2017年3月1日
1.使用ggplot2进行高级绘图
1.在ggplot2中,图是采用串联起来(+)号函数创建的,每个函数属于自己的部分。
library(ggplot2)
ggplot(data=mtcars,aes(x=wt,y=mpg))+geom_point()+
+ labs(title="Automobile Data",x="Weight",y="Miles Per Gallon")
注:aes()函数的功能是指定每个变量扮演的角色,在本例中,变量wt的值以映射到沿x轴的距离,变量mpg的值是映射到沿y轴的距离。
ggplot() 函数设置图形但没有自己的视觉输出。geom_point() 函数在图形中画点,创建了一个散点图。
labs() 函数是添加注释的。
2.
ggplot(data=mtcars,aes(x=wt,y=mpg))+geom_point(pch=17,color="blue",size=2)+
geom_smooth(method="lm",color="red",linetype=2)+
labs(title="Automobile Data",x="Weight",y="Miles Per Gallon")
注:geom_smooth() 函数增加了一条"平滑"曲线。默认情况下,平滑的曲线包括在95%的置信区间(较暗带)内。
3.ggplot2包提供了分组和小面化(faceting)的方法。分组指的是在一个图形中显示两组或多组观察结果。小面化指的是在单独、并排的图形上显示观察组。ggplot2包定义组或面时使用因子。
mtcars$am<- factor(mtcars$am,levels=c(0,1),labels=c("Automatic","manual"))
mtcars$vs<- factor(mtcars$vs,levels=c(0,1),labels=c("V-Engine","Straight Engine"))
> mtcars$cyl<- factor(mtcars$cyl)
> library(ggplot2)
> ggplot(data=mtcars,aes(x=hp,y=mpg,shape=cyl,color=cyl))+
+ geom_point(size=3)+
+ facet_grid(am~vs)+
+ labs(title="Automobile Data by Engine Type",x="Horsepower",y="Miles Per Gallon")
4.用几何函数指定图的类型
geom_bar() 条形图
geom_boxplot() 箱线图
geom_density() 密度图
geom_histogram() 直方图
geom_hline() 水平线
geom_jitter() 抖动图
geom_line() 线图
geom_point() 散点图
geom_rug() 地毯图
geom_smooth() 拟合曲线
geom_text() 文字注释
geom_violin() 小提琴图
geom_vline() 垂线
5.
ggplot(singer,aes(x=voice.part,y=height))+
geom_violin(fill="lightblue")+
geom_boxplot(fill="lightgreen",width=0.2)
6.在R中,组通常用分类变量的水平(因子)来定义。
ggplot()声明中的aes()函数负责分配变量(图形的视觉特征),所以这是一个分配分组变量的自然的地方。
data(Salaries,package="car")
library(ggplot2)
ggplot(data=Salaries,aes(x=salary,fill=rank))+
geom_density(alpha=0.3)
7.刻面
facet_wrap(~var,ncol=n) 将每个var水平排列成n列的独立图
facet_wrap(~var,nrow=n) 将每个var水平排列成n行的独立图
facet_grid(rowvar~colvar) rowvar和colvar组合的独立图,其中rowvar表示行,colvar表示列
facet_grid(rowvar~.) 每个rowvar水平的独立图,配置成一个单列
facet_grid(.~colvar) 每个colvar水平的独立图,配置成一个单行
8.
data(singer,package="lattice")
library(ggplot2)
ggplot(data=singer,aes(x=height,fill=voice.part))+
geom_density()+
facet_grid(voice.part~.)
9.
geom_smooth()函数来添加一系列的平滑曲线和置信区域。
ggplot(data=Salaries,aes(x=yrs.since.phd,y=salary,linetype=sex,shape=sex,color=sex))+
geom_smooth(method=lm,formula=y~poly(x,2),
se=FALSE,size=1)+
geom_point(size=2)
10.修改图形外观
(1)par()函数或特定图画函数的图形参数来自定义基本函数,但对pplot2图形没有影响。
(2)自定义函数
scale_x_continuous() scale_y_continuous():breaks=指定刻度标记,labels=指定刻度标记标签,limits=控制要展示的值得范围。
scale_x_discrete() scale_y_discrete() :breaks=对因子的水平进行放置和排序,labels=指定这些水平的标签,limits=表示哪些水平应该展示
coord_flip() 颠倒x轴和y轴
ggplot(data=Salaries,aes(x=rank,y=salary,fill=sex))+
geom_boxplot()+
scale_x_discrete(breaks=c("AsstProf","AssocProf","Prof"),
labels=c("Assistant\nProfessor",
"Associate\nProfessor","Full\nProfessor"))+
scale_y_continuous(breaks=c(50000,10000,150000,20000),
labels=c("$50k","$100K","$150K","$200K"))+
labs(title="Faculty Salary by Pank and Sex",x=" ",y="")
11.图例
标题的位置由theme()函数中的legend.position选项控制。
ggplot(data=Salaries,aes(x=rank,y=salary,fill=sex))+
geom_boxplot()+
scale_x_discrete(breaks=c("AsstProf","AssocProf","Prof"),
labels=c("Assistant\nProfessor",
"Associate\nProfessor","Full\nProfessor"))+
scale_y_continuous(breaks=c(50000,10000,150000,20000),
labels=c("$50k","$100K","$150K","$200K"))+
labs(title="Faculty Salary by Pank and Sex",x=" ",y="")+
theme(legend.position=c(0.1,0.8))
12.标尺
> ggplot(mtcars,aes(x=wt,y=mpg,size=disp))+
geom_point(shape=21,color="black",fill="cornsilk")+
labs(x="Wight",y="Miles Per Gallon",title="hongqianjin",size="Engine\nDisplacement")
ggplot(data=Salaries,aes(x=yrs.since.phd,y=salary,color=rank))+
scale_color_brewer(palette="Set1")+geom_point(size=2)
13.得到获得的数据集
library(RColorBrewer)
display.brewer.all()
14.多重图
使用图形参数myrow和基本函数layout()把两个或更多的基本图形放到单个图形中,这个方法在ggplot2包中不适用。
将多个ggplot2包的图形放到单个图形中最简单的方式是使用gridExtra包中grid.arrange()函数。
p1<-ggplot(data=Salaries,aes(x=rank))+geom_bar()
p2<-ggplot(data=Salaries,aes(x=sex))+geom_bar()
p3<-ggplot(data=Salaries,aes(x=yrs.since.phd,y=salary))+geom_point()
library(gridExtra)
grid.arrange(p1,p2,p3,ncol=3)
15.保存图形
ggsave()函数能更好的保存
library(ggplot2)
myplot <- ggplot(data=mtcars,aes(x=mpg))+geom_histogram()
ggsave(file="mygraph.png",plot=myplot,width=5,height=4)
ggplot(data=mtcars,aes(x=mpg))+geom_histogram()
ggsave(file="hongqianjin.pdf")
没有 plot=选项,最近创建的图形会保存
2.
目录
一、 SPSS安装及介绍... 2
1. SPSS的安装... 2
2. SPSS的介绍... 2
二、 统计学基本知识... 3
1. 统计学术语... 3
2. 连续型变量的描述性统计... 5
3. 分类型变量的统计描述... 8
4. -分布... 9
5. T-分布... 9
6. F-分布... 9
7. 参数估计... 9
8. 假设检验... 11
三、 SPSS分析的整体的思路... 13
1. 数据的获取... 13
2. 数据的处理... 13
3. 数据的预分析... 13
4. 模型的建立... 13
5. 报告的攒写... 14
一、 SPSS安装及介绍
1. SPSS的安装
百度网盘链接:http://pan.baidu.com/s/1bBHDwU
安装说明:
注意:请保持您的计算机连接网络!
第一步:双击IBM SPSS Statistics V21.0进行安装;
第二步:出现选择界面时选择中间选项(即 站点许可证);
第三步:点 下一步,一直到 完成(是否需要JAWS?随便选即可)。注意:最后那个单击注册获取提醒的请取消选项,此为广告。
第四步:请点击确定出现产品授权窗口,选择 立即授予产品许可证,复制下边代码:
QA3AW8U62Z4ZWTSPV44VXI65P59OLE547WHIQVZYWLARL9JEYQEGDUBLH8Z3ZCJAL3FLXMS98V95TSDYI7FOEXUPRR
点击下一步,一直到完成。
软件运行图标默认在程序菜单,请右键创建桌面快捷方式。
2. SPSS的介绍
(1)软件的名称
最早:Statistical Package for Social Science
现在:IBM SPSS Statistics
(2)发展历史
60年代:美国斯坦福大学三位研究生研制
70年代:SPSS总部成立于芝加哥,推出SPSS中小型机版-SPSSX
80年代:微机版(V1~4)SPSS/PC+
90年代: Windows版(V6~10)
本世纪:11~24版,中文版
从被IBM收购之后,SPSS的更新都是一年一个版本,每年的8月中旬,总能见到
(3)基本特点
功能强大:
囊括了各种成熟的统计方法与模型,如方差分析、回归分析、聚类分析等;在数据准备方面,SPSS提供了各种数据准备与数据整理技术,如利用值标签来快捷录入数据、对连续性变量进行离散型转化、将几个小类别合并为一个大类别、重复记录的发现、异常数据发现等;还有各种常用的统计图形
兼容性好:
在数据方面不仅可在SPSS中直接进行数据录入工作,还可将excel表格数据、文本格式数据导入SPSS中进行分析,并且可以在word等软件中使用中文输出结果
易用性强:
强大的统计功能、简单易用、界面的友好、操作的简单,SPSS也向高级用户提供了编程功能
扩展性高:(以一种不同的方式)
二、 统计学基本知识
SPSS是针对于初学者的一种专业的统计分析软件,它的操作主要是以菜单式为主,页面的设置与excel很类似,可以增加初学者的亲切感,并且,SPSS在进行操作的时候一定会用到的结果按钮,SPSS软件都会默认为选择,目的就是防止初学者忘记选择,这一方面很人性化,所以,对于一种方法的操作,只要记得步骤结果很快的就会出来,但是,SPSS是一种专业的统计分析软件,所以,它的难点不在于软件的操作,而在于结果的查看,SPSS的结果会用到相应的统计基础知识,所以,在进行操作之前,需要了解一些统计学知识。
1. 统计学术语
(1)变量
从一次观察到下一次观察会出现不同结果的某种特征,在SPSS中一列叫做一个变量,如:观察一个企业的销售额,这个月和上个月有所不同;观察股票市场上涨股票的家数,今天与昨天数量不一样;观察一个班学生的生活费支出,一个人和另一个人不一样;投掷一枚骰子观察其出现的点数,这次投掷的结果和下一次也不一样 “企业销售额”、“上涨股票的家数”、“生活费支出”、“投掷一枚骰子出现的点数”等就是变量;
在统计学里根据变量的形式与性质可以分为两大类:连续型变量与分类型变量,在后期进行分析的时候都是以分类型变量与连续型变量为主进行分析的,这两类变量其实是有原始的四种变量尺度转化而来的,下面展示的是原始的四种变量尺度在SPSS软件中相应的转化:

(2)个案
在SPSS软件中一行叫做一个个案,即为一个调查的主体
(3)总体与样本
总体(population):包含所研究的全部个体(数据)的集合;
样本(sample):从总体中抽取的一部分元素的集合;
样本量(sample size):构成样本的元素的数目
(4)概率
概率是对事件发生的可能性大小的度量;如:明天降水的概率是80%。这里的80%就是对降水这一事件发生的可能性大小的一种数值度量;你购买一只股票明天上涨的可能性是30%,这也是一个概率;
一个介于0和1之间的一个值;
事件A的概率记为P(A)
当试验的次数很多时,概率P(A)可以由所观察到的事件A发生次数(频数)的比例来逼近,在相同条件下,重复进行n次试验,事件A发生了m次,则事件A发生的概率可以写为:P(A)=![]()
2. 连续型变量的描述性统计
连续变量的统计描述从以下的几个方面:
集中趋势:大部分数值集中到某区间的趋势;
离散趋势:数值向两边分散的趋势;
分布形状(是否对称,分布曲线的形状);
分布特征(单、双峰,有无极端值等)
(1)集中趋势
A:均值
消除了观测值的随机波动;易受极端值的影响
总体平均数:若一组数据X1,X2,…,XN,代表一个大小为N的有限总体,则其总体平均数为:

样本平均数:若一组数据x1,x2,…,xn,代表一个大小为n的有限样本,则其样本平均数为:
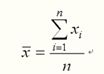
样本数据来自总体。样本的统计描述量可以反映总体数据的特征,但由于抽样等原因,使得样本数据不一定能够完全准确地反映总体,它可能与总体的真实值之间存在一定的差异。进行不同次抽样,会得到若干个不同的样本均值,它们与总体均值存在着不同的差异。
B:中位数
把一组数据按递增或递减的顺序排列,处于中间位置上的变量值就是中位数,它是一种位置代表值,所以不会受到极端数值的影响,具有较高的稳健性。
如果为奇数,那么该数列的中位数就是位置 (N+1)/2上的数;
如果N为偶数,中位数则是该数列中第 N/2与第N /2+1位置上两个数值的平均数。
C:四分位数
四分位数 是将一组个案由小到大(或由大到小)排序后,用3个点将全部数据分为四等份,与3个点上相对应的变量称为四分位数,分别记为Q1(第一四分位数)、Q2(第二四分位数)、Q3(第三四分位数)。其中,Q3到Q1之间的距离的一半又称为四分位差,记为Q。四分位差越小,说明中间的数据越集中;四分位数越大,则意味着中间部分的数据越分散,
四分之一位数=n/4
四份之三位数=3n/4
D:众数
一组数据中出现次数最多的变量值;
适合于数据量较多时使用;
不受极端值的影响;
一组数据可能没有众数或有几个众数
(2)离散趋势
A: 全距
定义:全距也称为极差,是数据的最大值与最小值之间的绝对差。
在相同样本容量情况下的两组数据,全距大的一组数据要比全距小的一组数据更为分散;
离散程度的最简单测度值:
易受极端值影响:
未考虑数据的分布
计算公式:最大值-最小值
B:方差与标准差
定义:方差是所有变量值与平均数偏差平方的平均值,它表示了一组数据分布的离散程度的平均值。标准差是方差的平方根,它表示了一组数据关于平均数的平均离散程度;
方差和标准差越大,说明变量值之间的差异越大,距离平均数这个“中心”的离散趋势越大
(样本方差)

(总体方差)
C:四分位差
也称为内距或四分间距;
上四分位数与下四分位数之差:Qd = QU – QL;
反映了中间50%数据的离散程度;
不受极端值的影响;
用于衡量中位数的代表性
D:离散系数
标准差与其相应的均值之比;
对数据相对离散程度的测度;
消除了数据水平高低和计量单位的影响;
用于对不同组别数据离散程度的比较;
计算公式为:
(3)分布形状与特征
A:正太分布
定义:若连续型随机变量X的概率分布密度函数为

其中,μ为平均数,?^2为方差,则称随机变量X服从正态分布,
记为X~N( μ,?^2),不同的μ、不同的?,对应于不同的正态分布,正太分布是是关于X=μ对称
B:标准正太分布
标准正态分布 :均数μ为0,、标准差为1的正态分布;
标准化Z分数:计算公式![]()
标准正太分布主要是用来进行Z得分的计算,Z得分的特点:
也称标准化值;
对某一个值在一组数据中相对位置的度量;
可用于判断一组数据是否有离群点(outlier);
用于对变量的标准化处理;
均值等于0,方差等于1
C:峰度
定义:峰度(Kurtosis)是描述某变量所有取值分布形态陡缓程度的统计量。这个统计量是与正态分布相比较的量。记为β
计算公式为: ![]()
β>0 峰的形状比较尖,比正态分布峰要陡峭,数据比正太时更加的集中;
β<0 峰的形状比较缓,比正态分布峰要平坦,数据比正太时分散;
β=0 正态分布峰
D:偏度
定义:偏度是描述数据分布形态的,它是描述某变量取值分布对称性的统计量。
计算公式为:

Skewness >0 正偏或右偏,长尾在右,峰尖偏左;
Skewness <0 负偏或左偏,长尾在左,峰尖偏右;
而偏度的绝对值数值越大表示分布形态的偏斜程度越大。
3. 分类型变量的统计描述
(1)单个分类变量的统计描述
频数描述:频数就是一个变量在各个变量值上取值的个案数。如要了解学生某次考试的成绩情况,需要计算出学生所有分数取值,以及每个分数取值有多少个人,这就需要用到频数分析
(2)多个分类变量的统计描述
主要是用表格对不同变量下的不同类别的频数进行统计
4.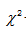 -分布
-分布
设X ~ N(μ,σ2),则 ~N(0,1);
~N(0,1);
令Y=X2 ,则 y 服从自由度为1的分布,即Y~X(1);
对于n个正态随机变量y1 ,y2 ,yn,则随机变量,![]()
称为具有n个自由度的X2分布;
分布的变量值始终为正;
分布的形状取决于其自由度n的大小,通常为不对称的正偏分布,但随着自由度的增大逐渐趋于对称;
期望为:E(X2)=n,方差为:D(X2)=2n(n为自由度)
5. T-分布
也被称为学生分布(student’s t); t 分布是类似正态分布的一种对称分布,通常要比正态分布平坦和分散。一个特定的分布依赖于称之为自由度的参数。随着自由度的增大,分布也逐渐趋于正态分布,
6. F-分布
设若U为服从自由度为n1的c2分布,即U~2(n1),V为服从自由度为n2的c2分布,即V~c2 (n2),且U和V相互独立,则:
称F为服从自由度n1和n2的F分布,记为F~F(n1,n2)
7. 参数估计
A:估计量与估计值
参数估计(parameter estimation)就是用样本统计量去估计总体的参数;
估计量:用于估计总体参数的统计量的名称,如样本均值,样本比例,样本方差等,例如: 样本均值就是总体均值μ的一个估计量;
参数用Θ表示,估计量用Θ表示;
估计值:估计参数时计算出来的统计量的具体值。
B:点估计
用样本的估计量的某个取值直接作为总体参数的估计值,例如:用样本均值直接作为总体均值的估计;用两个样本均值之差直接作为总体均值之差的估计;
无法给出估计值接近总体参数程度的信息,由于样本是随机的,抽出一个具体的样本得到的估计值很可能不同于总体真值;
一个点估计量的可靠性是由它的抽样标准误差来衡量的,这表明一个具体的点估计值无法给出估计的可靠性的度量
C:区间估计
在点估计的基础上,给出总体参数估计的一个估计区间,该区间由样本统计量加减估计误差而得到;
根据样本统计量的抽样分布能够对样本统计量与总体参数的接近程度给出一个概率度量,比如,某班级平均分数在75~85之间,置信水平是95%
D:置信水平
将构造置信区间的步骤重复很多次,置信区间包含总体参数真值的次数所占的比例,也称置信度表示为 (1 –α)% ,为是总体参数未在区间内的比例;
常用的置信水平值有 99%, 95%, 90%;
相应的α为0.01,0.05,0.10
E:置信区间
由样本估计量构造出的总体参数在一定置信水平下的估计区间;
统计学家在某种程度上确信这个区间会包含真正的总体参数,所以给它取名为置信区间;
如果用某种方法构造的所有区间中有95%的区间包含总体参数的真值,5%的区间不包含总体参数的真值,那么,用该方法构造的区间称为置信水平为95%的置信区间。同样,其他置信水平的区间也可以用类似的方式进行表述;
总体参数的真值是固定的,而用样本构造的区间则是不固定的,因此置信区间是一个随机区间,它会因样本的不同而变化,而且不是所有的区间都包含总体参数;
实际估计时往往只抽取一个样本,此时所构造的是与该样本相联系的一定置信水平(比如95%)下的置信区间。我们只能希望这个区间是大量包含总体参数真值的区间中的一个,但它也可能是少数几个不包含参数真值的区间中的一个;
当抽取了一个具体的样本,用该样本所构造的区间是一个特定的常数区间,我们无法知道这个样本所产生的区间是否包含总体参数的真值,因为它可能是包含总体均值的区间中的一个,也可能是未包含总体均值的那一个;
一个特定的区间总是“包含”或“绝对不包含”参数的真值,不存在“以多大的概率包含总体参数”的问题;
置信水平只是告诉我们在多次估计得到的区间中大概有多少个区间包含了参数的真值,而不是针对所抽取的这个样本所构建的区间而言的。
F:评价估计量的标准
无偏性:估计量抽样分布的数学期望等于被估计的总体参数;
有效性:对同一总体参数的两个无偏点估计量,有更小标准差的估计量更有效;
一致性:随着样本量的增大,估计量的值越来越接近被估计的总体参数
8. 假设检验
(1)假设检验的原理
先对总体的参数(或分布形式)提出某种假设,然后利用样本信息判断假设是否成立的统计方法;
逻辑上运用反证法,统计上依据小概率原理;
小概率是在一次试验中,一个几乎不可能发生的事件发生的概率;
在一次试验中小概率事件一旦发生,我们就有理由拒绝原假设
(2)原假设与备择假设
A:原假设
又称“0假设”,研究者想收集证据予以反对的假设,用H0表示;
所表达的含义总是指参数没有变化或变量之间没有关系;
最初被假设是成立的,之后根据样本数据确定是否有足够的证据拒绝它;
总是有符号=,≤或≥;
H0 :μ= 某一数值;
H0 :μ≤ 某一数值;
H0 :μ≥ 某一数值;
例如, H0 :μ=10cm
B:备择假设
也称“研究假设”,研究者想收集证据予以支持的假设,用H1或Ha表示;
所表达的含义是总体参数发生了变化或变量之间有某种关系;
备择假设通常用于表达研究者自己倾向于支持的看法,然后就是想办法收集证据拒绝原假设,以支持备择假设;
总是有符号≠,>或<;
H1 :μ≠某一数值;
H1 :μ> 某一数值;
H1 :μ< 某一数值
(3)双侧检验与单侧检验
备择假设没有特定的方向性,并含有符号“≠”的假设检验,称为双侧检验或双尾检验(two-tailed test);
备择假设具有特定的方向性,并含有符号“>”或“<”的假设检验,称为单侧检验或单尾检验(one-tailed test);
备择假设的方向为“<”,称为左侧检验;
备择假设的方向为“>”,称为右侧检验;

(4)根据P值做出决策
如果原假设为真,所得到的样本结果会像实际观测结果那么极端或更极端的概率;
P值告诉我们:如果原假设是正确的话,我们得到得到目前这个样本数据的可能性有多大,如果这个可能性很小,就应该拒绝原假设;
被称为观察到的(或实测的)显著性水平;
决策规则:若p值<α, 拒绝 H0;
双侧检验的P值如下:单侧检验的P值如下图的原理一样

三、 SPSS分析的整体的思路
1. 数据的获取
我们进行分析的数据主要有两种,一种是二手数据,也就是以其他的形式存在的数据;另一种是新数据,主要是以问卷存在的数据,所以,数据的获取就涉及到两部分,一部分是外部数据的导入,另一种是问卷数据的录入。
2. 数据的处理
将数据获取之后,首先要进行的是数据的处理,主要是重复值、缺失值、数据的验证、加权、选择个案、重组、转置等
3. 数据的预分析
数据处理好之后,在建模之前需要进行的是数据的预处理,数据的预处理是进行其他统计分析的基础和前提。通过基本统计方法的学习,可以对要分析数据的总体特征有比较准确的把握,从而有助于选择其他更为深入的统计分析方法,主要是描述统计分析、探索、交叉表等。
4. 模型的建立
根据预分析里面了解到的数据的结构以及业务的要求可以建立一些相应的模型,比如,需要对客户画像可以进行聚类,需要对销售量进行预测可以用回归等。
5. 报告的攒写
根据前面的数据分析的结果,和对业务目标理解写成一份相关的报告,并给出相关的建议。
2017年3月2日
1.各种GUI(图形用户界面)辅助编程
Rstudio:R语言综合开发环境;
Rattle:数据挖掘
R Commander:统计分析
2.

3.工作空间(workspace):R的当前工作环境,用于存储用户定义的对象。
ls():列出工作空间中的对象
rm(objectlist):移除一个或多个对象;
save(objectlist,file="myfile")保存对象object到文件"myfile";
save.image("myfile"):保存工作空间到文件myfile.Rdata;
load("myfile"):读取工作空间myfile.Rdata到当前会话。
5.

6.

sink("hongqianjin",append=false)
写代码
sink()//结束
(1).源文件没有则创建,(2)append=Flase,覆盖原来文件,注意原来文件全部删除,一行都不留。
7.mean() 均值
sd()方差
cor() 相关系数
options()显示或设置当前选项
runif()随机数
hist() 数据直方图
q() 退出R
3.高级编程
1.有两种基本的数据类型:原子向量和泛型向量。
2.attr()函数允许你创建任意属性并将其与对象相关联。
3.通过new.env()函数创建一个新的环境并通过assign()函数在环境中创建任务。
4.对象的值可以通过get()函数从环境中得到。
5.parent.env()函数展示了父环境。
6.trim(p)函数返回一个函数,即从矢量中修剪掉高低值得p%
7.system.time()函数可以用于确定CPU的数量和运行该函数所需的真实时间
8.内部调试函数
(1)debug 标记函数进行调试
(2)undebug() 取消标记函数进行调试
(3)browser() 允许单步通过函数的执行
(4)trace() 修改函数以允许暂时插入调试代码
(5)untrace() 取消追踪并删除临时代码
9.mad()函数计算一个数值向量的中位数绝对偏差
4.RStdio运行脚本
> setwd("C:/Users/lx/Desktop")//工作空间调整到sourcetest.R中
> source("sourcetest.R")
2017年3月3日
1.模板文件(example.Rmd)是一个纯文本文档,包含以下三个部分
(1)报告文字:所有解释性的语句和文字
(2)格式化语法:控制报告格式化的标签
(3)R代码:要运行的R语法
这个模板文件被作为参数传递到rmarkdown包的render()函数中,然后创建出一个网页文件example.html。此网页包含了报告文字和R结果。
2.is.vector(x) 检查x是不是向量
3.
4.


byrow 是按行进行排列,默认是按列排序
5.


6.因子

 b
b
7.列表

8.数据的输入

9.
##################数据框
patientID <- c(1, 2, 3, 4)
age <- c(25, 34, 28, 52)
diabetes <- c("Type1", "Type2", "Type1", "Type1")
status <- c("Poor", "Improved", "Excellent", "Poor")
patientdata <- data.frame(patientID, age, diabetes, status,
row.names = patientID)
patientdata
#################数据框attach()、detach()和with()
summary(mtcars$mpg)
plot(mtcars$mpg, mtcars$disp)
plot(mtcars$mpg, mtcars$wt)
#attach()
attach(mtcars)
summary(mpg)
plot(mpg, disp)
plot(mpg, wt)
detach(mtcars)
#with()
with(mtcars, {
stats <- summary(mpg)
stats
})
###因子
diabetes <- c("Type1", "Type2", "Type1", "Type1")
diabetes <- factor(diabetes)
status <- c("Poor", "Improved", "Excellent", "Poor")
status <- factor(status, ordered=TRUE)
status <- factor(status, order=TRUE,
levels=c("Poor", "Improved", "Excellent"))
###数值型变量,因子编码
gender <- c(1,2,1,2,3)
gender <- factor(gender, levels = c(1,2), labels = c("Male", "Female"))
###因子实例
patientID <- c(1,2,3,4)
age <- c(25, 34, 28, 52)
diabetes <- c("Type1", "Type2", "Type1", "Type1")
status <- c("Poor", "Improved", "Excellent", "Poor")
diabetes <- factor(diabetes)
status <- factor(status, order=TRUE)
patientdata <- data.frame(patientID, age, diabetes, status)
str(patientdata)
summary(patientdata)
###列表
g <- "My First List"
h <- c(25, 26, 18, 39)
j <- matrix(1:10, nrow = 5)
k <- c("one", "two", "three")
mylist <- list(title = g, ages = h, j, k)
mylist
###数据的输入
#使用键盘输入数据
mydata <- data.frame(age = numeric(0),
gender=character(0), weight=numeric(0))
mydata <- edit(mydata)
#从带分隔符的文本文件导入数据
grades <- read.table("studentgrades.csv", header=TRUE,
row.names="StudentID", sep=",",
colClasses=c("character", "character", "character",
"numeric", "numeric", "numeric"))
#加载包RODBC
library(RODBC)
#连接MySQL数据库
channel <- odbcConnect("MySQL", uid="root", pwd="123")
#查看数据库的表
sqlTables(channel)
#读取ODBC数据库中的表到数据库中
crs <- sqlFetch(channel, "course")
#向ODBC数据库提交一个查询并保存结果至数据框
crs_qry <- sqlQuery(channel, "select * from course")
#关闭连接
close(channel)
2017年3月4日
1.主成分分析(PCA)是一种数据降维技巧,它能将大量相关变量转化为一组很少的不相关变量,这些无关变量称为主成分。
2.探索性因子分析(EFA)是一系列用来发现一组变量的潜在结构的方法。它通过寻找一组更小的、潜在的或隐藏的结构来解释已观测到的、显示的变量间的关系。
3.psych包中有用的因子分析函数
principal() 含多种可选的方差旋转方法的主成分分析
fa() 可用主轴、最小的残差、加权最小平方或最大似然估计法估计的因子分析
fa.parallel() 含平行分析的碎石图
factor.plot() 绘制因子分析或主成分分析的结果
fa.diagram() 绘制因子分析或主成分的载荷矩阵
scree() 因子分析的主成分分析的碎石图
4.
1.广义线性模型扩展了线性模型的框架,它包含了非正态因变量的分析。
2.R中可通过glm()函数拟合广义线性模型。函数的基本形式为:
glm(formula,family=family(link=function),data=)
3.使用predict()函数,可以观察某个预测变量在各个水平时对结果概率的影响。
> testdata<- data.frame(rating=mean(Affairs$rating),age=seq(17,57,10),yearsmarried=mean(Affairs$yearsmarried),religiousness=mean(Affairs$religiousness))
> testdata
rating age yearsmarried religiousness
1 3.93178 17 8.177696 3.116473
2 3.93178 27 8.177696 3.116473
3 3.93178 37 8.177696 3.116473
4 3.93178 47 8.177696 3.116473
5 3.93178 57 8.177696 3.116473
> testdata$prob<- predict(fit.reduced,newdata=testdata,type="response")
> testdata
rating age yearsmarried religiousness prob
1 3.93178 17 8.177696 3.116473 0.3350834
2 3.93178 27 8.177696 3.116473 0.2615373
3 3.93178 37 8.177696 3.116473 0.1992953
4 3.93178 47 8.177696 3.116473 0.1488796
5 3.93178 57 8.177696 3.116473 0.1094738
1.lattice包中的图类型和响应的函数
3D等高线图 contourplot() z~x*y
3D水平图 levelplot() z~y*x
3D散点图 cloud() z~x*y|A
3D线框图 wireframe() z~y*x
条形图 barchart() x~A或A~x
箱线图 bwplot() x~A或A~x
点图 dotplot() ~x|A
柱状图 histogram() ~x
核密度图 densityplot() ~x|A*B
平行坐标曲线图 parallelplot() dataframe
散点图 xyplot() y~x|A
散点图矩阵 splom() dataframe
线框图 stripplot() A~x或x~A
2.
xyplot(mpg~disp|transmission,data=mtcars,
scales=list(cex=0.8,col="red"),
panel=panel.smoother,
xlab="Displacement",
ylab="Miles per Gallon"
main="uuu"
1.模板文件(example.Rmd)是一个纯文本文档,包含以下三个部分
(1)报告文字:所有解释性的语句和文字
(2)格式化语法:控制报告格式化的标签
(3)R代码:要运行的R语法
这个模板文件被作为参数传递到rmarkdown包的render()函数中,然后创建出一个网页文件example.html。此网页包含了报告文字和R结果。
2017年3月5日
1.主成分分析(PCA)是一种数据降维技巧,它能将大量相关变量转化为一组很少的不相关变量,这些无关变量称为主成分。
2.探索性因子分析(EFA)是一系列用来发现一组变量的潜在结构的方法。它通过寻找一组更小的、潜在的或隐藏的结构来解释已观测到的、显示的变量间的关系。
3.psych包中有用的因子分析函数
principal() 含多种可选的方差旋转方法的主成分分析
fa() 可用主轴、最小的残差、加权最小平方或最大似然估计法估计的因子分析
fa.parallel() 含平行分析的碎石图
factor.plot() 绘制因子分析或主成分分析的结果
fa.diagram() 绘制因子分析或主成分的载荷矩阵
scree() 因子分析的主成分分析的碎石图
4.主成分分析:Kaiser-Harris准则建议保留特征值大于1 的主成分,特征值小于1的成分所解释的方差比包含在单个变量中的方差更少。
5.探索性因子分析:Kaiser—Haris准则的特征值大于0,而不是大于1.
2017年3月6日
###加载RODBC
library(RODBC)
安装mysql驱动,并在管理工具中配置
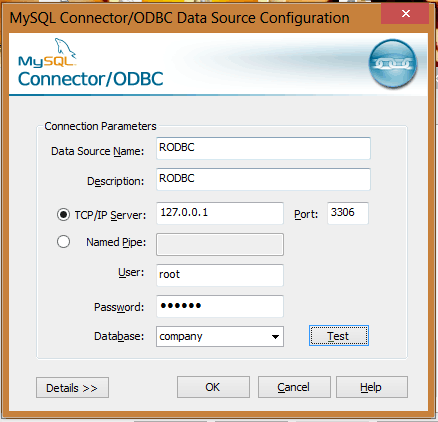
###连接RMySQL数据库
channel <- odbcConnect("RODBC", uid = "root", pwd = "123456")
###查看数据库的表
sqlTables(channel)
###读取ODBC数据库中表到R
orderdetail <- sqlFetch(channel, "orderdetail")
###向ODBC数据库提交查询
orderdetail_qry <- sqlQuery(channel, "select * from orderdetail
where productNo = 'P20050001'")
avg_quantity <- sqlQuery(channel, "select *, avg(quantity) from orderdetail
group by productNo")
###关闭连接
close(channel)
##################数据框
patientID <- c(1, 2, 3, 4)
age <- c(25, 34, 28, 52)
diabetes <- c("Type1", "Type2", "Type1", "Type1")
status <- c("Poor", "Improved", "Excellent", "Poor")
patientdata <- data.frame(patientID, age, diabetes, status,
row.names = patientID)
patientdata
#################数据框attach()、detach()和with()
summary(mtcars$mpg)
plot(mtcars$mpg, mtcars$disp)
plot(mtcars$mpg, mtcars$wt)
#attach()
attach(mtcars)
summary(mpg)
plot(mpg, disp)
plot(mpg, wt)
detach(mtcars)
#with()
with(mtcars, {
stats <- summary(mpg)
stats
})
###因子
diabetes <- c("Type1", "Type2", "Type1", "Type1")
diabetes <- factor(diabetes)
status <- c("Poor", "Improved", "Excellent", "Poor")
status <- factor(status, ordered=TRUE)
status <- factor(status, order=TRUE,
levels=c("Poor", "Improved", "Excellent"))
###数值型变量,因子编码
gender <- c(1,2,1,2,3)
gender <- factor(gender, levels = c(1,2), labels = c("Male", "Female"))
###因子实例
patientID <- c(1,2,3,4)
age <- c(25, 34, 28, 52)
diabetes <- c("Type1", "Type2", "Type1", "Type1")
status <- c("Poor", "Improved", "Excellent", "Poor")
diabetes <- factor(diabetes)
status <- factor(status, order=TRUE)
patientdata <- data.frame(patientID, age, diabetes, status)
str(patientdata)
summary(patientdata)
###列表
g <- "My First List"
h <- c(25, 26, 18, 39)
j <- matrix(1:10, nrow = 5)
k <- c("one", "two", "three")
mylist <- list(title = g, ages = h, j, k)
mylist
###数据的输入
#使用键盘输入数据
mydata <- data.frame(age = numeric(0),
gender=character(0), weight=numeric(0))
mydata <- edit(mydata)
#从带分隔符的文本文件导入数据
grades <- read.table("studentgrades.csv", header=TRUE,
row.names="StudentID", sep=",",
colClasses=c("character", "character", "character",
"numeric", "numeric", "numeric"))
#加载包RODBC
library(RODBC)
#连接MySQL数据库
channel <- odbcConnect("MySQL", uid="root", pwd="123")
#查看数据库的表
sqlTables(channel)
#读取ODBC数据库中的表到数据库中
crs <- sqlFetch(channel, "course")
#向ODBC数据库提交一个查询并保存结果至数据框
crs_qry <- sqlQuery(channel, "select * from course")
#关闭连接
close(channel)
#####RMySQL
library(RMySQL)
# 创建MySQL数据库的连接
con <- dbConnect(MySQL(), host = "127.0.0.1", dbname = "mysql",
username = "root", password = "123", port = 3308)
# 获取连接信息
summary(con)
dbInfo <- dbGetInfo(con) #返回数据框信息的列表
dbInfo[["host"]]
dbInfo[[1]]
dbInfo $ host
# 查看database下的所有表
dbListTables(con)
#删除数据库中的表格
dbRemoveTable(con, "fruits")
###写数据库表
fruits <- data.frame(id = 1:5,
name = c("apple", "banana", "pear", "corn", "watermelon"),
price = c(8.8, 4.98, 7.8, 6, 2.1),
status = c("none", "discount", "none", "sell out", "wholesale"))
dw <- dbWriteTable(con, "fruits", fruits)
###从数据库读取表
fruitdb <- dbReadTable(con, "fruits")
dbSendQuery(con, 'SET NAMES utf8')
Encoding(fruitdb) <- "UTF-8"
###写数据表,覆盖追加
testA <- data.frame(id = 1: 6,
e = c("a", "b", "c", "d", "e", "f"))
testB <- data.frame(id = 7:13,
e = c("g", "h", "i", "j", "k", "l", "m"))
dbWriteTable(con, "test", testA, row.names = F)
test1 <- dbReadTable(con, "test")
dbWriteTable(con, "test", testB,
append = T, row.names = F)
dbReadTable(con, "test")
##覆盖写testB
dbWriteTable(con, "test", testB, overwrite = TRUE)
###dbGetQuery() 和 dbSendQuery()两种方法
dbGetQuery(con, "select * from fruits limit 3")
#dbSendQuery()
res <- dbSendQuery(con, "select * from fruits")
data <- dbFetch(res, n = 2)
dbClearResult(res)
dbDisconnect(con)
# 用SQL语句批量查询
con <- dbConnect(MySQL(),host="127.0.0.1",dbname="mysql",
username="root", password="123", port = 3308,
client.flag= CLIENT_MULTI_STATEMENTS) #client.flag
sql <- "select * from fruits; select * from test"
res1 <- dbSendQuery(con, sql)
dbFetch(res1, n = 6)
if(dbMoreResults(con)) {
res2 <- dbNextResult(con)
dbFetch(res2, n = -1)
}
dbClearResult(res1)
dbClearResult(res2)
2017年3月7日
1.

2.缺失值

4.日期
![]()
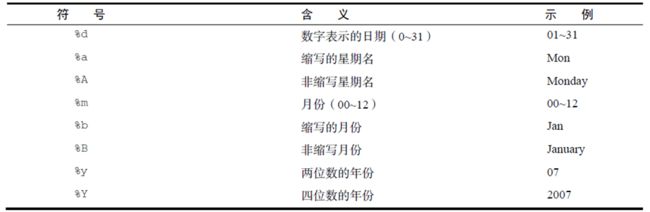


5.数据的排序

6.数据集的合并

7.分类
1.决策树是数据挖掘领域中的常用模型。其基本思想是对预测变量进行二元分离,从而构造一棵可用于预测新样本单元所属类别的树。
2.R中的rpart包支持rpart()函数构造决策树,prune()函数对决策树进行剪枝。
3.在完整树的基础上,prune()函数根据复杂度参数减掉最不重要的枝,从而将树的大小控制在理想的范围内。
4.rpart.plot包中的prp()函数可用于画出最终决策树。
5.随机森林是一种组成式的有监督学习方法。随机森林的算法涉及对样本单元和变量进行抽样,从而生成大量决策树。对每个样本单元来说,所有决策树依次对其进行分类,所有决策树预测类别中的众数类别即为随机森林所预测的这一样本单元的类别。
6.randomForest包根据传统决策树生成随机森林,而party包中的cforest()函数则可基于条件推断树生成随机森林。
7.支持向量机(SVM)是一类可用于分类和回归的有监督机器学习模型。其流行归功于两个方面:一方面,它们可输出较准确的预测结果;另一方面,模型基于较优雅的数学理论。
8.SVM可以通过R中kernlab包的ksvm()函数和e1071包中的svm()函数实现。
8.处理缺失数据的高级方法
1.缺失数据分为三类:(1)完全随机缺失(2)随机缺失(3)非随机缺失
2.函数is.na() is.nan() 和 is.infinite()可分别用来识别缺失值、不可能值和无穷值
3.三种流行的缺失值处理方法:推理法、行删除法和多重插插补
2017年3月9日
# 创建leadership数据框
manager <- c(1, 2, 3, 4, 5)
date <- c("10/24/08", "10/28/08", "10/1/08", "10/12/08", "5/1/09")
country <- c("US", "US", "UK", "UK", "UK")
gender <- c("M", "F", "F", "M", "F")
age <- c(32, 45, 25, 39, 99)
q1 <- c(5, 3, 3, 3, 2)
q2 <- c(4, 5, 5, 3, 2)
q3 <- c(5, 2, 5, 4, 1)
q4 <- c(5, 5, 5, NA, 2)
q5 <- c(5, 5, 2, NA, 1)
leadership <- data.frame(manager, date, country, gender, age,
q1, q2, q3, q4, q5, stringsAsFactors=FALSE)
### 创建新变量
mydata <- data.frame(x1 = c(2,2,6,4), x2 = c(3,4,2,8))
mydata$sumx <- mydata$x1 + mydata$x2
mydata$meanx <- (mydata$x1 + mydata$x2)/2
attach(mydata)
mydata$sumx <- x1 + x2
mydata$meanx <- (x1 + x2)/2
detach(mydata)
mydata <- transform(mydata, sumx = x1 + x2, meanx = (x1 + x2)/2)
###变量的重编码
leadership$age[leadership$age == 99] <- NA
leadership$agecat <- NA
leadership$agecat[leadership$age > 75] <- "Elder"
leadership$agecat[leadership$age >= 55 & leadership$age <= 75] <- "Middle Aged"
leadership$agecat[leadership$age < 55] <- "Young"
###变量的重命名
#方式1
fix(leadership)
#方式2
names(leadership)
names(leadership)[2] <- "testDate"
names(leadership)[6:10] <- c("item1", "item2", "item3", "item4", "item5")
#方式3
install.packages("plyr")
library(plyr)
leadership <- rename(leadership,
c(manager="managerID"))
###缺失值
y <- c(1, 2, 3, NA)
is.na(y)
#在分析中排除缺失值
x <- c(1, 2, NA, 3)
z <- sum(x)
y <- sum(x, na.rm = TRUE)
leadership
newdata <- na.omit(leadership)
newdata
###日期值
mydates <- as.Date(c("2007-06-22", "2004-02-13"))
strDates <- c("01/05/1965", "08/16/1975")
dates <- as.Date(strDates, "%m/%d/%Y")
myformat <- "%m/%d/%y"
leadership$testDate <- as.Date(leadership$testDate, myformat)
Sys.Date()
date()
today <- Sys.Date()
format(today, format="%B %d %Y")
format(today, format="%A")
#日期运算
startdate <- as.Date("2004-02-13")
enddate <- as.Date("2011-01-22")
days <- enddate - startdate
#difftime()计算时间间隔
today <- Sys.Date()
dob <- as.Date("1988-08-10")
difftime(today, dob, units="weeks")
#类型转换
a <- c(1,2,3)
a
is.numeric(a)
is.vector(a)
a <- as.character(a)
a
is.numeric(a)
is.vector(a)
is.character(a)
###数据排序
newdata <- leadership[order(leadership$age),]
attach(leadership)
newdata <- leadership[order(gender, age),]
detach(leadership)
attach(leadership)
newdata <- leadership[order(gender, -age),]
detach(leadership)
###merge
## use character columns of names to get sensible sort order
authors <- data.frame(
surname = I(c("Tukey", "Venables", "Tierney", "Ripley", "McNeil")),
nationality = c("US", "Australia", "US", "UK", "Australia"),
deceased = c("yes", rep("no", 4)))
books <- data.frame(
name = I(c("Tukey", "Venables", "Tierney",
"Ripley", "Ripley", "McNeil", "R Core")),
title = c("Exploratory Data Analysis",
"Modern Applied Statistics ...",
"LISP-STAT",
"Spatial Statistics", "Stochastic Simulation",
"Interactive Data Analysis",
"An Introduction to R"),
other.author = c(NA, "Ripley", NA, NA, NA, NA,
"Venables & Smith"))
m1 <- merge(authors, books, by.x = "surname", by.y = "name")
###数据框子集
# dataframe[row indices, column indices]
# 列子集
# 两种方式:第一种是列下标,第二种方式是列名称
# 删除数据框的列
# 三种方式
# 第一种方式:逻辑向量
leadership[, !names(leadership) %in% c("q3", "q4")]
# 第二种方式:dataframe $ colname <- NULL
# 第三种方式:dataframe[, c(-列下标)]
leadership[, -which(names(leadership) == "q3")]
leadership[, -which(names(leadership) %in% c("q3", "q4"))]
#####使用sqldf()函数
a <- sqldf("select (q1 + q2 + q3 + q4 + q5)/5 from leadership")
leadership $ averge <- a[[1]]
View(leadership)
sqldf("select gender, avg(age) from leadership group by gender")
###
#######数值和字符处理函数
###数学函数
abs(x)
sqrt(x)
ceiling(x)
floor(x)
trunc(x) 获取x中的整数部分
round(x,digits = n) x舍入到指定位的小数
signif(x, digits = n) 舍入x为指定的有效数字位数
log(x, base = n) 对x取以n为底的对数
log(x) 为自然对数
log10(x) 为常用对数
exp(x) 指数函数
###统计函数
mean() mean(c(1,2,3,4))
median() median(c(1,2,3,4))
sd() sd(c(1, 2, 3, 4))
var() var(c(1,2,3,4))
mad() (median absolute deviation)
mad(c(1,2,3,4))
quantile(x, probs) 求分位数
quantile(x, c(.3, .85))
range()
range(c(1,2,3,4))
sum()
diff(x, lag = n) 滞后差分
x <- c(1, 5, 23, 29)
diff(x)
min(c(1, 2, 3, 4))
max(c(1, 2, 3, 4))
#scale()对矩阵或数据框的指定列进行均值
scale(x, center = 1, scale = 1)
#实例
x <- 1:8
mean(x)
sd(x)
n <- length(x)
meanx <- sum(x) / n
css <- sum((x - meanx)^2)
sdx <- sqrt(css / (n - 1))
meanx
sdx
###字符处理函数
nchar(x) #计算x中的字符数量
x <- c("ab", "cde", "fghij")
length(x)
nchar(x[3])
substr(x, start, stop) 提取或替换
x <- "abcdef"
substr(x, 2, 4)
substr(x, 2, 4) <- "222"
# 在x中搜索模式,fixed = TRUE, 则pattern为一个文本字符串
global regular expression print
grep(pattern, x, ignore.case = FALSE, fixed = FALSE)
grep("A", c("b", "A", "c"), fixed = TRUE)
# 在x中搜索pattern,并以文本replacement将其替换
# fixed = FALSE,pattern为一个正则表达式
sub(pattern, replacement, x, ignore.case = FALSE, fixed = FALSE)
sub("\\s", ".", "Hello There")
# 按split分割x, 返回字符向量
strsplit(x, split, fixed = FALSE)
y <- strsplit("abc", "")
# 连接字符串,连接符为sep
# 可以连接多个向量
paste(..., sep = "")
paste("x", 1:3, sep = "")
paste("x", 1:3, sep = "M")
paste("Today is", date())
# 大写转换
toupper(x)
toupper("abc")
# 小写转换
tolower(x)
tolower("ABC")
############其他实用函数
length()
x <- c(2, 5, 6, 9)
length(x)
###seq(from, to, y)生成一个序列
indices <- seq(1, 10, 2)
#rep(x, n) 将x重复n次
y <- rep(1:3, 2)
#连接...对象,并输出到屏幕
cat(...)
name <- "Bob"
cat("Hello", name, "\b.\n")
###cat 和 paste 的区别
x <- c("x", "x", "x")
y <- c("a", "b", "c")
paste(x, y, sep = "") #向量元素依次连接
cat(x, y) #向量间连接
x <- c("x", "y")
y <- c("a", "b", "c")
paste(x, y, sep="") ###以向量形式保存结果
cat(x, y) ###保存结果为空,不保存连接结果,仅输出
mydata <- matrix(rnorm(30), nrow = 6)
mydata
apply(mydata, 1, mean)
apply(mydata, 2, mean)
apply(mydata, 2, mean, trim = 0.2)
###控制流——重复和循环
for (i in 1:10) print("Hello")
i <- 10
while(i > 0) {
print("Hello");
i <- i - 1;
}
### 条件执行
grade <- c("A", "A", "B", "B", "C")
if (is.character(grade)) {grade <- as.factor(grade)}
if (! is.factor(grade)) {grade <- as.factor(grade)} else {
print("Grade already is a factor")}
#ifelse()
score <- 0.6
score <- 0.3
ifelse(score > 0.5, print("Passed"), print("Failed"))
outcome <- ifelse(score > 0.5, "Passed", "Failed")
###switch示例
feelings <- c("sad", "afraid")
for (i in feelings) {
print(
switch(i,
happy = "I am glad you are happy",
afraid = "There is nothing to fear",
sad = "Cheer up",
angry = "Calm down now"
)
)
}
### 用户自编函数
# mystats(): 描述性统计量计算函数
mystats <- function(x, parametric = TRUE, print = FALSE) {
if (parametric) {
center <- mean(x);
spread <- sd(x);
} else {
center <- median(x);
spread <- mad(x);
}
if (print & parametric) {
cat("Mean=", center, "\n", "SD=", spread, "\n")
} else if (print & !parametric) {
cat("Median=", center, "\n", "MAD=", spread, "\n")
}
result <- list(center = center, spread = spread)
return(result)
}
set.seed(1234)
x <- rnorm(500)
y <- mystats(x)
y $ center
y $ spread
y <- mystats(x, parametric = FALSE, print = TRUE)
mydate <- function(type = "long") {
switch(type,
long = format(Sys.time(), "%A %B %d %Y"),
short = format(Sys.time(), "%m-%d-%d"),
cat(type, "is not a recognized type\n")
)
}
mydate("long")
mydate("short")
mydate()
mydate("medium")
#####矩阵的转置
cars <- mtcars[1:5, 1:4]
cars
t(cars)
###整合数据
options(digits = 3)
attach(mtcars)
aggdata <- aggregate(mtcars, by = list(Group.cyl = cyl, Group.gear = gear),
FUN = mean, na.rm = TRUE)
### reshape2包
install.packages("reshape2")
ID <- c(1, 1, 2, 2)
Time <- c(1, 2, 1, 2)
X1 <- c(5, 3, 6, 2)
X2 <- c(6, 5, 1, 4)
mydata <- data.frame(ID = ID, Time = Time, X1 = X1, X2 = X2)
library(reshape2)
md <- melt(mydata, id = c("ID", "Time"))
dcast(md, ID ~ variable, mean)
dcast(md, Time ~ variable, mean)
dcast(md, ID ~ Time, mean)
dcast(md, ID + Time ~ variable)
dcast(md, ID + variable ~ Time)
dcast(md, ID ~ variable + Time)
###实例
options(digits = 2)
Student <- c("John Davis", "Angela Williams", "Bullwinkle Moose",
"David Jones", "Janice Markhammer", "Cheryl Cushing",
"Reuven Ytzrhak", "Greg Knox", "Joel England",
"Mary Rayburn")
Math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
Science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
English <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18)
roster <- data.frame(Student, Math, Science, English,
stringsAsFactors = FALSE)
### 计算综合得分
z <- scale(roster[,2:4])
score <- apply(z, 1, mean)
roster <- cbind(roster, score)
### 对学生评分
roster $ grade <- NA
y <- quantile(score, c(.8, .6, .4, .2))
roster $ grade[score >= y[1]] <- "A"
roster $ grade[score < y[1] & score >= y[2]] <- "B"
roster $ grade[score < y[2] & score >= y[3]] <- "C"
roster $ grade[score < y[3] & score >= y[4]] <- "D"
roster $ grade[score < y[4]] <- "F"
name <- strsplit((roster$Student), " ")
Lastname <- sapply(name, "[", 2)
Firstname <- sapply(name, "[", 1)
roster <- cbind(Firstname, Lastname, roster[, -1])
roster <- roster[order(Lastname, Firstname),]
2017年3月10日
1.R语言的各种分布函数
rnorm(n,mean=0,sd=1)高斯(正态)
rexp(n,rate=1)指数
rgamma(n,shape,scale=1)γ分布
rpois(n,lambda)Poisson分布
rweibull(n,shape,scale=1)Weibull分布
rcauchy(n,location=0,scale=1)Cauchy分布
rbeta(n,shape1,shape2)β分布
rt(n,df)t分布
rf(n,df1,df2) F分布
rchisq(n,df)Χ2 分布
rbinom(n,size,prob)二项
rgeom(n,prob)几何
rhyper(nn,m,n,k)超几何
rlogis(n,location=0,scale=1) logistic分布
rlnorm(n,meanlog=0,sdlog=1)对数正态
rnbinom(n,size,prob)负二项分布
runif(n,min=0,max=1)均匀分布
rwilcox(nn,m,n) ,rsignrnak(nn,n) Wilcoxon分布
2017年3月12日
1.R语言 prod() 连乘
sort() 排序
rev() 倒序
seq() 按某种规律产生数列
t() 矩阵转置
diag()求矩阵对角线,求向量的为对角线矩阵,求标量为劫数的向量
2017年3月13日
1.
> x<-rnorm(5)
> x
[1] -0.1105737 2.5691194 -0.4457731 -0.9396918
[5] 1.0528433
创建一个名为x的向量,它包含5个来自标准正态分布的随机偏差。
2.mean() 均值
sd()标准差
cor() 相关差
demo()图形实例
2017年3月14日
1.批处理
R CMD BATCH options infile outfile
2.
lm()回归
summary()显示分析结果统计概要
cooks.distance() 计算和保存影响度量统计量
plot()绘图
predict()预测
3.使用一个新的包(vcd 一个用于可视化类别数据的包)
> help.start()
如果什么都不发生的话,你应该自己打开‘http://127.0.0.1:18928/doc/html/index.html’
> install.packages("vcd")
> help(package="vcd")
> library(vcd)
载入需要的程辑包:grid
> library(grid)
> library(vcd)
> help("Arthritis")
> Arthritis
> example("Arthritis")
> q()
创建数据集
1.R中有许多用于存储数据的结构,包括标量、响铃、数组、数据框和列表
2.R可以处理的数据类型(模式)包括数值型、字符型、逻辑型、复数型(虚数)和原生型(字节)
3.R将实例标识符称为rownames(行名),将类别型(包括名义型和有序型)变量称为因子
4.R拥有许多用于存储数据的对象类型,包括标量、向量、矩阵、数组、数据框和列表
5.向量c:当个向量中的数据必须拥有相同的类型或模式(数值型、字符型、逻辑型)。同一向量中无法混杂不同模式的数据。
6.矩阵matrix:每个元素都拥有相同的模式,默认是按列填充
7.数组array:数组中的数据也只能拥有一种模式
8.数据框data.frame:每一列数据的模式必须唯一
9.attach()可将数据框添加到R的搜索路径中
10.detach()将数据框中探索路径中移除。
11.R中的函数edit()会自动调用一个允许手动输入数据的文本编辑器。
mydata<- data.frame(age=numeric(0),gender=character(0),weight=numeric(0))
mydata<- edit(mydata)###简便等价写法是fix(mydata)
函数edit()事实上是在对象的一个副本上进行操作的。如不保存则丢失!
13.read.table()函数用于处理字符串并返回数据框
> mydatatatxt<- "
age gender weight
12 m 177
30 f 115
18 f 120"
> mydata<- read.table(header=TRUE,text=mydatatatxt)
14.read.table()带从分隔符的文本文件中导入数据
15.read.xlsx()导入Excel数据(library(xlsx))
16.导入spss数据
read.spss() library(foreign)
spss.get() library(Hmisc)
spss.get()是对read.spss()的一个封装
17.导入SAS
read.ssd() library(foreign)
sas.get() library(Hmisc)
read.sas7dbat() library(sas7dbat)
18.函数factor()可为类别型变量创建值标签
19.处理数据对象的使用函数
length() 显示对象中元素/成分的数量
dim() 显示某个对象的维度
str() 显示某个对象的结构
class() 显示某个对象的类或类型
mode() 显示某个对象的模式
names() 显示某对象中各成分的名称
c() 将对象合并入一个向量
cbind() 按列合并对象
rbind() 按行合并对象
object() 输出某个对象
head() 列出某个对象的开始部分
tail() 列出某个对象的最后部分
ls() 显示当前的对象列表
rm() 删除一个或更多个对象
newobject<- edit() 编辑对象并另存为newobject
fix() 直接编辑对象
dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
plot(dose, drugA, type = "b")
###图形参数
opar <- par(no.readonly = TRUE) ###复制当前的图形参数设置
par(lty = 2, pch = 17) ###设置参数
plot(dose, drugA, type = "b") ###根据设置的参数绘制图形
par(opar) ###还原原始设置
###图形参数 —— 符号和线条
plot(dose, drugA, type = "b", lty = 3, lwd = 3, pch = 15, cex = 2)


###添加文本、自定义坐标轴和图例
###函数自带参数设置选项
plot(dose, drugA, type = "b",
col = "red", lty = 2, pch = 2, lwd = 2,
main = "Clinical Trials for Drug A",
sub = "This is hypothetical data",
xlab = "Dosage", ylab = "Drug Response",
xlim = c(0, 60), ylim = c(0, 70))
annotation
###自定义坐标轴示例
windows()
x <- 1:10
y <- x
z <- 10/x
opar <- par(no.readonly = TRUE)
###增加边界大小
par(mar = c(5, 4, 4, 8) + 0.1)
###绘制x对y的图形
plot(x, y, type = "b",
pch = 21, col = "red",
yaxt = "n", lty = 3, ann = FALSE)
###添加x对1/x的直线
lines(x, z, type = "b", pch =22, col = "blue", lty =2)
###自定义坐标轴
axis(2, at = x, labels = x, col.axis = "red", las = 2)
axis(4, at = z, labels = round(z, digits =2),
col.axis = "blue", las = 0, cex.axis = 0.7,
tck = -.01)
mtext("y=1/x", side = 4, line = 3,
cex.lab = 1, las =2, col = "blue")
title("An Example of Creative Axes",
xlab = "X values",
ylab = "Y = X")
par(opar)
###图例
windows()
dose <- c(20, 30, 40, 45, 60)
drugA <- c(16, 20, 27, 40, 60)
drugB <- c(15, 18, 25, 31, 40)
opar <- par(no.readonly = TRUE)
par(lwd = 2, cex = 1.5, font.lab =2)
plot(dose, drugA, type = "b",
pch = 15, lty =1, col = "red", ylim = c(0, 60),
main = "Drug A vs. Drug B",
xlab = "Drug Dosage", ylab = "Drug Response")
lines(dose, drugB, type = "b",
pch = 17, lty = 2, col = "blue")
### 添加图例
legend(locator(1), title = "Drug Type",
c("A", "B"), lty = c(1, 2), pch = c(15, 17),
col = c("red", "blue"))
par(opar)
### 文本标注
attach(mtcars)
plot(wt, mpg,
main = "Mileage vs. Car Weight",
xlab = "Weight", ylab = "Mileage",
pch = 18, col = "blue")
text(wt, mpg, row.names(mtcars), cex = 0.6,
pos = 4, col = "red")
detach(mtcars)
### 展示不同字体族的代码
opar <- par(no.readonly = TRUE)
par(cex = 1.5)
plot(1:7, 1:7, type = "n")
text(3, 3, "Example of default text")
text(4, 4, family = "mono", "Example of mono-spaced text")
text(5, 5, family = "serif", "Example of serif text")
par(opar)
attach(mtcars)
opar <- par(no.readonly = TRUE)
par(mfrow = c(2,2))
plot(wt,mpg, main = "Scatterplot of wt vs. mpg")
plot(wt, disp, main = "Scatterplot of wt vs. disp")
hist(wt, main = "Histogram of wt")
boxplot(wt, main = "Boxplot of wt")
par(opar)
detach(mtcars)
###三行一列
attach(mtcars)
opar <- par(no.readonly = TRUE)
par(mfrow = c(3, 1))
hist(wt)
hist(mpg)
hist(disp)
par(opar)
detach(mtcars)
###函数layout()
attach()
layout(matrix(c(1, 1, 2, 3), 2, 2, byrow = TRUE))
hist(wt)
hist(mpg)
hist(disp)
detach(mtcars)
attach(mtcars)
layout(matrix(c(1, 1, 2, 3), 2, 2, byrow = TRUE),
widths = c(3, 1), heights = c(1, 2))
hist(wt)
hist(mpg)
hist(disp)
detach(mtcars)
### 图形布局的精细控制
windows()
opar <- par(no.readonly = TRUE)
par(fig = c(0, 0.8, 0, 0.8))
plot(mtcars $ wt, mtcars $ mpg,
xlab = "Miles Per Gallon",
ylab = "Car Weight")
par(fig = c(0, 0.8, 0.6, 1), new = TRUE)
boxplot(mtcars $ wt, horizontal = TRUE, axes = FALSE)
par(fig = c(0.7, 1, 0, 0.8), new = TRUE)
boxplot(mtcars $ mpg, axes = FALSE)
mtext("Enhanced Scatterplot", side = 3,
outer = TRUE, line = -3)
图形初阶
1.par() 指定图形参数选项
其中参数no.readonly=TRUE 可以生成一个可以修改的当前参数列表
2.用于指定符号和线条类型的参数
pch:指定绘图时使用的符号
cex:指定符号的大小
lty:指定线条的类型
lwd:指定线条的宽度
3.函数rgb()可基于红-绿-蓝三色值生成颜色,hsv()则基于色相-饱和度-亮度值来生成颜色
> rgb(1,1,1)
[1] "#FFFFFF"
> hsv(0,0,1)
[1] "#FFFFFF"
4.R用于创建连续型颜色向量的函数:rainbow()、heat.colors()、terrain.colors()、topo.colors()、cm.colors()
5.使用函数brewer.pal(n,name)来创建一个颜色值得向量,包(library(RColorBrewer)
> library(RColorBrewer)
> n<- 7
> mycolors<- brewer.pal(n,"Set1")##从Set1调色版中抽取了7种用十六进制表示的颜色并返回一个向量
> barplot(rep(1,n),col=mycolors)
> aa<-barplot(rep(1,n),col=mycolors)
> aa
[,1]
[1,] 0.7
[2,] 1.9
[3,] 3.1
[4,] 4.3
[5,] 5.5
[6,] 6.7
[7,] 7.9
> mycolors
[1] "#E41A1C" "#377EB8" "#4DAF4A" "#984EA3" "#FF7F00" "#FFFF33" "#A65628"
6.font用于指定绘图使用的字体样式。常规=1,粗体=2,斜体=3,粗斜体=4,符号字体(以Adobe符号编码表示)=5
7.在plot语句或单独的par()语句中添加ann=FALSE来移除某些高级绘图函数已经包含了默认的标题和标签。
8.axis():自定义的坐标图
las:标签是否平行于(=0)或垂直于(=2)坐标轴
tck:刻度线的长度(负值:图形外侧,正直:图形内侧,0表示禁用刻度线,1表示绘制网格线)
axes=FALSE 将禁用全部坐标轴。
xaxt="n"和yaxt="n" 将分别禁用X轴或y轴(会留下框架,只是去除了刻度)
8.lines()语句可以为一幅现有图形添加新的图形元素。
9.mtext()用于在图形的边界添加文本
10.函数abline()可以用来为图形添加惨嚎线
11.函数legend()来添加图例
12.text()可向绘图区域内部添加文本(也可以用来标示图形中的点),而mtext()则向图形的四个边界之一添加文本。
13.在R中使用函数par()或layout()可以组合多副图形为一幅总括图形
在par()函数中使用图形参数mfrow=c(nrows,ncols)来创建按行填充的图形矩阵,mfcol=c(nrows,nclos)按列填充
函数layout()的调用形式为layout(mat),其中mat是一个矩阵,它指定了所要组合的多个图的所在位置。
14.绝对宽度(以厘米为单位)可以通过函数lcm()来指定
15.par()函数中可以使用图形参数fig=c(x1,y1,x2,y2)将若干图形以任意排布方式组合到单幅图形中。
fig=默认会创建一幅图形,所以在添加到一幅现有的图形上时,请设定参数new=TRUE.
par(fig=c(0,0.5,0.55,1),new=TRUE)
数学知识
- 线性代数:在机器学习中,线性代数随处可见。主成分分析(PCA)、奇异值分解(SVD)、矩阵的特征分解、LU分解、QR分解、对称矩阵、正交化和正交归一化、矩阵的运算、分解、向量空间和范数等,这些都是理解机器学习中所使用的优化方法所必须的。
- 概率论和统计学:机器学习和统计学并不是很不同的领域。实际上,有人最近将机器学习定义为“在Mac上做统计”。机器学习所需的一些基本统计和概率理论主要有:组合学、概率规则和公理、贝叶斯定理、随机变量、方差和期望、条件和联合分布、标准分布(伯努利分布、二项式分布、多项式分布、均匀分布和高斯分布等)、动差生成函数(Moment Generating Functions)、最大似然估计(MLE)、先验和后验、最大后验估计(MAP)和抽样方法。
- 多元微积分:一些必要的内容包括微积分、偏导数、向量值函数、方向梯度、Hessian、 Jacobian、Laplacian和Lagragian分布。
- 算法和优化理论:这对我们理解机器学习算法的计算效率和可拓展性以及怎么利用数据中的稀疏性很重要。需要的知识主要包括:数据结构(二叉树、散列、堆、堆栈等)、动态规划、随机和次线性算法、图论、梯度/随机下降和原始-对偶方法。
- 其他还包括:复变函数(集合和序列、拓扑结构、度量空间、单值和连续函数、极限等)、信息论(熵、信息增益)、函数空间和流形。
2017年3月15日
1.依据随机化思想的统计方法:置换检验和自助法
2.coin包对于独立性问题提供了一个非常全面的置换检验的框架,而lmPerm包则专门用来做方差分析和回归分析的置换检验。
3.置换检验都是使用伪随机数来从所有可能的排列组合总进行抽样(当做近似检验时)。因此,每次检验的结果都所不同。
4.在coin包中,类别型变量和序数变量必须分别转化为因子和有序因子。另外,数据要以数据框形式存储。
5.相对于传统检验,提供可选置换检验的coin函数
检验 coin函数
两样本和K样本置换检验 oneway_test(y~A)
含一个分层(区组)因子的两样本和K样本置换检验 oneway_test(y~A|C)
Wilcoxon-Mann-Whitney秩和检验 wilcox_test(y~A)
Kruskal-Wallis检验 kruskal_test(y~A)
Pearson卡方检验 chisq_test(A~B)
Cochran-Mantel-Haenszel检验 cmh_test(A~B)
线性关联检验 lbl_test(D~E)
Spearman检验 spearman_test(y~x)
Friedman检验 friedman_test(y~A|C)
Wilcoxon符号秩检验 wilcoxsign_test(y1~y2)
注:在coin函数中,y和x是数值变量,A和B是分类因子,C是类别型区组变量,D和E是有序因子,y1和y2是匹配的数值变量
6.如变量都是有序8型,可使用lbl_test()函数(线性关联检验)来检验是否存在线性趋势。
7.spearman_test()函数提供了两数值变量的独立性置换检验。
8.对于两配对组的置换检验,可使用wilcoxsign_test()函数;对于两组时,使用friedman_test()函数。
9.independence_test()函数可以从置换角度来思考大部分传统检验,进而在面对无法用传统方法解决的问题时,使用户可以自己构建新的统计检验。
10.lmPerm包可做线性模型的置换检验。
2017年2月16日
1.数学函数
abs()绝对值
sqrt()平方根
ceiling()不小于x的最小整数
floor()不大于x的最大整数
trunc()向0的方向截取的x中的整数部分
round(x,digits=n)将x舍入为指定的小数
signif(x,digits=n)将x舍入为指定的有效数字位数
cos(),sin()、tan() 余弦、正弦、正切、
acos()、asin()、atan()反余弦、反正弦和正切
cosh(x)、sinh(x)、tanh(x)双曲余弦、双曲正弦和双曲正切
acosh(x)、asinh(x)、atanh(x)反双曲余弦、反双曲正弦和反双曲正切
log(x,base n) 对x取以n为底的对数
log(x) 为自然对数
log10(x)为常用对数
exp(x)指数函数
2.统计函数
mean() 平均数
median() 中位数
sd() 标准差
var() 方差
mad() 绝对中位差
quantile() 求分位数
range() 求值域
sum() 求和
diff() 滞后差分
min() 求最小值
max() 求最大值
scale(x,center=TRUE,scale=TRUE) 为数据对象x按列进行中心化(center=TRUE)或标准化(center=TRUE,scale=TRUE)
默认情况下,函数scale()对矩阵或数据框的指定列进行均值为0、标准差为1 的标准化
公式scale(mydate)*SD+M (SD为想要的标准差、M为想要的均值)
3.概率分布
Beta分布 beta
二项分布 binom
柯西分布 cauchy
(非中心)卡方分布 chisq
指数分布 exp
F分布 f
Gamma分布 gamma
几何分布 geom
超几何分布 hyper
对数正态分布 lnorm
Logistic分布 logis
多项分布 multinom
负二项分布 nbinom
正态分布 norm
泊松分布 pois
Wilcoxon符号秩分布 signrank
t分布 t
均匀分布 unif
Weibull分布 weibull
Wilcoxon秩和分布 wilcox
注:如果不指定一个均值和一个标准差,则函数将假设其为标准正态分布(均值为0,标准差为1)。
4.密度函数(dnorm)、分布函数(pnorm)、分位数函数(qnorm)和随机数生成函数(rnorm)
5.通过函数set.seed()显示指定这个种子,让结果可以重现
6.函数runif()用来生成0到1区间上服从均匀分布的伪随机数。
7.MASS包中的mvrnorm()函数可以获取来自给定均值向量和协方差阵的多元正态分布的数据。
8.字符串处理函数
nchar(x) 计算x中的最大字符数量
substr(x,start,stop) 提取或替换一个字符向量中的子串
grep(pattern,x,ignore.case=FALSE,fixed=FALSE) 在x中搜索某种模式,fixed=FALSE,pattern为正则表达式,若fixed=TRUE,则Pattern为一个文本字符串。返回值为匹配的下标。
sub(pattern,replacement,x,ignore.case=FALSE,fixed=FALSE) 在x中搜索pattern,并以文本replacement将其替换。
strsplit(x,split,fixed=FALSE) 在split处分割字符向量x中的元素,
paste(...,sep="") 连接字符串,连接符sep
toupper() 转换大写
tolower 小写转换
length() 对象x的长度
seq(from,to,by) 生成一个序列
rep(x,n) 将x重复n次
cut(x,n) 将连续型变量x分割为有着n个水平的因子,使用选项ordered_result=TRUE以创建一个有序型因子
pretty(x,n) 创建美观的分割点。
cat() 连接...中的对象,并将其输出到屏幕上或者文件上
9.R中提供了一个apply()函数,可将一个任意函数“应用”到矩阵、数组、数据框的任何维度上:
apply(x,MARGIN,FUN,...) x为数据对象,MARGIN为维度,FUN为函数。 在矩阵或数据框中,MARGIN=1表示行,MARGIN=2表示列
10.apply()可把函数应用到数组的某个维度上,而lapply()和sapply()则可将函数应用到列表list上。
11.options(digits=2)限定了输出小数点后数字的位数
12.函数warning()来生成一条错误提示信息,用message()来生成一条诊断信息,用stop()停止当前表达式的执行并提示错误
13整合于重构函数
函数t()即可对一个矩阵或数据进行转置
aggregate(x,by,FUN) 在R中使用一个或多个by变量和一个预先定义好的函数来折叠数据
13.reshape2包
melt()数据集的融合
dcast()函数读取已融合的数据,并用于整合数据的函数将其重塑。
1.abline()函数用来添加最佳拟合的线性直线
2.lowess()函数则用来添加一条平滑曲线
3.R有两个平滑曲线拟合函数:lowess() 和loess()
4.car包中的scatterplot()函数增强了散点图的许多功能。
5.pairs()函数可以创建基础的散点图矩阵
6.car包中的scatterplotMatrix()函数可以生成散点图矩阵
library(car)
scatterplotMatrix(~mpg+disp+drat+wt,data=mtcars,sprad=FALSE,smoother.args=list(lty=2))
线性和平缓(loess)拟合曲线被默认添加,主对角线处添加了核密度曲线和轴须图
spread=FALSE表示不添加展示分散度和对称信息的直线
smoother.args=list(lty=2)设定平滑(loess)拟合曲线使用虚线而不是实线
7.smoothScatter()函数可利用核密度估计生成用颜色密度来表示分布的散点图。
with(mydata,smoothScatter(x,y))
8.hexbin包中的hexbin()函数将二元变量的封箱放到六边形单元格中
library(hexbin)
with(mydata,{bin<- hexbin(x,y,xbins=50)
plot(bin,main="Hexagonal Binning with 10000 Observations")
})
9.scatterplot3d包中的scatterplot3d()函数绘制三个定量变量的交互关系
scatterplot3d(x,y,z)
library(scatterplot3d)
attach(mtcars)
s3d<- scatterplot3d(wt,disp,mpg,pch=16,highlight.3d=TRUE,type="h",main="qianjin")
fit<- lm(mpg~wt+disp)
s3d$plane3d(fit)
10.如何总R中导出一个表,和导入一个表
> getwd()
[1] "C:/Users/lx/Documents"
> setwd("C:/Users/lx/Documents")
> getwd()
[1] "C:/Users/lx/Documents"
> write.csv(mtcars,"mtcars")//导出
> mtcars<-read.csv("mtcars",header = TRUE)//导入,mtcar放到路径上
11.rgl包中的plot3d() 函数创建可交互的三维散点图
plot3d(x,y,z)
12.car包scatter3d()函数可包含各种回归曲面
基本图形
包library(vcd)
1.条形图
条形图通过垂直的或水平的条形展示了类别型变量的分布(频数)
barplot(height,)
height是一个向量或矩阵
height矩阵 时 beside=TRUE 分组条形图,beside=FALSE 堆砌条形图
names.arg允许指定一个字符向量作为条形的标签名
2.table()函数将其表格化
3.棘状图
棘状图对堆砌条形图进行了重缩放,这样每个条形的高度均为1,每一段的高度即表示比例
spine()
4.饼图
面积之比
pie(x,labels)
5.扇形图 包library(plotrix)
宽度之比
fan.plot()
6.直方图
直方图表述的是连续型变量的分布
直方图通过在x轴上将值域分割为一定数量的组,在y轴上显示响应 的频数,展示了连续变量的分布。
hist(x)
x是一个由数据值组成的数值向量
参数freq=FALSE表示根据概率密度,freq=TRUE频数绘制图形
breaks用于控制组的数量
7.轴须图(rug
轴须图是实际数据值得一种一维呈现方式
8.盒型
box()
9.核密度图
核密度估计是用于估计随机变量概率密度函数的一种非参数方法。
从总体上将,核密度图不失为一种用来观察连续型变量分布的有效方法。
绘制核密度方法:plot(density(x))
核密度图可用于比较组间差距
使用sm包中的sm.density.compare()函数可向图形叠加两组或更多的核密度图,使用格式:
sm.density.compare(x,factor)
核密度图的叠加不失为一种在某个结果变量上跨组比较观测的强大方法。箱线图同样是一项用来可视化分布和组间差异的绝佳图形手段
polygon()函数根据顶点的x和y轴坐标绘制了多边形
10.箱线图
箱线图(又称盒须图)通过绘制连续型变量的五数总括,即最小值、下四分位数(25%)、中位数(50%)、上四分位数(75%)以及最大值,描述了连续型变量的分布。
箱线图能够显示出可能为离群点(范围正负1.5*IQR以为的值,IQR表示四分位数,即上四分位数于下四分位数的差值)的观测。
boxplot()
箱线图可以展示单个变量或分组变量。
参数varwidth=TRUE将使箱线图的宽度与其样本大小的平方根成正比
参数notch=TRUE,可以得到含凹糟的箱线图
11.小提琴图
小提琴图是箱线图与核密度图的结合。
vioplot包中的vioplot()函数
小提琴图基本上时核密度图以镜像方式在箱线图上的叠加。
在图中,白点是中位数,黑色盒型范围是下四分位点到上四分位点,细黑线表示须.
外部形状即为核密度估计。
12.点图
点图提供了一种在简单水平刻度上绘制大量有标签值得方法
dotchart(x,labels=)
13.直方图、箱线图、轴须图以及点图可视化连续型变量分布的方式,使用叠加图的核密度图、并列箱线图和分组点图可视化连续型输出变量组间差异的方法
2017年3月18日
VBA
1.填充
Sub 填充()
'
' 填充 宏
'
' 快捷键: Ctrl+q
'
With Selection.Interior
.Pattern = xlSolid
.PatternColorIndex = xlAutomatic
.Color = 65535
.TintAndShade = 0
.PatternTintAndShade = 0
End With
End Sub
Sub 填充1()
Selection.Interior .Pattern = xlSolid
Selection.Interior .PatternColorIndex = xlAutomatic
Selection.Interior.Color = 65535
Selection.Interior .TintAndShade = 0
Selection.Interior .PatternTintAndShade = 0
End Sub
保存有VBA的代码的Excel文件是xlsm格式,否则无法保存代码
Sub 偏移()
ActiveCell.Offset(0, -1) = "洪前进"
With ActiveCell.Offset(0, -1).Font
.Size = 30
End With
End Sub
Sub 消息框()
MsgBox prompt:="前进", Buttons:=vbYesNo, Title:="qianjin"
End Sub
Sub 消息框()
'MsgBox prompt:="前进", Buttons:=vbYesNo, Title:="qianjin"
MsgBox "学习VBA", vbOKOnly, "数据挖掘"
End Sub
1.通过参数检验(t检验)和非参数检验(Mann-Whitney U检验、Kruskal-Wallis检验)方法研究组间差异
2.使用summary()函数来获取描述性统计量,summary()函数提供了最大值、最小值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计
3.函数fivenum()可返回图基五数总括(最大值、下四分位数、中位数、上四分位数和最大值)
4.Hmisc包中的describe()函数可返回变量和观测的数量、缺失值和唯一值得数目、平均值、分位数、以及五个最大的值和五个最小的值。
5.pastecs包中有一个名为stat.desc()的函数,它可以计算种类繁多的描述性统计量
stat.desc(x,basic=TRUE,desc=TRUE,norm=FALSE,p=0.95)
其中的x是一个数据框或时间序列
若basic=TRUE(默认值),则计算其中所有值、空值、缺失值的数量、以及最小值、最大值、值域、还有总和
若desc=TRUE(默认值),则计算中位数、平均数、平均数的标准误、平均数置信度为95%的3.置信区间、方差、标准差以及变异系数
若norm=TRUE,则返回正态分布统计量,包括偏度和峰度(以及它们的统计显著程度)和Shapiro-Wilk正态检验结果。这里使用了p值来计算平均数的置信区间(默认置信度为0.95)
6.psych包也拥有一个名为describe()的函数,它可以计算非缺失值的数量、平均值、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度和平均值得标准误
7.aggregate()仅允许在每次调用中使用平均数、标准差这样的单返回值函数,它无法一次仅返回若干个统计量。
8.doBy包和psych包提供了分组计算描述性统计量的函数。
doBy包中summaryBy()函数的使用格式为:
summaryBy(formula,data=dataframe,FUN=function)
9. 使用于创建和处理列链表的函数
table(var1,var2,var3,...,varN) 使用N个类别型变量(因子)创建一个N维列联表
xtabs(formula,data) 依据一个公式和一个矩阵或数据框创建一个N维列联表
prop.table(table,margins) 依margins定义的边际列表将表中条目表示为分数形式
margin.table(table,margins) 依margins定义的边际列表计算表中条目的和
addmargins(table,margins) 将概述边margins(默认是求和结果)放入表中
ftable(table) 创建一个紧凑的“平铺”式列联表
10.table()函数生成简单的频数统计表
prop.table()将频数转化为比例值(prop.table()*100 转化为百分比)
11.使用gmodels包中的CrossTable()函数是创建二维列联表
12.ftable()函数可以输出多维列联表
13.R提供了多种检验类别型变量独立性的方法,卡方独立性检验、Fisher精确性检验、Cochran-Mantel-Haenszel检验
14.卡方独立性检验
使用chisq.test()函数对二维表的行变量和列变量进行卡方独立性检验
p的值表示从总体中抽取的样本行变量与列变量是相互独立的概率。
15.Fisher精确检验
使用fisher.test()函数进行Fisher精确检验。Fisher精确检验的原假设:边界固定的列联表中行和列是相互独立的。
使用格式是:fisher.test(mytable) 其中mytable是一个任意行数大于等于2的二维列联表
16.Cochran-Mantel-Haenszel检验
mantelhaen.test()函数可用来进行Cochran-Mantel-Haenszel卡方检验,其原假设是,两个名义变量在第三个变量的每一层中都是条件独立的。
17.vcd包中的assocstats()函数可以用来计算二维列联表的phi系数、列联系数和Cramer‘s V系数
18.显著性检验评估了是否存在充分的证据以拒绝变量间相互独立的原假设。
19.相关系数可以用来描述定量变量之间的关系。相关系数的符号(-+)表明关系的方向(正相关或负相关),其值的大小表示关系的强弱程度(完全不相关时为0,完全相关为1)
20.R可以计算多种相关系数,包括Pearson相关系列、Spearman相关系数、Kendall相关系数、偏相关系数、多分格(Polychoric)相关系数和多系列(Polyserial)相关系数。
21.pearson极差相关系数衡量了两个定量变量之间的线性相关程度。Spearman等级相关系数则衡量分级定序变量之间的相关程度。Kendall‘s Tau相关系数也是一种非参数的等级相关变量。
cor()函数可以计算Pearson相关系列、Spearman相关系数、Kendall相关系数
cov()函数可以用来计算协方差。
22.偏相关是指在控制一个或多个定量变量时,另外两个定量变量之间的相互关系,可以使用ggm包中的pcor()函数计算偏相关系数。
计算格式为:
pcor(u,s)
s为协方差矩阵
23相关性的显著性检验
在计算好相关系数以后,如何对它们进行统计显著性检验呢?常用的原假设为变量间不相关(即总体的相关系数为0,独立)
可以使用cor.test()函数对当个的Pearson、Spearman和Kendall相关系数进行检验。
cor.test()每次只能检验一种相关关系,但psych包中提供的corr.test()函数可以为Pearson、Spearman或Kendall相关计算相关矩阵和显著性水平
24.在多元正态性的假设下,ggm包中的pcor.test()函数可以用来检验在控制一个或多个额外变量时两个变量之间的条件独立性。使用格式为:
pcor.test(r,q,n)
r是由pcor()函数计算得到的偏相关系数,q为要控制的变量数(以数值表示位置),n为样本大小
25.独立样本的t检验
一个针对两组的独立性样本t检验可以用于检验两个总体的均值相等的假设。
这里假设两组数据是独立的,并且是从正态总体中抽得。检验的调用格式为:
t.test(y~x,data)
26.非独立样本的t检验
前-后测试设计或重复测量设计同样会产生非独立的组
非独立样本的t检验假定组间的差异呈正态分布
27.如果能够假设数据是从正态总体中独立抽样而得的,那么可以使用方差分析(ANOVA)
28.组间差异的非参数检验
1.如果数据无法满足t检验或ANOVA的参数假设,可以转而使用非参数方法。
2.若两组数据独立,可以使用Wilcoxon秩和检验(Mann-Whitney U检验)来评估观测是否是从相同的概率分布中抽得(即,在一个总体中获得更高得分的概率是否比另一个总体要大)。调用的格式为:
wilcox.test(y~x,data)
29.Wilcoxon符号秩检验是非独立样本t检验的一种非参数代替方法。它使用于两组成对数据和无法保证正态性假设的情境。
30.多余两组的比较
如果无法满足ANOVA设计的假设,那么可以使用非参数方法来评估组间的差异。如果各组独立,则Kruskal-Wallis检验将是一种使用的方法。如果各组不独立(如重复测量设计或随机区组设计),那么Friedman检验更合适;
Kruskal-Wallis检验的调用格式为:
kruskal.test(y~A,data)
Friedman检验的调用格式为:
friedman.test(y~A|B,mdata)
2017年3月28日
1.OLS(最小二乘)回归是通过预测变量的加权和来预测量化的因变量,其中权重是通过数据估计而得到的参数。
2.在R中,拟合线性模型最基本的函数就是lm(),格式是:
myfit<- lm(formula,data)
3.回归模型的假设条件很苛刻:结果或响应变量不仅是数值型的,而且还必须来自正态分布的随机抽样。
4.回归分析通知那些一个或多个预测变量(自变量)来预测响应变量(因变量)的方法。通常,回归分析可以用来挑选与响应变量相关的解释变量,可以描述两者的关系,也可以生成一个等式,通过解释变量来预测响应变量。
5.回归分析的各种变体
简单线性 用一个量化的解释变量预测一个量化的响应变量
多项式 用一个量化的解释变量预测一个量化的响应变量,模型的关系是n阶多项式
多层 用拥有等级结构的数据预测一个响应变量.也被称为分层模型、嵌套模型或混合模型
多元线性 用一个或多个量化的解释变量预测一个量化的响应变量
多变量 用一个或多个解释变量预测多个解释变量
Logistic 用一个或多个解释变量预测一个类别型响应变量
泊松 用一个或多个解释变量预测一个代表频数的响应变量
Cox比例风险 用一个或多个解释变量预测一个事件(死亡、失败或疾病复发)发生的时间
时间序列 对误差项相关的时间序列数据建模
非线性 用一个或多个量化的解释变量预测一个量化的响应变量,不过模型是非线性的
非参数 用一个或多个量化的解释变量预测一个量化的响应变量,模型的形式源自数据形式,不事先设定
稳健 用一个或多个量化的解释变量预测一个量化的响应变量,能抵御强影响的干扰
6.对拟合线性模型非常有用的函数
summary() 展示拟合模型的详细结果
coefficients() 列出拟合模型的模型参数(截距项和斜率)
confint() 提供模型参数的执行区间(默认95%)
fitted() 列出拟合模型的预测值
residuals() 列出拟合模型的残差值
anova() 生成一个拟合模型的方差分析表,或者比较两个或更多拟合模型的方差分析表
vcov() 列出模型参数的协方差矩阵
AIC() 输出赤池信息统计量
plot() 生成评价拟合模型的诊断图
predict() 用拟合模型对新的数据集预测响应变量值
7.非线性模型可用nls()模型进行拟合
8.car包中的scatterplot()函数可以绘制二元关系图
9.cor()函数提供了二变量之间的相关关系,
car()包中scatterplotMatrix()函数则会生成散点图矩阵
scatterplotMatrix()函数默认在非对角线区域绘制变量间的散点图,并添加平滑和线性拟合曲线。对角线区域绘制每个变量的密度图和轴线图
> states<- as.data.frame(state.x77[,c("Murder","Population","Illiteracy","Income","Frost")])
> View(states)
> library(car)
> cor(state)
Murder Population Illiteracy Income Frost
Murder 1.0000000 0.3436428 0.7029752 -0.2300776 -0.5388834
Population 0.3436428 1.0000000 0.1076224 0.2082276 -0.3321525
Illiteracy 0.7029752 0.1076224 1.0000000 -0.4370752 -0.6719470
Income -0.2300776 0.2082276 -0.4370752 1.0000000 0.2262822
Frost -0.5388834 -0.3321525 -0.6719470 0.2262822 1.0000000
> scatterplotMatrix(states,spread = FALSE,smoother.args = list(lty=2),main="Sactter Plot Matrix")
> windows()
> scatterplotMatrix(states,spread = FALSE,smoother.args = list(lty=2),main="Sactter Plot Matrix")
10.通过effects包中的effect()函数,可以用图形展示交互项的结果,格式为:
plot(effect(term,mod,,xlevels),multiline=TRUE)
term即模型要画的项,mod为通过lm()拟合的模型,xlevels是一个列表,指定变量要设定的常量值,multiline=TRUE选项表示添加相应直线
> library(effects)
> windows()
> plot(effect("hp:wt",fit,,list(wt=c(2.2,3.2,4.2))),multiline = TRUE)
11.对lm()函数返回的对象使用plot()函数,可以生成评价模型拟合的四副图:
(1)正态性:(Normal Q-Q):如满足正态假设,那么图上的点应该落在呈45度角的直线上;若不是如此,那么就违反了正态性的假设。
(2)线性:(Residuals vs Fitted):若变量与自变量线性相关,那么残差值与预测(拟合)值就没有任何关系。
(3)同方差性:(Scale-Location Graph):若满足不变方差假设,那么在“位置尺度图”中,水平线周围的点应该随机分布
(4)残差于杠杆图):Residuals vs Leverage:提供了你可能关注的单个观测点的信息,从图形可以鉴别离群点、高杠杆值点和强影响点。
12.car包中的回归诊断实用函数
qqplot() 分位数比较图
durbinWatsonTest() 对误差自相关性做Durbin-Watson检验
crPlots() 成分与残差图
ncvTest() 对非恒定的误差方差做得分检验
spreadLevelPlot() 分散水平检验
outlierTest() Bonferroni离群点检验
avPlots() 添加的变量图形
inluencePlot() 回归影响图
scatterplot() 增强的散点图
scatterplotMatrix 增强的散点图矩阵
vif() 方差膨胀因子
13.时间序列数据通常呈现自相关性------相隔时间越近的观测相关性大于相隔越远的观测。
car包提供了一个可做Durbin-Watson检验的函数,能够检测误差的序列相关性。
14.线性
通过成分残差图也称偏残差图,可以看看因变量与自变量之间是否呈线性关系,也可以看是否有不同于已设定线性模型的系统偏差,图形可用car包中的crPlots()函数绘制
15.同方差性
car包提供了两个有用的函数,可以判断误差方差是否恒定。
ncvTest()函数生成一个计分检验,零假设为误差方差不变,备择假设为误差方差随着拟合值水平的变化而变化。若检验显著,则说明存在异方差性(误差方差不恒定)
spreadLevelPlot()函数创建一个添加了最佳拟合曲线的散点图,展示标准化残差绝对值与拟合值得关系。
16.gvlma包中的gvlm()函数能对线性模型假设进行综合验证,同时还能做偏斜度、峰度和异方差性的评价。也就是它给模型假设提供了一个单独的综合检验(通过/不通过)
17.多重共线性可用统计量(VIF,方差膨胀因子)进行检测.VIF的平方根表示变量回归参数的置信区间能膨胀为与模型无关的预测变量的程度。car包中的vif()函数提供VIF值,一般原则下,根号vif>2就表明存在多重共线性问题
18.离群点的判断方法
(1)Normal Q-Q图,落在置信区间带外的点即可被认为是离群点。
(2)粗糙的判断标准:标准化残差值大于2或者小于-2的点可能是离群点,需要特别关注
(3)car包提供了一种离群点的统计验证方法。outlierTest()函数可以求得最大标准化残差绝对值Bonferroni调整后的p值
18.高杠杆值点
高杠杆值观测点,即与其他预测变量有关的离群点。也就是说,它们是由许多异常的预测变量值组合起来的,与响应变量值没有关系。
高杠杆值的观测点通过帽子统计量判断
高杠杆值点可能是强影响点,也可能不是,这要看它们是否是离群点。
19.强影响点
强影响点,即对模型参数估计值有些比例失衡的点。
有两种方法可以检测强影响点:Cook距离,或称D统计量,以及变量添加图,一般来说,Cook's D值大于4/(n-k-1),则表明它是强影响点,其中n为样本量大小,k是预测变量数目
20.有四种方法可以处理违背回归假设的问题:
(1)删除观测点
(2)变量变换
(3)添加或删除变量
(4)使用其他回归方法
21.变量变换
car包中的powerTransform()函数通过r(参数那么la)的最大似然估计来正态化变量XN(x的N次方)
car包中的boxTidwell()函数通过获得预测变量幂数的最大似然估计来改善线性关系。
22.anova()函数可以比较两个嵌套模型的拟合优度
23.AIC赤池信息准侧
AIC也可用来比较模型,它考虑了模型的统计拟合度以及用来拟合的参数数目,AIC值较小的模型要优先选择,它说明模型用较少的参数获得了足够的拟合度,用AIC()函数实现
24.从大量候选变量中选择最终的预测变量有两种流行的方法:逐步回归法和全子集回归
逐步回归法中,模型会一次添加或者删除一个变量,直到达到某个判停准侧为准。
MASS包中的stepAIC()函数可以实现逐步回归模型,依据的是精确AIC准侧
全子集回归是指所有可能的模型都会被检测。
全子集回归可用leaps包中的regsubsets()函数实现。
25.bootstrap包中的crossval()函数可以实现k重交叉验证
1.关注重点通常会从预测转向组别差异的分析,这种分析方法称作方差分析(ANOVA)
2.单因素协方差分析(ANCOVA)扩展了单因素方差分析(ANOVA),包含一个或多个定量的协变量。
3.HH包中的ancova()函数可以绘制因变量、协变量和因子之间的关系图
4.通常处理的数据集是宽格式,即列是变量,行是观测值,而且 一行一个受试对象。不过在处理重复测量设计时,需要有长格式数据才能拟合模型。
5.当因变量(结果变量)不止一个时,可用多元方差分析(MANOVA)对它们同时进行分析。
6.manova()函数能对组间差异进行多元检验。
7.评估假设检验
单因素多元方差分析有两个前提假设,一个时多元正态性,一个是方差--协方差矩阵同质性。第一个假设即指因变量组合成的向量服从一个多元正态分布。
方差-协方差矩阵同质性即指各组的协方差矩阵相同,通常可用Box's M检验来评估该假设。
1.功效分析可以帮助在给定置信度的情况下,判断检测到给定效应值时所需的样本量。反过来,它也可以帮助你在给定置信水平情况下,计算在某样本量内能检测到给定效应值得概率。如果概率低得难以接受,修改或者放弃这个实验将使一个明智的选择。
2.由于功效分析针对的是是假设检验,我们将首先简单回顾零假设显著性检验(NHST)过程,然后学习如何用R进行功效分析,主要关注pwr包
3.预先预约的阈值(0.05)称为检验的显著性水平
4.pwr包中的函数
pwr.2p.test() 两比例(n相等)
pwr.2p2n.test() 两比例(n不相等)
pwr.anova.test() 平衡的单因素ANOVA
pwr.chisq.test() 卡方检验
pwr.f2.test() 广义线性模型
pwr.p.test() 比例(单样本)
pwr.r.test() 相关系数
pwr.t.test() t检验(单样本、两样本、配对)
pwr.t2n.test() t检验(n不相等的两样本)
5.卡方检验
卡方检验常常用来评价两个类别型变量的关系。典型的零假设是变量之间独立,备择假设是不独立。
pwr.chisq.test()函数可以用来评估卡方检验的功效、效应值和所需的样本大小。
6.典型的功效分析是一个交互性的过程。
功效分析的一个重要附加效益是引起方向性的转变,它鼓励不要仅仅关注于二值型(即效应存在还是不存在)的假设检验,而应该仔细思考效应值增加的意义。
2017年3月30日
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 30 09:30:25 2017
@author: Administrator
"""
#第一天
a = 5
b = 4
#用两个新变量交换值
a_backup = a
b_backup = b
a = b_backup
b = a_backup
#用一个新变量交换值
a_backup = a
a = b
b = a_backup
#不用新变量交换值
a = a + b
b = a-b
a = a-b
#字符串
s1 = '我是字符串'
s2 ="我也是字符串"
s3 = ''' 我也
是
字
符串 '''
#为啥要搞这么多种引号
" i'm 21 "
''' i'm "abc" 21 '''
#还可以加\
'i\'m 21'
#数值常量
1 #整型
1.0 #浮点型
complex(1,2) #复数
a_234234 = '我是变量'
#1_aaaa = 1 # 数字在前面,这个会报错
#变量大小写敏感,a和A是两个不一样的变量
a = 1
A = 2
#变量名不可以是Python内置关键字,如min、max、range等;
#类型转换
num = 1234
s_num = str(num)
#int('a')
int('123')
float(num)
int(1.234) #警惕,这个会损失精度
str(complex(1,3))
#算术运算符:
3 + 5.6 #内部会先把整数转换成小数再相加
7 -1
3*3.14
5/3
11//4
11%4
2 ** 3
#关系运算符
a = 7
b = 6
a > b
a < b
a <= b
a >= b
a == b
a != b
#布尔算符
True
False
#逻辑运算符:
True and True
True and False
True or False
not True
1 and 3 #挑那个大的
1 and 0 #0
#list 列表
l = [1,"aaa"] #c(1,2,3) 在这里叫列表,可以放不同的类型
l2 = [1,2,3,4,5,100,80,60,1,1,2]
l2[0]
l2[0:3]
l2[4]
len(l2) #len返回数组的长度
l2[len(l2)-1] #取出最后一个元素
l2[-1] #可以省略len(l2),写成这样
l2[0] = 100 #list 是可变的
L2 = list(range(1,101,2))
l2[::-1] #倒序取里边的元素
l2[-4:] #取最后四个元素 是l2[len(Mylist)-4:len(Mylist)]的简写
l2[:] #取出全部的元素
#[:]取全部值跟直接l2的区别
a = l2
a[0] = 100
b = l2[:]
b[1] = 1000
#列表方法
l2.append(1111) #增加一个元素
l2.insert(2,22222) #在第二个位置插入22222
l3 = [9,8,7]
l2.extend(l3) #每次可以在列表的末尾增加多个元素
last_one = l2.pop()
l2.remove(3) #删除某一个元素
l2.clear() #全部删除
l2.sort() #排序
l2.reverse()
l2.index(100)
l2.count(1)
l3 = l2.copy() #值不会跟着l2变化,和[:]一样
l2[0] = 1000000
height = [172,165,188,170,168,177,174]
weight = [66.2,60,75.3,80,55,65,67.8]
#height/weight #报错,不能做向量化运算 要做的话需要numpy模块
import numpy as np
Height = np.array(height)
Weight = np.array(weight)
BIM = Weight/(Height/100)**2
#tuple 元组
t1 = (1,2,3,1,1,1)
t2 = 1, #当创建的元组只有一个元素时,必须在元素后面加上逗号;
t3 = t1+t2 #可通过+完成多个元组之间的连接
t1[0]
t1[-1]
t1[0] = 100 #会报错,元组不可变
T2 = tuple(range(1,6)) #用函数创建元组。。
T3 = ('My','name','is','Sim')
t1.count(1)
t1[(t1.index(1)+1):].index(1) + (t1.index(1)+1) #返回第二个1所在的位置
t2l = list(t1) #元组变成list,便于增,删,改
#dict 字典
d1 = {"key1":[1,2,3,4],"key2":2} #如果键相同,会被覆盖 d1 = {"key1":1,"key1":2}
d1['key1'] #用键获取值
d1.keys() #取出全部的键
d1.values() #取出全部的值
#字典并不是序列,其元素并不是有序排放的,位置并不重要。
#不能用下标去索引
#d1[1] 报错
dict1 = {'name':'Sim'}
dict2 = {'name':'Sim','gender':'Male','age':27,'address':'Jiangsu'}
dict3 = {'name':'Bob','score':[67,90,72]}
dict4 = {'name':['Sim','BaiSheng'],'score':[84,87]}
dict5 = {'name':{'fstname':'Liu','lstname':'Sim'},'job':['teacher','data miner']}
dict2['address']
dict4['name'][1]
dict5['name']['fstname']
#字典虽不是一个序列,但却是一个非常灵活的数据结构,可以进行增、删、改和查的操作!
del dict2['name']
score = dict3.pop('score')
#clear只是把dict2里面的值删除。还能有个{}剩下 而del删除,变量名都可以删除
dict2.clear()
del dict1
#增加一个值,通过给新键赋值:
dict1['height'] = 167;
#把dict3的内容copy到dict2里面,重复的键值会排重用的是dict3值!
dict2.update(dict3)
#通过列表方法增加列表类型的值
dict3['score'].append(85) #单个
dict3['score'].extend([67,89]) #多个
#改
dict1['name'] = 'Snake'
dict3['score'][0] = 77
dict4['name'] = ['Snake','Peter']
#字典方法
newdict = dict1.copy()
dict1['asdfadsf'] #会报错
dict1.get('name')
dict1.get('asdf') #不会报错
dict1.setdefault("0")
#items() 列表的形式返回可遍历的(键, 值) 元组数组
for a in dict1.items():
print(a)
dict1.keys()
dict1.values()
#把键值成对的POP出来,返回的是元组类型
dict1.popitem()
#字典与列表的比较
#当数据集非常大的时候,通过字典的方式查找数据会比列表快很多!
l1 = ['Sim','Male',27,'Jiangsu']
print("%s's age is %d!" %(l1[0],l1[2]))
print("%s's age is %d!" %(l1[l1.index('Sim')],l1[l1.index(27)]))
#用dict()方式创建字典
dict1 = dict(name = 'Sim', gender = 'M', age = 27, address = 'JiangSu')
print("%s's age is %d!" %(dict1['name'],dict1['age']))
#print 是一个输出函数
print(dict1)
#print("%s is %d" %("Sim",27))
print("%s is %d" %(dict2['name'],dict2['age']))
dict5['name']['lstname'] = 'Snake'
# 控制流和自定义函数
#if分支语句
if True:
print('true')
#保存输入数据
a_num = input("please input a value:")
#单个分支
if int(a_num) < 100:
print("less than 100")
#两个分支
if int(a_num) < 100:
print("less than 100")
else:
print("more than 100")
#多个分支
a_num = input("please input a score:")
if int(a_num) > 90:
print("好")
elif(int(a_num) > 80):
print("良")
elif(int(a_num) > 60):
print("及格")
else:
print("SB")
#循环
i = 0
sum_i = 0
while(i<100):
i = i + 1 # i+=1
sum_i = sum_i + i # sum_i += i
print("第%d次循环, sum_i = %d" %(i,sum_i))
#循环
#有一个初始值为5,公差为3的等差数列,计算前100项的和
i = 0
sum_i = 0
a = 5
while(i<100):
i = i + 1
#通项
sum_i = sum_i + a
print("第%d次循环, a = %d sum = %d" %(i,a,sum_i))
a = a + 3
#100以内的偶数,奇数全部相加,
i = 0
sum_au = 0
sum_ji = 0
while(i<100):
i = i + 1 # i+=1
if(i % 2 == 0):
sum_au = sum_au + i
else:
sum_ji = sum_ji + i
print(sum_au,sum_ji)
2017年4月1日
# -*- coding: utf-8 -*-
"""
Created on Fri Mar 31 10:24:20 2017
@author: Administrator
"""
#
#找出,100以内所有的素数。。
#素数:只能除尽1和它本身的数、
#先判断一个数是不是素数
i = 2
l = list()
while(i < 100):
j = 2
is_sushu = True
while(j < i):
if(i%j == 0):
is_sushu = False
j = j + 1
if(is_sushu):
l.append(i)
i = i + 1
print(l)
#for循环的语法
for i in range(5,10):
print(i)
list1 = [0,11,22,33,44,55,66,77,88,99]
for i in list1:
print(i)
string1 = "helloworld"
for i in string1:
print(i)
#建议使用的方式,即可以得到索引,也可以有值
list1 = [0,11,22,33,44,55,66,77,88,99]
for i in range(len(list1)):
print(i,list1[i])
#for循环一个字典
dict1 = {'name':'jack','gender':'man','age':30}
dict1.items()
for key,value in dict1.items():
print(key,"----->",value)
#这次用for循环
#找出,100以内所有的素数。。
#素数:只能除尽1和它本身的数、
#先判断一个数是不是素数
i = 18
is_sushu = True
for j in range(2,i):
if i % j == 0:
is_sushu = False
#然后判断2到100所有的数是不是素数
l = list()
for i in range(2,100):
is_sushu = True
for j in range(2,i):
if i % j == 0:
is_sushu = False
if(is_sushu):
l.append(i)
#自定义函数
def f():
print("i am a function")
#参数(必选参数)和返回值
def me_add_me(a):
return a + a
#参数(可选参数),可选参数一定要在必选参数后面
def a_add_b(a,b = 1):
return a + b
#定义一个函数,判断一个数是不是素数
def is_sushu(num):
is_sushu = True
for i in range(2,num):
if(num % i == 0):
is_sushu = False
return is_sushu
#找100以内的素数
for i in range(2,100):
if(is_sushu(i)):
print(i)
#一个*号,可变参数,调用时传多个参数,
#它会变成元组传进去,可以用for循环遍历
def f(*a):
for i in a:
print(i)
f(1,2,3,4,5)
#两个*号,关键词参数
def f(**a):
for k,v in a.items():
print(k,"---------->>",v)
#三个循环练习
# 题目1,输出前100个这样的数
## 规律为数列1,1,2,3,5,8,13,21....
l = [1,1]
for i in range(2,100):
l.append( l[-1] + l[-2])
#题目2:求1+2!+3!+...+20!的和
#先搞出来一个数的阶乘
def jie_cheng(a):
jie_c = 1
for i in range(a):
jie_c = jie_c * (i + 1)
return jie_c
#现在计算前20项的和
sum_jiec = 0
for i in range(20):
sum_jiec = sum_jiec + jie_cheng(i+1)
print(sum_jiec)
#题目3:有一分数序列:
#2/1,3/2,5/3,8/5,13/8,21/13...
#求出这个数列的前20项之和。
#1.程序分析:请抓住分子与分母的变化规律。
fenzi = [2,3]
fenmu = [1,2]
sum = 2/1 + 3/2
for i in range(2,20):
fenzi.append(fenzi[-1] + fenzi[-2])
fenmu.append(fenmu[-1] + fenmu[-2])
sum = sum + fenzi[i]/fenmu[i]
#sum = sum + fenzi[-1]/fenmu[-1]
#读取数据
import pandas as pd
data0 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data0.txt")
#以逗号做分隔的数据加 sep = ',' 参数。。
#文件中有中文的时候 ,要改成UTF-8保存后再读进来
data1 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data1.txt",
sep = ',')
#读取没有表头的数据
data2 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data2.txt",
sep = ' ',header = None)
#读取没有表头的数据 ,表头换个名
data2 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data2.txt",
sep = ' ',header = None,prefix = "XX")
data3 = pd.read_csv(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data3.csv")
data4 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\comment$.txt"
,comment = '$')
data4 = pd.read_excel(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data4.xls")
#data4有10000行,太多了,用head()方法看前5行数据
data4.head()
data5 = pd.read_excel(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data5.xlsx")
#Python常用的数值函数—内建函数:
abs(-4) #取绝对值
divmod(10,4) #商和余数
pow(2,3) # 乘方,相当于 2 ** 3
round(4.51) #四舍五入,大于0.5才会入
#math包里的函数
from math import *
pi
e
ceil(4.1) #向上取整
floor(4.999) # 向下取整
modf(5.888) #把小数和整数分割
fabs(4)
exp(2) #e的2次方
log(7.38905609893065)
log2(4)
log10(100)
sqrt(100)
pow(2,3)
fmod(10,3)
factorial(5)
#认识字符串
#字符串的创建;
s1 = "hello "
s2 = "world"
s1 + s2 # 字符串拼接
s1*8 # 字符串重复
s1[0:3] #子字符串的获
\?0\d{2}\
?[- ]?\d{8}|0\d{2}[- ]?\d{8}
#正则表达式
import re
re.findall("a.c","abcaccafcagc")
# -*- coding: utf-8 -*-
"""
Created on Sat Apr 1 11:22:45 2017
@author: Administrator
"""
#python 如何链接数据库
import MySQLdb
conn = MySQLdb.connect(db='testdb',
host='localhost',
user='root',
passwd='123456')
cur = conn.cursor()
cur.execute('select * from stu;')
mydata = cur.fetchall()
for i in mydata:
print(i[1])
#Python的字符串方法
s1 = "hello world"
S1 = s1.capitalize()
ST = s1.title()
s1.count('l')
s1.endswith("ld")
s1.startswith("hell")
s1.index('or')
s1.find('or')
'aa123aa'.isalnum()
'aa'.isalpha()
'11'.isnumeric()
"aa".upper()
"Aa".lower()
"aa".islower()
"AA".isupper()
"AaBBBBbbbb".swapcase()
s1.replace("world","小明")
"this is a string".split(" ")
",".join(['this','is','a','string'])
爬虫图片python


import requests from bs4 import BeautifulSoup urls=[] for i in list(range(1,11)): urls.append('http://www.nipic.com/photo/lvyou/guonei/index.html?page=%s'%i) pics_urls=[] for url in urls: content=requests.get(url).text soup=BeautifulSoup(content,'html.parser') pics_urls.extend(soup.find_all('a',attrs={'class':'relative block works-detail hover-none works-img-box'})) pic=[] name=[] for pics in pics_urls: if(pics.find('img')['src'] !=" "): pic.append(pics.find('img')['src']) name.append(pics.find('img')['alt']) print(len(pic)) for i in list(range(0,len(pic))): print('Downloading:'+pic[i]) Pic=requests.get(pic[i]) fp=open('Pic\\'+name[i]+str(i)+'.jpg','wb') fp.write(Pic.content) fp.close()
# -*- coding: utf-8 -*- """ Created on Sat Apr 1 11:22:45 2017 @author: Administrator """ #python 如何链接数据库 import MySQLdb conn = MySQLdb.connect(db='testdb', host='localhost', user='root', passwd='123456') cur = conn.cursor() cur.execute('select * from stu;') mydata = cur.fetchall() for i in mydata: print(i[1]) #Python的字符串方法 s1 = "hello world" S1 = s1.capitalize() ST = s1.title() s1.count('l') s1.endswith("ld") s1.startswith("hell") s1.index('or') s1.find('or') 'aa123aa'.isalnum() 'aa'.isalpha() '11'.isnumeric() "aa".upper() "Aa".lower() "aa".islower() "AA".isupper() "AaBBBBbbbb".swapcase() s1.replace("world","小明") "this is a string".split(" ") ",".join(['this','is','a','string']) #冒泡排序 def bubble_sort(l): for j in range(len(l)-1): for i in range(len(l)-1-j): if(l[i] > l[i+1]): l[i],l[i+1] = l[i+1],l[i] print("内层循环第",i,"次",l) return l l = [1,3,6,5,4,2,10,8,9,100,20,7] bubble_sort(l) #快速排序 l = [1,3,6,5,4,2,10,8,9,100,20,7] def quick_sort(l): if(len(l) <= 1): return l bl = [] sl = [] for i in range(len(l)-1): if(l[0] >= l[i+1]): sl.append(l[i+1]) else: bl.append(l[i+1]) bl = quick_sort(bl) sl = quick_sort(sl) return sl+l[0:1]+bl quick_sort(l)
2017年4月5日
# -*- coding: utf-8 -*- """ Created on Wed Mar 29 15:14:09 2017 @author: Administrator """ import urllib.request import os # #'http://jandan.net/ooxx/' def url_open(url): url = 'http://jandan.net/ooxx/' print("url_open(url) start") print(url) req = urllib.request.Request(url) key = 'User-Agent' value = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' #加上头信息,伪装成人在点击网页 req.add_header(key,value) response = urllib.request.urlopen(req) html = response.read() print(html) print("url_open(url) end") return html #'http://jandan.net/ooxx/' def get_page(url): print('get_page()') html = url_open(url).decode('utf-8') a = html.find("current-comment-page") + 23 b = html.find(']',a) print(html[a:b]) return html[a:b] def find_imgs(url): print("find_imgs()") html = url_open(url).decode('utf-8') img_addrs = [] a = html.find('img src=') while a != -1: b = html.find('.jpg',a, a+255) if b != -1: img = "http:" + html[a+9:b+4] img_addrs.append(img) else: b = a + 9 a = html.find('img src=',b) return img_addrs def save_imgs(folder,img_addrs): print("save_imgs() start") for each in img_addrs: print(each) filename = each.split('/')[-1] with open(filename,'wb') as f: img = url_open(each) f.write(img) f.close() print("save_imgs() end") def download_mm(folder = 'OOXX2',pages=3): print('download_mm()') os.mkdir(folder) os.chdir(folder) url = 'http://jandan.net/ooxx/' page_num = int(get_page(url)) for i in range(pages): page_num -= 1 page_url = url + 'page-' + str(page_num) + '#comments' img_addrs = find_imgs(page_url) save_imgs(folder,img_addrs) if __name__ == '__main__': download_mm()
# -*- coding: utf-8 -*- """ Created on Wed Apr 5 10:10:18 2017 @author: Administrator """ import requests url = 'https://www.douban.com/' response = requests.get(url) text = response.text #https://www.baidu.com/s?wd=Python&rsv_spt=1&rsv_iqid=0xa3780ea500000989&issp=1&f=3&rsv_bp=0&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=0&rsv_sug3=2&rsv_n=2&rsv_sug1=1&rsv_sug7=100&prefixsug=Python&rsp=0&inputT=19929&rsv_sug4=19929&rsv_sug=2 import requests payload = {'wd':'Python', 'rn':10} url = 'https://www.baidu.com/s' response = requests.get(url, params = payload) print(response.text) print(response.url) #urllib from urllib.request import urlopen html = urlopen("http://pythonscraping.com/pages/page1.html") print(html.read()) #BeautifulSoup from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("http://www.pythonscraping.com/pages/page1.html") bsObj = BeautifulSoup(html.read()) #再端一碗BeautifulSoup from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html") bsObj = BeautifulSoup(html) print(bsObj.div.span) #这个只能获取一个。 #我们可以用 findAll 函数抽取只包含在 标签里的文字, #这样就会得到一个人物名称的 Python 列表 nameList = bsObj.findAll("span", {"class":"green"}) #span.green for name in nameList: print(name.get_text()) help(bsObj.find_all) #BeautifulSoup的find()和findAll() nameList = bsObj.findAll(text="the prince") nameList = bsObj.find(text="the prince") print(len(nameList)) #还有一个关键词参数 keyword,可以让你选择那些具有指定属性的标签 allText = bsObj.findAll(id="text") print(allText[0].get_text()) ##处理子标签和其他后代标签 from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("http://www.pythonscraping.com/pages/page3.html") bsObj = BeautifulSoup(html) for child in bsObj.find("table",{"id":"giftList"}).children: print(child) #正则表达式和BeautifulSoup from urllib.request import urlopen from bs4 import BeautifulSoup import re html = urlopen("http://www.pythonscraping.com/pages/page3.html") bsObj = BeautifulSoup(html,'html.parser') images = bsObj.findAll("img", {"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")}) for image in images: print(image["src"]) #一段获取维基百科网站的任何页面并提取页面链接的 Python 代码 from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon") bsObj = BeautifulSoup(html) for link in bsObj.findAll("a"): if 'href' in link.attrs: print(link.attrs['href']) #print(link['href']) #我们可以利用这些规则稍微调整一下代码来获取词条链接: from urllib.request import urlopen from bs4 import BeautifulSoup import re html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon") bsObj = BeautifulSoup(html) #(?!:)我们排除:号 for link in bsObj.find("div", {"id":"bodyContent"}).\ findAll("a",href=re.compile("^(/wiki/)((?!:).)*$")): if 'href' in link.attrs: print(link.attrs['href']) #当然,写程序来找出这个静态的维基百科词条里所有的词条链接很有趣,不过没什么实际 #用处。我们需要让这段程序更像下面的形式。 #• 一个函数 getLinks,可以用维基百科词条 /wiki/< 词条名称 > 形式的 URL 链接作为参数, # 然后以同样的形式返回一个列表,里面包含所有的词条 URL 链接。 #• 一个主函数, 以某个起始词条为参数调用 getLinks,再从返回的 URL 列表里随机选择 # 一个词条链接,再调用 getLinks,直到我们主动停止,或者在新的页面上没有词条链接 # 了,程序才停止运行。 from urllib.request import urlopen from bs4 import BeautifulSoup import datetime import random import re random.seed(datetime.datetime.now()) def getLinks(articleUrl): html = urlopen("http://en.wikipedia.org"+articleUrl) bsObj = BeautifulSoup(html) return bsObj.find("div", {"id":"bodyContent"}).findAll("a",\ href=re.compile("^(/wiki/)((?!:).)*$")) links = getLinks("/wiki/Kevin_Bacon") while len(links) > 0: newArticle = links[random.randint(0, len(links)-1)].attrs["href"] print(newArticle) links = getLinks(newArticle) import requests from bs4 import BeautifulSoup urls = [] for i in list(range(1,3)): urls.append('http://www.nipic.com/photo/lvyou/guonei/index.html?page=%s' %i) pics_urls =[] for url in urls: content = requests.get(url).text soup = BeautifulSoup(content, 'html.parser') pics_urls.extend(soup.find_all('a', attrs={'class':'relative block works-detail hover-none works-img-box'})) # 抓取图片链接和图片名称 pic = [] name = [] for pics in pics_urls: if(pics.find('img')['src'] != ""): pic.append(pics.find('img')['src']) name.append(pics.find('img')['alt']) import requests from bs4 import BeautifulSoup urls = [] for i in list(range(1,11)): urls.append('http://www.nipic.com/photo/lvyou/guonei/index.html?page=%s' %i) pics_urls =[] for url in urls: content = requests.get(url).text # 解析网站 soup = BeautifulSoup(content, 'html.parser') # 抓取特征 pics_urls.extend(soup.find_all('a', attrs={'class':'relative block works-detail hover-none works-img-box'})) # 抓取图片链接和图片名称 pic = [] name = [] for pics in pics_urls: if(pics.find('img')['src'] != ""): pic.append(pics.find('img')['src']) name.append(pics.find('img')['alt']) # 下载图片 for i in list(range(0,len(pic))): #开始遍历pic_url中的每个元素 print('Downloding: ' + pic[i]) Pic = requests.get(pic[i]) fp = open('Pic11\\' + name[i] + str(i) + '.jpg','wb') #保存文件 fp.write(Pic.content) #将文件写入到指定的目录文件夹下 fp.close() #python修改目录 import os #获取当前工作目录 os.getcwd() #更改当前工作目录 os.chdir(r'D:\mywork\python') os.getcwd() # 导入所需的开发模块 import requests import re # 创建循环链接 urls = [] #到network的JS里找链接 #https://detail.tmall.com/item.htm?spm=a230r.1.14.4.B5SLXi&id=530894663917&ns=1&abbucket=20 #https://rate.tmall.com/list_detail_rate.htm?itemId=530894663917&spuId=569378605&sellerId=2259491815&order=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=19 for i in list(range(1,3)): urls.append('https://rate.tmall.com/list_detail_rate.htm?itemId=530894663917&spuId=569378605&sellerId=2259491815&order=3¤tPage=%s&append=0&content=1&tagId=&posi=&picture=&ua=19' %i) # 构建字段容器 nickname = [] ratedate = [] color = [] #size = [] ratecontent = [] # 循环抓取数据 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'} for url in urls: url = 'https://rate.tmall.com/list_detail_rate.htm?itemId=530894663917&spuId=569378605&sellerId=2259491815&order=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=19' content = requests.get(url, headers = headers).text nickname.extend(re.findall('"displayUserNick":"(.*?)"',content)) color.extend(re.findall(re.compile('颜色分类:(.*?)"'),content)) # size.extend(re.findall(re.compile('尺码:(.*?);'),content)) ratecontent.extend(re.findall(re.compile('"rateContent":"(.*?)","rateDate"'),content)) ratedate.extend(re.findall(re.compile('"rateDate":"(.*?)","reply"'),content)) # 写入数据 file = open('南极人天猫评价2.csv','w') for i in list(range(0,len(nickname))): # file.write(','.join((nickname[i],ratedate[i],color[i],size[i],ratecontent[i]))+'\n') file.write(','.join((nickname[i],ratedate[i],color[i],ratecontent[i]))+'\n') file.close()
# -*- coding: utf-8 -*- """ Created on Thu Mar 30 09:30:25 2017 @author: Administrator """ #第一天 a = 5 b = 4 #用两个新变量交换值 a_backup = a b_backup = b a = b_backup b = a_backup #用一个新变量交换值 a_backup = a a = b b = a_backup #不用新变量交换值 a = a + b b = a-b a = a-b #字符串 s1 = '我是字符串' s2 ="我也是字符串" s3 = ''' 我也 是 字 符串 ''' #为啥要搞这么多种引号 " i'm 21 " ''' i'm "abc" 21 ''' #还可以加\ 'i\'m 21' #数值常量 1 #整型 1.0 #浮点型 complex(1,2) #复数 a_234234 = '我是变量' #1_aaaa = 1 # 数字在前面,这个会报错 #变量大小写敏感,a和A是两个不一样的变量 a = 1 A = 2 #变量名不可以是Python内置关键字,如min、max、range等; #类型转换 num = 1234 s_num = str(num) #int('a') int('123') float(num) int(1.234) #警惕,这个会损失精度 str(complex(1,3)) #算术运算符: 3 + 5.6 #内部会先把整数转换成小数再相加 7 -1 3*3.14 5/3 11//4 11%4 2 ** 3 #关系运算符 a = 7 b = 6 a > b a < b a <= b a >= b a == b a != b #布尔算符 True False #逻辑运算符: True and True True and False True or False not True 1 and 3 #挑那个大的 1 and 0 #0 #list 列表 l = [1,"aaa"] #c(1,2,3) 在这里叫列表,可以放不同的类型 l2 = [1,2,3,4,5,100,80,60,1,1,2] l2[0] l2[0:3] l2[4] len(l2) #len返回数组的长度 l2[len(l2)-1] #取出最后一个元素 l2[-1] #可以省略len(l2),写成这样 l2[0] = 100 #list 是可变的 L2 = list(range(1,101,2)) l2[::-1] #倒序取里边的元素 l2[-4:] #取最后四个元素 是l2[len(Mylist)-4:len(Mylist)]的简写 l2[:] #取出全部的元素 #[:]取全部值跟直接l2的区别 a = l2 a[0] = 100 b = l2[:] b[1] = 1000 #列表方法 l2.append(1111) #增加一个元素 l2.insert(2,22222) #在第二个位置插入22222 l3 = [9,8,7] l2.extend(l3) #每次可以在列表的末尾增加多个元素 last_one = l2.pop() l2.remove(3) #删除某一个元素 l2.clear() #全部删除 l2.sort() #排序 l2.reverse() l2.index(100) l2.count(1) l3 = l2.copy() #值不会跟着l2变化,和[:]一样 l2[0] = 1000000 height = [172,165,188,170,168,177,174] weight = [66.2,60,75.3,80,55,65,67.8] #height/weight #报错,不能做向量化运算 要做的话需要numpy模块 import numpy as np Height = np.array(height) Weight = np.array(weight) BIM = Weight/(Height/100)**2 #tuple 元组 t1 = (1,2,3,1,1,1) t2 = 1, #当创建的元组只有一个元素时,必须在元素后面加上逗号; t3 = t1+t2 #可通过+完成多个元组之间的连接 t1[0] t1[-1] t1[0] = 100 #会报错,元组不可变 T2 = tuple(range(1,6)) #用函数创建元组。。 T3 = ('My','name','is','Sim') t1.count(1) t1[(t1.index(1)+1):].index(1) + (t1.index(1)+1) #返回第二个1所在的位置 t2l = list(t1) #元组变成list,便于增,删,改 #dict 字典 d1 = {"key1":[1,2,3,4],"key2":2} #如果键相同,会被覆盖 d1 = {"key1":1,"key1":2} d1['key1'] #用键获取值 d1.keys() #取出全部的键 d1.values() #取出全部的值 #字典并不是序列,其元素并不是有序排放的,位置并不重要。 #不能用下标去索引 #d1[1] 报错 dict1 = {'name':'Sim'} dict2 = {'name':'Sim','gender':'Male','age':27,'address':'Jiangsu'} dict3 = {'name':'Bob','score':[67,90,72]} dict4 = {'name':['Sim','BaiSheng'],'score':[84,87]} dict5 = {'name':{'fstname':'Liu','lstname':'Sim'},'job':['teacher','data miner']} dict2['address'] dict4['name'][1] dict5['name']['fstname'] #字典虽不是一个序列,但却是一个非常灵活的数据结构,可以进行增、删、改和查的操作! del dict2['name'] score = dict3.pop('score') #clear只是把dict2里面的值删除。还能有个{}剩下 而del删除,变量名都可以删除 dict2.clear() del dict1 #增加一个值,通过给新键赋值: dict1['height'] = 167; #把dict3的内容copy到dict2里面,重复的键值会排重用的是dict3值! dict2.update(dict3) #通过列表方法增加列表类型的值 dict3['score'].append(85) #单个 dict3['score'].extend([67,89]) #多个 #改 dict1['name'] = 'Snake' dict3['score'][0] = 77 dict4['name'] = ['Snake','Peter'] #字典方法 newdict = dict1.copy() dict1['asdfadsf'] #会报错 dict1.get('name') dict1.get('asdf') #不会报错 dict1.setdefault("0") #items() 列表的形式返回可遍历的(键, 值) 元组数组 for a in dict1.items(): print(a) dict1.keys() dict1.values() #把键值成对的POP出来,返回的是元组类型 dict1.popitem() #字典与列表的比较 #当数据集非常大的时候,通过字典的方式查找数据会比列表快很多! l1 = ['Sim','Male',27,'Jiangsu'] print("%s's age is %d!" %(l1[0],l1[2])) print("%s's age is %d!" %(l1[l1.index('Sim')],l1[l1.index(27)])) #用dict()方式创建字典 dict1 = dict(name = 'Sim', gender = 'M', age = 27, address = 'JiangSu') print("%s's age is %d!" %(dict1['name'],dict1['age'])) #print 是一个输出函数 print(dict1) #print("%s is %d" %("Sim",27)) print("%s is %d" %(dict2['name'],dict2['age'])) dict5['name']['lstname'] = 'Snake' # 控制流和自定义函数 #if分支语句 if True: print('true') #保存输入数据 a_num = input("please input a value:") #单个分支 if int(a_num) < 100: print("less than 100") #两个分支 if int(a_num) < 100: print("less than 100") else: print("more than 100") #多个分支 a_num = input("please input a score:") if int(a_num) > 90: print("好") elif(int(a_num) > 80): print("良") elif(int(a_num) > 60): print("及格") else: print("SB") #循环 i = 0 sum_i = 0 while(i<100): i = i + 1 # i+=1 sum_i = sum_i + i # sum_i += i print("第%d次循环, sum_i = %d" %(i,sum_i)) #循环 #有一个初始值为5,公差为3的等差数列,计算前100项的和 i = 0 sum_i = 0 a = 5 while(i<100): i = i + 1 #通项 sum_i = sum_i + a print("第%d次循环, a = %d sum = %d" %(i,a,sum_i)) a = a + 3 #100以内的偶数,奇数全部相加, i = 0 sum_au = 0 sum_ji = 0 while(i<100): i = i + 1 # i+=1 if(i % 2 == 0): sum_au = sum_au + i else: sum_ji = sum_ji + i print(sum_au,sum_ji)
# -*- coding: utf-8 -*- """ Created on Fri Mar 31 10:24:20 2017 @author: Administrator """ # #找出,100以内所有的素数。。 #素数:只能除尽1和它本身的数、 #先判断一个数是不是素数 i = 2 l = list() while(i < 100): j = 2 is_sushu = True while(j < i): if(i%j == 0): is_sushu = False j = j + 1 if(is_sushu): l.append(i) i = i + 1 print(l) #for循环的语法 for i in range(5,10): print(i) list1 = [0,11,22,33,44,55,66,77,88,99] for i in list1: print(i) string1 = "helloworld" for i in string1: print(i) #建议使用的方式,即可以得到索引,也可以有值 list1 = [0,11,22,33,44,55,66,77,88,99] for i in range(len(list1)): print(i,list1[i]) #for循环一个字典 dict1 = {'name':'jack','gender':'man','age':30} dict1.items() for key,value in dict1.items(): print(key,"----->",value) #这次用for循环 #找出,100以内所有的素数。。 #素数:只能除尽1和它本身的数、 #先判断一个数是不是素数 i = 18 is_sushu = True for j in range(2,i): if i % j == 0: is_sushu = False #然后判断2到100所有的数是不是素数 l = list() for i in range(2,100): is_sushu = True for j in range(2,i): if i % j == 0: is_sushu = False if(is_sushu): l.append(i) #自定义函数 def f(): print("i am a function") #参数(必选参数)和返回值 def me_add_me(a): return a + a #参数(可选参数),可选参数一定要在必选参数后面 def a_add_b(a,b = 1): return a + b #定义一个函数,判断一个数是不是素数 def is_sushu(num): is_sushu = True for i in range(2,num): if(num % i == 0): is_sushu = False return is_sushu #找100以内的素数 for i in range(2,100): if(is_sushu(i)): print(i) #一个*号,可变参数,调用时传多个参数, #它会变成元组传进去,可以用for循环遍历 def f(*a): for i in a: print(i) f(1,2,3,4,5) #两个*号,关键词参数 def f(**a): for k,v in a.items(): print(k,"---------->>",v) #三个循环练习 # 题目1,输出前100个这样的数 ## 规律为数列1,1,2,3,5,8,13,21.... l = [1,1] for i in range(2,100): l.append( l[-1] + l[-2]) #题目2:求1+2!+3!+...+20!的和 #先搞出来一个数的阶乘 def jie_cheng(a): jie_c = 1 for i in range(a): jie_c = jie_c * (i + 1) return jie_c #现在计算前20项的和 sum_jiec = 0 for i in range(20): sum_jiec = sum_jiec + jie_cheng(i+1) print(sum_jiec) #题目3:有一分数序列: #2/1,3/2,5/3,8/5,13/8,21/13... #求出这个数列的前20项之和。 #1.程序分析:请抓住分子与分母的变化规律。 fenzi = [2,3] fenmu = [1,2] sum = 2/1 + 3/2 for i in range(2,20): fenzi.append(fenzi[-1] + fenzi[-2]) fenmu.append(fenmu[-1] + fenmu[-2]) sum = sum + fenzi[i]/fenmu[i] #sum = sum + fenzi[-1]/fenmu[-1] #读取数据 import pandas as pd data0 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data0.txt") #以逗号做分隔的数据加 sep = ',' 参数。。 #文件中有中文的时候 ,要改成UTF-8保存后再读进来 data1 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data1.txt", sep = ',') #读取没有表头的数据 data2 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data2.txt", sep = ' ',header = None) #读取没有表头的数据 ,表头换个名 data2 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data2.txt", sep = ' ',header = None,prefix = "XX") data3 = pd.read_csv(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data3.csv") data4 = pd.read_table(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\comment$.txt" ,comment = '$') data4 = pd.read_excel(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data4.xls") #data4有10000行,太多了,用head()方法看前5行数据 data4.head() data5 = pd.read_excel(r"E:\BaiduNetdiskDownload\上课资料\CH12-Python爬虫\CH12-Python爬虫\Python\CH5-数据读取\data5.xlsx") #Python常用的数值函数—内建函数: abs(-4) #取绝对值 divmod(10,4) #商和余数 pow(2,3) # 乘方,相当于 2 ** 3 round(4.51) #四舍五入,大于0.5才会入 #math包里的函数 from math import * pi e ceil(4.1) #向上取整 floor(4.999) # 向下取整 modf(5.888) #把小数和整数分割 fabs(4) exp(2) #e的2次方 log(7.38905609893065) log2(4) log10(100) sqrt(100) pow(2,3) fmod(10,3) factorial(5) #认识字符串 #字符串的创建; s1 = "hello " s2 = "world" s1 + s2 # 字符串拼接 s1*8 # 字符串重复 s1[0:3] #子字符串的获 \?0\d{2}\ ?[- ]?\d{8}|0\d{2}[- ]?\d{8} #正则表达式 import re re.findall("a.c","abcaccafcagc")
2017年4月6日
# -*- coding: utf-8 -*- """ Created on Thu Apr 6 13:01:18 2017 @author: Administrator """ ls = ['Python','User','I','Am','OK','Very','Easy'] #1、取出第3,第5,和最后一个元素 ls[2] ls[4] ls[len(ls)-1] #2、往ls中添加两个元素:'Will','Success'。其中'Will'插在列表ls的'Am'元素后面,'Success'插在最后 ls.insert(4,"Will") ls.append("Success") #3统计每个字母的频次 t = ('a','a','b','c','b','c','d','a','e','d','d','c','a','d','a') count_t = {} for i in t: if i in count_t: count_t[i] += 1 else: count_t[i]=1 from collections import defaultdict count_t = defaultdict(int) for x in t: count_t[x] += 1 #4、创建一个字典,包含的信息如下: #姓名为Joy,年龄为30,收入为30000,孩子姓名为Tom和Lily #往字典里再增加一个元素:妻子的姓名为Will dic={"姓名":"joy","年龄":30,"收入":30000,"孩子":["tom","lily"]} dic["妻子"]="will" s = 'Python for Data Analysis is A Book Name,If You Have Any Question Plz Call Me! My Email Is [email protected].' # (这是第5题 和 第6题的数据) #提示:5,6题需要使用正则表达式 #5、提取出字符串中的邮箱信息 import re a=re.findall("@(.*?).com",s) a b=re.findall("\\w*[iI]\\w*",s) b #7、计算 1+1/2!+1/3!+1/4!+...1/20!=? s=0 for i in range (1,21): a=1 for j in range(1,i+1): a=a*j s=s+(1/a) print(a) s #8、写一个冒泡排序的函数 def buble_sort(l): for j in range(len(l)-1): for i in range(len(l)-1-j): if(l[i] > l[i+1]): l[i],l[i+1] = l[i+1],l[i] return l #一个简单例子---中国图书网 # 爬虫 # 正则表达式爬虫 import requests import re pubtimeall = [] titleall = [] authorall = [] pubhousesall = [] now_priceall = [] for i in range(1,3): print("~~~~~~~~~~",titleall) url = 'http://www.bookschina.com/book_find2/default.aspx?pageIndex=%s&stp=python&dmethod=all&sType=0'%i content = requests.get(url).text titleall.extend(re.findall('[jg][pi][gf]" title="(.*?)"',content)) authorall.extend(re.findall('作者:.*?;sbook=(.*?)">.*?出版社:',content)) pubhousesall.extend(re.findall('出版社:.*?">(.*?)
出版时间:',content)) pubtimeall.extend(re.findall('
出版时间:(.*?)
ISBN:',content)) now_priceall.extend(re.findall('现价:¥(.*?) 您节省:',content)) file = open('books12.csv','w') for i in range(0,len(titleall)): file.write(','.join((titleall[i],authorall[i],pubhousesall[i],pubtimeall[i],now_priceall[i]))+'\n') file.close() 插入排序 (模型是插入扑克) l = [5,3,4,2,1] def insert_sort(l): for j in range(1,len(l)): key = l[j] i = j-1 print("i = ",i,l[i],key,i >= 0 and l[i] > key) while i >= 0 and l[i] > key: l[i+1] = l[i] i = i - 1 print(l) l[i+1] = key print(l) insert_sort(l) l = [5,3,4,2,1] def insert_sort(l): for j in range(1,len(l)): i = j-1 while i >= 0 and l[i] > l[i+1] : l[i],l[i+1] = l[i+1],l[i] i = i - 1 print(l) print("~~~~~~~~~~~~~~~~",l) insert_sort(l) i=1 j=0 def insert_sort(ls): for i in range(len(ls)): for j in range(i,0,-1): if ls[j-1]>=ls[j]: ls[j],ls[j-1]=ls[j-1],ls[j] ls=[2,3,39,4,5,1,8,2] insert_sort(ls)
2017年4月7日
1.
(1)TEXT(value,format_text)根据指定格式将数字转成文本
(2)TODAY() 返回日期格式的当前日期
2.
(1)HYPERLINK()创建一个快捷方式或链接,以便打开一个存储在硬盘,网络服务器或Internet上的文档
(2)MATCH()返回符合特定值,特定顺序的项在数组中的相对位置
3.

(1)MOD() 返回两数相除的余数
(2)MID(text,start_num,num_chars)从文本字符串中指定的起始位置起返回指定长度的字符
4.

(1)EDATE(start_date,months) 返回一串日期,指示起始之前之后的月数
5.


6.


7.
(1)SEARCH(find_text,within_text,[start_num]) :返回一个指定字符或文本字符串在字符串第一次出现的位置,从左到右查找(忽略大小写)
(2)SMALL(array,k):返回数组中第k个最小值
(3)IFERROR(value,value_if_error):如果表达式是一个错误,则返回value_if_error,否则返回表达式自身的值
(4)INDEX(arrary,row_num,[column_num])、INDEX(reference,row_num,[column_num],[area_num]):在给定的单元格区域中,返回特定行列交叉单元格的值或引用
(5)ISNUMBER(value):检测一个值是否是数值,返回TRUE或FALSE
2017年4月8日
1.
(1)MATCH(look_value,look_array,[match_type]):返回符合特定值特定顺序的项在数值中相对位置
(2)VLOOKUP(lookup_value,table_array,col_index_num,[range_lookup]):搜索表区域首列满足条件的元素,确定待检索单元格在区域中的行序号,再进一步返回选定单元格的值。默认是以升序排序的。
2017年4月9日
1.Dir 函数
语法:Dir[(pathname[, attributes])]
两个参数都是可选的,attributes表示文件属性。
功能:返回一个文件名、目录名或文件夹名称,它必须与指定的模式或文件属性、或磁盘卷标相匹配。
说明:在第一次调用 Dir 函数时,必须指定 pathname,否则会产生错误。如果也指定了文件属性,那么就必须包括 pathname。
2.ByVal 表示该参数按值传递。
ByRef 表示该参数按地址传递。ByRef 是 Visual Basic 的缺省选项。
3.COUNT(value1,[value2]...):计算区域中包含数字的单元格的个数
COUNTA(value1,[value2],...):计算区域中非空单元格的个数
COUNTBLANK(range):计算某个区域中空单元格的数目
COUNTIF(range,criteria):计算某个区域中满足给定单元格数目
COUNTIFS(criteria_range1,criteria1,...):统计一组给定条件所指定的单元格数
2017年4月11日
1.
(1)自定义单元格格式";;;",会使单元格显示为空白,但编辑栏仍会显示实际内容
(2)IFERROR(value,value_if_error) :如果表达式是一个错误,则返回value_if_error,否则返回表达式自身的值
(3)DATEDIF()返回两个日期的相差值
2017年4月12日
1.
REPLACE(old_text,start_num,num_chars,new_text):将一个字符串中的部分字符用另一个字符串替换
REPLACEB(old_text,start_num,num_chars,new_text):用其他文本字符串替换某文本字符串的一部分
INDIRECT(ref_text,[a1]):返回文本字符串所指定的引用
CHOOSE(index_num,value1,[value2]):根据给定的索引值,从参数中选出响应的值或操作
SUBSTITUTE(text,old_text,new_text,[instance_num]):将字符串的部分字符串以新字符串替换
2017年4月13日
1.
SUMPRODUCT(array1,[array2],[array3],...):返回响应的数组或区域乘积的和
ISNUMBER(value):检测一个值是否是数值,返回TRUE或FALSE
T(value):检测给定值是否为文本,如果是文本按原样返回,如果不是,则返回双引号(空文本)


RANDBETWEEN(bottom,top):返回一个介于指定的数字之间的随机数
ROUND(number,num_digits):按指定的位数对数值进行四舍五入