}^d yi=(yi1,yi2,⋯,yid)T∈Rd
于是在新的坐标系下, x i x_i xi 的新表示为
x ^ i = ∑ j = 1 d y i j w j , j = 1 , 2 , ⋯ , n . \hat{x}_i=\sum_{j=1}^{d}y_{ij}w_j,\quad j=1,2,\cdots, n. x^i=j=1∑dyijwj,j=1,2,⋯,n.经计算我们有
∑ i = 1 n ∥ x − x ^ i ∥ 2 2 = − T r ( W T ∑ i = 1 n x i x i T W ) + c o n s t \sum_{i=1}^{n}\Vert x-\hat{x}_i\Vert_2^2=-\mathbf{Tr}\bigg(W^T\sum_{i=1}^nx_ix_i^TW\bigg)+const i=1∑n∥x−x^i∥22=−Tr(WTi=1∑nxixiTW)+const故我们的优化问题转化为
max W ∈ R m × d T r ( W T X X T W ) , s . t . W W T = I . \max\limits_{\mathbf{W}\in \mathbb{R}^{m\times d}}\quad \mathbf{Tr}\bigg(\mathbf{W^TXX^TW}\bigg),\quad s.t.\;\mathbf{WW^T=I}. W∈Rm×dmaxTr(WTXXTW),s.t.WWT=I.
采用拉格朗日乘子法,经过矩阵计算我们有
X X T W = λ W , \mathbf{XX^TW}=\lambda \mathbf{W}, XXTW=λW,
只需要对协方差矩阵 X X T \mathbf{XX^T} XXT 进行特征值分解, 并对特征值进行排序, 取前 d d d 个特征值对应的特征向量构成变换矩阵 W \mathbf{W} W。
线性判别分析
给定样本集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) } , y i ∈ { 0 , 1 } , D=\{(\mathbf{x_1},y_1),(\mathbf{x_2},y_2),\cdots, (\mathbf{x_n},y_n)\},y_i\in \{0,1\}, D={(x1,y1),(x2,y2),⋯,(xn,yn)},yi∈{0,1}, 令 X i , μ i , Σ i \bm{X}_i,\bm{\mu}_i,\bm{\Sigma}_i Xi,μi,Σi 分别表示第 i ∈ { 0 , 1 } i\in \{0,1\} i∈{0,1} 类的示例集合,,均值向量,协方差矩阵。考虑线性变换 y = w T x \textcolor{blue}{y=\bm{w^T}x} y=wTx,对两类样本的中心点,在直线上的投影分别为 w T Σ 0 w \bm{w^T\Sigma}_0 \textbf{w} wTΣ0w 和 w T Σ 1 w \bm{w^T\Sigma}_1\textbf{w} wTΣ1w.
欲使同类样本的投影点尽可能接近, 可以让同类样本的协方差尽可能小,即 w T Σ 0 w + w T Σ 1 w 尽 可 能 小 ; \bm{w}^T\bm{\Sigma_0}\bm{w}+\bm{w^T\Sigma}_1\bm{w}\;尽可能小; wTΣ0w+wTΣ1w尽可能小;欲使异类样本的投影点尽可能远离,则可让类中心之间的距离尽可能大,即 ∥ w T μ 0 − w T μ 1 ∥ 2 2 尽 可 能 大 . \Vert \bm{w^T\mu}_0-\bm{w^T\mu}_1\Vert_2^2\;尽可能大. ∥wTμ0−wTμ1∥22尽可能大.
于是, 我们可以最大化如下函数
J ( W ) = ∥ w T μ 0 − w T μ 1 ∥ 2 2 w T Σ 0 w + w T Σ 1 w = w T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w w T ( Σ 0 + Σ 1 ) w J(W)=\frac{\Vert \bm{w^T\mu}_0-\bm{w^T\mu}_1\Vert _2^2}{\bm{w^T\Sigma}_0\bm{w}+\bm{w^T\Sigma}_1\bm{w}}=\frac{\bm{w^T(\mu_0-\mu_1)(\mu_0-\mu_1)^Tw}}{\bm{w^T(\Sigma_0+\Sigma_1)w}} J(W)=wTΣ0w+wTΣ1w∥wTμ0−wTμ1∥22=wT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)Tw
我们定义类内散度矩阵 S w = Σ 0 + Σ 1 = ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T + ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T \bm{S}_w=\bm{\Sigma}_0+\bm{\Sigma}_1=\sum_{\mathbf{x}\in X_0}(\mathbf{x}-\bm{\mu}_0)(\bm{x}-\bm{\mu}_0)^T+\sum_{\mathbf{x}\in X_1}(\mathbf{x}-\bm{\mu}_1)(\bm{x}-\bm{\mu}_1)^T Sw=Σ0+Σ1=x∈X0∑(x−μ0)(x−μ0)T+x∈X1∑(x−μ1)(x−μ1)T
定义类间散度矩阵
S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T , \bm{S}_b=(\bm{\mu}_0-\bm{\mu}_1)(\bm{\mu}_0-\bm{\mu}_1)^T, Sb=(μ0−μ1)(μ0−μ1)T,
此时目标函数可以写为\textbf{广义Rayleigh熵}:
J ( w ) = w T S b w w T S w w . \textcolor{blue}{J(w)=\frac{\bm{w^T}\bm{S}_b\bm{w}}{\bm{w^TS}_w\bm{w}}}. J(w)=wTSwwwTSbw. 由于目标函数值与长度无关, 故上述问题可转化为
max w T S b w , s . t . w T S w w = 1. \max\quad \bm{w}^T\bm{S}_b\bm{w},\quad s.t.\quad \bm{w}^T\bm{S}_w\bm{w}=1. maxwTSbw,s.t.wTSww=1.
由拉格朗日乘子法, 有
S b w = λ S w w ⇒ S w − 1 S b w = λ w . \bm{S}_b\bm{w}=\lambda \bm{S}_w\bm{w}\;\Rightarrow\;\bm{S}_w^{-1}\bm{S}_b\bm{w}=\lambda\bm{w}. Sbw=λSww⇒Sw−1Sbw=λw.
代入计算有
w = S w − 1 ( μ 0 − μ 1 ) . \textcolor{red}{\bm{w}=\bm{S}_w^{-1}(\bm{\mu}_0-\bm{\mu}_1)}. w=Sw−1(μ0−μ1).
上述是两类LDA算法, 我们将其稍加推广,便得到了我们下面问题中将会使用的多类LDA算法, 设类别数为 c c c, 定义全局散度矩阵
S t = S w + S b = ∑ i = 1 n ( x i − μ ) ( x i − m u ) T , μ = ∑ i = 1 n x i ; \textcolor{blue}{\bm{S}_t=\bm{S}_w+\bm{S}_b}=\sum_{i=1}^n(\bm{x}_i-\bm{\mu})(\bm{x}_i-\bm{mu})^T,\quad \bm{\mu}=\sum_{i=1}^{n}\bm{x}_i; St=Sw+Sb=i=1∑n(xi−μ)(xi−mu)T,μ=i=1∑nxi;
定义类间散度矩阵 S w = ∑ j = 1 c S w j , S w j = ∑ x ∈ X j ( x − μ j ) ( x − μ j ) T , μ j = 1 n j ∑ x ∈ X j X ; \textcolor{blue}{\bm{S}_w=\sum_{j=1}^c\bm{S}_{wj},}\quad S_{wj}=\sum_{\bm{x}\in X_j}(\bm{x}-\bm{\mu}_j)(\bm{x}-\bm{\mu}_j)^T,\quad \bm{\mu}_j=\frac{1}{n_j}\sum_{\bm{x\in X_j}}\bm{X}; Sw=j=1∑cSwj,Swj=x∈Xj∑(x−μj)(x−μj)T,μj=nj1x∈Xj∑X;
定义类间散度矩阵
S b = S t − S w = ∑ j = 1 c n j ( μ j − μ ) ( μ j − μ ) T , \textcolor{blue}{\bm{S}_b=\bm{S}_t-\bm{S}_w}=\sum_{j=1}^{c}n_j(\bm{\mu}_j-\bm{\mu})(\bm{\mu}_j-\bm{\mu})^T, Sb=St−Sw=j=1∑cnj(μj−μ)(μj−μ)T,
我们求解下述优化问题
max T r ( W T S b W ) T r ( W T S w W ) , s . t . W T W = I . \max\quad \frac{\mathbf{Tr}\bigg(\mathbf{W}^T\bm{S}_b\bm{W}\bigg)}{\mathbf{Tr}\bigg(\bm{W^TS}_w\bm{W}\bigg)},\quad s.t.\quad \mathbf{W^TW=I}. maxTr(WTSwW)Tr(WTSbW),s.t.WTW=I.
MNIST数据集
我们采用pytorch 来实现代码, 首先加载 MNIST 数据集,
# mnist classification
import torch
import torchvision
import numpy as np
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
import time
'''download mnist dataset '''
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])),
shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])),
shuffle=False)
对上述数据集稍作处理,(归一化)
X_train = train_loader.dataset.train_data.view(60000, 28*28).numpy()
X_train_label = train_loader.dataset.train_labels.numpy()
X_test = test_loader.dataset.test_data.view(10000, 28*28).numpy()
X_test_label = test_loader.dataset.test_labels.numpy()
print('Train:', X_train.shape, 'Label:', X_train_label.shape)
# Train: (60000, 784) Label: (60000,)
mms = MinMaxScaler()
X_train = mms.fit_transform(X_train)
X_test = mms.fit_transform(X_test)
PCA降维:我们将维数分为5个部分,【50,100,200,300,400】(经过PCA之后的维数)
KNN(k近邻算法)中近邻个数取1,3
LDA:降维维数需要讨论。我们以k近邻数为3,PCA维数为50,观测不同LDA维数对应的分类精度,如下图:
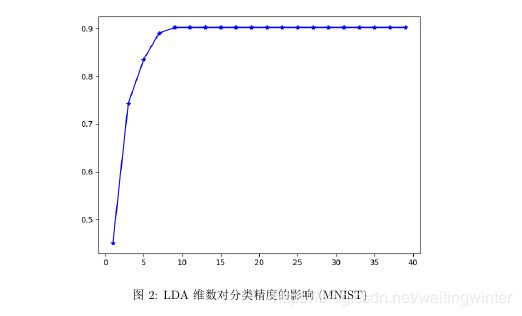
故我们取LDA降维后的维数是PCA降维后维数的1/2,进行测试
'''PCA Dimensionality Reduction'''
# 原始数维数为784,降维后的维数为N1,实际取N1={50,100,200,300,400}
M1 = np.array([50, 100, 200, 300, 400])
M2 = np.array([1, 3])
accuracy = np.zeros([5, 2])
time1 = np.zeros([5, 2])
accuracy_no = np.zeros([5, 2])
time_no = np.zeros([5, 2])
for i in range(len(M1)):
for j in range(len(M2)):
N1 = M1[i]
N2 = M2[j]
pca = PCA(n_components=N1)
pca.fit(X_train)
train_data_pca = pca.transform(X_train)
test_data_pca = pca.transform(X_test)
knn = KNeighborsClassifier(n_neighbors=N2, p=2, metric='minkowski')
mms = MinMaxScaler()
N2 = N1 / 2
start_time = time.time()
lda = LDA(n_components=N2)
lda.fit(train_data_pca, X_train_label)
train_data_lda = lda.transform(train_data_pca)
test_data_lda = lda.transform(test_data_pca)
train_data_lda_std = mms.fit_transform(train_data_lda)
knn.fit(train_data_lda_std, X_train_label)
test_pred = knn.predict(mms.fit_transform(test_data_lda))
time1[i][j] = time.time() - start_time
accuracy[i][j] = np.mean(np.equal(test_pred, X_test_label))
start_time = time.time()
train_data_lda_std = mms.fit_transform(train_data_pca)
knn.fit(train_data_lda_std, X_train_label)
test_pred = knn.predict(mms.fit_transform(test_data_pca))
time_no[i][j] = time.time() - start_time
accuracy_no[i][j] = np.mean(np.equal(test_pred, X_test_label))
plt.figure()
plt.plot(M1, accuracy[:, 0], M1, accuracy[:, 1], M1, accuracy_no[:, 0], M1, accuracy_no[:, 1])
plt.legend(['k=1', 'k=3', 'k=1,without LDA', 'k=3,without LDA'])
plt.show()
plt.figure()
plt.plot(M1, time1[:, 0], M1, time1[:, 1], M1, time_no[:, 0], M1, time_no[:, 1])
plt.legend(['k=1', 'k=3', 'k=1,without LDA', 'k=3,without LDA'])
plt.show()
结果如图所示
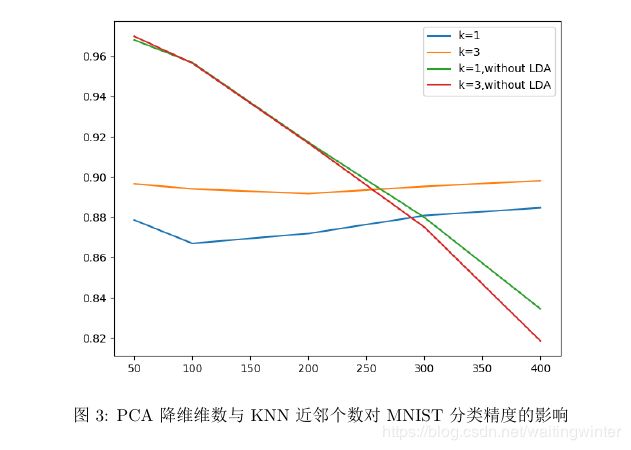
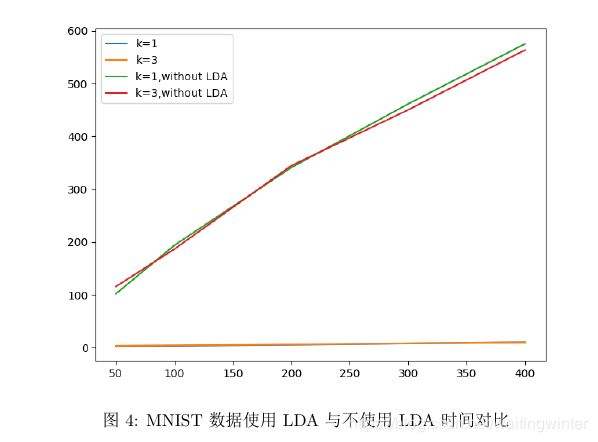
从图(3)中可以看出, k = 3 k=3 k=3 时分类结果比 k = 1 k=1 k=1 时的分类结果好,不使用LDA降维比使用LDA降维的分类结果好。 使用LDA降维后,分类准确率在 0.87 ∼ 0.91 0.87 \sim 0.91 0.87∼0.91 之间; 不使用 LDA 降维后,分类准确率在0.96左右。 在数值实验过程中,我们发现,尽管不使用LDA精度更高,但是运行的时间大大增加, 具体见图(4)
注意:此程序运行时间半个小时以上,原因见图(4),读者可将代码中不使用LDA部分去掉,之后运行时间应该在几分钟内
最后,给出一个PCA,LDA,KNN实现的程序
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import MinMaxScaler
pca = PCA(n_components=N1)
pca.fit(X_train)
train_data_pca = pca.transform(X_train)
test_data_pca = pca.transform(X_test)
lda = LDA(n_components=N1)
lda.fit(train_data_pca, X_train_label)
train_data_lda = lda.transform(train_data_pca)
test_data_lda = lda.transform(test_data_pca)
knn = KNeighborsClassifier(n_neighbors=N2, p=2, metric='minkowski')
mms = MinMaxScaler()
train_data_lda_std = mms.fit_transform(train_data_lda)
knn.fit(train_data_lda_std, X_train_label)
test_pred = knn.predict(mms.fit_transform(test_data_lda))