在逝去的2016后半年,由于项目需要支持数据的快速更新和多用户的高并发负载,我试水SQL Server 2016的In-Memory OLTP,创建内存数据库实现项目的负载需求,现在项目接近尾声,系统运行稳定,写一篇博客,记录一下使用内存数据库的经验。
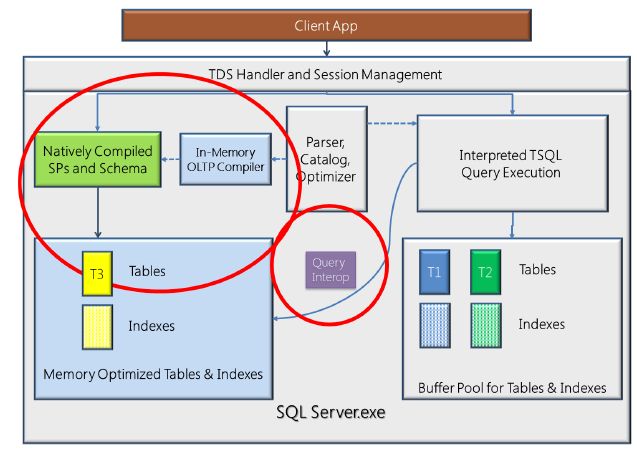
SQL Server 2016的In-Memory OLTP,通俗地讲,是内存数据库,使用内存优化表(Memory-Optimized Table,简称MOT)来实现,MOT驻留在内存中,使用 Hekaton 内存数据库引擎访问。在查询MOT时,只从内存中读取数据行,不会产生Disk IO消耗;在更新MOT时,数据的更新直接写入到内存中。内存优化表能够在Disk上维护一个数据副本,该副本只用于持久化数据,不用于数据读写操作。
在内存数据库中,不是所有的数据都需要存储在内存中,有些数据仍然能够存储在Disk上,硬盘表(Disk-Based Table,简称DBT)是传统的表存储结构,每个Page是8KB,在查询和更新DBT时,产生Disk IO操作,将数据从Disk读取到内存,或者将数据更新异步写入到Disk中。
内存数据库将原本存储在Disk上的数据,存储在内存中,利用内存的高速访问优势实现数据的快速查询和更新,但是,内存数据库,不仅仅是存储空间的变化,Hekaton 内存数据库访问引擎实现本地编译模块(Natively compiled),交叉事务(Cross-Container Transaction)和查询互操作(Query Interop):
- 本地编译模块:如果代码模块只访问MOT,那么可以将该模块定义为本地编译模块,SQL Server直接将TSQL脚本编译成机器代码;SQL Server 2016支持本地编译的模式有:存储过程(SP),触发器(Trigger),标量值函数(Scalar Function)或内嵌多语句函数(Inline Multi-Statement Function)。相比于解释性(Interpreted)TSQL 模块,机器代码直接使用内存地址,性能更高。
- 交叉事务:在解释性TSQL模块中,一个事务既能访问硬盘表,也能访问内存优化表;实际上,SQL Server创建了两个事务,一个事务用于访问硬盘表,一个事务用于访问内存优化表,在DMV中,分别使用transaction_id 和 xtp_transaction_id 来标识。
- 查询互操作:解释性TSQL脚本能够访问内存优化表和硬盘表,本地编译模块只能访问内存优化表。
内存数据被整合到SQL Server关系引擎中,使用内存数据库时,客户端应用程序甚至感受不到任何变化,DAL接口也不需要做任何修改。由于Query Interop的存在,任何解释性TSQL脚本都能透明地访问MOT,只是性能没有本地编译TSQL脚本性能高。在使用分布式事务访问MOT时,必须设置合适的事务隔离级别,推荐使用Read Committed,如果发生MSSQLSERVER_41333 错误,说明产生交叉事务隔离错误(CROSS_CONTAINER_ISOLATION_FAILURE),原因是当前事务的隔离级别太高。
一,创建内存数据库
内存优化表的数据必须存储在包含Memory_Optimized_Data的File Group中,该FileGroup可以有多个File,每个File实际上是Folder,一个DB只能创建一个包含Memory_Optimized_Data的File Group。
step1,创建一个数据库,创建的Data File的数量最好和CPU内核数量保持一致,存放在不同的物理磁盘上;


use master go --Create database create database Test_MemboryDB on Primary ( name=Test_MemoryDB_1, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_1.mdf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_2, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_2.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_3, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_3.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_4, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_4.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_5, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_5.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_6, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_6.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_7, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_7.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_8, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_8.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_9, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_9.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_10, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_10.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_11, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_11.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_12, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_12.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_13, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_13.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_14, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_14.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_15, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_15.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_16, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_16.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_17, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_17.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_18, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_18.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_19, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_19.ndf', size=5GB, FileGrowth=1GB ), ( name=Test_MemoryDB_20, filename='D:\Program Files\Microsoft SQL Server\Test_MemoryDB_20.ndf', size=5GB, FileGrowth=1GB ) LOG ON ( name = N'Test_MemboryDB_log', filename = N'D:\Program Files\Microsoft SQL Server\Test_MemboryDB_log.ldf' , size = 10GB , filegrowth = 1GB ) GO
step2,为数据库创建一个包含内存优化数据的FileGroup,向该FileGroup中添加“File”,实际上是目录(Directory),用于存储内存优化数据文件,主要是CheckPoint文件,用于还原持久化的内存优化表。

-- Add File Group from memory-optimized data alter database [Test_MemboryDB] add filegroup fg_MemoryOptimizedData contains MEMORY_OPTIMIZED_DATA; alter database [Test_MemboryDB] add file ( name=Test_MemboryDBDirectory, filename='D:\Program Files\Microsoft SQL Server\Test_MemboryDBDirectory' ) to FILEGROUP fg_MemoryOptimizedData;
文件组属性:CONTAINS MEMORY_OPTIMIZED_DATA 子句,指定File Group用于存储内存优化表数据,每个数据库只能指定一个存储内存优化数据的File Group,可以在该File Group下创建多个Directory,分布在不同的物理Disk上,加快内存优化表数据还原的速度。
二,创建内存优化表
内存优化表用于存储用户数据,可以持久化存储,数据存储在内存中,同时,在Disk上维护数据的一个副本,通过选项 DURABILITY= SCHEMA_AND_DATA 指定持久化存储内存优化表;也可以只存储在内存中,通过选项DURABILITY= SCHEMA_ONLY指定。在内存优化表上,可以创建nonclustered index 或nonclustered hash index,每个内存优化表中至少创建一个Index。
--create memory optimized table create table [dbo].[products] ( [ProductID] [bigint] not null, [Name] [varchar](64) not null, [Price] decimal(10,2) not null, [Unit] varchar(16) not null, [Description] [varchar](max) null, constraint [PK__Products_ProductID] primary key nonclustered hash ([ProductID])with (bucket_count=2000000) ,index idx_Products_Price nonclustered([Price] desc) ,index idx_Products_Unit nonclustered hash(Unit) with(bucket_count=40000) ) with(memory_optimized=on,durability= schema_and_data) go
1,内存优化:MEMORY_OPTIMIZED
[MEMORY_OPTIMIZED = {ON | OFF}]
默认值是OFF,指定创建的表是硬盘表;设置选项MEMORY_OPTIMIZED为ON,指定创建的表是内存优化表;
2,持久性:Durability
DURABILITY = {SCHEMA_ONLY | SCHEMA_AND_DATA}
默认值是SCHEMA_AND_DATA,指定创建的内存优化表是持久化的,这意味着,数据更新会持久化存储到Disk上,在SQL Server重启之后,内存优化表的数据能跟根据存储在Disk上的副本还原。选项 SCHEMA_ONLY 指定创建的内存优化表是非持久化的,这意味着Table Schema是持久化存储到Disk上,但是,任何数据更新都不会持久化到Disk上,在SQL Server重启之后,内存优化表的数据会丢失。
3,哈希索引和范围索引
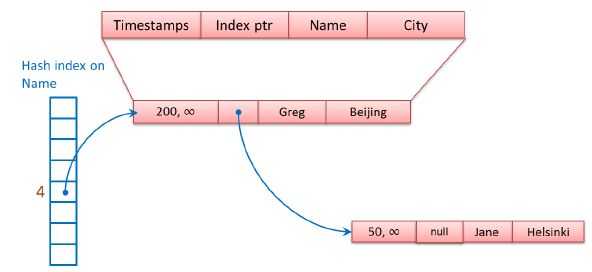
内存优化表支持Hash Index,属性 BUCKET_COUNT 指定为Hash Index创建的bucket的数量,一般hash bucket的数量是数据行的1-2倍,如果无法估计bucket的数量,请创建范围索引(NonClustered Index),索引结构是Bw-Tree。
Hash 索引由一个数组和多个数据行链组成,每一个数组元素叫做一个Hash Bucket,通过内置的Hash函数,将Hash索引的Key映射到Hash Bucket上,例如,如果Hash Index的Key是(Col1,Col2),根据HashFunction(Col1,Col2)返回的Hash Value,将数据行映射到指定的Hash Bucket上;如果多个Key映射到同一个Hash Bucket上,那么这些Key组成一个链。例如:数据表结构是(Name,City),在Name字段上创建Hash Index,Hash值相同的数据行链接成一个单向链。
三,创建Natively Compiled SP
本地编译SP在创建时编译成机器代码,整个SP以原子方式执行,这意味着,以SP为单位,整个SP中的所有操作是一个原子操作,要么执行成功,要么执行失败。
create procedure dbo.usp_GetProduct @ProductID bigint not null with native_compilation, schemabinding, execute as owner as begin atomic with (transaction isolation level = snapshot, language = N'US_English') select [ProductID] ,[Name] ,[Price] ,[Unit] ,[Description] from [dbo].[Products] where ProductID=@ProductID end go
1,在本地编译SP中,能够为参数,变量指定Nullability属性,默认值是NULL
NOT NULL 属性:不能为参数或变量指定NULL值,
- 在本便编译SP中,为参数指定NOT NULL属性,不能为参数指定NULL值;
- 在本便编译SP中,为变量定义NOT NULL属性,必须在Declare时初始化变量;
2,本地编译SP必须包含两个选项:SCHEMABINDING 和 ATOMIC Block
- SCHEMABINDING:绑定引用的内存优化表
- ATOMIC Block:在原子块中的所有语句,以单个事务运行;在事务成功时,所有语句都提交成功;在事务失败时,所有语句都回滚。Atomic Bloc保证原子地执行SP,如果SP在其他事务的上下文中被调用,那么该SP开始一个新的事务。
- Atomic blocks guarantee atomic execution of the stored procedure. If the procedure is invoked outside the context of an active transaction, it will start a new transaction, which commits at the end of the atomic block.
使用Atomic Block必须设置两个选项:
- TRANSACTION ISOLATION LEVEL:指定Atomic Block开启事务的隔离级别,通常指定Snapshot隔离级别;
- LANGUAGE:指定SP上下文的语言;
3,解释型SP和本地编译SP的区别
解释性SP能够访问硬盘表(Disk-Based Table)和内存优化表(Memory-Optimized Table),其真正的区别是解释性(Interpreted)SP在第一次执行时编译,而本地编译(Natively Compiled)SP是在创建时编译,并且直接编译成机器代码,绑定的是内存地址。
4,延迟持久化
在本地编译SP中,设置Atoic Block的选项:DELAYED_DURABILITY = ON ,使SP对内存优化表的更新操作,以异步写事务日志方式,延迟持久化到Disk,这意味着,如果内存优化表维护了一个Disk-Based 的副本,数据在内存中修改之后,不会立即更新到Disk-Based 的副本中,这有丢失数据的可能性,但是能够减少Disk IO,提高数据更新的性能。
四,使用内存优化的表变量和临时表
传统的表变量和临时表,都使用tempdb存储临时数据,而tempdb不是内存数据库,使用Disk存储临时表和表变量的数据,会产生Disk IO和竞争,SQL Server提供了内存优化的表变量,将临时数据存储在内存中,详细信息,请参考我的博客:《In-Memory:在内存中创建临时表和表变量》。
五,在内存数据库中使用JSON
自从使用JSON之后,我的第一感概是:数据库岂能没有JSON,不管是数据库将值传递前端,还是前端将数据传递到数据库,使用JSON方便很多,相比XML,JSON的使用简单很多,详细信息,请参考我的博客:《使用TSQL查询和更新 JSON 数据》
六,内存数据库的事务处理
交叉事务是指在一个事务中,解释性TSQL语句同时访问内存优化表(Memory-Optimized Table,简称MOT)和硬盘表(Disk-Based Table,简称DBT)。在交叉事务中,访问MOT的操作和访问DBT的操作都拥有自己独立的事务序号,就像在一个大的交叉事务下,存在两个单独的子事务,分别用于访问MOT和DBT;在sys.dm_db_xtp_transactions (Transact-SQL)中,访问DBT的事务使用transaction_id标识,访问MOT的事务序号使用xtp_transaction_id标识。详细信息,请参考我的博客:《In-Memory:内存优化表的事务处理》
参考文档:
sqlserver2014内存数据库特性介绍
In-Memory OLTP (In-Memory Optimization)
Introduction to Memory-Optimized Tables
Natively Compiled Stored Procedures
Memory-Optimized Tables
试试SQLSERVER2014的内存优化表
SQLServer 2014 内存优化表
SQL Server 2014 内存优化表(1)实现内存优化表