旷视CVPR2019图卷积多标签图像识别Multi-Label Image Recognition with Graph Convolutional Networks论文详解
背景:GCN刚出来,很多很容易想到的idea会被运用起来,很容易产生一些paper。我们解析此篇论文,了解其中原理,一来看看如何将图卷积应用于目前技术上,二来看到底如何快速的把准确率刷到state of the art以便发文章。
代码地址:https://github.com/chenzhaomin123/ML_GCN
论文地址 https://arxiv.org/abs/1904.03582
相关论文详解:
GCN (Graph Convolutional Network) 图卷积网络概览
图注意力网络(GAT) ICLR2018, Graph Attention Network论文详解
旷视CVPR2019图卷积多标签图像识别Multi-Label Image Recognition with Graph Convolutional Networks论文详解
无监督图嵌入Unsupervised graph embedding|基于对抗的图对齐adversarial graph alignment详解
Graph特征提取方法:谱聚类(Spectral Clustering)详解
目录
一、概览
1.1 任务描述
1.2 方法
1.3 效果
二、背景及相关工作
2.1 多标签识别
2.2 相关工作
2.3 本文方法
2.4 贡献点
三、方法
3.1 motivation
3.2 Graph Convolution Network简化的表示
3.3 多标签GCN
结构概览
图像特征提取
基于GCN的分类器
前馈预测
loss
3.4 ML-GCN的互相关矩阵
标签互相关矩阵
条件概率矩阵
缺陷与改进
欠拟合问题
四、实验
五、结论及个人总结
一、概览
为了构建图像中同时出现的不同目标标签的依赖关系模型,来提高模型的识别性能,在这篇论文中提出了一种基于图卷积网络模型——ML-GCN(Multi-Label Graph Convolution Networks)。
1.1 任务描述
多标签的图像识别任务,旨在预测图像中所有存在的一系列目标标签。
由于图像中的目标通常是同时出现的,因此理想状态下,我们希望对不同目标标签的依赖性进行建模以便提高模型的识别性能。
1.2 方法
为了捕获和利用这种重要的依赖关系,本文提出了一种基于图卷积网络的模型 (GCN)。
- 该模型能够在目标标签之间构建有向图,其中每个节点 (标签) 由词向量 (word embedding) 表示,
- 关于词向量word embedding,属于NLP的内容 https://baike.baidu.com/item/%E8%AF%8D%E5%90%91%E9%87%8F/22719921?fr=aladdin
- 而 GCN 网络用于将该标签图映射到一组相互依赖的目标分类器。
- 这些分类器使用另一个子网络提取的图像描述器,实现整个网络的端到端训练。
- 通过设计不同类型的相关矩阵并将它们集成到图卷积网络中训练,来深入研究图构建问题。
1.3 效果
目前最优:通过在两个多标签图像识别数据集基准的试验评估,结果表明所提出的方法明显优于当前最先进的方法。
语义信息:可视化分析结果表明图卷积网络模型所学习的分类器能够保持有意义的语义结构信息。
二、背景及相关工作
2.1 多标签识别
多标签识别是CV领域的一个基础的子问题,有很多重要的应用。对于多标签识别问题一个重要的方面是要识别出标签之间的依赖性,即dependecies。
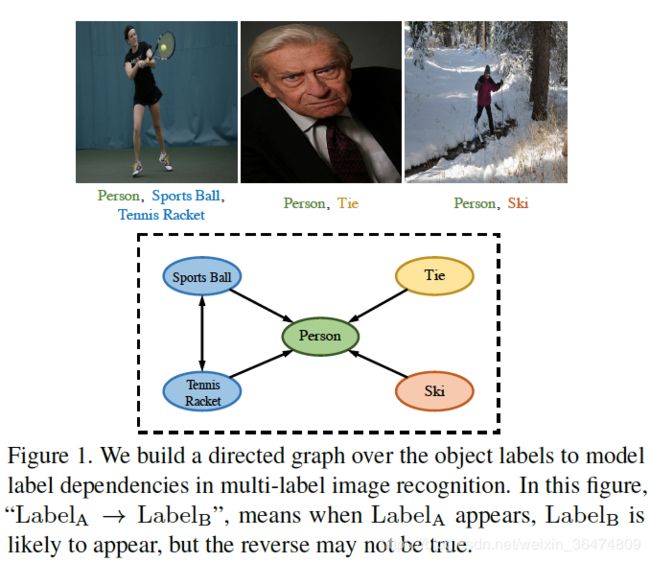
例如一个如下面的图结构之中,A标签出现,则B标签很有可能出现,但是反之不是这样,就是B标签出现,A标签并不一定出现。
2.2 相关工作
作者介绍了其他人的一些方法
- 每个标签当做一个二值的分类问题
- 通过RNN建立相应的概率模型
- 引入注意力机制来获得local correlations、global correlations
2.3 本文方法
提出了一个新的网络:aka ML-GCN,which properties with scalability and flexibility impossible for competing approaches. Instead of treating object classifiers as a set of independent parameter vectors to be learned, we propose to learn inter-dependent object classifiers from prior label representations
- 对于运算方法而言,更加可定制与灵活
- 训练时,每个分类器不把多标签分类当做一系列独立的问题去学习参数
- 提前通过标签来学习,得到标签的之间的representation
2.4 贡献点
- 端到端的训练,用GCN刻画标签之间的representation
- 设计了互相关矩阵,并且设计了re-weighted的方法,避免过拟合与欠拟合
- 在两个多标签的基准数据集上达到了最好的效果。
三、方法
这部分先介绍了motivation,然后重新认识一下GCN,然后详细的介绍我们的ML-GCN
3.1 motivation
多标签识别之中有两个重要的问题:
- 如何更好的识别出标签
- 如何更好的弄懂标签之间的互相关关系
本文中,我们运用Graph结构来建立标签之间的关系,特别的,运用word embedding(词向量,这个不懂的话自行百度)的方法来处理每个节点(节点也是label,这个问题里面node等价于label),运用GCN直接的将这些label集成化为相互关联的分类器
- Firstly, as the embedding-to-classifier mapping parameters are shared across all classes,the learned classifiers can retain the weak semantic structures in the word embedding space, where semantic related concepts are close to each other.集成后的分类器可以从所有的类别之中提取信息,分类器可以从弱语义结构之中获取信息。
- Secondly, we design a novel label correlation matrix based on their co-occurrence patterns to explicitly model the label dependencies by GCN, with which the update of node features will absorb information from correlated nodes (labels).设计了一个新的label之间的互相关矩阵,GCN可以从节点的相关节点中提取信息。
3.2 Graph Convolution Network简化的表示
我们之前解析过GCN的公式 GCN (Graph Convolutional Network) 图卷积网络概览
上面那篇详细的给出了GCN的具体公式推导,这里,我们从这篇论文的角度,再次看一下相关的公式,以及用更简化的方法去理解这些公式。
GCN的目的是在图G上学到一个函数f( · , · )
- 该图的特征描述为
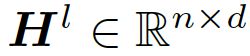
- 对应的互相关矩阵

- n表示节点的个数
- d表示节点特征的个数
- 通过上面这些更新节点的新特征

所以每个GCN可以描述为这样的公式:
- 运用了卷积操作之后,这个学到的函数 f( · , · ) 表示为:

- 其中,转移矩阵为
 ,需要通过训练获得(注意这个带上标的W与后面的分类器W不同)
,需要通过训练获得(注意这个带上标的W与后面的分类器W不同) - 互相关矩阵A归一化后为

- h( · )表示非线性激活
这样,我们对GCN的公式进行了更加简化的理解和表示。
3.3 多标签GCN
结构概览
模型有两个部分组成,一个是image representation learning,另一个是GCN based classifier learning
- image representation learning:图片经过一个CNN,提取出一个特征向量D。
- GCN based classifier learning:GCN通过对图结构的学习,word-embeddings学到
 ,这个就是网络的输入,C为类别的个数,d为word-embedding vector的纬度,直接的图会被建立于这些label之上。i.e.
,这个就是网络的输入,C为类别的个数,d为word-embedding vector的纬度,直接的图会被建立于这些label之上。i.e. 

图像特征提取
也就是image representation learning,我们运用ResNet101,,输入图像I为 448*448大小,conv5_x的输出为2048*14*14大小的featuremap,然后进行global pooling来得到图像层面的feature x

其中,θcnn表示网络参数,D纬度为2048.即通过卷积网络,我们将图像的特征提取为一个2048纬度的向量。
基于GCN的分类器
前馈预测
我们通过GCN学到各个类别之间的关联性, ,C表示类别的个数。
,C表示类别的个数。
运用结构为stacked GCN,layer l takes the node representations from previous layer (Hl) as inputs and outputs new node representations。第l层的节点是前面一层作为输入,并且输出为新节点。(这里我们理解的不透彻)
例如第一层的输入为![]() ,其中d代表label-level word embedding的纬度。最后一层输出为
,其中d代表label-level word embedding的纬度。最后一层输出为 ,D代表图像特征向量的纬度。
,D代表图像特征向量的纬度。
通过将learned classifiers应用于image representations,最终的预测为:
x就是前面通过CNN提取出的特征向量,纬度2048。
loss
假定ground truth label为 ,1表示label i 有,0表示label i 没有。一共有C类个标签。网络的loss如下:
,1表示label i 有,0表示label i 没有。一共有C类个标签。网络的loss如下:

其中σ(*)表示sigmoid函数。
3.4 ML-GCN的互相关矩阵
对于GCN而言,如何构建节点之间的互相管矩阵A至关重要。很多情况下,互相关矩阵是预先定义好的。这里,我们通过最小化labels的co-occurrence patterns来构建互相关矩阵。
我们通过条件概型来定义label correlation dependency,例如P( Lj | Li ),表示Li出现的情况下,Lj 出现的概率。同理,P( Li | Lj)表示Lj出现的情况下,Li出现的概率,这两个条件概率的意义不同,所以P( Lj | Li ) 与 P( Li | Lj)是未必相等的。互相关矩阵是非对称的。
标签互相关矩阵
为了构建这样一个互相关矩阵,我们会列出所有的标签对 ,即一个标签与另一个标签之间的对应关系。
,即一个标签与另一个标签之间的对应关系。
C为类别的个数,也就是标签的个数
条件概率矩阵
元素Mij表示Li与Lj同时出现的情况,通过co-occurrence matrix我们就可以得到了条件概率矩阵:
![]() ,表示i出现的情况下,每一类j出现的概率。Pi有j维,Mi也有j维。
,表示i出现的情况下,每一类j出现的概率。Pi有j维,Mi也有j维。
注意这里,Pi与Mi为粗体,表示一个向量,例如Mi表示M中与i对应的所有的Mij,Ni是一个数,表示Li在训练集中出现的概率。
Pi中的元素 ,表示Li出现的情况下Lj出现的概率。
,表示Li出现的情况下Lj出现的概率。
缺陷与改进
如果运用这样的条件概率矩阵的话,有一些缺点:
- the co-occurrence patterns between a label and the other labels may exhibit a long-tail distribution, where some rare co-occurrences may be noise。因为并发性,两个标签之间可能有long-tail distribution,导致噪声可能过大。这个long-tail distribution我们不太明白什么意思。后面再来研究。简单而言就是受到噪声影响过大。
- the absolute number of co-occurrences from training and test may not be completely consistent. A correlation matrix overfitted to the training set can hurt the generalization capacity.训练集与测试集之间的相关性未必相同,所以根据训练集获得的互相关矩阵可能过拟合。
因此,我们将此互相关矩阵二值化为P,用τ表示噪声边界:

A为二值化后的互相关矩阵
欠拟合问题
通过上面3.2我们所讲的GCN的公式,,一个节点的feature是它自身的feature与相邻节点的feature的加权和。那么只用0和1当做二值矩阵有一个缺点就是over-smoothing,(上一节,之所以采用二值化,论文说因为怕过拟合,结果这里运用了二值化之后,这里又怕欠拟合,挺矛盾的)。
所以对重新定义互相关矩阵:

- A'是re-weighted correlation matrix
- p 表示节点自身和与其他节点之间的weights
- 含义,p->1 时,节点自身的特征更容易被忽视
- p->0时,相邻节点的特征更容易被忽视
四、实验
前面这些原理看懂了已经基本可以看懂相应的代码,并且运行模型了。
实验部分也相对是重点,因为实验间接的体现了作者如何将模型调参到state of the art的效果的。我们后续对此进行认真研究然后汇总,再来更新。
五、结论及个人总结
idea并不新,只是将CNN与GCN结合起来,A+B就能发论文。
唯一实质性的创新点是,提出了互相关矩阵的运算方法。
另外,我们需要搞懂作者如何将模型做到state of the art的。对于我们的模型实现很有帮助。
相关论文详解:
GCN (Graph Convolutional Network) 图卷积网络概览
图注意力网络(GAT) ICLR2018, Graph Attention Network论文详解
旷视CVPR2019图卷积多标签图像识别Multi-Label Image Recognition with Graph Convolutional Networks论文详解
无监督图嵌入Unsupervised graph embedding|基于对抗的图对齐adversarial graph alignment详解
Graph特征提取方法:谱聚类(Spectral Clustering)详解