事情的起因是这样的,由于我想找几部经典电影欣赏欣赏,于是便向某老司机寻求资源(我备注了需要正规视频,绝对不是他想的那种资源),然后他丢给了我一个视频资源网站,说是比较有名的视频资源网站。我信以为真,便激动地点开寻求经典电影,于是便引出了一段经典的百度网盘之战。
免责申明:文章中的工具等仅供个人测试研究,请在下载后24小时内删除,不得用于商业或非法用途,否则后果自负,文章出现的截图只做样例演示,请勿非法使用
先来看下这个视频网站的截图:

不得不说,这是一个正规的网站,正规的视频,只是看着标题的我想多了而已。
怀着满满的求知欲,我点开了链接,并在网页下方看到了视频资源链接。
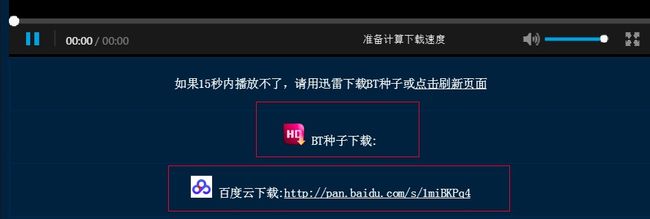
这里有2种资源,一种是百度网盘,另一种是迅雷种子,不得不说这个网站还是比较良心,相较于只发图不留种的某些网站。按照正常逻辑,此时我应该点开资源地址静静地欣赏起来(不对,其实我不是那样的人),因此我选择默默地将资源添加到网盘收藏。看到网盘又多了几部佳作,心情顿时爽了很多,但仅仅添加几部作品并没有满足我的收藏欲望,于是我便开始探索如何快速将视频资源自动添加到百度网盘,也由此引发了我对于百度网盘的一系列斗争。
战争序幕
首先通过观察该网站url构成,以及网页源码组成,我决定采用爬取的方式采集资源链接地址。
网页截图:
该过程并没有遇到很大的问题,我采用了python+协程的方式进行采集,很快便获取了一部分资源地址:
百度网盘资源地址: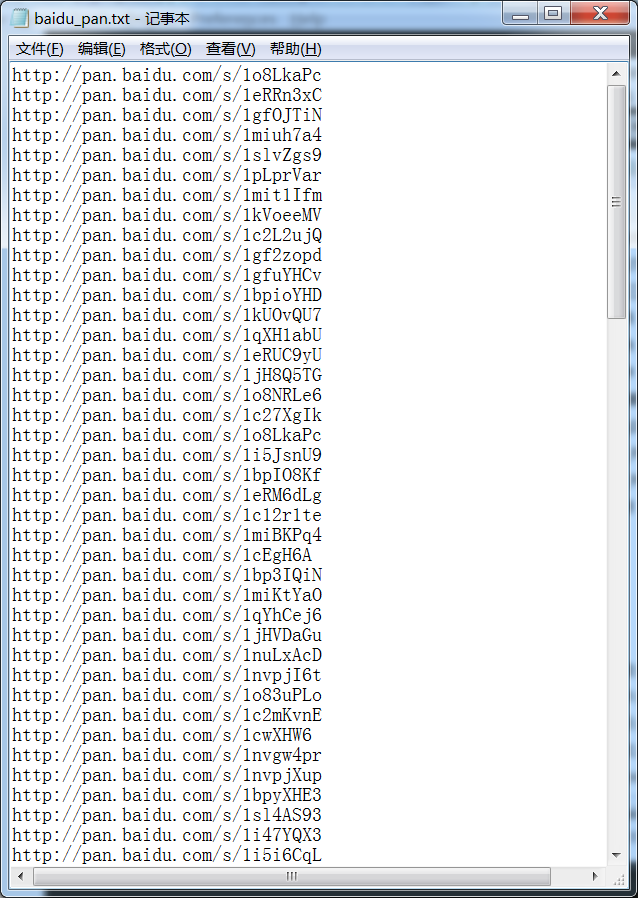
写完采集数据脚本,采集完部分数据已是晚上11点,原本应该洗洗睡了,然而技术探索的力量鼓舞着我继续前行。目前资源地址都有了,然而对于百度网盘资源,仍然需要一一点开,然后添加到我的网盘,此步骤太耗费精神,因此我决定继续挖掘自动添加资源到百度网盘的方法。
注意:以下内容是本文的重点技术内容,关乎着我与百度网盘一战的最终结局,请勿走开,精彩继续。
终极之战
首先我通过抓包,查看源码,审查元素等方式分析了百度分享页面的特征,判断其是否适合爬虫方式。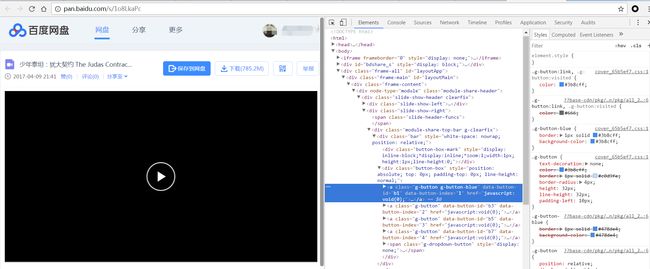
在经过一系列测试之后,我发现虽然过程有点曲折,但还是可以用爬虫的方式实现自动化的添加资源到网盘。
要实现这一技术,我总结了以下几点流程:
- 获取用户cookie(可以手动登录然后抓包获取)
- 首先爬取如:http://pan.baidu.com/s/1o8LkaPc网盘分享页面,获取源码。
- 解析源码,筛选出该页面分享资源的名称、shareid、from(uk)、bdstoken、appid(app_id)。
- 构造post包(用来添加资源到网盘),该包需要用到以上4个参数+cookies。
获取cookie
抓取cookie可以用很多工具,我用了火狐的Tamper插件,效果如下:
获取登录的数据包: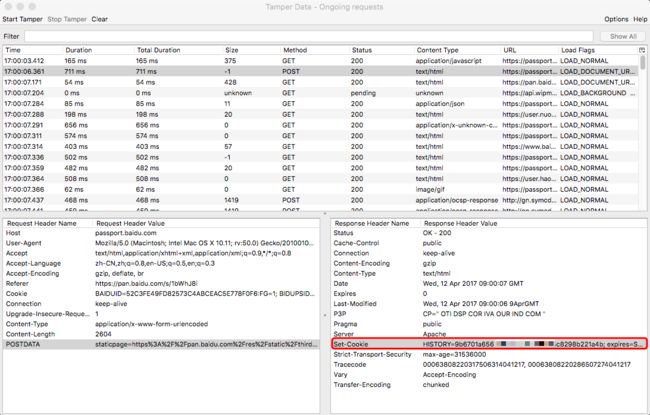
查看登录发送的请求包,发现有账号密码,当然我们这里需要的是cookie,可以在response中查看到。
cookie的格式如下:
BAIDUID=52C3FE49FD82573C4ABCEAC5E77800F6:FG=1;
BIDUPSID=52C11E49FD82573C4ABCEAC5E778F0F6;
PSTM=1421697115; PANWEB=1; Hm_lvt_7a3960b6f067eb0085b7196ff5e660b0=1491987412; Hm_lpvt_7a3960b6f067eb0085b7f96ff5e6260b0=1491988544;
STOKEN=3f84d8b8338c58f127c29e3eb305ad41f7c68cefafae166af20cfd26f18011e8;
SCRC=4abe70b0f9a8d0ca15a5b9d2dca40cd6;
PANPSC=16444630683646003772%3AWaz2A%2F7j1vWLfEj2viX%2BHun90oj%2BY%2FIsAxoXP3kWK6VuJ5936qezF2bVph1S8bONssvn6mlYdRuXIXUCPSJ19ROAD5r1J1nbhw55AZBrQZejhilfAWCWdkJfIbGeUDFmg5zwpdg9WqRKWDBCT3FjnL6jsjP%2FyZiBX26YfN4HZ4D76jyG3uDkPYshZ7OchQK1KQDQpg%2B6XCV%2BSJWX9%2F9F%2FIkt7vMgzc%2BT;
BDUSS=VJxajNlVHdXS2pVbHZwaGNIeWdFYnZvc3RMby1JdFo5YTdOblkydkdTWlVmUlZaSVFBQUFBJCQAAAAAAAAAAAEAAAA~cQc40NLUy7XEwbm359PwABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFTw7VhU8O1Yb
由于此cookie涉及到个人账号,因此我做了改动处理,但格式应该是一样的。
访问百度资源分享页面
请求页面如:http://pan.baidu.com/s/1o8LkaPc
获取cookie以后,可以在访问百度资源分享页面时,在headers里面写入cookie值,并使用该cookie登录,期间我也失败过几次,原因还是需要加上其他header参数(如果不加cookie参数,返回的结果将是”页面不存在”)。
请求成功之后,我们可以在源码中找到一些我们需要的内容,比如页面分享资源的名称、shareid、from(uk)、bdstoken、appid(app_id)值。
构造添加资源POST包
首先看下post包的构造:
POST https://pan.baidu.com/share/transfer?shareid=2337815987&from=1612775008&bdstoken=6e05f8ea7dcb04fb73aa975a4eb8ae6c&channel=chunlei&clienttype=0&web=1&app_id=250528&logid= HTTP/1.1
Host: pan.baidu.com
Connection: keep-alive
Content-Length: 169
Accept: */*
Origin: https://pan.baidu.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Referer: https://pan.baidu.com/s/1kUOxT0V?errno=0&errmsg=Auth%20Login%20Sucess&&bduss=&ssnerror=0
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.8,en;q=0.6
Cookie:
filelist=["/test.rar"]&path=/
在post包的url中有一些参数,填写我们获取到的内容即可,还有一个logid参数,内容可以随便写,应该是个随机值然后做了base64加密。
在post包的payload中,filelist是资源名称,格式filelist=[“/name.mp4”],path为保存到那个目录下,格式path=/pathname
cookie必须填上,就是之前我们获取到的cookie值。
最终返回内容
{"errno":0,"task_id":0,"info":[{"path":"\/\u5a31\u4e50\u6e38\u620f\/\u4e09\u56fd\u5168\u6218\u6218\u68cb1.4\u516d\u53f7\u7248\u672c.rar","errno":0}],"extra":{"list":[{"from":"\/\u5a31\u4e50\u6e38\u620f\/\u4e09\u56fd\u5168\u6218\u6218\u68cb1.4\u516d\u53f7\u7248\u672c.rar","to":"\/\u4e09\u56fd\u5168\u6218\u6218\u68cb1.4\u516d\u53f7\u7248\u672c.rar"}]}}
最终如果看到以上内容,说明资源已经成功添加到网盘,如果errno为其他值,则说明出现了错误,12代表资源已经存在。
战绩
花费了近1个小时之后,我写完了代码,其中大部分时间主要花费在调试与研究数据包上,期间遇到了很多坑,但最终还是解决了。
欣赏下程序运行时的快感吧: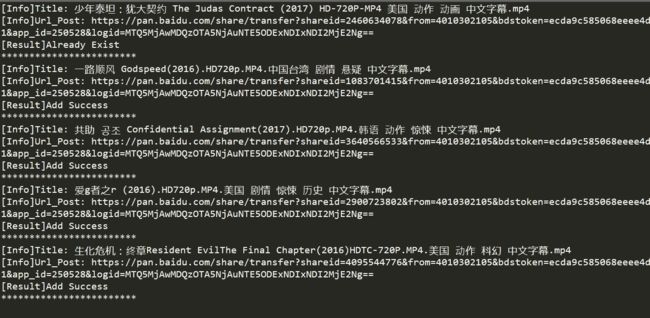
百度网盘的战果: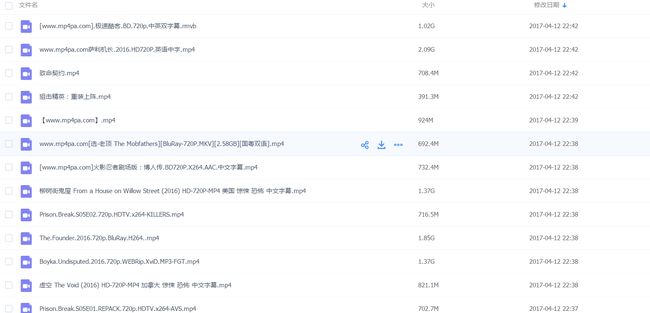
搞完这些,写下这篇文章差不多快半夜12点了,视频资源我只跑了一小部分,其余的明天继续。(为了看点视频容易吗我?!)
项目GitHub地址:https://github.com/tengzhangchao/BaiDuPan
文章来自个人博客:https://thief.one/2017/04/12/2/