1.小说爬取(spider)
参照链接:使用Beautiful Soup爬取小说(bs4 + urllib)
a.BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
# print(soup.prettify())
# tag 的内容,名称等。。。可用于查找文本内容
print(soup.title)//print(soup.title.name)//print(soup.title.string)//print(soup.title.parent.name)// print(soup.body.children.name) # children 选项
print(soup.p)//print(soup.p.name)//print(soup.p.get_text())# 获取所有文字内容
.text 与 .string 的区别于使用范围: 是否包含多个子节点,多个只能用text,返回类型有区别
# tag中包含多个字符串 [2] ,可以使用 .strings 来循环获取
# 输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容
print(soup.a.attrs)# 获取所有的属性值 可使用属性值进行目标位置确认,或者 href,scr,img等获取
# 属性值的获取方式 : ["attrs"] , .get("attrs ")
print(soup.a['class']) // print(soup.a.get('href'))
# 查找,遍历
# find_all( name , attrs , recursive , string , **kwargs )
'''
name 参数可以查找所有名字为 name 的tag,字符串对象会被自动忽略掉,
keyword 参数:搜索指定名字的属性时可以使用的参数值包括 字符串 , 正则表达式 , 列表, True .
string 参数可以搜搜文档中的字符串内容.
limit 参数限制返回结果的数量 也可理解find 为 limit= 1
只想搜索tag的直接子节点,可以使用参数 recursive=False,默认为True: 搜索所有子孙节点
'''
eg:
print(soup.find(id="link3"))//print(soup.find_all('a'))
# 关键字: class 改为 class_
for linkin soup.find_all('a', class_="sister"):
print(link['id'], ':', link.get('href'))
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag , NavigableString , BeautifulSoup , Comment .
(1)tag
soup = BeautifulSoup('Extremely bold')
tag = soup.b
# tag 的属性值更改获取 , tag的属性操作方法与字典一样
tag.name ='change'
print(soup.change)
tag["class"] ='blod_change'
print(tag.get('class'))
(2) NavigableString 类来包装tag中的字符串
一个 NavigableString 字符串与Python中的Unicode字符串相同,
并且还支持包含在 遍历文档树 和 搜索文档树 中的一些特性.
通过 unicode() 方法可以直接将 NavigableString 对象转换成Unicode字符串
# tag中包含的字符串不能编辑,但是可以被替换成其它的字符串,用 replace_with()
(3)comment
# Comment 对象是一个特殊类型的 NavigableString 对象
(4)相关知识点
.parent 属性来获取某个元素的父节点
.parents 属性可以递归得到元素的所有父辈节点
.next_sibling 和 .previous_sibling 属性来查询兄弟节点
.next_siblings 和 .previous_siblings 属性可以对当前节点的兄弟节点迭代输出
.next_element 属性指向解析过程中下一个被解析的对象(字符串或tag),结果可能与 .next_sibling 相同,但通常是不一样的.
# Beautiful Soup支持大部分的CSS选择器: .select() 方法中传入字符串参数, 即可使用CSS选择器的语法找到tag
b.小说内容实战
小说章节内容爬取使用BeautifulSoup进行解析文本内容;
针对小说章节列表进行分析,return(list) 小说章节名+链接;
使用函数def实现以上功能,并进行代码整合。
注意:
文本解析时的空格与换行符;
进度显示:
#打印爬取进度
sys.stdout.write("已下载:%.3f%%"% float(index/numbers) +'\r')
sys.stdout.flush() index +=1
2.python运算符
Python比较运算符:

Python赋值运算符:+=,-=, ......etc简化操作
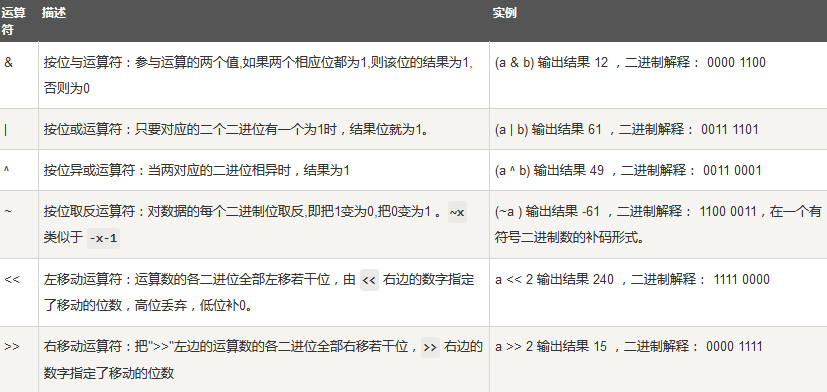
Python位运算符
python逻辑运算符:与或非,and,or,not
身份运算符与成员运算符:in//not in;is//not is:


运算符优先等级(从高到底):

3.user_agent 和 IP
参照资料链接: 使用User Agent和代理IP隐藏身份
User Agent存放于Headers中,服务器就是通过查看Headers中的User Agent来判断是谁在访问。(模拟浏览器访问)对于在程序过程中访问网页,发送请求时(urlopen/requests.get)需要在请求总添加 “headers=header”或使用add_header()方法,添加headers(session/request.Request(url))。
IP设置可大致分为以下三个步骤:
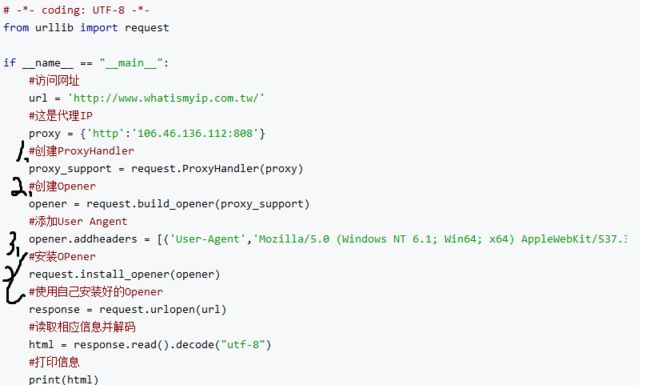
需要注意:
这里示例使用的代理IP为开放代理,若使用加密代理第一步需:{'http' : 'user:password @ ip:port}:
可以使用random.choice(ip)//random.choice(user_agent) :此处ip和user_agent 为一组
random.choice():查找内容可以为 列表,元组或字符串
requests:requests.get(url = http_url, headers = headers, proxies = proxies, timeout =30)
针对第三步:request.install_opener(opener) 目的是将前面的内容作为默认设置保存,后续使用response = request.urlopen(url)中就已经针对ip设置, 或者也可使用opener .urlopen(url) 进行局部使用
4.不同级别的范数在机器学习中的应用
参考链接:范数与距离的关系以及在机器学习中的应用
L1范数和L2范数,用于机器学习的L1正则化、L2正则化。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
其作用是:
L1正则化是指权值向量w中各个元素的绝对值之和,可以产生稀疏权值矩阵(稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. ),即产生一个稀疏模型,可以用于特征选择;
L2正则化是指权值向量w中各个元素的平方和然后再求平方根,可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合。
常用的向量的范数:
L1范数(曼哈顿距离): ||x|| 为x向量各个元素绝对值之和。
L2范数(欧式距离): ||x||为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数
Lp范数(闵可夫斯基距离(Minkowski Distance)): ||x||为x向量各个元素绝对值p次方和的1/p次方
L∞范数(切比雪夫距离): ||x||为x向量各个元素绝对值最大那个元素的绝对值,如下:

Mahalanobis距离:也称作马氏距离。在近邻分类法中,常采用欧式距离和马氏距离。

其中p是一个变参数。
当p=1时,就是曼哈顿距离,
当p=2时,就是欧氏距离,
当p→∞时,就是切比雪夫距离,
根据变参数的不同,闵氏距离可以表示一类的距离。