python中的re模块是正则技术中应用。对于正则就是正则表达式,正则表达式是独立一门技术,在各个编程体系都有它的“身影"。在python中在爬虫技术中,数据分析,它都是必不可少的存在。主要利用正则表达式筛选字符串中我们需要的字符串类型数据。
正则表达式基础知识。元字符和量词。
| 元字符 |
匹配作用 |
| . |
可以匹配除换行符以外的任何字符 |
| \w |
匹配字母,数字和下滑线 |
| \d |
匹配数字 |
| \s |
匹配空格 |
| \W |
匹配非字母,数字和下划线 |
| \D |
匹配非数字 |
| \S |
匹配非空格 |
| ^ |
匹配^字符串开头。用法(^a:匹配a开头的字符串) |
| $ |
匹配$字符串结尾。用法(a$:匹配字符串a结尾) |
| \n |
匹配换行符 |
| \t |
匹配一个制表符 |
| \b |
匹配单词的结尾 |
| () |
匹配括号内的表达式,也表示一个分组 |
| […] |
匹配字符组中的字符 |
| [^….] |
匹配除了字符组中的所有字符 |
| a|b |
匹配a或b字符 |
量词
| 量词 |
用法说明 |
| * |
代表零次或多次 |
| + |
重复零次或多次 |
| ? |
重复零次或一次 |
| {n} |
重复n次 |
| {n,} |
至少重复n次 |
| {n, m} |
重复n次到m次 |
以上便是一些基本知识。对于基本知识的应用。进入这个网站:http://tool.chinaz.com/regex/。可以测试这些符号的使用。

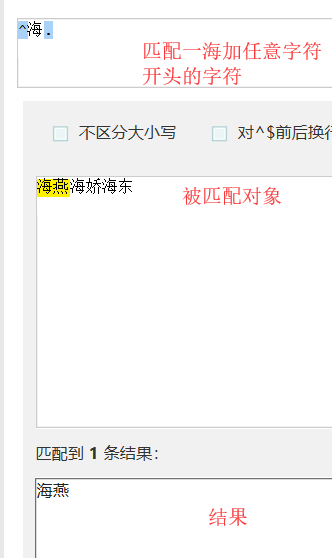
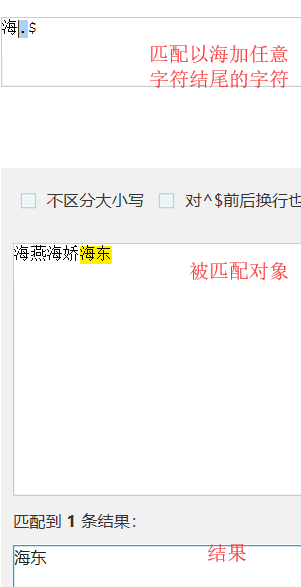

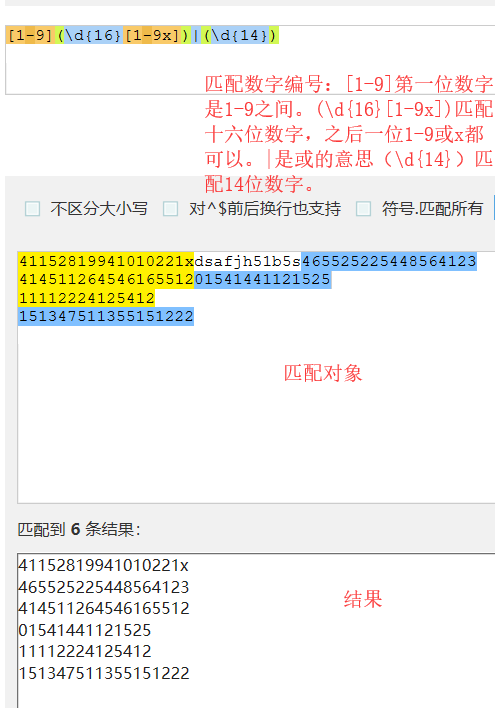
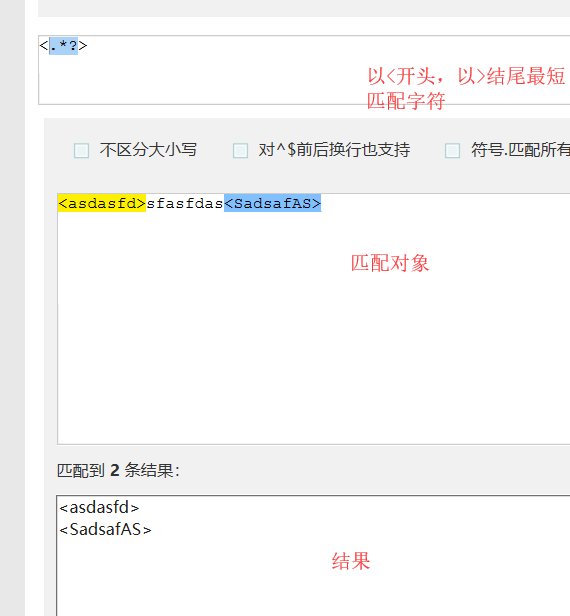
正则表达式在使用量词*和+,正则匹配是贪婪匹配。默认的是尽可能多的匹配。这个时候需要.*?这个正则表达式:这个正则表达式.任意字符。在前也可以自己添加字符,*量词多次匹配。?匹配一次或多次。在后面添加结束的字符。对于贪婪匹配,有惰性匹配。*?重复次任意,但尽可能少重复。+?重复次一次或多次,但尽可能少的匹配。??重复0次到一次,但尽可能少的匹配。此外在匹配时还需要注意转义符\的使用。不想是但\转义可以用\\转义,双\\则需要\\对其转义。或者使用r'\\'转义
在python中re模块的使用。使用调用模块:import re调用。常用的re模块中的函数有findall(), serch(), match()。
findall('正则表达式', '匹配对象(字符串类型)')。找到正则表达式中的内容,并且返回一个列表,列表中的元素就匹配的结果。
# findall res = re.findall('a', 'dghahfhjfadhbvavlfhjvb') print(res) >>>['a', 'a', 'a']
search('正则表达式', '匹配对象(字符串类型)')。找到正则表达式中的内容之找一次,找到后就结束。查找到不存在结果返回None。并且返回结果需要借助group函数打印。
res = re.search('a','dasda' ) print(res.group())
match('正则表达式', '匹配对象(字符串类型)')。只会以正则表达式匹配开头字符串,开头字符长不符合返回None。打印时也需要借助group函数。


ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个 print(ret) #evaHegon4yuan4 ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 print(ret.group()) #结果 : 123 import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) #print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果
使用search和match时可以给正则表达式中的组取名,在调用时使用字符串类型组名和group函数即可调用
res = re.search('(?P[a-d]*) ', 'adaabuxdabcdabcddadadkamfaslcjhlancabcd' ) print(res.group('rec')) # 必须在组内,以?P<名字>格式 >>>adaab
在findall的分组机制有些不同
res = re.findall('www.(baidu|jd).com', 'www.baidu.com') print(res) >>>['baidu'] # 在组内加上?: res = re.findall('www.(?:baidu|jd).com', 'www.baidu.com') print(res) >>>['www.baidu.com']