cs224笔记:Lecture 6 Language Models and RNNs
Language Models and RNNs
1 Language Model
Language Model is the task of predicting what word comes next.
更正式的:给定一个单词序列, x ( 1 ) , x ( 2 ) , . . . , x ( t ) \mathbf{x}^{(1)},\mathbf{x}^{(2)},...,\mathbf{x}^{(t)} x(1),x(2),...,x(t),预测下一个单词 x ( t + 1 ) \mathbf{x}^{(t+1)} x(t+1)的概率分布。
p ( x ( t + 1 ) ∣ x ( 1 ) , x ( 2 ) , . . . , x ( t ) ) p(\mathbf{x}^{(t+1)}|\mathbf{x}^{(1)},\mathbf{x}^{(2)},...,\mathbf{x}^{(t)}) p(x(t+1)∣x(1),x(2),...,x(t))
x ( t + 1 ) \mathbf{x}^{(t+1)} x(t+1)可以是单词表 V = { w 1 , . . . , w ∣ V ∣ } V=\{w_1,...,w_{|V|}\} V={w1,...,w∣V∣}中的任意单词。这样的系统成为language model,也可以理解为给一段文本分配概率。
p ( x ( 1 ) , x ( 2 ) , . . . , x ( t ) ) = p ( x ( 1 ) ) × p ( x ( 2 ) ∣ x ( 1 ) ) × ⋯ × p ( x ( T ) ∣ x ( T − 1 ) , x ( T − 2 ) , . . . , x ( 1 ) ) = ∏ t = 1 T p ( x ( t ) ∣ x ( t − 1 ) , . . . , x ( 1 ) ) p(\mathbf{x}^{(1)},\mathbf{x}^{(2)},...,\mathbf{x}^{(t)})=p(\mathbf{x}^{(1)})\times p(\mathbf{x}^{(2)}|\mathbf{x}^{(1)})\times \cdots \times p(\mathbf{x}^{(T)}|\mathbf{x}^{(T-1)},\mathbf{x}^{(T-2)},...,\mathbf{x}^{(1)})\\ =\prod_{t=1}^Tp(\mathbf{x}^{(t)}|\mathbf{x}^{(t-1)},...,\mathbf{x}^{(1)}) p(x(1),x(2),...,x(t))=p(x(1))×p(x(2)∣x(1))×⋯×p(x(T)∣x(T−1),x(T−2),...,x(1))=t=1∏Tp(x(t)∣x(t−1),...,x(1))
Language Model是一个benchmark task,可以帮助我们评估对语言的理解的程度。
同时,Language Model是许多NLP任务的组成部分(subcomponent),尤其是对于那些包含文本生成(generating text)和估计给定文本概率(estimating the probability of text)的任务。
• Predictive typing
• Speech recognition
• Handwriting recognition
• Spelling/grammar correction
• Authorship identification
• Machine translation
• Summarization
• Dialogue
• etc.
2 n-gram Language Models
n-gram 就是n个连续的单词,根据n的不同,有不同的类型,比如对于同一句话 the students opened their __ 有:
unigram: “the” “students” “opened” “their”
bigram:“the students” “students opened” “opened their”
trigram: “the students opened” “students opened their”
4-gram: “the students opened their”
可以看出n越大涵盖的信息多,模型相较就会更精准一些。
n-gram language model的思想就是统计不同n-gram出现的频率,用于预测单词。(其实就是简单的counts)
首先,n-gram language model的简单假设就是一个单词 x ( t ) \mathbf{x^{(t)}} x(t)只依赖于它前面的n-1个单词,即:
p ( x ( t + 1 ) ∣ x ( t ) , x ( t − 1 ) , . . . , x ( 1 ) ) = p ( x ( t + 1 ) ∣ x ( t ) , x ( t − 1 ) , . . . , x ( t − n + 2 ) ) p(\mathbf{x}^{(t+1)}|\mathbf{x}^{(t)},\mathbf{x}^{(t-1)},...,\mathbf{x}^{(1)}) = p(\mathbf{x}^{(t+1)}|\mathbf{x}^{(t)},\mathbf{x}^{(t-1)},...,\mathbf{x}^{(t-n+2)}) p(x(t+1)∣x(t),x(t−1),...,x(1))=p(x(t+1)∣x(t),x(t−1),...,x(t−n+2))
然后根据条件概率定义计算它,
p ( x ( t + 1 ) ∣ x ( t ) , x ( t − 1 ) , . . . , x ( t − n + 2 ) ) = p ( x ( t + 1 ) , x ( t ) , . . . , x ( t − n + 2 ) ) p ( x ( t ) , . . . , x ( t − n + 2 ) ) ) p(\mathbf{x}^{(t+1)}|\mathbf{x}^{(t)},\mathbf{x}^{(t-1)},...,\mathbf{x}^{(t-n+2)})=\frac{p(\mathbf{x}^{(t+1)},\mathbf{x}^{(t)},...,\mathbf{x}^{(t-n+2)})}{p(\mathbf{x}^{(t)},...,\mathbf{x}^{(t-n+2)}))} p(x(t+1)∣x(t),x(t−1),...,x(t−n+2))=p(x(t),...,x(t−n+2)))p(x(t+1),x(t),...,x(t−n+2))
分子是n-gram出现的概率,分母是(n-1)-gram出现的概率,通过对大规模语料库的统计,可以获得这两个概率的近似(statistical approximation),即:
p ( x ( t + 1 ) , x ( t ) , . . . , x ( t − n + 2 ) ) p ( x ( t ) , . . . , x ( t − n + 2 ) ) ) ≈ c o u n t ( x ( t + 1 ) , x ( t ) , . . . , x ( t − n + 2 ) ) c o u n t ( x ( t ) , . . . , x ( t − n + 2 ) ) \frac{p(\mathbf{x}^{(t+1)},\mathbf{x}^{(t)},...,\mathbf{x}^{(t-n+2)})}{p(\mathbf{x}^{(t)},...,\mathbf{x}^{(t-n+2)}))} \approx \frac{count(x^{(t+1)},x^{(t)},...,x^{(t-n+2)})}{count(x^{(t)},...,x^{(t-n+2)})} p(x(t),...,x(t−n+2)))p(x(t+1),x(t),...,x(t−n+2))≈count(x(t),...,x(t−n+2))count(x(t+1),x(t),...,x(t−n+2))
e.g. 学习一个4-gram language model,句子为:
as the proctor started the clock, the students opened their __ \text{as the proctor started the clock, the students opened their \_\_ } as the proctor started the clock, the students opened their __
p ( w ∣ students opened their ) = c o u n t ( students opened their w ) c o u n t ( students opened their ) p(w|\text{ students opened their }) = \frac{count(\text{ students opened their w })}{count(\text{ students opened their })} p(w∣ students opened their )=count( students opened their )count( students opened their w )
假设在语料库中,"students opened their"出现了1000次,"students opened their books"出线了400次,"students opened their exams"出线了100次,则
p ( books ∣ students opened their ) = c o u n t ( students opened their books ) c o u n t ( students opened their ) = 0.4 p ( exams ∣ students opened their ) = c o u n t ( students opened their examss ) c o u n t ( students opened their ) = 0.1 p(\text{books}|\text{ students opened their }) = \frac{count(\text{ students opened their books })}{count(\text{ students opened their })} = 0.4 \\ p(\text{exams}|\text{ students opened their }) = \frac{count(\text{ students opened their examss })}{count(\text{ students opened their })} = 0.1 \\ p(books∣ students opened their )=count( students opened their )count( students opened their books )=0.4p(exams∣ students opened their )=count( students opened their )count( students opened their examss )=0.1
N-gram language model的问题
Sparsity Problem(稀疏问题)
p ( w ∣ students opened their ) = c o u n t ( students opened their w ) c o u n t ( students opened their ) p(w|\text{ students opened their }) = \frac{count(\text{ students opened their w })}{count(\text{ students opened their })} p(w∣ students opened their )=count( students opened their )count( students opened their w )
首先是分子的问题,“students opened their w”有可能没在语料库出现过,所以这个概率为0。
解决:给每个单词 w ∈ V w\in V w∈V都加上一个很小的值 δ \delta δ,这个方法称为smoothing。
然后是分母的问题,“students opened their”有可能没出现过,这样对于任何概率都无法计算。
解决:backoff(回退),统计"opened their"作为替代。
Storage Problem(存储问题)
对于每一个出现过的n-gram都需要存储下来,随着n的增大,要存储的规模也会增大。
所以引出了一个矛盾,我们希望大一点n使得模型更加精确,但是n越大会引发sparsity problem和storage problem。
3 Neural Language Models
a fixed-window language model
as the proctor started the clock, the students opened their __ \text{as the proctor started the clock, the students opened their \_\_} as the proctor started the clock, the students opened their __
还是同样的例子,假设window大小为4,则我们的模型只用到"the students opened their"来预测下一个单词。

其中输入 x ( 1 ) , x ( 2 ) , x ( 3 ) , x ( 4 ) \mathbf{x}^{(1)},\mathbf{x}^{(2)},\mathbf{x}^{(3)},\mathbf{x}^{(4)} x(1),x(2),x(3),x(4)为one-hot编码的向量,接着将词嵌入(word embedding)后的词向量拼接(concatenation)成一个向量 e = [ e ( 1 ) ; e ( 2 ) ; e ( 3 ) ; e ( 4 ) ] \mathbf{e}=[\mathbf{e}^{(1)};\mathbf{e}^{(2)};\mathbf{e}^{(3)};\mathbf{e}^{(4)}] e=[e(1);e(2);e(3);e(4)],然后经过一个隐层, h = f ( W e + b 1 ) \mathbf{h}=f(\mathbf{W}\mathbf{e}+\mathbf{b_1}) h=f(We+b1),最后softmax输出获得概率分布, y ^ = s o f t m a x ( U h + b 2 ) ∈ R ∣ V ∣ \hat{\mathbf{y}}= softmax(\mathbf{U}\mathbf{h}+\mathbf{b_2})\in \mathbb{R}^{|V|} y^=softmax(Uh+b2)∈R∣V∣
相较n-gram模型的改进:
没有sparsity问题;
不需要存储观测到的所有n-gram。
存在的问题:
固定窗口(fixed window)不够大,扩大窗口就相当于扩大 W \mathbf{W} W,因而窗口不能太大;
因为各个单词通过拼接组成的 e \mathbf{e} e,使得不同的单词对应 W \mathbf{W} W矩阵不同的位置,这样相当于丢失了机器学习很重要的特性–共享权重。例如:
W e = [ w 1 , w 2 , w 3 , w 4 ] [ e 1 e 2 e 3 e 4 ] \mathbf{W}\mathbf{e} = [\mathbf{w_1},\mathbf{w_2},\mathbf{w_3},\mathbf{w_4}] \left [ \begin{array}{ccc}{\mathbf{e_1}} \\{\mathbf{e_2}}\\{\mathbf{e_3}}\\{\mathbf{e_4}} \end{array} \right ] We=[w1,w2,w3,w4]⎣⎢⎢⎡e1e2e3e4⎦⎥⎥⎤
可以看出 W \mathbf{W} W中不同块对应不同的单词,即丢失了对称性(symmetry)。
4 RNN Language Models
4.1 RNN(Recurrent Neural Network)
Core idea: 重复的运用同一个权重 W \mathbf{W} W。可以同上面fixed window neural做比较,RNN中 W \mathbf{W} W会重复用在输入序列每个词上面。

4.2 a RNN Language Model

如图,输入为one-hot编码的词向量 x ( t ) \mathbf{x}^{(t)} x(t),首先词嵌入(word embedding)成稠密向量 e ( t ) = E x ( t ) \mathbf{e}^{(t)}=\mathbf{E}\mathbf{x}^{(t)} e(t)=Ex(t),接着隐层计算,每个隐层的输入 h ( t ) \mathbf{h}^{(t)} h(t)包括 x ( t ) \mathbf{x}^{(t)} x(t)和上一时刻的隐层 h ( t − 1 ) \mathbf{h}^{(t-1)} h(t−1), h ( t ) = σ ( W h h ( t − 1 ) + W e e ( t ) + b 1 ) \mathbf{h}^{(t)}=\sigma(\mathbf{W_h}\mathbf{h}^{(t-1)}+\mathbf{W_e}\mathbf{e}^{(t)}+\mathbf{b_1}) h(t)=σ(Whh(t−1)+Wee(t)+b1),最后输入通过softmax获取概率分布, y ^ ( t ) = s o f t m a x ( U h ( t ) + b 2 ) ∈ R ∣ V ∣ \hat{\mathbf{y}}^{(t)}= softmax(\mathbf{U}\mathbf{h}^{(t)}+\mathbf{b_2})\in \mathbb{R}^{|V|} y^(t)=softmax(Uh(t)+b2)∈R∣V∣。这里任意时刻都可以获得输出,取决于你想让模型做什么样的预测。此外输入序列可以任意长度。
RNN优点:
可以处理任意长度的序列;
在时刻t的计算,可以获取到很多步前的输入信息;
模型规模不会随着输入序列增大而增大;
权重 W \mathbf{W} W应用到每个时刻的输入上,所以对于任意的输入,权重 W \mathbf{W} W有对称性(symmetry)。
RNN缺点:
循环计算(recurrent computation)很慢;
很难获取到很多步前的信息;
4.3 训练RNN Language Model
给定一个文本的语料库(corpus),由单词序列组成 x ( 1 ) , x ( 2 ) , . . . , x ( T ) \mathbf{x}^{(1)},\mathbf{x}^{(2)},...,\mathbf{x}^{(T)} x(1),x(2),...,x(T)。对于RNN-LM,在每一步t,计算输出概率分布 y ^ ( t ) \mathbf{\hat{y}}^{(t)} y^(t),即根据之前的所有单词,预测下个单词。
每一步t的损失函数定义为预测概率分布 y ^ ( t ) \mathbf{\hat{y}}^{(t)} y^(t)与真实的下个个单词 y ( t ) \mathbf{y}^{(t)} y(t)( x ( t + 1 ) \mathbf{x}^{(t+1)} x(t+1)的one-hot)之间的互熵损失(cross entropy):
J ( t ) ( θ ) = C E ( y ( t ) , y ^ ( t ) ) = − ∑ w ∈ V y w ( t ) log y ^ w ( t ) = − log y ^ x t + 1 ( t ) J^{(t)}(\theta)=CE(\mathbf{y}^{(t)},\mathbf{\hat{y}}^{(t)})=-\sum_{w\in \mathbf{V}}\mathbf{y}_w^{(t)}\log\mathbf{\hat{y}}_w^{(t)} =-\log\mathbf{\hat{y}}_{\mathbf{x}_{t+1}}^{(t)} J(t)(θ)=CE(y(t),y^(t))=−w∈V∑yw(t)logy^w(t)=−logy^xt+1(t)
总的损失(overall loss)为整个训练集loss的均值:
J ( θ ) = 1 T ∑ t = 1 T J ( t ) ( θ ) = 1 T ∑ t = 1 T − log y ^ x t + 1 ( t ) J(\theta)=\frac{1}{T}\sum_{t=1}^{T} J^{(t)}(\theta)=\frac{1}{T}\sum_{t=1}^{T}-\log\mathbf{\hat{y}}_{\mathbf{x}_{t+1}}^{(t)} J(θ)=T1t=1∑TJ(t)(θ)=T1t=1∑T−logy^xt+1(t)
但是在整个语料库上计算损失(loss)和梯度(gradient) too expensive,实践中在一个句子上或者一个文本上做计算。
4.4 Backpropagation for RNNs
Multivariable Chain Rule
给定一个多变量(multivariable)函数 f ( x , y ) f(x,y) f(x,y),其中 x ( t ) x(t) x(t)和 y ( t ) y(t) y(t)是单变量(single variable)函数,下面是multivariable chain rule:
d d t f ( x ( t ) , y ( t ) ) = ∂ f ∂ x d x d t + ∂ f ∂ y d y d t \frac{d}{d_t}f\left( x(t),y(t) \right )=\frac{\partial f}{\partial x}\frac{dx}{dt} + \frac{\partial f}{\partial y}\frac{dy}{dt} dtdf(x(t),y(t))=∂x∂fdtdx+∂y∂fdtdy
所有对于RNN权重 W \mathbf{W} W的梯度计算如图,也就是运用multivariable chain rule将每个时刻对权重 W \mathbf{W} W的梯度加起来:
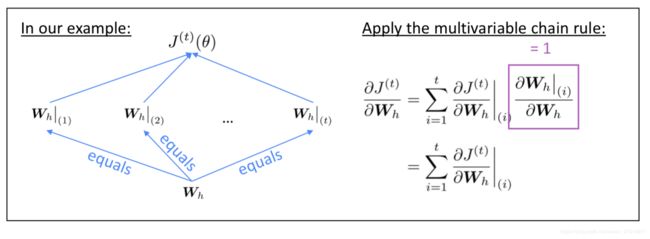
关于 ∂ J ( t ) ∂ W h = ∑ t = 1 t ∂ J ( t ) ∂ W h ∣ i \frac{\partial J^{(t)}}{\partial \mathbf{W}_h} =\sum_{t=1}^t {\frac{\partial J^{(t)}}{\partial \mathbf{W}_h}}\vert_i ∂Wh∂J(t)=∑t=1t∂Wh∂J(t)∣i的计算为按照时间 i = t , . . . , 0 i=t,...,0 i=t,...,0反向传播,将梯度加起来,算法被称为backpropagation through time(BPTT)。
评估Language Model
对于language model一个标准的评估度量是perplexity (perplexity越小越好)
p e r p l e x i t y = ∏ t = 1 T ( 1 P L M ( x ( t + 1 ) ∣ x ( t ) , . . . , x ( 1 ) ) ) 1 / T perplexity= \prod_{t=1}^T{\left(\frac{1}{P_{LM}(\mathbf{x}^{(t+1)}|\mathbf{x}^{(t)},...,\mathbf{x}^{(1)}) } \right)} ^{1/T} perplexity=t=1∏T(PLM(x(t+1)∣x(t),...,x(1))1)1/T
等价于互熵损失的指数:
= ∏ t = 1 T ( 1 y ^ x t + 1 ( t ) ) 1 / T = e x p ( 1 T ∑ t = 1 T − log y ^ x t + 1 ( t ) ) = e x p ( J ( θ ) ) \begin{aligned} &=\prod_{t=1}^T{\left(\frac{1}{\mathbf{\hat{y}}_{\mathbf{x}_{t+1}}^{(t)}} \right)} ^{1/T}\\ &= exp(\frac{1}{T}\sum_{t=1}^{T}-\log\mathbf{\hat{y}}_{\mathbf{x}_{t+1}}^{(t)})\\ &=exp(J(\theta)) \end{aligned} =t=1∏T(y^xt+1(t)1)1/T=exp(T1t=1∑T−logy^xt+1(t))=exp(J(θ))