本文示例代码及数据已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
最近一段时间(本文写作于2020-07-10)geopandas与geoplot两个常用的GIS类Python库都进行了一系列较为重大的内容更新,新增了一些特性,本文就将针对其中比较实际的新特性进行介绍。
2 geopandas&geoplot近期重要更新内容
2.1 geopandas近期重要更新
2.1.1 新增高性能文件格式
从geopandas0.8.0版本开始,在矢量文件读写方面,新增了.feather与.parquet两种崭新的数据格式,他们都是Apache Arrow项目下的重要数据格式,提供高性能文件存储服务,使得我们可以既可以快速读写文件,又可以显著减少文件大小,做到了“多快好省”:

在将geopandas更新到0.8.0版本后,便新增了read_feather()、to_feather()、read_parquet()以及to_parquet()这四个API,但要注意,这些新功能依赖于pyarrow,首先请确保pyarrow被正确安装,推荐使用conda install -c conda-forge pyarrow来安装。
安装完成后,我们就来一睹这些新功能的效率如何,首先我们创建一个足够大的虚拟表(200万行11列),并为其新增点要素矢量列:
import numpy as np
from shapely.geometry import Point
import pandas as pd
from tqdm.notebook import tqdm
# 创建虚拟表,其中字段名为了导出shapefile不报错加上非数字的前缀
base = pd.DataFrame(np.column_stack([np.random.randint(1, 100, (2000000, 10)),
np.random.uniform(-90, 90, (2000000, 2))]),
columns=['_'+str(i) for i in range(12)])
tqdm.pandas() # 开启apply进度条
base['geometry'] = base.progress_apply(lambda row: Point(row['_10'], row['_11']), axis=1) # 添加矢量列
base = gpd.GeoDataFrame(base, crs='EPSG:4326') # 转换为GeoDataFrame
最终得到一个较为庞大的GeoDataFrame,接着我们分别测试geopandas读写shapefile、feather以及parquet三种数据格式的耗时及文件占硬盘空间大小:


具体的性能比较结果如下,可以看到与原始的shapefile相比,feather与parquet取得了非常卓越的性能提升,且parquet的文件体积非常小:
| 类型 | 写出耗时 | 读入耗时 | 写出文件大小 |
|---|---|---|---|
| shapefile | 325秒 | 96秒 | 619MB |
| feather | 50秒 | 25.7秒 | 128MB |
| parquet | 52.4秒 | 26秒 | 81.2MB |
所以当你要存储的矢量数据规模较大时,可以尝试使用feather和parquet来代替传统的文件格式。
2.2 geoplot近期重要更新
2.2.1 webplot在线底图切换方式升级
在之前我们出品的基于geopandas的空间数据分析系列文章中的geoplot篇(上)中,对可以添加在线底图的webplot()进行过介绍,但在先前的版本中只能使用固定的少数几种内置的在线地图,而在最近的版本中,webplot()的底图叠加方式进行了非常大的调整,使得可以利用参数provider来像folium那样自由切换底图,其传入格式为:
{
'url': 地图源url,
'attribution': 自定义字符串,必填
}
譬如我们可以在一个神奇的网站 http://openwhatevermap.xyz/#3/-60.50/167.87 上点击自己感兴趣的地图样式:
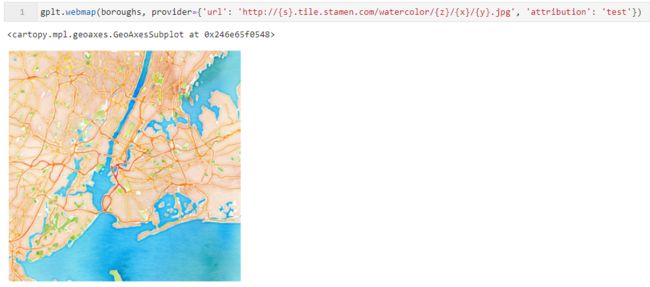
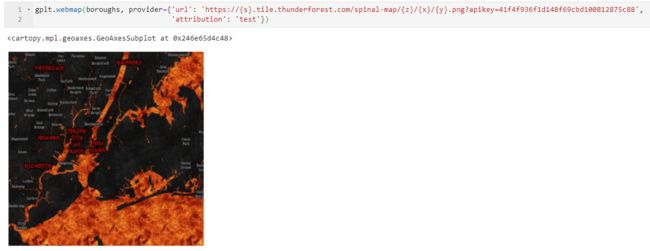
将对应的url和自定义的attribution传入webplot()中:
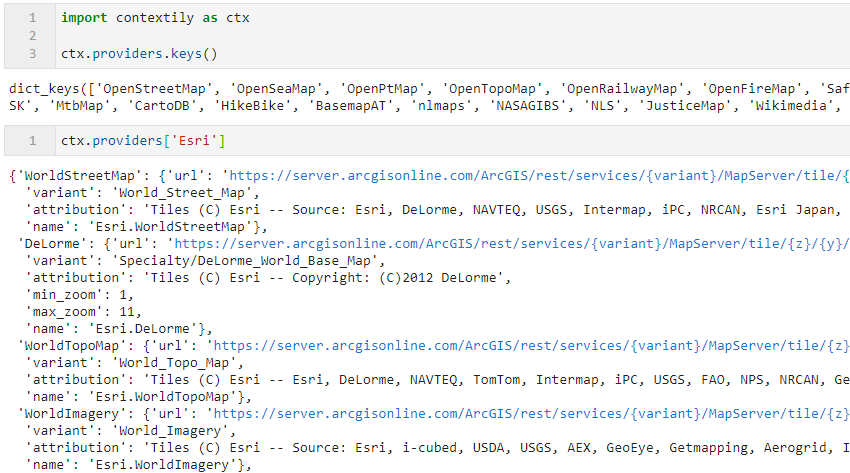
你也可以利用下面的方式查看contextily中所有内置的底图参数,从中选择你心仪的底图:
以上就是本文的全部内容,欢迎在评论区与我们进行讨论~