(一)大型电商详情页亿级缓存架构简介
大型电商详情页亿级缓存架构
- 上亿流量的商品详情页系统的多级缓存架构
- 架构图
- 采用三级缓存:**nginx本地缓存+redis分布式缓存+tomcat堆缓存的多级缓存架构**。
- 多级缓存架构中每一层的意义
- 最经典的缓存+数据库读写的模式,cache aside pattern
- Cache Aside Pattern
- 为什么是删除缓存,而不是更新缓存呢?
- 集群环境简介
- 环境准备
- 在虚拟机中安装CentOS
- 在每个CentOS中都安装Java和Perl
该系列文章是基于中华石杉老师的“[大数据架构]-亿级流量电商详情页系统的大型高并发与高可用缓存架构实战”课程整理的课堂笔记。
上亿流量的商品详情页系统的多级缓存架构
架构图
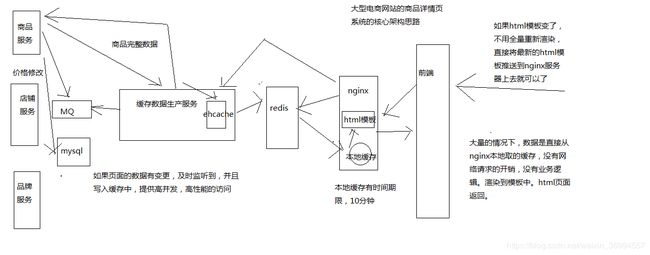
很多人以为,做个缓存,其实就是用一下redis,访问一下,就可以了,简单的缓存。做复杂的缓存,支撑电商复杂的场景下的高并发的缓存,遇到的问题,非常非常之多,绝对不是说简单的访问一下redsi就可以了。
采用三级缓存:nginx本地缓存+redis分布式缓存+tomcat堆缓存的多级缓存架构。
一般来说,显示的库存,都是时效性要求会相对高一些,因为随着商品的不断的交易,库存会不断的变化。当然,我们就希望当库存变化的时候,尽可能更快将库存显示到页面上去,而不是说等了很长时间,库存才反应到页面上去
时效性要求不高的数据(商品的基本信息:名称、颜色、版本、规格参数,等等),就还好,比如说你现在改变了商品的名称,稍微晚个几分钟反应到商品页面上,也还能接受。
商品价格/库存等时效性要求高的数据,而且种类较少,采取相关的服务系统每次发生了变更的时候,直接采取数据库和redis缓存双写的方案,这样缓存的时效性最高。
商品基本信息等时效性不高的数据,而且种类繁多,来自多种不同的系统,采取MQ异步通知的方式,写一个数据生产服务,监听MQ消息,然后异步拉取服务的数据,更新tomcat jvm缓存+redis缓存。
nginx+lua脚本做页面动态生成的工作,每次请求过来,优先从nginx本地缓存中提取各种数据,结合页面模板,生成需要的页面。
如果nginx本地缓存过期了,那么就从nginx到redis中去拉取数据,更新到nginx本地。
如果redis中也被LRU算法清理掉了,那么就从nginx走http接口到后端的服务中拉取数据,数据生产服务中,现在本地tomcat里的jvm堆缓存中找,ehcache,如果也被LRU清理掉了,那么就重新发送请求到源头的服务中去拉取数据,然后再次更新tomcat堆内存缓存+redis缓存,并返回数据给nginx,nginx缓存到本地。
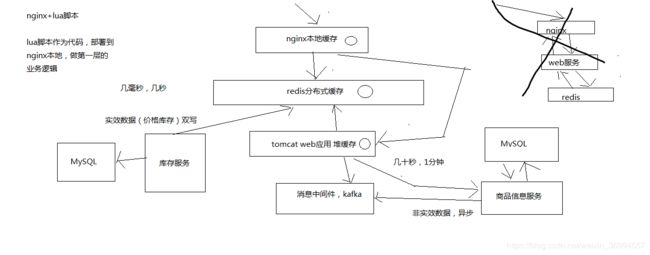
多级缓存架构中每一层的意义
nginx本地缓存,抗的是热数据的高并发访问,一般来说,商品的购买总是有热点的,比如每天购买iphone、nike、海尔等知名品牌的东西的人,总是比较多的。
这些热数据,利用nginx本地缓存,由于经常被访问,所以可以被锁定在nginx的本地缓存内。
大量的热数据的访问,就是经常会访问的那些数据,就会被保留在nginx本地缓存内,那么对这些热数据的大量访问,就直接走nginx就可以了。
那么大量的访问,直接就可以走到nginx就行了,不需要走后续的各种网络开销了。
redis分布式大规模缓存,抗的是很高的离散访问,支撑海量的数据,高并发的访问,高可用的服务。
redis缓存最大量的数据,最完整的数据和缓存,1T+数据; 支撑高并发的访问,QPS最高到几十万; 可用性,非常好,提供非常稳定的服务。
nginx本地内存有限,也就能cache住部分热数据,除了各种iphone、nike等热数据,其他相对不那么热的数据,可能流量会经常走到redis那里。
利用redis cluster的多master写入,横向扩容,1T+以上海量数据支持,几十万的读写QPS,99.99%高可用性,那么就可以抗住大量的离散访问请求。
tomcat jvm堆内存缓存,主要是抗redis大规模灾难的,如果redis出现了大规模的宕机,导致nginx大量流量直接涌入数据生产服务,那么最后的tomcat堆内存缓存至少可以再抗一下,不至于让数据库直接裸奔。
同时tomcat jvm堆内存缓存,也可以抗住redis没有cache住的最后那少量的部分缓存。
最经典的缓存+数据库读写的模式,cache aside pattern
Cache Aside Pattern
(1)读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应。
(2)更新的时候,先删除缓存,然后再更新数据库。
为什么是删除缓存,而不是更新缓存呢?
原因很简单,很多时候,复杂点的缓存的场景,因为缓存有的时候,不简单是数据库中直接取出来的值。
商品详情页的系统,修改库存,只是修改了某个表的某些字段,但是要真正把这个影响的最终的库存计算出来,可能还需要从其他表查询一些数据,然后进行一些复杂的运算,才能最终计算出现在最新的库存是多少,然后才能将库存更新到缓存中去。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据,并进行运算,才能计算出缓存最新的值的。
更新缓存的代价是很高的。
是不是说,每次修改数据库的时候,都一定要将其对应的缓存去跟新一份?也许有的场景是这样的,但是对于比较复杂的缓存数据计算的场景,就不是这样了。
如果你频繁修改一个缓存涉及的多个表,那么这个缓存会被频繁的更新,频繁的更新缓存。
但是问题在于,这个缓存到底会不会被频繁访问到???
举个例子,一个缓存涉及的表的字段,在1分钟内就修改了20次,或者是100次,那么缓存跟新20次,100次; 但是这个缓存在1分钟内就被读取了1次,有大量的冷数据。
28法则,黄金法则,20%的数据,占用了80%的访问量
实际上,如果你只是删除缓存的话,那么1分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。每次数据过来,就只是删除缓存,然后修改数据库,如果这个缓存,在1分钟内只是被访问了1次,那么只有那1次,缓存是要被重新计算的,用缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个lazy计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。类似mybatis,hibernate,懒加载,思想。查询一个部门,部门带了一个员工的list,没有必要说每次查询部门,都里面的1000个员工的数据也同时查出来啊,80%的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询1000个员工。
集群环境简介
-
搭建redis集群,集群部署,主从架构,分布式集群架构。
-
搭建一个storm的集群。
-
整套的系统包括:nginx,tomcat+java web应用,mysql等。
真实环境:
redis集群,独立的一套机器
storm集群,独立的一套机器
nginx,独立部署
tomcat + java web应用,独立部署
mysql,独立部署
环境准备
在虚拟机中安装CentOS
使用virtual box虚拟机管理软件(vmware不太稳定,休眠以后再重启,集群就挂掉了)
- 使用CentOS 6.5镜像即可,CentOS-6.5-i386-minimal.iso。
- 创建虚拟机:打开Virtual Box,点击“新建”按钮,点击“下一步”,输入虚拟机名称为eshop-cache01,选择操作系统为Linux,选择版本为Red Hat,分配1024MB内存,后面的选项全部用默认,在Virtual Disk File location and size中,一定要自己选择一个目录来存放虚拟机文件,最后点击“create”按钮,开始创建虚拟机。
- 设置虚拟机网卡:选择创建好的虚拟机,点击“设置”按钮,在网络一栏中,连接方式中,选择“Bridged Adapter”。
- 安装虚拟机中的CentOS 6.5操作系统:选择创建好的虚拟机,点击“开始”按钮,选择安装介质(即本地的CentOS 6.5镜像文件),选择第一项开始安装-Skip-欢迎界面Next-选择默认语言-Baisc Storage Devices-Yes, discard any data-主机名:spark2upgrade01-选择时区-设置初始密码为hadoop-Replace Existing Linux System-Write changes to disk-CentOS 6.5自己开始安装。
- 安装完以后,CentOS会提醒你要重启一下,就是reboot,你就reboot就可以了。
- 配置网络
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=dhcp
service network restart
ifconfig
BOOTPROTO=static
IPADDR=192.168.0.X
NETMASK=255.255.255.0
GATEWAY=192.168.0.1
service network restart
- 配置hosts
vi /etc/hosts
配置本机的hostname到ip地址的映射
- 配置SecureCRT
此时就可以使用SecureCRT从本机连接到虚拟机进行操作了
一般来说,虚拟机管理软件,virtual box,可以用来创建和管理虚拟机,但是一般不会直接在virtualbox里面去操作,因为比较麻烦,没有办法复制粘贴
比如后面我们要安装很多其他的一些东西,perl,java,redis,storm,复制一些命令直接去执行
SecureCRT,在windows宿主机中,去连接virtual box中的虚拟机。
- 关闭防火墙
service iptables stop
service ip6tables stop
chkconfig iptables off
chkconfig ip6tables off
vi /etc/selinux/config
SELINUX=disabled
关闭windows的防火墙
后面要搭建集群,有的大数据技术的集群之间,在本地你给了防火墙的话,可能会没有办法互相连接,会导致搭建失败
- 配置yum
yum clean all
yum makecache
yum install wget
在每个CentOS中都安装Java和Perl
WinSCP,就是在windows宿主机和linux虚拟机之间互相传递文件的一个工具
- 安装JDK
- 将jdk-7u60-linux-i586.rpm通过WinSCP上传到虚拟机中
- 安装JDK:rpm -ivh jdk-7u65-linux-i586.rpm
- 配置jdk相关的环境变量
vi .bashrc
export JAVA_HOME=/usr/java/latest
export PATH=$PATH:$JAVA_HOME/bin
source .bashrc
- 测试jdk安装是否成功:java -version
- 安装Perl
yum install -y gcc
wget http://www.cpan.org/src/5.0/perl-5.16.1.tar.gz
tar -xzf perl-5.16.1.tar.gz
cd perl-5.16.1
./Configure -des -Dprefix=/usr/local/perl
make && make test && make install
perl -v
为什么要装perl?我们整个大型电商网站的详情页系统,复杂。java+nginx+lua,需要perl。
perl,是一个基础的编程语言的安装,tomcat,跑java web应用
- 在4个虚拟机中安装CentOS集群
(1)按照上述步骤,再安装三台一模一样环境的linux机器
(2)另外三台机器的hostname分别设置为eshop-cache02,eshop-cache03,eshop-cache04
(3)安装好之后,在每台机器的hosts文件里面,配置好所有的机器的ip地址到hostname的映射关系
比如说,在eshop-cache01的hosts里面
192.168.31.187 eshop-cache01
192.168.31.xxx eshop-cache02
192.168.31.xxx eshop-cache03
192.168.31.xxx eshop-cache04
- 配置4台CentOS为ssh免密码互相通信
(1)首先在三台机器上配置对本机的ssh免密码登录
ssh-keygen -t rsa
生成本机的公钥,过程中不断敲回车即可,ssh-keygen命令默认会将公钥放在/root/.ssh目录下
cd /root/.ssh
cp id_rsa.pub authorized_keys
将公钥复制为authorized_keys文件,此时使用ssh连接本机就不需要输入密码了
(2)接着配置三台机器互相之间的ssh免密码登录
使用ssh-copy-id -i hostname命令将本机的公钥拷贝到指定机器的authorized_keys文件中
java,在公司里做项目,有几个人是自己去维护linux集群的啊?????
几乎没有,很少很少,类似这一讲要做的事情,其实都是SRE,运维的同学,去做的
但是对于课程来说,我们只能自己一步一步做,才有环境去学习啊!!!