- 操作系统性能工具之top
top - 20:00:19 up 10 min, 2 users, load average: 0.21, 2.93, 2.63
top 命令第一行结果和uptime的输出结果一样:
当前时间,运行时间,登陆用户数,系统负载
系统负载有三个参数:系统任务队列的平均长度,分别统计最近1、5、15分钟的系统平均负载
[root@docker_master ~]# uptime 20:41:18 up 51 min, 2 users, load average: 0.20, 0.17, 0.38
Tasks: 232 total, 2 running, 230 sleeping, 0 stopped, 0 zombie
#总进程数,正在运行的进程数,正在休眠的进程数,停止的进程数,僵尸进程数
%Cpu0 : 0.0 us, 0.7 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.7 us, 2.1 sy, 0.0 ni, 97.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
#按数字1显示出多核cpu信息
#us用户空间占用CPU百分比,sy内核空间占用CPU百分比
#ni用户进程空间内改变过优先级的进程占用百分比
#id孔家CPU百分比,wa等待输入输出的CPU时间百分比
#hi CPU服务于硬件中断所消耗的时间总额,hard_interrupt
#si CPU服务软中断所消耗的时间总额,soft_interrupt
KiB Mem : 3861512 total, 1603888 free, 1169252 used, 1088372 buff/cache
#物理内存总量,空闲内容总量,使用的屋里内存总量,用作内核缓存的内存量
KiB Swap: 2097148 total, 2097148 free, 0 used. 2313272 avail Mem
#交换分区总量,空闲交换分区量,使用交换分区量,应用程序可用内存数
PID: 进程ID
USER:进程拥有者
PR:进程优先权
NI:进程nice值,代表这个进程的优先值
VIRT:申请的虚拟内存总量
RES:是进程使用物理内存的总和。
SHR:和其他进程共享的物理内存空间。
S:State(进程状态),有S=sleeping,R=running,T=stopped or traced,D=interruptible sleep(不可中断的睡眠状态),Z=zombie。
%CPU:CPU使用率
%MEM:物理内存的使用
TIME:进程占用的总共CPU时间
COMMAND:进程命令
topas是AIX的命令
vmstat命令
[root@docker_master ~]# vmstat 5 10
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 1390236 2116 1293856 0 0 92 98 792 2813 1 3 94 2 0
1 0 0 1389988 2116 1293884 0 0 0 830 1523 5168 1 2 97 0 0
0 0 0 1389988 2116 1293888 0 0 0 47 1470 5944 1 2 98 0 0
0 0 0 1389988 2116 1293888 0 0 0 114 1402 5623 0 2 98 0 0
0 0 0 1389816 2116 1293892 0 0 0 57 1477 5102 0 2 98 0 0
0 0 0 1389768 2116 1293896 0 0 0 73 1479 4870 1 2 97 0 0
0 0 0 1389608 2116 1293904 0 0 0 222 1497 4827 1 2 97 0 0
0 0 0 1389940 2116 1293940 0 0 0 50 1439 5251 1 2 97 0 0
0 0 0 1389212 2116 1293948 0 0 0 58 1507 5491 1 2 97 0 0
0 0 0 1389212 2116 1293956 0 0 0 111 1450 5779 1 2 98 0 0
#vmstat命令的两个参数,第一个是采样的时间间隔,第二个参数是采样的次数
| 类别 | 项目 | 含义 |
| Procs(进程) | r | 等待执行的任务数 |
| b | 等待IO的进程数 |
|
| Memory | swpd | 正在使用虚拟内存的大小 |
| free | 空闲内存大小 | |
| buff | 已用的buff大小,单位k对块设备的读写进行缓冲 | |
| cache | 已用的cache大小,文件系统的cache | |
| swap | si | 每秒从交换区写入内存的大小 |
| so | 每秒从内存写到交换分区的大小 | |
| io | bi | 每秒读取的块数(读磁盘);(块设备每秒接收的块数量,单位是block,这里的块设备是之系统上所有的磁盘和其他块设备,默认块大小是1024byte) |
| bo | 每秒写入的块数(块设备每秒发送的块数量,单位是block) | |
| system | in | 每秒中断数,包括时钟中断(这两个值越大,会看到由内核消耗的cpu的时间sy会越多) |
| cs | 每秒上下文切换数 | |
| CPU(数值以百分比表示) | us | 用户进程执行消耗CPU时间(user time);us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长时间超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
| sy | 系统进程消耗CPU时间(system time);sys的值过高时,说明系统讷河消耗的CPU资源越多,这是不良的表现,说明我们应该检查原因了。这里us+sy的参考值是80%,如果us+sy大于80%说明可能存在CPU不足。 | |
| id | 空闲时间(包括IO等待时间);一般来说us+sys+id=100 | |
| wa | 等待IO时间,wa过高是,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。 |
参考文章:https://blog.csdn.net/m0_38110132/article/details/84190319
iostat
[root@docker_master ~]# iostat Linux 3.10.0-957.5.1.el7.x86_64 (docker_master) 2019年03月15日 _x86_64_ (2 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 1.07 0.01 2.72 1.29 0.00 94.91 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn scd0 0.00 0.11 0.00 1028 0 sda 15.77 116.71 172.59 1069251 1581267 dm-0 15.98 112.92 170.90 1034595 1565768 dm-1 0.01 0.32 0.00 2972 0
单独执行iostat,显示的结果为从胸痛开机到当前执行命令时刻的统计信息:
Linux 3.10.0-957.5.1.el7.x86_64 (docker_master) 2019年03月15日 _x86_64_ (2 CPU)
系统版本,主机名,当前时间,CPU架构,CPU核数
avg-cpu: %user %nice %system %iowait %steal %idle
总体CPU使用情况统计信息,对于多核CPU,这里为所有CPU的平均值
%user:CPU在用户态执行进程的时间百分比
%nice:CPU在用户状态下,用于nice操作,所占用CPU总时间的百分比
%system:CPU处在内核状态执行进程的时间百分比
%iowait:CPU用于等待IO操作占用CPU总时间的百分比
%steal:管理程序hypervisor为另一个虚拟进程提供服务而等待虚拟CPU的百分比
%idle:CPU空闲时间百分比
注意项:%iowait的值过高,表示硬盘存在I/O瓶颈
%idle的值过高但胸痛相应慢时,有可能CPU等待分配内存,此时应加大内从容量
%idle的值持续低于1,则系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
Device:各磁盘设备IO统计信息。
tps:每秒向磁盘设备请求数据的次数,包括读、写请求,为rtps与wtps的总和。出于效率考虑,
每一次IO下发后并不是立即处理请求,二三十将请求合并(merge),这里tps指请求合并和的请求计数。
kB_read/s、kB_wrtn/s、kB_read、kB_wrtn的值均以kB为单位,相比山区数为单位,这里的值为原值的一半(1kB=512bytes*2)
free命令:
| Mem | total:表示物理内存总量。 |
| used | 表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用。 |
| free | 未被分配的内存 |
| shared | 共享内存,一般系统不会用到,这里也不讨论。 |
| buffers | 系统分配但未被使用的buffers 数量。 |
| cached | 系统分配但未被使用的cache 数量。buffer 与cache 的区别见后面。 total = used + free 第2行 -/+ buffers/cached: used:也就是第一行中的used - buffers-cached 也是实际使用的内存总量。 |
| free | 未被使用的buffers 与cache 和未被分配的内存之和,这就是系统当前实际可用内存。 free 2= buffers1 + cached1 + free1 //free2为第二行、buffers1等为第一行 |
| buffer 与cache 的区别 | A buffer is something that has yet to be “written” to disk. A cache is something that has been “read” from the disk and stored for later use |
参考:https://www.cnblogs.com/pengdonglin137/p/3315124.html
mpstat是Multiprocessor Statistics的缩写,能实时监控系统。其报告关于CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。mpstat最大的特点是:可以查看多核心CPU中每个计算核心的统计数据;而类似工具vmstat只能查看系统整体cpu情况。
[root@docker_master ~]# mpstat 1 2 Linux 3.10.0-957.5.1.el7.x86_64 (docker_master) 2019年03月16日 _x86_64_ (2 CPU) 09时43分40秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 09时43分41秒 all 0.52 0.00 3.09 0.00 0.00 0.00 0.00 0.00 0.00 96.39 09时43分42秒 all 0.52 0.00 1.55 0.00 0.00 0.00 0.00 0.00 0.00 97.94 平均时间: all 0.52 0.00 2.32 0.00 0.00 0.00 0.00 0.00 0.00 97.16
网络分析工具iptraf-ng:
首先系统不带此命令需安装此命令
yum -y intall iptraf-ng
安装完成后输入命令iptraf-ng弹出对话框如下:
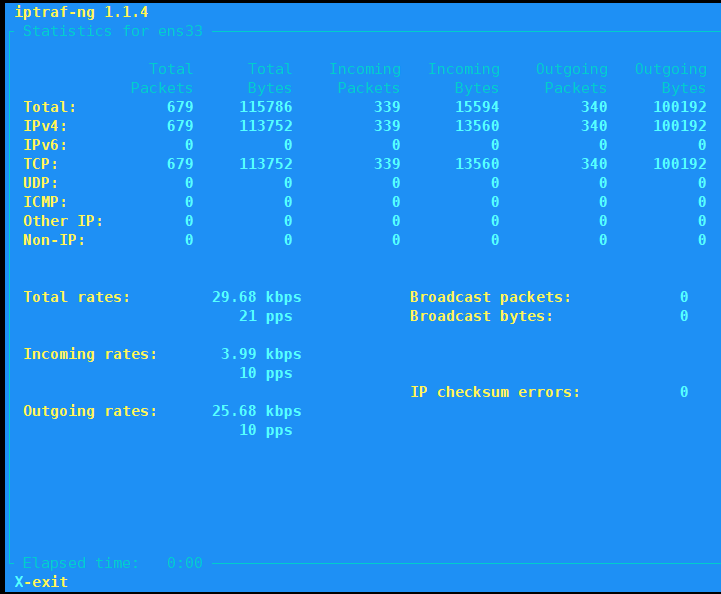
Detailed interface statistics----->ens33
操作系统性能收集与分析之nmon:
nmon是一种在AIX与linux操作系统广泛使用的监控与分析工具,相对于其它一些系统资源监控工具来说,nmon所记录的信息是比较全面的,它能在系统运行过程中实时地捕捉系统资源使用情况,并且能输出结果到文件中,然后再通过nmon_analyzer工具产生数据文件与图形化结果。