注:参考《JavaScript语言精粹》第七章和第八章。
一、正则表达式的概念,作用
1.概念:正则表达式是一门简单语言的语法规范。
2.作用:它以方式的形式被用于对字符串中的信息进行查找,替换和提取的操作。js中可处理正则表达式的方式有regexp.exec(),regexp.test(),string.match(),string.replace(),string.search()和string.split()。关于这些方法将在本篇最后一节详述。通常来说,在js中正则表达式相较于等效的字符串运算有着显著的性能优势。
二、学习正则表达式
我先大体介绍下正则表达式的结构以及创建方式(2.1小节),然后把整个正则表达式拆开来看,分别在之后的小节介绍。最后再组合在一起举个小例子(第三节)大概就能逐渐清晰起来。
2.1 正则表达式结构,创建方式
1.创建方式(2种):
① 正则表达式字面量(性能更好,优先使用)
正则表达式字面量被包围在一对斜杠中,例如:
let regex = /abc+/; //{1}
let regex = /[a-z]+_[0-9]+/gi; //{2}
{1}中展示了命名正则表达式的字面量写法,ab+c这一个正则表达式被包裹在一对斜杠中。
{2}中的正则表达式字面量的斜杠后有两个字母:gi,这里说明一下,它们是正则表达式的匹配模式的标志。一种有3个匹配模式的标志能在RegExp中设置,他们分别是:g、i、m。它们代表的意思如下:
| 标志 | 含义 |
|---|---|
| g | 全局匹配(对一个字符串进行多次匹配,准确含义随方法而变) |
| i | 匹配时大小写不敏感(忽略大小写) |
| m | 多行匹配(^和$能匹配行结束符) |
这里来举个例子来分别说明一下(说明,我使用的测试方法是JavaScript中String的match方法,使用浏览器的console作为代码运行环境):
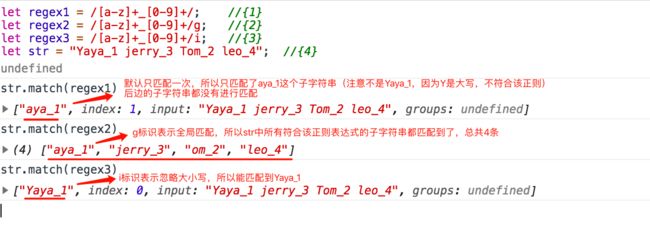
let regex1 = /[a-z]+_[0-9]+/; //{1}
let regex2 = /[a-z]+_[0-9]+/g; //{2}
let regex3 = /[a-z]+_[0-9]+/i; //{3}
let str = "Yaya_1 jerry_3 Tom_2 leo_4"; //{4}
{1}是匹配 至少一个任意小写字母 加 一个下划线 加 至少一个任意数字(如abc_123) 这样的形式。{2},{3}相较于{1}分别是多了g,i的标志(m标志的例子在后边)。
那么拿{4}的字符串分别与{1},{2},{3}匹配,则匹配结果分别如下图所示:
let regex1 = /^[a-z]+_[0-9]+/; //{1}
let regex2 = /^[a-z]+_[0-9]+/g; //{2}
let regex3 = /^[a-z]+_[0-9]+/m; //{3}
let str1 = "frank_5 tony_6 jason_7"; //{4}
let str2 = ["I am the first line", "frank_5 tony_6 jason_7"].join('\n'); //{5}
详细解释以及结果见下图:

② 使用RegExp构造器(不推荐)
这个构造器会接收一个字符串,并把它编译为一个RegExp对象。第二个参数接收指定标志的字符串,例如:
let regex = new RegExp("abc+");
let regex = new RegExp(/^[a-zA-Z]+[0-9]*\W?_$/, "gi"); //{1}
let regex = new RegExp("^[a-zA-Z]+[0-9]*\\W?_$", "gi"); //{2}
这里需要注意,因为反斜杠在正则表达式和在字符串字面量中有一些不同的含义,所以在书写时需要小心,通常情况下需要双写反斜杠,请看{1}{2}的区别。所以通常情况下不推荐使用RegExp构造器这种方式来创建一个正则表达式。
接下来我们开始详细拆分讲述正则表达式。
2.2 正则表达式分支
正则表达式分支也就是“或”的意思,用符号|表示。如果这些分支条件中有任何一项满足匹配条件,那么就符合。例如以下代码能匹配first或者second,所以不管是{1}还是{2},该正则表达式都能匹配到(注意这个正则有个i的标志,所以匹配的时候会忽略大小写)。
let regex = /first|second/i;
let str1 = "First, I will tell you …"; //{1}
let str2 = "and second, I will …"; //{2}
这里的{1},{2}都有一个子字符串会被匹配,如图所示。

2.3 正则表达式因子
正则表达式拆开来看也就是很多个因子和量词的组合,因子是决定该正则需要匹配的字符都可以有哪些,而量词是决定该量词前面的因子可以匹配多少次(具体见2.7小节)。
而正则表达式因子可以是这四种类型:
1.一个字符(除了特殊字符之外的任意普通字符,如a、b、c、0、1、2、#、%、&等等)

2.一个正则转义(详见2.5节)
3.一个字符类(详见2.4节)
4.一个由圆括号包围的组(详见2.6节)
2.4 正则表达式字符类
1.概念:正则表达式字符类是一种指定一组字符的便利方式,也就是说正则在匹配的时候可以匹配这个字符类中的任意一个字符都可以。例如想匹配任意元音字母中的任意一个字符,我们可以写成a|e|i|o|u,但通常我们可以更方便的写成一个类:[aeiou]
2.类的两个好处:
1.可以指定字符范围:例如/[a-z]+_[0-9]+/,我们可以方便的指定a-z,0-9,(这里的-代表范围的意思,指az,09)但如果用分支的话就要麻烦了。
2.方便类的求反:如果要匹配除了[a-z]之外的所有字符,则可以用字符类方便的写为[^a-z],那么这里字符类中的^则代表取反的意思
3.注意:在字符类中需要被转义的特殊字符:- / [ \ ] ^
2.5 正则表达式转义
正则表达式中一些转义字符存在特殊的含义,以下列出一些常用的:
| 转义字符 | 含义 |
|---|---|
| \d | 匹配一个数字。 等价于[0-9] |
| \D | 与\d相反。匹配一个非数字字符。等价于[^0-9] |
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \s | 等同于 [\f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff]。是Unicode空白符的不完全子集。 |
| \S | 与\s相反。等同于[^\f\n\r\t\v\u00a0\u1680\u180e\u2000-\u200a\u2028\u2029\u202f\u205f\u3000\ufeff],表示非空白字符。 |
| \t | 匹配一个水平制表符 |
| \v | 匹配一个垂直制表符 |
| \w | 等同于[0-9A-Z_a-z]。 匹配一个单字字符(字母、数字或者下划线)。 |
| \W | 与\w相反。等同于[^0-9A-Z_a-z] |
| \b | 匹配一个词的边界。它是利用\w去寻找边界的 |
| \n(注:这里的n代表一个数字) | 在正则表达式中,它代表正则中的第n个组所对应的最后捕获到的子字符串(关于组的概念详见2.5小节) |
2.6 正则表达式分组
因子的前3种类型(见2.2小节)都是匹配一个字符,但分组可以匹配多个字符,也就是说分组可以匹配字符串。
正则表达式分组有4种类型(注:以下x,y都代表一小段正则表达式):
1.捕获型:捕获型分组是这样的格式:(x),也就是说一个捕获型分组是一个被包围在圆括号中的一小段正则表达式。之所以为捕获型,是因为任何匹配这个分组的字符都会被捕获到。每个捕获型分组都会有一个数字代号,很简单:第1个捕获的分组就是分组1,第2个捕获的分组是分组2,以此类推。
2.非捕获型:非捕获型分组是这样的格式:(?:x),也就是说与捕获型分组相比,它的圆括号中有一个?:的前缀。非捕获型分组仅做简单的匹配,并不会捕获匹配的文本。
3.向前正向匹配:向前正向匹配是这样的格式:x(?=y),匹配'x'仅仅当'x'后面跟着’y’,但是注意,它的意思只是检查x后边跟的是不是y,如果是y,那么匹配x,而y并没有被真正匹配。但y才是真正的分组中的内容,也就是说这个分组什么都没有匹配,只是一个检验的作用。这并不是一个好的特性,不常用。
4.向前负向匹配:向前负向匹配是这样的格式:x(?!y),匹配'x'仅仅当'x'后面不跟着’y’,但是注意,它的意思只是检查x后边跟的是不是y,如果不是y,那么匹配x,而y并没有被真正匹配。但y才是真正的分组中的内容,也就是说这个分组什么都没有匹配,只是一个检验的作用。这并不是一个好的特性,不常用。
2.7 正则表达式量词
1.解释:量词后缀用来决定前面的因子应该被匹配的次数。
2.写法:通常情况下量词的写法是将数字或者数字范围包裹在一对大括号中。如{3,5}表示最少3次最多5次;{3,}表示最少3次;{3}表示3次。还有一些特殊字符也可以代表匹配次数:?相当于{0,1};*相当于{0,};+相当于{1,}。如果一个因子后边没有量词后缀,则默认匹配该因子1次。
三、一个例子
var parse_url = /^(?:(http|ftp|https):)?(?:\/{0,3})([0-9.\-A-Za-z]+)(?::(\d+))?(?:\/([^?#]*))?(?:\?([^#]*))?(?:#(.*))?$/;
我们把该正则表达式拆开来看:
^匹配字符串开始的地方,表示该字符串开始。
(?:(http|ftp|https):)?匹配一个非捕获型分组:在这个非捕获分组里又有一个捕获分组,这个分组匹配的内容是http或ftp或https。捕获分组结束后再匹配一个冒号,?代表这个它前面的因子(也就是那个非捕获分组)可以被匹配0次或1次。那么字符串http:或ftp:或https:或空字符串都能与这一小段正则匹配。
(?:\/{0,3})匹配一个非捕获型分组:匹配内容是字符串/,由于/是特殊字符,所以需要转义。/这个因子被匹配的次数可以是0次到3次。那么字符串/或//或///或空字符串都能与这一小段正则匹配。
([0-9.\-A-Za-z]+)匹配一个捕获型分组:匹配内容是由一个字符类组成的,匹配字符可以是字符类中的这些字符:0-9 . - A-Z a-z 。这个字符类被匹配的次数可以是1次到多次。那么例如字符串a.b_c a 0_e 等等很多都能与这一小段正则匹配。这一小段在整个正则中是用来匹配域名或ip地址(host)的,例如www.baidu.com
(?::(\d+))?匹配一个非捕获分组:先匹配一个冒号: ,然后匹配至少一个数字的捕获型分组。?代表这个非捕获型分组的匹配次数可以是0次或1次。这一小段在整个正则中是用来匹配端口号(port)的。
(?:\/([^?#]*))?匹配一个非捕获分组:先匹配一个/,之后的字符类[^?#]以^开始,它表示这个字符类包含除了?和#之外的所有字符,*表示这个字符集可以被匹配0次或多次。?表示这个非捕获分组会匹配0次或1次。这一小段是用来匹配url中的路径(path)的。
(?:\?([^#]*))?匹配一个非捕获分组:先匹配一个?,之后的字符类[^#]以^开始,它表示这个字符类包含除了#之外的的所有字符,*表示这个字符集可以被匹配0次或多次。?表示这个非捕获分组会匹配0次或1次。这一小段是用来匹配url中的参数(query)的。
(?:#(.*))?匹配一个以#开始的可选分组,.会匹配除行结束符之外的所有字符。这一小段是用来匹配url中的锚(hash)的。
$匹配字符串结束的地方。表示该字符串结束。
四、js对于正则表达式的支持
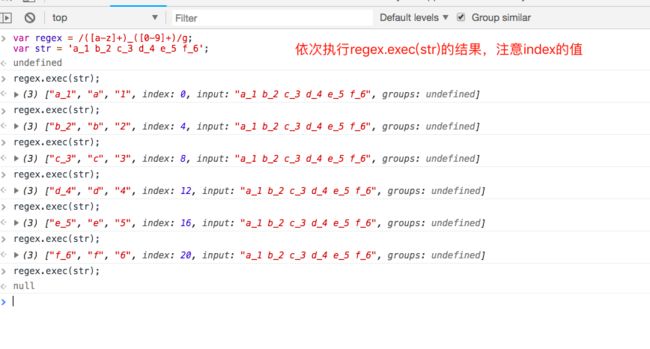
4.1 regexp.exec(string)
exec方法是使用正则表达式最强大(和最慢)的方法。如果它成功的匹配regexp和字符创string,它会返回一个数组,数组下标为0的元素将包含正则表达式regexp匹配的子字符串。下标为1的元素是第一个捕获分组匹配的文本,下标为2的元素是第二个捕获分组匹配的文本,以此类推。如果匹配失败,他会返回null。
如果regexp带有g标识,那么查找不是从这个字符串的起始位置开始的,而是从regexp.lastIndex(初始值为0)的位置开始的。如果匹配成功,那么regexp.lastIndex将被设置为该匹配后第一个字符的位置。不成功的匹配会重置regexp.lastIndex为0。这就说明当regexp带有g标识时,你可以循环调用exec。但有两件事情需要注意:1.如果提前退出了这个循环,再次进入循环前要把regexp.lastIndex重置到0;2.^仅匹配regexp.lastIndex为0的情况。
例子:

4.2 regexp.test(string)
test方法是使用正则表达式最简单(和最快)的方法。如果该regexp匹配string,则返回true,否则返回false。注意:不要对这个方法使用g标识,原因是g标识每次会改变regexp.lastIndex的值,见下图:

4.3 string.match(regexp)
match方法让字符串和一个正则表达式进行匹配。它根据g标识来决定如何进行匹配。如果没有g标识,那么调用string.match(regexp)的结果与调用regexp.exec(string)的结果相同。如果regexp带有g标识,那么它生成一个包含所有匹配(除捕获分组之外)的数组。

4.4 string.replace(searchValue, replaceValue)
replace方法对string进行查找和替换操作,并返回一个新的字符串。searchValue可以是一个字符串或一个正则表达式对象。如果他是一个字符串,那么searchValue只会在第1次出现的地方被替换。所以下边代码的结果是:you-are_beautiful
var result = "you_are_beautiful".replace('_', '-');
如果searchValue是一个正则表达式并且带有g标识,那么他会替换所有的匹配。如果没有带有g标识,那么它仅仅替换第一个匹配。
replaceValue可以是一个字符串,也可以是一个自定义函数。如果replaceValue是一个字符串,那么字符$拥有特别的含义:
var oldareacode = /\((\d{3})\)/g;
var p = '(555)666-1234'.replace(oldareacode, '$1-'); //p 是 '555-666-1234'
如果replaceValue是一个函数,那么每遇到一次匹配函数就会被调用一次,该函数返回的字符串会被用作替换文本。传递给该函数的第一个参数数被匹配的文本,第二个参数是分组1捕获的文本,第三个参数是分组2捕获的文本,以此类推。

4.5 string.search(regexp)
search方法和indexOf方法类似,只是它接受一个正则表达式作为参数而不是一个字符串。如果找到匹配,它返回第1个匹配的首字符位置,如果没有找到匹配,它返回-1.此方法会忽略g标识。
var text = 'and he says "Any damn fool could';
var pos = text.search(/["']/); // pos 是12
4.6 string.split(separator, limit)
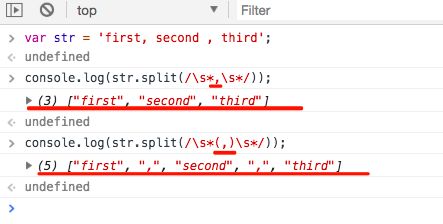
split方法把这个string分割成片段来创建一个字符串数组。可选参数limit可以限制被分隔的片段数量。separator可以是一个字符串或一个正则表达式。此方法会在string中查找所有separator出现的地方,以此作为分隔符。此方法会忽略g标识,加不加g标识都一样。
var ip = '192.168.0.1';
var b = ip.split('.'); // b是['192','168','0','1']
但有一点需要注意,捕获分组的文本会被包含在分割后的数组中: