參考:http://scikit-learn.org/stable/modules/label_propagation.html
The semi-supervised estimators insklearn.semi_supervised are able to make use of this additional unlabeled data to better capture the shape of the underlying data distribution and generalize better to new samples. These algorithms can perform well when we have a very small amount of labeled points and a large amount of unlabeled points.
Unlabeled entries in y:It is important to assign an identifier to unlabeled points along with the labeled data when training the model with the fit method. The identifier that this implementation uses is the integer value .
标签传播算法(Label propagation):
特点:
1)分类和回归问题均适用
2)能够使用kernel methods将数据映射到其它维度空间。
scikit-learn提供了两个标签传播模型:LabelPropagation and LabelSpreading. Both work by constructing a similarity graph over all items in the input dataset.
两者差别在于:对原始label分布的图模型和夹紧效果(clamping effect)的similarity matrix的改动程度。所谓的夹紧效果,就是同意两个模型change true ground labeled data的weight。
LabelPropagation适用“硬夹紧(hard clamping),即alpha=1。
假设令alpha=0.8,这意味着我们将保留原有的80%的标签分布。但该算法的信任的分布度也会有20%的影响。
LabelPropagation使用从没有不论什么改动的原始数据中构造的similarity matrix。而LabelSpreading最小化一个带有正规项的loss function,从而对noise鲁棒。
标签传播模型有两个内置的kernel methods,不同的kernel对算法的可扩展性和性能都有影响:

The RBF kernel will produce a fully connected graph which is represented in memory by a dense matrix. This matrix may be very large and combined with the cost of performing a full matrix multiplication calculation for each iteration of the algorithm can lead to prohibitively long running times. On the other hand, the KNN kernel will produce a much more memory-friendly sparse matrix which can drastically reduce running times.
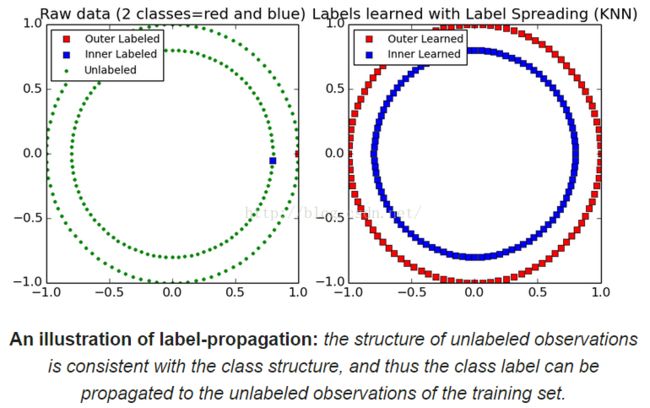
Examples
- Decision boundary of label propagation versus SVM on the Iris dataset
- Label Propagation learning a complex structure
- Label Propagation digits active learning