OpenCV(Open Source Computer Vision Library)
OpenCV 是一个开源的计算机视觉库,它提供了很多函数,这些函数非常高效地实现了计算机视觉算法(最基本的滤波到高级的物体检测皆有涵盖)。
OpenCV 使用 C/C++ 开发,同时也提供了 Python、Java、MATLAB 等其他语言的接口。
OpenCV 是跨平台的,可以在 Windows、Linux、Mac OS、Android、iOS 等操作系统上运行。
OpenCV 的应用领域非常广泛,包括图像拼接、图像降噪、产品质检、人机交互、人脸识别、动作识别、动作跟踪、无人驾驶等。
OpenCV 还提供了机器学习模块,你可以使用正态贝叶斯、K最近邻、支持向量机、决策树、随机森林、人工神经网络等机器学习算法。
Blog:https://blog.csdn.net/qq_40962368/article/category/7688903
(一)读取、复制、显示、保存
1)读取图像
函数:cv2.imread
参数:两个参数
第一个参数:图片地址
第二个参数:模式参数
0:读入的为灰度图像(即使读入的为彩色图像也将转化为灰度图像) 1:读入的为彩色图像(默认)
导入包
import cv2 import numpy as np
图像就是一个数组,所有对图像的处理就是对数字的处理
img = cv2.imread('rose.jpg') # img = cv2.imread('rose1.jpg', 1)
print(img)
print(np.shape(img)) # (972, 1024, 3)
2)显示图像
将读取的图像显示出来,原始图片较大,显示时将图片放下点
# 读取图片 img = cv2.imread('rose1.jpg') # 创建一个窗口 cv2.namedWindow('Image') # 在窗口中显示图像 cv2.imshow('Image', img) # 设置窗口始终保持 cv2.waitKey(0)
最后释放窗口
cv2.destroyAllWindows()
3)复制图像
函数:copy()
img_copy = img.copy()
4)保存图像
函数:cv2.imwrite()
参数:三个参数
第一个参数:保存图像的地址以及文件的名字
第二个参数:所要保存的图像数组
第三个参数:针对特定的图像格式而不同含义 - 对于JPEG,其表示的是图片的Quality,用0-100的整数表示,默认为95。当然如果把参数设置得超过100也不会出错,但100已经达到图片本身的最高质量了,cv2.IMWRITE_JPEG_QUALITY的类型为int类型,符合图像数组为整数的要求,不用再更改类型
cv2.imwrite('rose_copy.jpg', img_copy, [cv2.IMWRITE_JPEG_QUALITY, 2])
- 对于PNG,其表示的是压缩级别,cv2.IMWRITE_PNG_COMPRESSION,从0到9,压缩级别越高,图像尺寸越小,默认级别为3
cv2.imwrite("rose_test.png", img, [cv2.IMWRITE_PNG_COMPRESSION, 0]) cv2.imwrite("rose_test.png", img, [cv2.IMWRITE_PNG_COMPRESSION, 9])
cv2.imwrite('rose_copy.jpg', img_copy)
(二)图像像素的访问、通道的合并与分离
1)像素访问
对于RGB图像矩阵一共有三层,分别代表着RGB通道,矩阵中每一个数的大小代表着不同通道的亮度,范围在0~255之间。
访问图像的像素,就如同对矩阵元素的访问
print(img[0][0][0]) # 34
可以对所读取的图像矩阵的像素进行赋值
# 在图左上角形成400x400像素的白色区域
for i in range(400): for j in range(400): for k in range(3): img[i][j][k] = 255
图像特效 - 椒盐现象
# 椒盐函数,将想要的像素随机的分布在图像上 def salt(img, numbers): for x in range(numbers): i = np.random.randint(img.shape[0]) j = np.random.randint(img.shape[1]) for k in range(3): img[i][j][k] = 255 return img # 添加1000个点 img = salt(img, 1000)


2)通道分离
函数:cv2.split()
对于RGB图像,拥有RGB三原色通道,从矩阵的角度来讲,可以理解为三层矩阵,也就是三维的矩阵,每一层代表着一个通道。将图片进行通道分离可以使用OpenCV里的split函数,也可以通过numpy库对图像矩阵进行直接操作
b, g, r = cv2.split(img) cv2.namedWindow('Blue') cv2.imshow('Blue', b) cv2.waitKey(0) cv2.namedWindow('Green') cv2.imshow('Green', g) cv2.waitKey(0) cv2.namedWindow('Red') cv2.imshow('Red', r) cv2.waitKey(0)
保留单通道,将其他通道的图像矩阵的值全设置为零
img = cv2.imread('Road.jpg') b, g, r = cv2.split(img) pic = np.zeros(np.shape(img), np.uint8) pic[:, :, 0] = b cv2.namedWindow('Blue') cv2.imshow('Blue', pic) cv2.waitKey(0) pic = np.zeros(np.shape(img), np.uint8) pic[:, :, 1] = g cv2.namedWindow('Green') cv2.imshow('Green', pic) cv2.waitKey(0) pic = np.zeros(np.shape(img), np.uint8) pic[:, :, 2] = r cv2.namedWindow('Red') cv2.imshow('Red', pic) cv2.waitKey(0) cv2.destroyAllWindows()




也可以任选两个通道进行拼接
pic = np.zeros(np.shape(img), np.uint8) pic[:, :, 0] = b pic[:, :, 1] = g cv2.namedWindow('Blue-Green') cv2.imshow('Blue-Green', pic) cv2.waitKey(0) pic = np.zeros(np.shape(img), np.uint8) pic[:, :, 0] = b pic[:, :, 2] = r cv2.namedWindow('Blue-Red') cv2.imshow('Blue-Red', pic) cv2.waitKey(0) pic = np.zeros(np.shape(img), np.uint8) pic[:, :, 1] = g pic[:, :, 2] = r cv2.namedWindow('Green-Red') cv2.imshow('Green-Red', pic) cv2.waitKey(0) cv2.destroyAllWindows()

3)通道合并
将图片进行通道合并可以使用OpenCV里的megre函数,也可以通过numpy库里的dstack(深度拼接函数)实现,但需要注意这两种拼接方式是不一样的,另外,pandas中也有对矩阵的拼接操作,也可实现np.dstack()相同的效果
megre = cv2.merge([b, g, r]) # dstack = np.dstack([b, g, r])
(三)绘制简单的几何图形、显示文字
1)绘制直线和矩形
img = np.zeros([512, 512, 3]) # cv2.line()函数用来画直线
# 第一个参数可以理解为画布矩阵 # 第二个参数pt1是直线的起始位置
# 第三个参数pt2是直线的终止位置 # 第四个参数color用来控制直线的颜色
# 第五个参数thickness表示的是线条的厚度/宽度 cv2.line(img, (255, 512), (255, 0), (255, 0, 255), 9) # cv2.rectangle()函数用来画矩形
# 第一个参数为需要传入的画布矩阵 # 第二个参数pt1是矩形的左上角位置坐标
# 第三个参数pt2是矩形右下角的位置坐标 # 第四个参数color用来控制矩形的颜色
# 第五个参数thickness表示的是边框的厚度/宽度 cv2.rectangle(img, (150, 150), (350, 350), (255, 255, 0), 2) cv2.imshow('Image', img) cv2.waitKey(0) cv2.destroyAllWindows()
2)绘制圆和椭圆
# cv2.circle()函数用来画圆形
# 第二个参数指的是圆心
# 第三个参数指的是圆的半径 cv2.circle(img, (255, 255), 50, (255, 0, 255), 9) cv2.circle(img, (250, 245), 9, (255, 0, 0), 36)
# cv2.ellipse()函数用来画椭圆 # 第二个参数是椭圆的中心点
# 第三个参数axes指的是短半径和长半径 # 第四个参数指的是逆时针旋转的角度 # 第五个参数指的是逆时针开始画图的角度
# 第六个参数指的是逆时针结束画图的角度 # 四/五/六参数若加上符号,表示的反方向,即顺时针方向 cv2.ellipse(img, (255, 255), (170, 70), 20, 0, 270, (255, 255, 0), 2) cv2.imshow('Image', img) cv2.waitKey(0) cv2.destroyAllWindows()
3)绘制多边形
# cv2.polylines()函数用来画多边形
pts = np.array([[50, 190], [380, 420], [255, 50], [120, 420], [450, 190]]) # 第三个参数指是否封口,注意该参数外面必须再加一层中括号 cv2.polylines(img, [pts], True, (255, 255, 0), 15) cv2.imshow('Image', img) cv2.waitKey(0) cv2.destroyAllWindows()
4)添加文字
# 目前不能显示汉字,能显示英文字母
font = cv2.FONT_HERSHEY_SIMPLEX # 第三个参数为显示文字的起始位置
# 第五个参数表示的是文字的大小 cv2.putText(img, 'wen huai yi shi xin', (10, 255), font, 1.6, (255, 255, 0), 2) cv2.imshow('Image', img) cv2.waitKey(0) cv2.destroyAllWindows()
(四)图像的简单几何变换
几何变换不改变图像的像素值,只是在图像平面上进行像素的重新安排。
适当的几何变换可以最大程度地消除由于成像角度、透视关系乃至镜头自身原因所造成的几何失真所产生的负面影响。有利于在后续的处理和识别工作中将注意力集中于图像内容本身,更确切地说是图像中的对象,而不是该对象的角度和位置等。
几何变换常常作为图像处理应用的预处理步骤,是图像归一化的核心工作之一。
几何变换需要两部分运算:首先是空间变换所需的运算,如平移、缩放、旋转和正平行投影等,需要用它来表示输出图像与输入图像之间的(像素)映射关系;此外,还需要使用灰度差值算法,因为按照这种变换关系进行计算,输出图像的像素可能被映射到输入图像的非整数坐标上。
1)图像的平移
方法:平移前,先构造一个移动矩阵,说明在x轴方向上移动多少距离,在y轴上移动多少距离
函数:cv2.warpAffine()
参数:三个参数
第一个参数:需要进行图像变换的原始图像矩阵
第二个参数:移动矩阵
第三个参数:图像变换的大小(图像本身并不会放大或缩小,而是图像显示区域的大小)
img = cv2.imread('4.jpg') # 通过numpy构造移动矩阵H,并将其传给仿射函数cv2.warpAffine() # 在x轴方向移动多少距离,在y轴方向移动多少距离 H = np.float32([[1, 0, 50], [0, 1, 25]]) rows, cols = img.shape[:2] print(img.shape) print(rows, cols)
# 注意其中rows和cols需要反置 res = cv2.warpAffine(img, H, (cols, rows)) cv2.imshow('origin_picture', img) cv2.imshow('new_picture', res) cv2.waitKey(0)
2)图像的放大和缩小
方法:设置缩放的比例,一种办法是设置缩放因子,另一种办法是直接设置图像的大小(缩放后,图像必然会发生变化,这就涉及到图像的插值问题)
函数:cv2.resize()
参数:
interpolation参数:int类型,指定插值方法,默认为INTER_LINEAR(线性插值)
可选的插值方式: INTER_NEAREST - 最近邻插值 INTER_LINEAR - 线性插值(默认值) INTER_AREA - 区域插值(利用像素区域关系的重采样插值) INTER_CUBIC –三次样条插值(超过4×4像素邻域内的双三次插值) INTER_LANCZOS4 -Lanczos插值(超过8×8像素邻域的Lanczos插值)
在缩小图像时,推荐使用cv2.INTER_AREA
在扩大图像时,推荐使用cv2.INTER_CUBIC(效率不高,慢,不推荐使用)或cv2.INTER_LINEAR(效率较高,速度较快,推荐使用)
img = cv2.imread('4.jpg') # 一是通过设置图像缩放比例,即缩放因子,来对图像进行放大或缩小 res1 = cv2.resize(img, None, fx=2, fy=2, interpolation=cv2.INTER_LINEAR) height, width = img.shape[:2] # 二是直接设置图像的大小,不需要缩放因子 res2 = cv2.resize(img, (int(0.8*width), int(0.8*height)), interpolation=cv2.INTER_AREA) cv2.imshow('origin_picture', img) cv2.imshow('res1', res1) cv2.imshow('res2', res2) cv2.waitKey(0)
插值算法 - 最近邻插值算法:选择离它映射到的位置最近的输入像素的灰度值为插值结果
# 通过图像长和宽的比例,将原有的图像映射到所需要的图像上,这里涉及到对图像矩阵元素的操作 # need_height参数不得超过原来图像高的两倍,这是由临近插值算法本身的性质所决定的 # need_width参数则可以任意选取 def pic_interpolation(img, need_height, need_width): height, width, channels = img.shape print(height, width, channels) emptyImage = np.zeros((need_height, need_width, channels), np.uint8) sh = need_height/height sw = need_width/width for i in range(need_height): for j in range(need_width): x = round(i/sh) y = math.floor(j/sw) emptyImage[i, j] = img[x, y] return emptyImage img = cv2.imread("4.jpg") zoom = pic_interpolation(img, 220, 180) cv2.imshow("nearest neighbor", zoom) cv2.imshow("image", img) cv2.waitKey(0)
3)图像的旋转
方法:对于图像的旋转,需要先构造旋转矩阵,一般图像的旋转矩阵是在原点处进行变换的
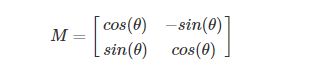
为了能够在任意位置进行旋转变换,OpenCV采用了另一种方式

函数:cv2.getRotationMarix2D( )
参数:三个参数
第一个参数:旋转中心
第二个参数:旋转角度
第三个参数:旋转后图像的缩放比例
img = cv2.imread('4.jpg') rows, cols = img.shape[:2] # 第一个参数是旋转中心,第二个参数是旋转角度,第三个参数是缩放比例 M1 = cv2.getRotationMatrix2D((cols/2, rows/2), 45, 0.5) M2 = cv2.getRotationMatrix2D((cols/2, rows/2), 45, 2) M3 = cv2.getRotationMatrix2D((cols/2, rows/2), 45, 1) res1 = cv2.warpAffine(img, M1, (cols, rows)) res2 = cv2.warpAffine(img, M2, (cols, rows)) res3 = cv2.warpAffine(img, M3, (cols, rows)) cv2.imshow('res1', res1) cv2.imshow('res2', res2) cv2.imshow('res3', res3) cv2.waitKey(0) cv2.destroyAllWindows()



4)图像的仿射
仿射变换是指在向量空间中进行一次线性变换(乘以一个矩阵)并加上一个平移(加上一个向量),变换为另一个向量空间的过程。
仿射变换(Affine Transform)描述了一种二维仿射变换的功能,它是一种二维坐标之间的线性变换,保持二维图形的“平直性”(即变换后直线还是直线,圆弧还是圆弧)和“平行性”(即保持二维图形间的相对位置关系不变,平行线还是平行线,直线上的点位置顺序不变,另特别注意向量间夹角可能会发生变化)。仿射变换可以通过一系列的原子变换的复合来实现包括:平移(Translation)、缩放(Scale)、翻转(Flip)、旋转(Rotation)和错切(Shear)。
方法:仿射变换首先需要一个M矩阵,由于仿射变换比较复杂很难找到M矩阵,OpenCV提供了根据变换前后三个点的对应关系来自动求解M,事实上,仿射变换代表的是两幅图之间的关系,通常使用2x3矩阵来表示仿射变换
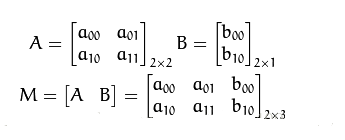
函数:cv2.getAffineTransoform(pts1, pts2)
img = cv2.imread('4.jpg') rows, cols = img.shape[:2] pts1 = np.float32([[50, 50], [200, 50], [50, 200]]) pts2 = np.float32([[10, 100], [200, 50], [100, 250]]) # 类似于构造矩阵 M = cv2.getAffineTransform(pts1, pts2) res = cv2.warpAffine(img, M, (cols, rows)) cv2.imshow('原图', img) cv2.imshow('res', res) cv2.waitKey(0) cv2.destroyAllWindows()


5)图像的透射
仿射变换(Affine Transform)与透视变换(Perspective Transform)在图像还原、图像局部变化处理方面有重要意义。通常,在2D平面中,仿射变换的应用较多,而在3D平面中,透视变换又有了自己的一席之地。两种变换原理相似,结果也类似,可针对不同的场合使用适当的变换。
基于3×3矩阵进行的变换,叫透视变换或者单应性映射。
仿射变换可以形象的表示成以下形式:一个平面内的任意平行四边形ABCD可以被仿射变换映射为另一个平行四边形A’B’C’D’。通俗的解释就是,可以将仿射变换想象成一幅图像画到一个胶版上,在胶版的角上推或拉,使其变形而得到不同类型的平行四边形。相比较仿射变换,透射变换更具有灵活性,一个透射变换可以将矩形转变成梯形。
img = cv2.imread('4.jpg') rows, cols = img.shape[:2] pts1 = np.float32([[56, 65], [238, 52], [28, 237], [239, 240]]) pts2 = np.float32([[0, 0], [200, 0], [0, 200], [200, 200]]) M = cv2.getPerspectiveTransform(pts1, pts2) res = cv2.warpPerspective(img, M, (cols, rows)) cv2.imshow('yuantu', img) cv2.imshow('res', res) cv2.waitKey(0) cv2.destroyAllWindows()


(五)图像的阈值分割
一幅图像包括目标物体、背景还有噪声,若想从多值的数字图像中直接提取出目标物体,常用的方法就是设定一个阈值T,用T将图像的数据分成两部分:大于T的像素群和小于T的像素群。这是研究灰度变换的最特殊的方法,称为图像的二值化(Binarization)。
阈值分割法的特点是:适用于目标与背景灰度有较强对比的情况,重要的是背景或物体的灰度比较单一,而且总可以得到封闭且连通区域的边界。
1)简单阈值
方法:选取一个全局阈值,然后就把整幅图像分成非黑即白的二值图像。
函数:cv2.threshold( )
参数:四个参数
第一个参数:原图像矩阵 第二个参数:进行分类的阈值 第三个参数:高于/低于阈值时重新赋的新值 第四个参数:方法选择
cv2.THRESH_BINARY(黑白二值)
cv2.THRESH_BINARY_INV(黑白二值反转)
cv2.THRESH_TRUNC(得到的图像为多像素值)
cv2.THRESH_TOZERO(当像素高于阈值时像素重新赋像素值,低于阈值时不作处理)
cv2.THRESH_TOZERO_INV(当像素低于阈值时重新赋像素值,高于阈值时不作处理)
返回:两个返回值
第一个返回值:阈值
第二个返回值:阈值处理后的图像矩阵
ret, thresh = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
2)自适应阈值
简单阈值 VS 自适应阈值
简单阈值是一种全局性的阈值,只需要设定一个阈值,整个图像都和这个阈值比较;自适应阈值可以看成一种局部性的阈值,通过设定一个区域大小,比较这个点与区域大小里面像素点的平均值(或者其他特征)的大小关系确定这个像素点的情况,这种方法理论上得到的效果更好,相当于在动态自适应的调整属于自己像素点的阈值,而不是整幅图都用一个阈值。
函数:cv2.adaptiveThreshold()
参数:六个参数
第一个参数:原始图像矩阵
第二个参数:像素值上限
第三个参数:自适应方法(adaptive method)
cv2.ADAPTIVE_THRESH_MEAN_C 邻域内均值
cv2.ADAPTIVE_THRESH_GAUSSIAN_C 邻域内像素点加权和,权重为一个高斯窗口
第四个参数:赋值方法选择(只有两种)
cv2.THRESH_BINARY (黑白二值)
cv2.THRESH_BINARY_INV (黑白二值反转)
第五个参数(Block size):设定领域大小(一个正方形的领域),对于第五个参数的窗口越来越小时,得到的图像越来越细,假设把窗口设置的足够大(不能超过图像大小),可得到的结果可能就和第二幅图像的相同
第六个参数(C):阈值等于均值或者加权值减去这个常(为0相当于阈值,就是求得领域内均值或者加权值)
img = cv2.imread('4.jpg', 0) ret, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY) th2 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 5, 2) th3 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11, 2) th4 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2) cv2.imshow('img', img) cv2.imshow('th1', th1) cv2.imshow('th2', th2) cv2.imshow('th3', th3) cv2.imshow('th4', th4) cv2.waitKey(0) cv2.destroyAllWindows()
3)Otsu's二值化
前面cv2.threshold( )函数的阈值设定为127,而在实际情况中,有的图像阈值不是127得到的图像效果更好。那么这里就需要算法去寻找一个阈值,而Otsu's就可以自动找到一个认为最好的阈值。并且Otsu's非常适合于图像灰度直方图(只有灰度图像才有)具有双峰的情况。其会在双峰之间找到一个值作为阈值,对于非双峰图像,可能并不是很好用。
那么经过Otsu's得到的那个阈值就是函数cv2.threshold()的第一个返回值。因为Otsu's方法会产生一个阈值,那么函数cv2.threshold( )的第二个参数(设定阈值)就是0,并且在cv2.threshold()的方法参数中还得加上语句cv2.THRESH_OTSU
img = cv2.imread('2.jpg', 0) # 简单滤波 ret1, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY) # Otsu's滤波 ret2, th2 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) print(ret2) cv2.imshow('img', img) cv2.imshow('th1', th1) cv2.imshow('th2', th2) # 用于解决matplotlib中显示图像的中文乱码问题 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False plt.hist(img.ravel(), 256) plt.title('灰度直方图') plt.show() cv2.waitKey(0) cv2.destroyAllWindows()
OpenCV中文路径问题
- 读取图片 - img_path图片路径包含中文
img = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), 1)
- 保存图片 - img为所要保存的图像原始数据,save_path保存图片路径包含中文,‘.jpg’为保存文件格式,在参数img后可以添加压缩参数,与cv2.imwrite()函数的参数是一致的
cv2.imencode('.jpg', img)[1].tofile(save_path)
matplotlib可视化中文乱码问题
在添加中文轴标签或标题等时,将下面两行代码放入它们之前
plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False
(六)图像平滑与滤波
平滑滤波
平滑滤波是低频增强的空间域滤波技术。滤波的本义是指信号有各种频率的成分,滤掉不想要的成分,即为滤掉常说的噪声,留下想要的成分,这即是滤波的过程,也是目的。空间域的平滑滤波一般采用简单平均法进行,就是求邻近像素点的平均亮度值。邻域的大小与平滑的效果直接相关,邻域越大平滑的效果越好,但邻域过大,平滑会使边缘信息损失得越大,从而使输出的图像变得模糊,因此需合理选择邻域的大小。
其目的有两类:一类是模糊;另一类是消除噪音。
- 抽出对象的特征作为图像识别的特征模式
- 为适应图像处理的要求,消除图像数字化时所混入的噪声
对于2D图像可以进行低通或者高通滤波操作,低通滤波(LPF)有利于去噪、模糊图像,高通滤波(HPF)有利于找到图像边界
1)2D滤波器
函数:cv2.filter2D()
import cv2 import numpy as np img = cv2.imread('./Rose.jpg', 0) kernel = np.ones((5, 5), np.float32) / 25 dst = cv2.filter2D(img, -1, kernel) cv2.imshow('dst', dst) cv2.imwrite('./RoseDst.png',dst) cv2.imshow('yuantu', img) cv2.waitKey(0) cv2.destroyAllWindows()


2)均值滤波
OpenCV中有一个专门的平均滤波模板供使用 - 归一化卷积模板,所有的滤波模板都是使卷积框覆盖区域所有像素点与模板相乘后得到的值作为中心像素的值。OpenCV中均值模板可以用cv2.blur()和cv2.boxFilter(),比如一个3*3的模板

模板大小m*n是可以设置的。如果不想要M前面的1/9,可以使用非归一化模板cv2.boxFitter()
函数:cv2.blur() - 其是一个通用的2D滤波函数,它的使用需要一个核模板。该滤波函数是单通道运算的,如果是彩色图像,那么需要将彩色图像的各个通道提取出来,然后分别对各个通道滤波
函数:cv2.boxFilter() - 如果不想使用归一化模板,那么应该使用cv2.boxFilter(),并且传入参数normalize=False
img = cv2.imread('kenan.jpg', 0) # 模板大小为3*5, 模板的大小可以设定 blur = cv2.blur(img, (3, 5)) box = cv2.boxFilter(img, -1, (3, 5)) cv2.imshow('gray', img) cv2.imshow('gray_new', blur) cv2.imshow('gray_new2', box) cv2.waitKey(0) cv2.destroyAllWindows()
3)高斯模糊
前面的卷积模板中的值全是1,将卷积模板中的值换成一组符合高斯分布的数值,其中中间的数值最大,往两边走越来越小,构造一个小的高斯包。这样可以减少原始图像信息的丢失。
函数:cv2.GaussianBlur()
对于高斯模板,首先需要制定高斯核的高和宽(奇数),沿x与y方向的标准差(如果只给x,y=x;如果都给0,那么函数会自己计算)。高斯核可以有效的去除图像的高斯噪声。当然也可以自己构造高斯核,相关函数为:cv2.GaussianKernel()
# 高斯模糊模板
img = cv2.imread('./Rose.jpg', 0)
# 在图像中加入点噪声
for i in range(2000):
_x = np.random.randint(0, img.shape[0])
_y = np.random.randint(0, img.shape[1])
img[_x, _y] = 255
# (5,5)表示的是卷积模板的大小,0表示的是沿x与y方向上的标准差
blur = cv2.GaussianBlur(img, (5, 5), 0)
cv2.imshow('img', img)
cv2.imshow('blur', blur)
cv2.imwrite('./RoseSalt2.png',img)
cv2.imwrite('./RoseGauss.png',blur)
cv2.waitKey(0)
cv2.destroyAllWindows()


4)中值滤波
中值滤波模板就是用卷积框中像素的中值代替中心值,达到去噪声的目的。这个模板一般用于去除椒盐噪声。前面的滤波器都是用计算得到的一个新值来取代中心像素的值,而中值滤波是用中心像素周围(也可以是他本身)的值来取代他,卷积核的大小也是个奇数。
函数:cv2.medianBlur()
中值滤波对于白点噪声的去除,效果非常好
# 中值滤波模板 img = cv2.imread('kenan.jpg', 0) # 加入椒盐噪声 for i in range(2000): _x = np.random.randint(0, img.shape[0]) _y = np.random.randint(0, img.shape[1]) img[_x][_y] = 255 # 中值滤波函数 blur = cv2.medianBlur(img, 5) cv2.imshow('img', img) cv2.imshow('medianblur_img', blur) cv2.waitKey(0) cv2.destroyAllWindows()


5)双边滤波
双边滤波(Bilateral filter)是一种可以保证边界清晰的去噪的滤波器。之所以可达到此去噪声效果,是因为滤波器是由两个函数构成:一个函数是由几何空间距离决定滤波器系数;另一个由像素差决定滤波器系数。它的构造比较复杂,既考虑了图像的空间关系,也考虑了图像的灰度关系。双边滤波同时使用了空间高斯权重和灰度相似性高斯权重,确保了边界不会被模糊掉。
函数:cv2.bilateralFilter(img, d, 'p1', 'p2')
参数:四个参数
第一个参数:原始图像
第二个参数(d):邻域的直径
第三个参数:空间高斯函数标准差
第四个参数:灰度值相似性高斯函数标准差
后面两个参数设置的越大,图像的去噪越多,但图像将变得模糊,所以根据需要调整好后两个参数的大小
# 双边滤波 img = cv2.imread('rose1.jpg', 0) # 添加椒盐噪声 for i in range(2000): _x = np.random.randint(0, img.shape[0]) _y = np.random.randint(0, img.shape[1]) img[_x][_y] = 255 # 9表示的是滤波领域直径,后面的两个数字:空间高斯函数标准差,灰度值相似性标准差 blur = cv2.bilateralFilter(img, 9, 80, 80) cv2.imshow('img', img) cv2.imshow('blur_img', blur) cv2.waitKey(0) cv2.destroyAllWindows()
(七)图像的形态学处理
数学形态学(Mathematical morphology)是一门建立在图论和拓扑学基础之上的图像分析学科,是数学形态学图像处理的基本理论。其基本的运算包括:腐蚀和膨胀、开运算和闭运算、骨架抽取、极限腐蚀、击中击不中变换、形态学梯度、Top-hat变换、颗粒分析、流域变换等。
膨胀、腐蚀、开运算和闭运算是数学形态学的四个基本运算,它们在二值图像和灰度图像中各有特点。基于这些运算还可推导和组合成各种数学形态学实用算法,用它们可以进行图像形状和结构的分析和处理,包括图像分割、特征提取、边缘检测、图像滤波、图像增强和恢复等。
1)图像的膨胀和腐蚀
方法:
函数:cv2.erode()、cv2.dilate()
参数:两个参数
第一个参数:需要处理的二值化图像
第二个参数:结构元素(定义结构元素是数学形态学处理的核心,在OpenCV中可以使用其自带的getStructuringElemet函数,也可以直接使用numpy数组来定义一个结构元素)
函数:Mat getStructuringElement(int shape, Size esize, Point anchor = Point(-1, -1)) 参数:
第一个参数:内核的形状
矩形:MORPH_RECT
交叉形:MORPH_CROSS
椭圆形:MORPH_ELLIPSE
第二个参数:内核的尺寸
第三个参数:锚点的位置,默认值Point(-1,-1),表示锚点位于中心点
返回:处理好的图像
# 腐蚀操作 img = cv2.imread('luotuo.jpg', 0) # 先对图像进行一个二值化处理 ret2, th2 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) # 用numpy定义结构元素 npKernel = np.uint8(np.zeros((5, 5))) for i in range(5): npKernel[2, i] = 1 npKernel[i, 2] = 1 print(npKernel) # 用OpenCV中的getStructuringElement()函数定义结构元素 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 进行腐蚀操作 npKernel_eroded = cv2.erode(th2, npKernel) kernel_eroded = cv2.erode(th2, kernel) cv2.imshow('img', th2) cv2.imshow('npKernel Eroded Image', npKernel_eroded) cv2.imshow('kernel Eroded Image', kernel_eroded) cv2.waitKey(0) cv2.destroyAllWindows() # 膨胀操作 img = cv2.imread('4.jpg', 0) # 先对图像进行一个二值化处理 ret2, th2 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) # 用numpy定义结构元素 npKernel = np.uint8(np.zeros((5, 5))) for i in range(5): npKernel[2, i] = 1 npKernel[i, 2] = 1 # 用OpenCV中的getStructuringElement()函数定义结构元素 kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5)) # 进行膨胀操作 npKernel_dilated = cv2.dilate(th2, npKernel) kernel_dilated = cv2.dilate(th2, kernel) cv2.imshow('img', th2) cv2.imshow('npKernel Dilated Image', npKernel_dilated) cv2.imshow('kernel Dilated Image', kernel_dilated) cv2.waitKey(0) cv2.destroyAllWindows()
2)开运算
开运算:指图像先进行腐蚀再膨胀的运算,腐蚀可以使图像外的小点点去掉,再膨胀就可以去除掉图像外的噪声。
# 开运算操作 img = cv2.imread('luotuo.jpg', 0) ret2, th2 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU) # 添加椒盐噪声 for i in range(2000): _x = np.random.randint(0, th2.shape[0]) _y = np.random.randint(0, th2.shape[1]) th2[_x][_y] = 255 kernel = np.ones((5, 5), np.uint8) # 开运算函数 erosion = cv2.morphologyEx(th2, cv2.MORPH_OPEN, kernel) cv2.imshow('th2', th2) cv2.imshow('morph_open', erosion) cv2.waitKey(0) cv2.destroyAllWindows()
3)闭运算
闭运算:指先进行膨胀运算再进行腐蚀运算,膨胀可以将图像内的小白点去掉,然后把主图像腐蚀回来,实现对图像内噪声的去除。
# 闭运算操作 img = cv2.imread('luotuo.jpg', 0) ret2, th2 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) # 添加椒盐噪声 for i in range(20000): _x = np.random.randint(0, th2.shape[0]) _y = np.random.randint(0, th2.shape[1]) th2[_x][_y] = 0 kernel = np.ones((5, 5), np.uint8)
# 闭运算函数(此时,对图像的膨胀和腐蚀操作是对二值化后的白色图像区域的膨胀和腐蚀) erosion = cv2.morphologyEx(th2, cv2.MORPH_CLOSE, kernel) cv2.imshow('th2', th2) cv2.imshow('erosion', erosion) cv2.waitKey(0) cv2.destroyAllWindows()
4)形态学梯度
方法:通过利用对图像的膨胀和腐蚀的组合使用,使得处理后的图像如同提取了物体的轮廓。
# 形态学梯度 img = cv2.imread('luotuo.jpg', 0) ret, th = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) kernel = np.ones((5, 5), np.uint8) # cv2.morphologyEx() 形态学 - cv2.MORPH_GRADIENT 形态梯度 gradient = cv2.morphologyEx(th, cv2.MORPH_GRADIENT, kernel) cv2.imshow('th', th) cv2.imshow('gradient', gradient) cv2.waitKey(0) cv2.destroyAllWindows()


5)礼帽和黑帽
礼帽:指的是原始图像与其进行开运算后的图像进行一个差,对于差别之处显示其原有图色。
# 礼帽 img = cv2.imread('4.jpg', 0) ret, th = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) kernel = np.ones((5, 5), np.uint8) tophat = cv2.morphologyEx(th, cv2.MORPH_TOPHAT, kernel) cv2.imshow('th', th) cv2.imshow('tophat', tophat) cv2.waitKey(0) cv2.destroyAllWindows()
黑帽:指的是原始图像与其进行闭运算后的图像进行一个差,对于差别之处显示原有图色的反颜色。
# 黑帽 img = cv2.imread('4.jpg', 0) ret, th = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) kernel = np.ones((5, 5), np.uint8) blackhat = cv2.morphologyEx(th, cv2.MORPH_BLACKHAT, kernel) # blackhat cv2.imshow('th', th) cv2.imshow('blackhat', blackhat) cv2.waitKey(0) cv2.destroyAllWindows()
(八)边缘检测
边缘检测
边缘检测是图像处理和计算机视觉中的基本问题,边缘检测的目的是标识数字图像中亮度变化明显的点。图像属性中的显著变化通常反映了属性的重要事件和变化。边缘检测是特征提取中的一个研究领域。
图像边缘检测大幅度地减少了数据量,并且剔除了可以认为不相关的信息,保留了图像重要的结构属性。有许多方法用于边缘检测,它们的绝大部分可以划分为两类:基于查找一类和基于零穿越的一类。
基于查找的方法通过寻找图像一阶导数中的最大值和最小值来检测边界,通常是将边界定位在梯度最大的方向。基于零穿越的方法通过寻找图像二阶导数零穿越来寻找边界,通常是Laplacian过零点或者非线性差分表示的过零点。
如果将边缘认为是一定数量点亮度发生变化的地方,那么边缘检测大体上就是计算这个亮度变化的导数。
1)检测方法
边缘检测的方法大致可分为两类:
- 基于搜索:基于搜索的边缘检测方法首先计算边缘强度,通常用一阶导数表示,例如梯度模,然后,用计算估计边缘的局部方向,通常采用梯度的方向,并利用此方向找到局部梯度模的最大值;
- 基于零交叉:基于零交叉的方法找到由图像得到的二阶导数的零交叉点来定位边缘,通常用拉普拉斯算子或非线性微分方程的零交叉点。
滤波作为边缘检测的预处理通常是必要的,通常采用高斯滤波。
2)Sobel边缘检测算子
Sobel边缘检测算法比较简单,实际应用中效率比Canny边缘检测效率要高,但边缘不如Canny检测得准确,但很多实际应用的场合Sobel边缘却是首选,Sobel算子是高斯平滑与微分操作的结合体,所以其抗噪声能力很强,用途较多。尤其是效率要求较高,而对细纹理不太要求的时候。算子的模板为:

Sobel算子是一种带有方向的过滤器
函数:cv2.Sobel() - Sobel_x_or_y = cv2.Sobel(src, ddepth, dx, dy, dst, ksize, scale, delta, borderType)
参数:九个参数
第一个参数:传入的图像 第二个参数:图像的深度 第三/四个参数(dx/dy):指的是求导的阶数,所填的数一般为0、1、2,0表示这个方向上没有求导 第五个参数(dst):dst及dst之后的参数都是可选参数 第六个参数(ksize):是Sobel算子的大小,即卷积核的大小,必须为奇数1、3、5、7。如果ksize=-1,就演变成为3x3的Scharr算子 第七个参数(scale):是缩放导数的比例常数,默认情况为没有伸缩系数 第九个参数(borderType):是判断图像边界的模式,这个参数默认值为cv2.BORDER_DEFAULT
# Sobel边缘检测算子 img = cv2.imread('luotuo.jpg', 0) x = cv2.Sobel(img, cv2.CV_16S, 1, 0) y = cv2.Sobel(img, cv2.CV_16S, 0, 1) # cv2.convertScaleAbs(src[, dst[, alpha[, beta]]]) # 可选参数alpha是伸缩系数,beta是加到结果上的一个值,结果返回uint类型的图像 # convert转换 scale缩放 Scale_absX = cv2.convertScaleAbs(x) Scale_absY = cv2.convertScaleAbs(y) result = cv2.addWeighted(Scale_absX, 0.5, Scale_absY, 0.5, 0) cv2.imshow('img', img) cv2.imshow('Scale_absX', Scale_absX) cv2.imshow('Scale_absY', Scale_absY) cv2.imshow('result', result) cv2.waitKey(0) cv2.destroyAllWindows()
Sobel函数求完导数后会有负值,还有会大于255的值。而原图像是uint8,即8位无符号数,所以Sobel建立的图像位数不够,会有截断。因此要使用16位有符号的数据类型,即cv2.CV_16S。处理完图像后,再使用cv2.convertScaleAbs()函数将其转回原来的uint8格式,否则图像无法显示。
Sobel算子是在两个方向计算的,最后还需要用cv2.addWeighted( )函数将其组合起来。
result = cv2.addWeighted(src1, alpha, src2, beta, gamma[, dst[, dtype]])
其中alpha是第一幅图片中元素的权重,beta是第二个图像的权重,gamma是加到最后结果上的一个值。
3)Scharr算子
当Sobel()函数的参数ksize=-1时,就演变成了3x3的Scharr算子。该算子的模板为:
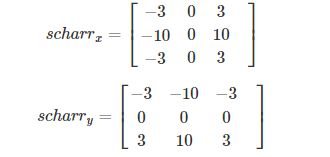
# Scharr算子 img = cv2.imread('luotuo.jpg', 0) x = cv2.Sobel(img, cv2.CV_16S, 1, 0, ksize=-1) y = cv2.Sobel(img, cv2.CV_16S, 0, 1, ksize=-1) # ksize=-1 Scharr算子 # cv2.convertScaleAbs(src[, dst[, alpha[, beta]]]) # 可选参数alpa是伸缩系数,beta是加到结果上的一个值,结果返回uint类型的图像 # convert转换 scale缩放 Scharr_absX = cv2.convertScaleAbs(x) Scharr_absY = cv2.convertScaleAbs(y) result = cv2.addWeighted(Scharr_absX, 0.5, Scharr_absY, 0.5, 0) cv2.imshow('img', img) cv2.imshow('Scharr_absX', Scharr_absX) cv2.imshow('Scharr_absY', Scharr_absY) cv2.imshow('result', result) cv2.waitKey(0) cv2.destroyAllWindows()
从Scharr算子与Sobel算子最终的结果比较可以看出,Scharr对图像梯度的变化更加敏感
4)拉普拉斯(Laplacian)算子
Laplacian函数实现的方法是先用Sobel算子计算二阶x和y导数,再求和。
![]()
函数:laplacian = cv2.Laplacian(src, ddepth[, dst[, ksize[, scale[, delta[, borderType]]]]])
参数:两个参数
# 前两个参数是必选参数,其后是可选参数 第一个参数:需要处理的图像 第二个参数:图像的深度,-1表示采用的是原图像相同的深度,目标图像的深度必须大于等于原图像的深度 第四个参数(ksize):是算子的大小,即卷积核的大小,必须为1、3、5、7,默认为1 第五个参数(scale):是缩放导数的比例chan常数,默认情况下没有伸缩系数 第七个参数(borderType):是判断图像边界的模式,这个参数默认值为cv2.BORDER_DEFAULT
# 拉普拉斯算子 img = cv2.imread('luotuo.jpg', 0) laplacian = cv2.Laplacian(img, cv2.CV_16S, ksize=3) dst = cv2.convertScaleAbs(laplacian) cv2.imshow('laplacian', dst) cv2.waitKey(0) cv2.destroyAllWindows()
当参数ksize越大即卷积核越大时,算子对图像梯度的变化越敏感。ksize=3时的图像还不是很好,在经过高斯模糊处理一下,去掉了很多噪声。
blur = cv2.GaussianBlur(img, (3, 3), 0) laplacian = cv2.Laplacian(blur, cv2.CV_16S, ksize=3)
5)Canny算子
图像边缘检测必须满足两个条件,一能有效地抑制噪声;二必须尽量精确确定边缘的位置。
根据对信噪比与定位乘积进行测度,得到最优化逼近算子。这就是Canny边缘检测算子。
算法的基本步骤为:
1.用高斯滤波器平滑图像;
2.用一阶偏导的有限差分来计算梯度的幅值和方向;
3.对梯度幅值进行非极大抑制;
4.用双阈值算法检测和连接边缘。
函数:canny = cv2.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient ]]])
参数:
第一个参数:需要处理的原图像单通道的灰度图 第二/三个参数:阈值1/阈值2,较大的阈值2用于检测图像中明显的边缘,但一般情况下检测的效果不会那么完美,边缘检测出来是断断续续的。所以这时候应用较小的第一个阈值来将这些间断的边缘连接起来 第五个参数(Aperaperturesize[可选参数]):卷积核的大
第六个参数(L2gradient[可选参数]):该参数是一个布尔值,如果为true,则就使用更精确的L2范数进行计算(即两个方向的倒数的平方和再开方),否则使用L1范数(直接将两个方向导数的绝对值相加)
# canny算子 img = cv2.imread('luotuo.jpg', 0) # 用高斯滤波处理原图像降噪 blur = cv2.GaussianBlur(img, (3, 3), 0) # 50是最小阈值,150是最大阈值 canny = cv2.Canny(blur, 50, 150) cv2.imshow('canny', canny) cv2.waitKey(0) cv2.destroyAllWindows()
其对图像的处理效果比较不错,在阈值的选取上可以设置一个可以在运行时调整阈值大小的程序。
lowThreshold = 0 max_lowThreshold = 100 ratio = 3 kernel_size = 3 img = cv2.imread('luotuo.jpg') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) cv2.namedWindow('canny demo') cv2.createTrackbar('Min threshold', 'canny demo', lowThreshold, max_lowThreshold, CannyThreshold) # Initiatization CannyThreshold(0) if cv2.waitKey(0) == 27: cv2.destroyAllWindows()
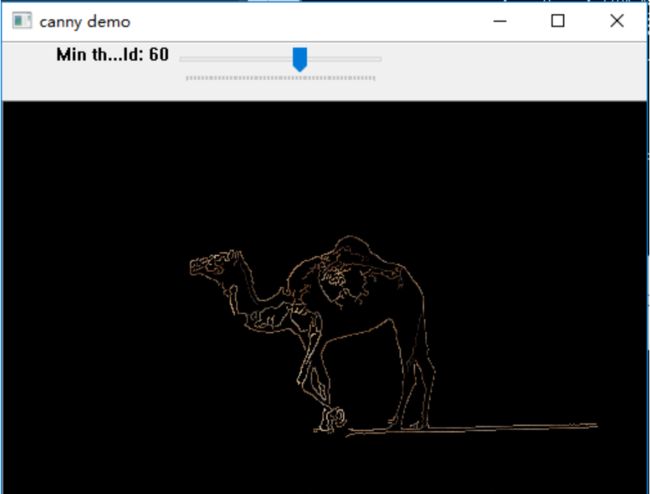
(九)图像金字塔
图像金字塔是图像多尺度表达的一种,是一种以多分辨率来解释图像的有效但概念简单的结构。图像金字塔最初用于机器视觉和图像压缩,一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。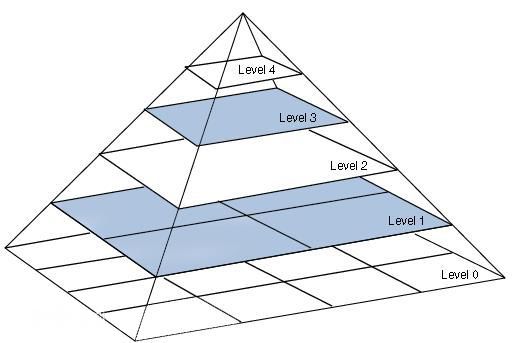
从上面对图像金字塔的定义来看,图像金字塔的功能之一就是对图像尺度的转换,即放大或者缩小图片,在OpenCV中提供了两种方法:
- cv2.resize()函数:这种方法可直接对图像进行尺度的变换
- cv2.pyrUp()、cv2.pyrDown()函数:对图像向上/下采样,这是与图像金字塔相关的两个函数,分别是对图像的向上采样、向下采样操作
图像金字塔一般有两种类型(区别:高斯金字塔用来向下采样图像,而拉普拉斯金字塔则用来从金字塔底层图像中向上采样重建一个图像):
- 高斯金字塔(Gaussianpyramid):用来向下采样,是主要的图像金字塔
- 拉普拉斯金字塔(Laplacianpyramid):用来从金字塔底层图像重建上层未采样图像,在数字图像处理中也就是预测残差,可以对图像进行最大程度的还原,配合高斯金字塔一起使用
# 读为灰度图 img = cv2.imread('luotuo.jpg', 0) # 上采样操作 up_img = cv2.pyrUp(img) # 下采样操作 img_1 = cv2.pyrDown(img) img_2 = cv2.pyrDown(img_1) cv2.imshow('up_img', up_img) cv2.imshow('img', img) cv2.imshow('img_1', img_1) cv2.imshow('img_2', img_2) cv2.waitKey(0) cv2.destroyAllWindows()
这里的向下与向上采样是对图像的尺度来说的 ,相当于倒立的金字塔,向上就是图像尺寸加倍,向下就是图像尺寸减半。
需要注意的是,pyrUp和pyrDown不是互逆的,即上采样不是下采样的逆操作。
pyrDown()是一个会丢失信息的函数。为了恢复原来更高分辨率的图像,要获得由于下采样操作所丢失的信息,这些数据就和拉普拉斯金字塔有关了。
图像的拉普拉斯金字塔可以由图像的高斯金字塔得到,转换的公式为:
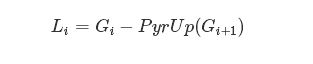
img = cv2.imread('3.jpg', 0)
# 高斯金字塔 img1 = cv2.pyrDown(img) _img1 = cv2.pyrDown(img1) _img = cv2.pyrUp(_img1)
# 拉普拉斯金字塔 img2 = img1 - _img cv2.imshow('img1', img1) cv2.imshow('img2', img2) cv2.waitKey(0) cv2.destroyAllWindows()
拉普拉斯金字塔的图像看起来就像是边界图,经常被用在图像压缩中。
关于图像的放大和缩小,一般还是使用resize()函数比较好,因为其不会使图像变得特别模糊,而且非常简便。
(十)霍夫变换简单图形检测
霍夫变换
霍夫变换(Hough Transform)是图像处理中从图像中识别几何形状的基本方法之一,应用很广泛,也有很多改进算法。主要用来从图像中分离出具有某种相同特征的几何形状(如:直线、圆等)。最基本的霍夫变换是从黑白图像中检测直线。
霍夫变换是经典的检测直线的算法。其最初用来检测图像中的直线,同时也可以将其扩展,以用来检测图像中的简单结构。它最初是用于在二值化的图像中进行直线检测的。对于图像中的一条直线,利用直角坐标系,可以用公式表示为:
![]()
如果从k-b参数空间的角度来考虑,则该直线的任意一点(x,y)将变成一个“点”。也就是说,将图像空间中所有的非零像素转换到k-b参数空间,那么它们将聚焦在一个点上,而且参数空间中的一个局部峰值点就很有可能对应着原图像空间的一条直线。不过,由于直线的斜率可能为无穷大,或者无穷小,那么在k-b参数空间就不便于对直线进行描述和刻画。所以,提出采用极坐标参数空间进行直线检测。在极坐标系中,直线可以表述为以下形式:![]()

上图(a)所示为原始的图像空间中的一个点(x0,y0);图(b)中所示为直角坐标系当中为过同一点的四条直线;图(c)所示为这四条直线在极坐标参数空间可以表示为四个点。
在OpenCV中支持两种不同的霍夫直线变换:The Standard Hough Transform(SHT/标准霍夫变换);Progressive Probability Hough Transform(PPHT/渐进概率式霍夫变换)。
SHT就是上述的在极坐标空间进行参数表示的方法,而PPHT是SHT的改进,它是在一定的范围内进行霍夫变换,从而减少计算量,缩短计算时间。
在OpenCV中检测直线的函数有cv2.HoughLines() - 标准霍夫变换,cv2.HoughLinesP() - 渐进概率式霍夫变换。
1)标准霍夫变换
函数:cv2.HoughLines()
返回:返回值实际上是一个二维数据矩阵,表述的就是上述的(ρ,θ),其中ρ的单位是像素长度(即直线到图像原点直线的距离,从上述图(b)中可以看出),θ的单位是弧度
参数:四个参数 - 通过调整边缘检测算子Canny阈值参数和标准霍夫变换阈值参数,来获取较好的检测效果
第一个参数:是需要进行检测的灰度图 第二/三参数:分别是ρ和θ的精确度,可以理解为步长 第四个参数:阈值T,认为当累加器中的值高于所设定的阈值T时,才认为是一条直线
# 标准霍夫变换 img = cv2.imread('malu.jpg') # 获取灰度图 house = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) edges = cv2.Canny(house, 50, 200) # 霍夫变换返回的就是极坐标系中的两个参数rho和theta lines = cv2.HoughLines(edges, 1, np.pi/180, 260) print(np.shape(lines)) # 将数据转换到二维 lines = lines[:, 0, :] for rho, theta in lines: a = np.cos(theta) b = np.sin(theta) # 从图b中可以看出
# x0 = rho x cos(theta) # y0 = rho x sin(theta) x0 = a*rho y0 = b*rho # 由参数空间向实际坐标点转换 x1 = int(x0 + 1000*(-b)) y1 = int(y0 + 1000*a) x2 = int(x0 - 1000*(-b)) y2 = int(y0 - 1000*a) cv2.line(img, (x1, y1), (x2, y2), (0, 0, 255), 1) cv2.imshow('img', img) cv2.imshow('edges', edges) cv2.waitKey(0) cv2.destroyAllWindows()
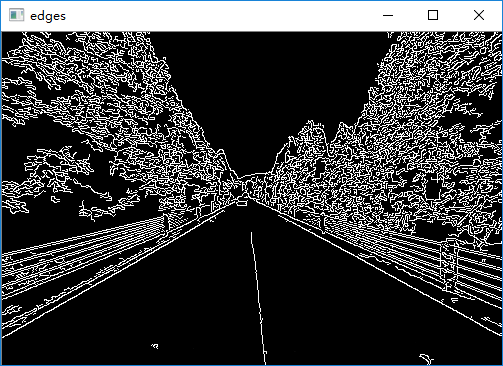
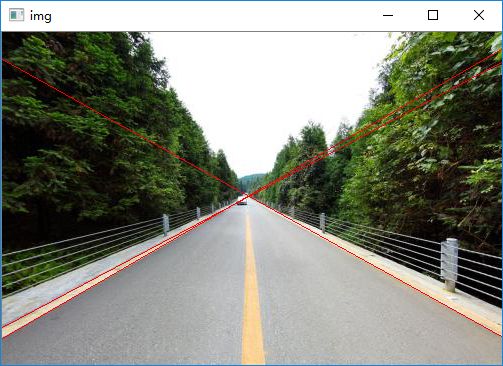
2)渐进概率式霍夫变换
函数:cv2.HoughLinesP() - 是一种概率直线检测,从原理上讲Hough变换是一个耗时耗力的算法,尤其是对每一个点的计算,即便经过了canny转换,但有的时候点的数量依然很庞大,这时候采取一种概率挑选机制,不是所有的点都进行计算,而是随机的选取一些点来进行计算,这样的话在阈值设置上也需要降低一些
参数:与标准霍夫变换函数相比,在参数的输入上多了两个参数:minLineLengh(线的最短长度,比这个线段短的都忽略掉)和maxLineGap(两条直线之间的最大间隔,小于此值,就认为是一条直线)
返回:输出直接是直线点的坐标位置,这样可以省去一系列for循环中的由参数空间到图像的实际坐标点的转换
# 渐进概率式霍夫变换 img = cv2.imread('house1.jpg') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) edges = cv2.Canny(gray, 50, 250) lines = cv2.HoughLinesP(edges, 1, np.pi/180, 30, minLineLength=60, maxLineGap=10) lines = lines[:, 0, :] for x1, y1, x2, y2 in lines: cv2.line(img, (x1, y1), (x2, y2), (0, 255, 0), 1) cv2.imshow('img', img) cv2.waitKey(0) cv2.destroyAllWindows()
再进行边缘检测之前如果对图像进行去噪声操作,图像显示的效果将会更好。

3)利用霍夫变换检测圆环
圆的数学的数学表达式为:
![]()
所以一个圆的确定需要三个参数,那么就需要三层循环来实现,从而把图像上的所有点映射到三维空间上。寻找参数空间累加器的最大(或者大于某一阈值)的值。那么理论上圆的检测将比直线更耗时,然而OpenCV对其进行了优化,用了霍夫梯度法。
函数:cv2.HoughCircles(image, method, dp, minDist, circles, param1, param2, minRadius, maxRadius)
参数:param1和param2就是和的精确度,最后两个参数是所要检测的圆的最大最小半径,不能盲目的检测,否则浪费时间和空间
返回:输出就是三个参数空间矩阵
# 利用霍夫检测对印章进行定位
img = cv2.imread('yinzhang.jpg') gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) cv2.imshow('img_yuantu', img) gaussian = cv2.GaussianBlur(gray, (3, 3), 0) circles1 = cv2.HoughCircles(gaussian, cv2.HOUGH_GRADIENT, 1, 100, param1=100, param2=30, minRadius=15, maxRadius=80) # hough_gradient 霍夫梯度法 print(np.shape(circles1)) circles = circles1[0, :, :] circles = np.uint16(np.around(circles)) for i in circles[:]: cv2.circle(img, (i[0], i[1]), i[2], (0, 255, 0), 3) cv2.circle(img, (i[0], i[1]), 2, (255, 0, 255), 10) cv2.imshow('img', img) cv2.waitKey(0) cv2.destroyAllWindows()


(十一)图像轮廓检测
1)检测轮廓
函数:cv2.findContours() - cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]])
参数:三个参数
第一个参数:寻找轮廓的图像
第二个参数:轮廓的检索模式
cv2.RETR_EXTERNAL 表示只检测外轮廓
cv2.RETR_LIST 检测的轮廓不建立等级关系
cv2.RETR_CCOMP 建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息
cv2.RETR_TREE 建立一个等级树结构的轮廓
第三个参数:方法为轮廓的近似方法
cv2.CHAIN_APPROX_NONE 存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2),abs(y1-y2))=1
cv2.CHAIN_APPROX_SIMPLE 压缩水平方向、垂直方向、对角线方向的元素,只保留该方向的终点坐标,例如一个矩阵轮廓只需4个点来保存轮廓信息(矩形只需四顶点)
cv2.CHAIN_APPROX_TC89_L1 使用teh-Chinl chain近似算法
cv2.CHAIN_APPROX_TC89_KCOS 使用teh-Chini chain近似算法
返回:两个返回值
(contours):轮廓本身
(hierarchy):各层轮廓的索引,每条轮廓对应的属性
2)绘制轮廓
函数:cv2.drawContours - cv2.drawContours(image, contours, contourIdx, color[, thickness[, lineType[, hierarchy[,maxLevel[, offset ]]]]])
参数:四个参数
第一个参数:传入所要绘制轮廓的背景图片 第二个参数:轮廓本身 第三个参数:指定绘制轮廓中的哪条轮廓,如果是-1则绘制其中的所有的轮廓 第四个参数(thickness):轮廓的宽度,如果是-1(cv2.FILLED)表示为填充模式
# 轮廓检测 img = cv2.imread('2.jpg') # 获取灰度图 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 利用阈值自动选择的方法获取二值图像 ret, binary = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) # 检测轮廓 image, contours, hierarchy = cv2.findContours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) # 画出轮廓 cv2.drawContours(img, contours, -1, (0, 255, 0), 1) cv2.imshow('gray', binary) cv2.imshow('res', img) cv2.waitKey(0) cv2.destroyAllWindows()
(十二)图像的差分
函数:cv2.absdiff() - 将两幅图像作差,获取两个图像之间的差分图
返回:将两张图片进行对比,返回的结果代表他们的差异之处,一般用在比较与背景图的差异
# 输入灰度图,类型是uint8(在OpenCV单通道使用的数据类型是uint8) # 两个uint8的数相减得不到负数,会得到差的补码 map = cv2.imread('./img/TextNotOnMap.png') text = cv2.imread('./img/TextOnMap.png') strtimg = cv2.absdiff(text, map) cv2.imshow('img',strtimg) cv2.waitKey(0)