深度学习阅读笔记
深度学习(Deep Learning):通过组合低层特征形成更加抽象的高层特征(或属性类别),像人脑一样深层次地思考。
深度学习与机器学习有什么区别?
数据依赖性:二者之间最主要的区别与数据的规模有关。当数据很小时,深度学习表现一般,而传统的机器学习表现较好;随着数据量的增加,深度学习的性能则远远高于机器学习。
可解释性:假设使用深度学习给散文自动评分,并接近人类的表现,但没有揭示为什么它给出了这个分数。而像决策树这样的机器学习算法可以解释其背后的推理。因此,决策树和线性逻辑回归等算法主要用于解释性行业。
神经网络
神经网络的本质就是通过参数与激活函数来拟合特征与目标之间的真实函数关系。
初学者可能认为画神经网络的结构图是为了在程序中实现这些圆圈与线,但在一个神经网络的程序中,既没有“线”这个对象,也没有“单元”这个对象。实现一个神经网络最需要的是线性代数库。
训练:
机器学习模型训练的目的,就是使得参数尽可能的与真实的模型逼近。具体做法是这样的。首先给所有参数赋上随机值。我们使用这些随机生成的参数值,来预测训练数据中的样本。样本的预测目标为yp,真实目标为y。那么,定义一个值loss,计算公式如下。
loss = (yp - y)2
这个值称之为损失(loss),我们的目标就是使对所有训练数据的损失和尽可能的小。
如果将先前的神经网络预测的矩阵公式带入到yp中(因为有z=yp),那么我们可以把损失写为关于参数(parameter)的函数,这个函数称之为损失函数(loss function)。下面的问题就是求:如何优化参数,能够让损失函数的值最小。
预训练模型
两种使用方法:
- 特征提取
特征提取就是使用已经训练好的网络在新的样本上提取特征,然后将这些特征输入到新的分类器,从头开始训练的过程。 - 微调模型
用于特征提取的卷积基是需要被冻结的,而微调则是将顶部的几层解冻,将解冻的几层和新增的部分,如全连接层联合训练。之所以称之为微调,是因为我们只略微调整了复用的模型的更加抽象的表示部分,使得模型与当前求解问题更加相关。
激活函数
得到的网络可以模拟数据更复杂的关系和模式,拥有更好的泛化能力

正则化
在算法中使用,是防止模型出现过拟合。
正则化的本质:约束或者限制要优化的参数。
Batch Normalization
优点:
- 训练速度更快。因为网络的数据分布更加稳定,模型更容易学习。
- 使用更大的学习率。因为网络的数据分布更加稳定,使用更大的学习率不会轻易造成损失函数曲线发散情况。使用更大的学习率能够加快训练的收敛速度。
- 不需要太关注模型参数的初始化。模型的随机初始化结果对模型的训练没有太大的影响。
- 正则化效果。Mini-batch的BN层是使用mini-batch的统计值近似训练集的统计值,使得BN层具有正则化效果。
缺点:
- BN依赖batch size,对batch size敏感。当batch size太小时,batch的统计值不能代表训练集的统计值,使得训练过程更加困难。
- 在迁移学习fine-tune阶段,模型的BN层参数固定不变,这是不合理的,因为迁移学习的预训练数据集和目标数据集有非常大的不同。
- 不能用于测试阶段。测试阶段使用训练集的统计值去近似训练集的统计值是不合理的。
《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
梯度下降


反向传播
反向传播法其实是神经网络的基础了,但是很多人在学的时候总是会遇到一些问题,或者看到大篇的公式觉得好像很难就退缩了,其实不难,就是一个链式求导法则反复用。如果不想看公式,可以直接把数值带进去,实际的计算一下,体会一下这个过程之后再来推导公式,这样就会觉得很容易了。
步骤
- 神经网络先向传播
- 计算总误差(求梯度)
- 隐含层---->输出层的权值更新(原理:链式求偏导)(梯度下降)
batchsize:每批数据量的大小。DL通常用SGD的优化算法进行训练,也就是一次(1 个iteration)一起训练batchsize个样本,计算它们的平均损失函数值,来更新参数。
iteration:1个iteration即迭代一次,也就是用batchsize个样本训练一次。
epoch:1个epoch指用训练集中的全部样本训练一次,此时相当于batchsize 等于训练集的样本数。
https://blog.csdn.net/qq_37995260/article/details/91348274
卷积神经网络(Convolutional Neural Networks / CNNs / ConvNets)
卷积神经网络是一种带有卷积结构的深度神经网络,卷积结构可以减少深层网络占用的内存量,其三个关键的操作,
其一是局部感受野,
其二是权值共享,
其三是pooling层,
有效的减少了网络的参数个数,缓解了模型的过拟合问题
CNN本质上是一个多层感知机,其成功的原因关键在于它所采用的局部连接和共享权值的方式,一方面减少了的权值的数量使得网络易于优化,另一方面降低了过拟合的风险。
权重共享:在卷积神经网络中,卷积层的每一个卷积滤波器重复的作用于整个感受野中,对输入图像进行卷积,卷积结果构成了输入图像的特征图,提取出图像的局部特征。每一个卷积滤波器共享相同的参数,包括相同的权重矩阵和偏置项。

最左边是数据输入层,对数据做一些处理,比如去均值(把输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA/白化等等。CNN只对训练集做“去均值”这一步。
中间是
CONV:卷积计算层,线性乘积,求和(矩阵对应元素的乘积之和),加上偏移量。
卷积神经网络最大的特点既是模仿人类这一特点,通过提取物件中的某个特征来确定该物件属于什么类型,从而省去每一张图片都遍历一次像素点的工作量。而卷积在此则扮演了一个重要的角色——提取特征。

RELU:激励层,ReLU是激活函数的一种。

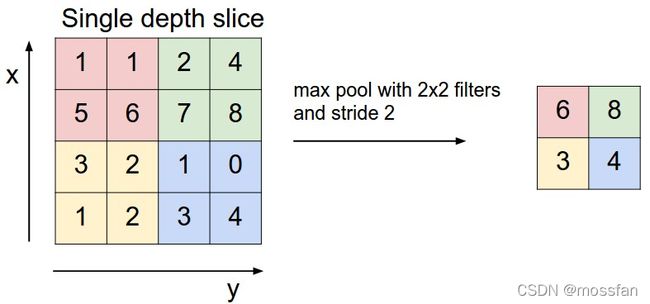
POOL:池化层,简言之,即取区域平均或最大。
最右边是
FC:全连接层
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。
全连接的一个作用是维度变换,尤其是可以把高维变到低维,同时把有用的信息保留下来。
全连接另一个作用是隐含语义的表达(embedding),把原始特征映射到各个隐语义节点(hidden node)。对于最后一层全连接而言,就是分类的显示表达。
利用CNN实现图像识别的任务
一个卷积层中通常包含多个具有不同权值向量的特征图,使得能够保留图像更丰富的特征。卷积层后边会连接池化层进行降采样操作,一方面可以降低图像的分辨率,减少参数量,另一方面可以获得平移和形变的鲁棒性。卷积层和池化层的交替分布,使得特征图的数目逐步增多,而且分辨率逐渐降低,是一个双金字塔结构。
https://blog.csdn.net/Real_Myth/article/details/51824193
https://blog.csdn.net/jiaoyangwm/article/details/80011656
https://blog.csdn.net/qq_41884002/article/details/106424500
计算机视觉
计算机视觉是使用计算机及相关设备对生物视觉的一种模拟。它的主要任务就是通过对采集的图片或视频进行处理以获得相应场景的三维信息,就像人类和许多其他类生物每天所做的那样。
目标检测
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观、形状和姿态,加上成像时光照、遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
指标
目标检测器使用多种指标来评价检测器的性能,如:FPS、precision、recall,以及最常用的mAP。precision由IoU推导出来,后者的定义是预测边框和GT之间的交并比。然后,设定一个IoU阈值来判定检测结果是否正确:如果IoU大于阈值,则该结果分类为True Positive(TP),如果小于阈值,则分类为False Positive(FP)。如果模型没有检测出GT中存在的目标,则这些目标分类为False Negative(FN)。average precision(AP)是每一类的平均精度。然后,为了对比不同检测器,将所有类的AP平均,即可得到mAP这个单一指标。
核心问题
(1)分类问题:即图片(或某个区域)中的图像属于哪个类别。
(2)定位问题:目标可能出现在图像的任何位置。
(3)大小问题:目标有各种不同的大小。
(4)形状问题:目标可能有各种不同的形状。
one-stage和two-stage网络的区别
one-stage网络生成的ancor框只是一个逻辑结构,或者只是一个数据块,只需要对这个数据块进行分类和回归就可以,不会像two-stage网络那样,生成的 ancor框会映射到feature map的区域(rcnn除外),然后将该区域重新输入到全连接层进行分类和回归,每个ancor映射的区域都要进行这样的分类和回归,所以它非常耗时
one-stage网络最终学习的ancor有很多,但是只有少数ancor对最终网络的学习是有利的,而大部分ancor对最终网络的学习都是不利的,这部分的ancor很大程度上影响了整个网络的学习,拉低了整体的准确率;而two-stage网络最终学习的ancor虽然不多,但是背景ancor也就是对网络学习不利的ancor也不会特别多,它虽然也能影响整体的准确率,但是肯定没有one-stage影响得那么严重,所以它的准确率比one-stage肯定要高
https://blog.csdn.net/weixin_33602281/article/details/86169287
效果评估
交并比:使用IoU(Intersection over Union,交并比)来判断模型的好坏。所谓交并比,是指预测边框、实际边框交集和并集的比率,一般约定0.5为一个可以接收的值。
非极大值抑制:预测结果中,可能多个预测结果间存在重叠部分,需要保留交并比最大的、去掉非最大的预测结果,这就是非极大值抑制(Non-Maximum Suppression,简写作NMS)。如下图所示,对同一个物体预测结果包含三个概率0.8/0.9/0.95,经过非极大值抑制后,仅保留概率最大的预测结果。
YOLO-v3
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。(center-x,center-y,w,h )
yoloV3不同于之前的yolo1与yolo2,其使用了图像金字塔的思想,对一张图片进行了3次降采样,分别为8,16,32。表示我们输入的图像必须是32的倍数,不然没有办法进行32倍的降采样。
注意数据集中图片的高宽比
因为yolo模型的预测是在13 * 13的正方形网格上,输入图像也是正方形(416 * 416)。但是训练数据集中的图片通常不是正方形,并且测试图片一般也不是,图片的大小也会各种各样。
因为yolo网络的输入是416 * 416的正方形图像,因此必须将训练图像放在该正方形中,有如下三种方法:
- 方法一:直接将图像resize到416 * 416。缺点会挤压图像
- 方法二:将最小边调整为416,然后从图像中裁剪出416 * 416区域,缺点:通过裁剪虽然高宽比保持不变,但可能切掉图像的重要部分。
- 方法三:将最大边调整为416,用0去填充另外的短边,缺点可能会使物体太小而无法检测。
在训练yolo前,将边界框的xmin和xmax除以图像宽度,ymin和ymax除以图像高度,以归一化坐标,目的是为了使训练独立于每个图像的实际像素大小。但是输入的图像通常不是正方形的,所以x坐标除以一个与y坐标不同的数字,根据图像的尺寸和高宽比,每个图像的除数是不一样的,这影响到如何处理边界框坐标和先验框。
bounding box
- anchor box:其实就是从训练集的所有ground truth box中**统计(使用k-means)**出来的在训练集中最经常出现的几个box形状和尺寸。
我们可以预先将这些统计上的先验(或来自人类的)经验加入到模型中,这样模型在学习的时候,瞎找的可能性就更小了些,当然就有助于模型快速收敛了。
anchor box其实就是对预测的对象范围进行约束,并加入了尺寸先验经验,从而实现多尺度学习的目的。 - 置信度(confidence):表示一种自信程度,框出的box内确实有物体的自信程度和框出的box将整个物体的所有特征都包括进来的自信程度。
- 对象条件类别概率:是一组概率的数组,数组的长度为当前模型检测的类别种类数量,它的意义是当bounding box认为当前box中有对象时,要检测的所有类别中每种类别的概率.
yolov3检测分两步:
1、确定检测对象位置
2、对检测对象分类(是什么东西)
处理图片过程如下

首先一张图片传进yolo,yolo会将其转化为416×416大小的网格,增加灰度条用于防止失真,之后图片会分成三个网格图片(13×13,26×26,52×52)
yolov3主干网络为Darknet53,重要的是使用了残差网络Residual,darknet53的每一个卷积部分使用了特有的DarknetConv2D结构,每一次卷积的时候进行l2正则化,完成卷积后进行BatchNormalization标准化与LeakyReLU激活函数
https://blog.csdn.net/yegeli/article/details/109861867
https://blog.csdn.net/weixin_39615182/article/details/109752498
https://blog.csdn.net/syysyf99/article/details/93207020
https://blog.csdn.net/qq_41884002/article/details/106424500
自然语言处理
主要研究用计算机来处理、理解以及运用人类语言(又称自然语言)的各种理论和方法,属于人工智能领域的一个重要研究方向,是计算机科学与语言学的交叉学科,又常被称为计算语言学。
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面
自然语言处理这一术语指的是对人类语言进行自动的计算处理。它包括两类算法:
将人类产生的文本作为输入;
产生看上去很自然的文本作为输出。
自然语言具有歧义性、动态性和非规范性,同时语言理解通常需要丰富的知识和一定的推理能力,这些都给自然语言处理带来了极大的挑战。
深度学习主要为自然语言处理的研究带来了两方面的变化:
一方面是使用统一的分布式(低维、稠密、连续)向量表示不同粒度的语言单元,如词、短语、句子和篇章等;
另一方面是使用循环、卷积、递归等神经网络模型对不同的语言单元向量进行组合,获得更大语言单元的表示。
步骤:
- 获得语料
- 语料预处理
- 特征工程
- 特征选择
- 模型训练
- 评价指标

Yoav Goldberg所著《Neural Network Methods for Natural Language Processing》的中文版《基于深度学习的自然语言处理》
https://www.jianshu.com/p/16c643f794d8
transformer
Transformer就是一个基于多头注意力机制的模型,是一个全连接(或者是一维卷积)加Attention的结合体。
将中间的Transformer模块进一步拆开,可以看到它主要包含Encoders和Decoders两个部分,加了s代表它包含多个encoder和decoder

其中每一个encoder和decoder结构都是一样的,这里只是单纯地叠加起来而已。我们主要要关注的是单个encoder和decoder的内部结构,先将encoder的结构展示如下:

encoder的一共包含2层,分别是Self-Attention(SA)层和Feed Forward Neural Network(FFN)层,SA层的作用是在对输出序列中的每个词编码的时候,让编码信息中包含序列中的其他单词的信息,即保存了当前单词与其余单词之间的关系。FFN层就是普通的前向网络,对SA层的输出进行近一步的特征提取。
encoder里的每层有self attention和feed forward两层。其中encoder输入是n个词向量,n是输入最长的句子里单词数量。
decoder的输出则是类似传统的seq2seq结构,是一个一个目标语言的单词。
Self-Attention层

self attention假设:一个句子中每个单词的含义,都部分取决于该句子里其他词。
self attention encoding的目的,即,将句子中每个原始词向量按照attention加权相加,求出新的词向量。
Position Encoding
每个词都加上一个位置信息

注意,这个加是在原有词向量上叠加一个同维度表示位置的向量,不是粘在后边。
高维空间里,词向量之间都是以原点为起点的向量,现在通过这种方法,让词向量之间产生了距离。
https://www.jianshu.com/p/b40deff0ca63
https://zhuanlan.zhihu.com/p/265174916