集成学习方法主要分成三种:bagging,boosting 和 Stacking。这里主要介绍Stacking。
stacking严格来说并不是一种算法,而是精美而又复杂的,对模型集成的一种策略。
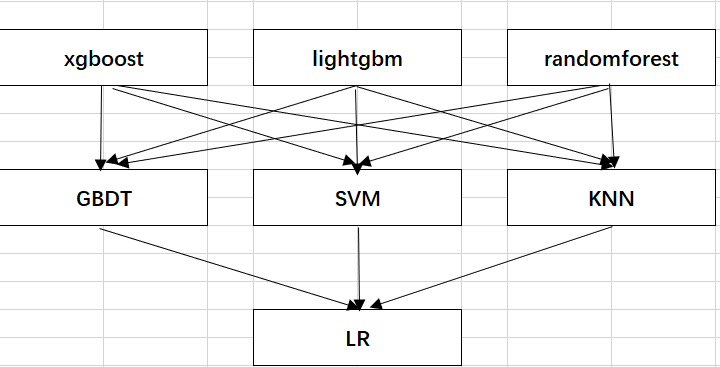
首先来看一张图。
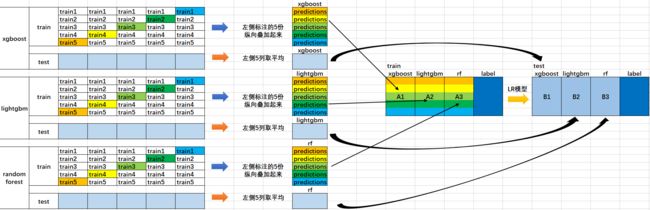
1、首先我们会得到两组数据:训练集和测试集。将训练集分成5份:train1,train2,train3,train4,train5。
2、选定基模型。这里假定我们选择了xgboost, lightgbm 和 randomforest 这三种作为基模型。比如xgboost模型部分:依次用train1,train2,train3,train4,train5作为验证集,其余4份作为训练集,进行5折交叉验证进行模型训练;再在测试集上进行预测。这样会得到在训练集上由xgboost模型训练出来的5份predictions,和在测试集上的1份预测值B1。将这五份纵向重叠合并起来得到A1。lightgbm和randomforest模型部分同理。
3、三个基模型训练完毕后,将三个模型在训练集上的预测值作为分别作为3个"特征"A1,A2,A3,使用LR模型进行训练,建立LR模型。
4、使用训练好的LR模型,在三个基模型之前在测试集上的预测值所构建的三个"特征"的值(B1,B2,B3)上,进行预测,得出最终的预测类别或概率。
做stacking,首先需要安装mlxtend库。安装方法:进入Anaconda Prompt,输入命令 pip install mlxtend 即可。
stacking主要有几种使用方法:
1、最基本的使用方法,即使用基分类器所产生的预测类别作为meta-classifier“特征”的输入数据
1 from sklearn import datasets 2 3 iris = datasets.load_iris() 4 X, y = iris.data[:, 1:3], iris.target 5 6 from sklearn import model_selection 7 from sklearn.linear_model import LogisticRegression 8 from xgboost.sklearn import XGBClassifier 9 import lightgbm as lgb 10 from sklearn.ensemble import RandomForestClassifier 11 from mlxtend.classifier import StackingClassifier 12 import numpy as np 13 14 basemodel1 = XGBClassifier() 15 basemodel2 = lgb.LGBMClassifier() 16 basemodel3 = RandomForestClassifier(random_state=1) 17 18 lr = LogisticRegression() 19 sclf = StackingClassifier(classifiers=[basemodel1, basemodel2, basemodel3], 20 meta_classifier=lr) 21 22 print('5-fold cross validation:\n') 23 24 for basemodel, label in zip([basemodel1, basemodel2, basemodel3, sclf], 25 ['xgboost', 26 'lightgbm', 27 'Random Forest', 28 'StackingClassifier']): 29 30 scores = model_selection.cross_val_score(basemodel,X, y, 31 cv=5, scoring='accuracy') 32 print("Accuracy: %0.2f (+/- %0.2f) [%s]" 33 % (scores.mean(), scores.std(), label))
2、这一种是使用第一层所有基分类器所产生的类别概率值作为meta-classfier的输入。需要在StackingClassifier 中增加一个参数设置:use_probas = True。
另外,还有一个参数设置average_probas = True,那么这些基分类器所产出的概率值将按照列被平均,否则会拼接。
例如:
基分类器1:predictions=[0.2,0.2,0.7]
基分类器2:predictions=[0.4,0.3,0.8]
基分类器3:predictions=[0.1,0.4,0.6]
1)若use_probas = True,average_probas = True,
则产生的meta-feature 为:[0.233, 0.3, 0.7]
2)若use_probas = True,average_probas = False,
则产生的meta-feature 为:[0.2,0.2,0.7,0.4,0.3,0.8,0.1,0.4,0.6]
1 from sklearn import datasets 2 3 iris = datasets.load_iris() 4 X, y = iris.data[:, 1:3], iris.target 5 6 from sklearn import model_selection 7 from sklearn.linear_model import LogisticRegression 8 from xgboost.sklearn import XGBClassifier 9 import lightgbm as lgb 10 from sklearn.ensemble import RandomForestClassifier 11 from mlxtend.classifier import StackingClassifier 12 import numpy as np 13 14 basemodel1 = XGBClassifier() 15 basemodel2 = lgb.LGBMClassifier() 16 basemodel3 = RandomForestClassifier(random_state=1) 17 lr = LogisticRegression() 18 sclf = StackingClassifier(classifiers=[basemodel1, basemodel2, basemodel3], 19 use_probas=True, 20 average_probas=False, 21 meta_classifier=lr) 22 23 print('5-fold cross validation:\n') 24 25 for basemodel, label in zip([basemodel1, basemodel2, basemodel3, sclf], 26 ['xgboost', 27 'lightgbm', 28 'Random Forest', 29 'StackingClassifier']): 30 31 scores = model_selection.cross_val_score(basemodel,X, y, 32 cv=5, scoring='accuracy') 33 print("Accuracy: %0.2f (+/- %0.2f) [%s]" 34 % (scores.mean(), scores.std(), label))
3、这一种方法是对基分类器训练的特征维度进行操作的,并不是给每一个基分类器全部的特征,而是赋予不同的基分类器不同的特征。比如:基分类器1训练前半部分的特征,基分类器2训练后半部分的特征。这部分的操作是通过sklearn中的pipelines实现。最终通过StackingClassifier组合起来。
1 from sklearn.datasets import load_iris 2 from mlxtend.classifier import StackingClassifier 3 from mlxtend.feature_selection import ColumnSelector 4 from sklearn.pipeline import make_pipeline 5 from sklearn.linear_model import LogisticRegression 6 from xgboost.sklearn import XGBClassifier 7 from sklearn.ensemble import RandomForestClassifier 8 9 iris = load_iris() 10 X = iris.data 11 y = iris.target 12 #基分类器1:xgboost 13 pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)), 14 XGBClassifier()) 15 #基分类器2:RandomForest 16 pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)), 17 RandomForestClassifier()) 18 19 sclf = StackingClassifier(classifiers=[pipe1, pipe2], 20 meta_classifier=LogisticRegression()) 21 22 sclf.fit(X, y)
StackingClassifier使用API和参数说明:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。