分布式系统为了保证其可靠性,一般都会多节点提供服务,各别节点的故障不会影响系统的可用性。对于分布式的存储系统来说,在保证可用性的同时,数据的可靠性(不丢失)也是其要解决的核心问题。目前通用的方案是使用多副本存储。这就会引入一个新的问题,分布式存储系统的又一核心问题——多个副本间的数据一致性保障。所以就有了各种数据一致性协议。例如:Zookeeper的Zab、Etcd使用的Raft和无比复杂的Paxos等等。这些一致性协议都有一个共同的特点,那就是都有一个主节点(Leader)负责数据的同步。
本文不讨论这些一致性协议的工作原理,我们重点聊一聊它们的选主策略——当Leader挂掉后,集群必须有能力选出一个新的Leader。为什么只讨论选主呢?因为在我们的工作中几乎不太可能去设计实现一致性协议,但"选主"这个事儿还是有可能需要我们去做的。例如之前文章介绍的时间轮,我们有多个节点提供服务,但只能有一个节点去转动轮子(一秒移动一次当前指针),这个时候就需要系统中始终有一个Leader负责转动轮子。业务上类似的需求还有很多,这里就不举例了,接下来我们介绍下几种选主策略。
首先明确下选主的时机:一般发生在集群的Leader宕机或者集群刚刚启动时,集群中没有Leader,这时就会触发选主。这里有两个技术点:
1、集群中节点需要能够感知到Leader的存在;
2、从剩余的活跃节点中选出一个新的Leader;
选主常用的方式有两种:投票和竞争,下面我们分别介绍下。
一、投票选主
在投票选主方式中,一般集群中会有两种角色:Leader和Follower,Leader和各Follower间保持心跳,Follower通过心跳判断Leader是否存活,如果Follower感知不到Leader,则触发选举。获得集群半数以上节点投票的Follower将成为集群新的Leader。为了提高选举的效率,集群节点数一般都为奇数个。那么Leader是如何选出来的呢?不同的一致性协议,有不同的玩法,下面简单了解下Zookeeper和Etcd的选主方式(为了便于理解对模型做了简化,只描述核心算法和思路):
ZooKeeper
ZK的节点在投票时是通过比较两个“ID”来决定把票投给谁的:
1、ZXID:ZooKeeper事务Id,越大表示数据越新;
2、SID:集群中每个节点的唯一编号;
投票时的比较算法为:谁的ZXID大谁胜出,ZXID相同情况谁的SID大谁胜出(简单理解:谁的数据新胜出,数据一样谁的编号大谁胜出)。
选举算法如下:
1、集群失去Leader后,所有节点进入Looking状态,向集群中广播(第一轮投票)自身选举值(SID,ZXID),投自己一票;
2、每个节点都会将自身选举值与收到的所有其它节点的选举值作比较,选出“最大”的,如果最大的不是自己,则改投最"大“节点,广播变更(第二轮投票);
3、集群中节点收到第二轮结果后,统计超过半数的选举值,其对应的节点将成为集群新的Leader;选举过程入下图所示:
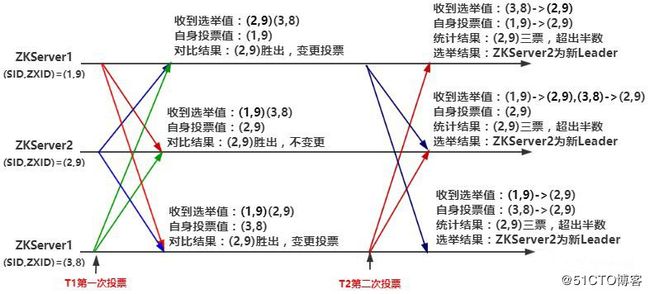
图1 ZooKeeper选主过程
Etcd
Etcd使用Raft一致性协议,集群中每个节点都有自己的倒计时器,且时间随机。Follower每次收到心跳后都会重置倒计时器,当某个Follower的倒计时结束,说明长时间没有收到心跳,就可以认为Leader挂了,需要选举新的Leader了。这个Follower就会触发选举,想成集群为新的Leader。
Follower首先会将自身状态改为Candidate,并向所有节点发起投票,如果得到半数以上节点的同意则成为集群新的Leader。否则,在下次倒计时结束后发起新一轮选举。
Raft选举过程中,投票节点通过对比任期(Term,一个连续递增的整型值)和CommitId(类似ZK的事务Id)来判断是否投“同意”票。选举过程如下:
1、Candidate发起投票时将自身当前任期加1(NewTerm),并向集群中所有节点发起投票请求(请求中包含新的任期值);
2、Follower节点将自身当前任期(CurrentTerm)和收到的Candidate投票请求中带来的NewTerm比较,如果NewTerm大就投“同意”票(这里忽略的CommitId的比较是为了更好理解和强调Term的作用,比较方法与ZK类似);
3、Candidate得到大于半数节点的”同意“后成为Leader,与其他节点建立心跳,并更新所有节点的当前任期为NewTerm;
4、如果不够半数,则选举失败,等待倒计时器下次到期发起下一轮选举;
选举过程如图2、图3所示:
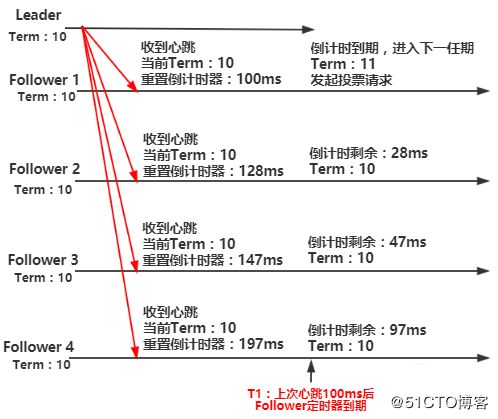
图2 Leader心跳中断,进入下一任期
集群正常情况下,各节点处于同一任期,Leader节点定时发送心跳重置各Follower倒计时器,当Leader心跳中断后,Follower倒计时器不再被重置,则会必然会有节点到期,触发选举,图2中Follower 1先到期,变为Candidate并发起选举,进入下一任期。
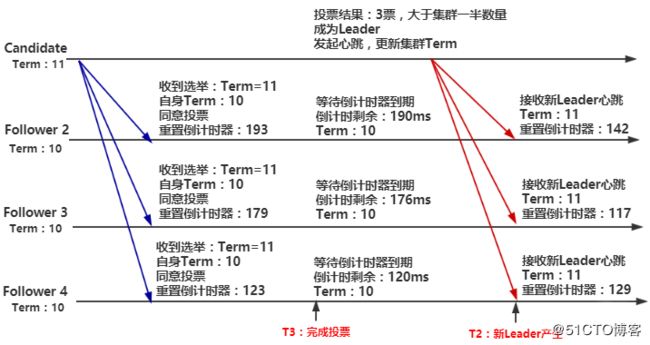
图3 完成选举
选举成功,原Follower成为集群新的主节点,开始向各Follower发送心跳,并更新其它节点的任期。
上面介绍的流程只是最简单的场景,实际情况会复杂些,例如有可能会有产生多个Candidate,因为只要有Follower节点到期,就会发起投票,进入Candidate状态,Reft是如何尽量避免产生多个Candidate的呢?
首先各节点倒计时时间随机,尽量避免同时到期。其次Follower收到Candidate的投票请求时会重置自己的倒计时器,这样就尽量保证了在选举失败后Candidate能够率先到期,可以下一任期继续由它发起投票。
但是肯定还存在产生多个Candidate的情况,所以协议规定一个Follower在一个任期只能投一次票,这样就够不可能有两个Candidate同时获得半数以上的投票(不可能选出两个Leader来)。如果选举失败,由于节点倒计时器时间随机,所以几乎可以肯定会有一个Candidate先到期,并且大概率在下一轮选举中成为Leader。
二、竞争选主
上面介绍的投票选举方式需要集群各节点互相感知对方的存在,实现相对复杂,下面介绍一种比较简单的方案——竞争选主。
竞争选主需要借助外部存储服务来实现,各节点通过对某个约定的Key-Value数据的访问,来决定谁是Leader,假设KV数据为Leader:UUID(写入前生成的唯一Id),具体”抢主“逻辑如下:
1、尝试获取Leader:UUID数据,判断数据是否存在;
2、如果Leader不存在,则将Leader:UUID写入到存储服务中并设置其TTL(如果存储服务不支持TTL,可以将TTL作为Value的一部分一起写入),本地保存UUID值,当前进程为主节点;
3、如果Leader存在,通过TTL判断是否过期,如果过期,当做Leader不存在处理,否则对比Leader的UUID和本地存储的UUID是否一致;
3.1、如果一致则刷新”数据“TTL,当前进程为Leader;
3.2、如果不一致则不作任何操作,当前节点不是Leader;
集群内所有的进程,都保证以小于TTL的周期执行上述逻辑,Leader就会不停的“刷新”Leader:UUID的TTL,始终保持自己是Leader,如果想更安全,刷新时可以使用CAS的方式每次更新UUID。当Leader宕机不能继续刷新后,数据必然会过期,其它节点将会竞争写入,成为集群新的Leader(和分布式锁很像,可以理解为一把长期持有的锁,新的玩法)。
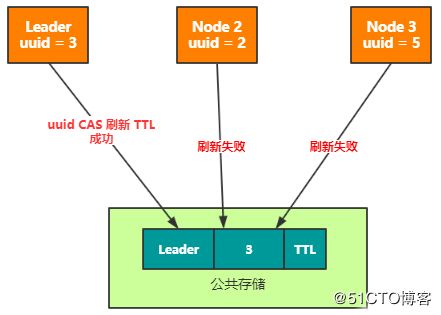
图4 竞争Leader
我们分析下上述逻辑,当约定的Key不存在时,集群处于没有主或主挂了的状态,其他节点可以通过判断这个Key感知到Leader是否存在,从而触发选主,写入Key的过程相当于竞争选主的过程,谁写入成功谁就是新的Leader。
三、总结
本文介绍了两种选主方式,竞争的方式很好理解,实现也非常简单,但为什么存储系统很少选择竞争选主方案?如果我们的业务模块要实现选举使用那种方案好一些?欢迎大家在留言区讨论。
作者:奈学教育请添加链接描述-孙玄