CUDA-Pinned Host Memory
翻译原文:https://devblogs.nvidia.com/how-optimize-data-transfers-cuda-cc/
Pinned Host Memory
Host (CPU) data allocations are pageable by default. The GPU cannot access data directly from pageable host memory, so when a data transfer from pageable host memory to device memory is invoked, the CUDA driver must first allocate a temporary page-locked, or “pinned”, host array, copy the host data to the pinned array, and then transfer the data from the pinned array to device memory, as illustrated below.
固定主机内存
主机(CPU)数据分配在默认情况下是可分页的。GPU无法直接从可分页主机内存访问数据,因此当调用从可分页主机内存到设备内存的数据传输时,CUDA驱动程序必须首先分配一个临时的页面锁定或“固定”主机阵列,将主机数据复制到固定阵列,然后将数据从固定阵列传输到设备内存,如图所示:
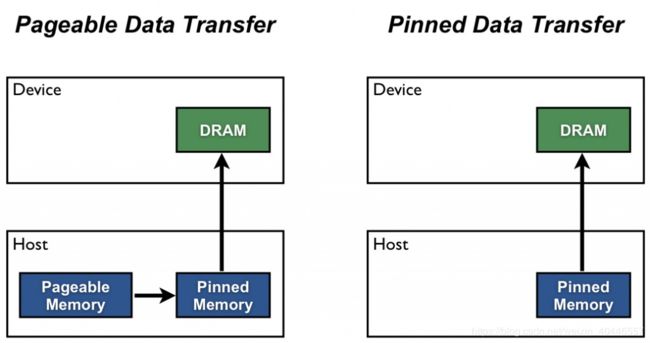
As you can see in the figure, pinned memory is used as a staging area for transfers from the device to the host. We can avoid the cost of the transfer between pageable and pinned host arrays by directly allocating our host arrays in pinned memory. Allocate pinned host memory in CUDA C/C++ using cudaMallocHost() or cudaHostAlloc(), and deallocate it with cudaFreeHost(). It is possible for pinned memory allocation to fail, so you should always check for errors. The following code excerpt demonstrates allocation of pinned memory with error checking.
如图所示,固定内存用作从设备传输到主机的临时区域。我们可以通过直接在固定内存中分配主机阵列来避免可分页主机阵列和固定主机阵列之间的传输成本。在CUDA C/C++中使用cudaMallocHost()或 cudaHostAlloc()分配被寄存的主机内存,并用cudaFreeHost()释放它。固定内存分配可能会失败,因此应始终检查错误。下面的代码摘录演示了带错误检查的固定内存分配。
cudaError_t status = cudaMallocHost((void**)&h_aPinned, bytes);
if (status != cudaSuccess)
printf("Error allocating pinned host memory\n");Data transfers using host pinned memory use the same cudaMemcpy() syntax as transfers with pageable memory. We can use the following “bandwidthtest” program (also available on Github) to compare pageable and pinned transfer rates.
使用主机固定内存的数据传输与使用可分页内存的传输使用相同的cudamemcpy()语法。我们可以使用下面的“bandwidthtest”程序(也可以在github上使用)来比较可分页和固定传输速率。
#include
#include
// Convenience function for checking CUDA runtime API results
// can be wrapped around any runtime API call. No-op in release builds.
inline
cudaError_t checkCuda(cudaError_t result)
{
#if defined(DEBUG) || defined(_DEBUG)
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n",
cudaGetErrorString(result));
assert(result == cudaSuccess);
}
#endif
return result;
}
void profileCopies(float *h_a,
float *h_b,
float *d,
unsigned int n,
char *desc)
{
printf("\n%s transfers\n", desc);
unsigned int bytes = n * sizeof(float);
// events for timing
cudaEvent_t startEvent, stopEvent;
checkCuda( cudaEventCreate(&startEvent) );
checkCuda( cudaEventCreate(&stopEvent) );
checkCuda( cudaEventRecord(startEvent, 0) );
checkCuda( cudaMemcpy(d, h_a, bytes, cudaMemcpyHostToDevice) );
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
float time;
checkCuda( cudaEventElapsedTime(&time, startEvent, stopEvent) );
printf(" Host to Device bandwidth (GB/s): %f\n", bytes * 1e-6 / time);
checkCuda( cudaEventRecord(startEvent, 0) );
checkCuda( cudaMemcpy(h_b, d, bytes, cudaMemcpyDeviceToHost) );
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&time, startEvent, stopEvent) );
printf(" Device to Host bandwidth (GB/s): %f\n", bytes * 1e-6 / time);
for (int i = 0; i < n; ++i) {
if (h_a[i] != h_b[i]) {
printf("*** %s transfers failed ***\n", desc);
break;
}
}
// clean up events
checkCuda( cudaEventDestroy(startEvent) );
checkCuda( cudaEventDestroy(stopEvent) );
}
int main()
{
unsigned int nElements = 4*1024*1024;
const unsigned int bytes = nElements * sizeof(float);
// host arrays
float *h_aPageable, *h_bPageable;
float *h_aPinned, *h_bPinned;
// device array
float *d_a;
// allocate and initialize
h_aPageable = (float*)malloc(bytes); // host pageable
h_bPageable = (float*)malloc(bytes); // host pageable
checkCuda( cudaMallocHost((void**)&h_aPinned, bytes) ); // host pinned
checkCuda( cudaMallocHost((void**)&h_bPinned, bytes) ); // host pinned
checkCuda( cudaMalloc((void**)&d_a, bytes) ); // device
for (int i = 0; i < nElements; ++i) h_aPageable[i] = i;
memcpy(h_aPinned, h_aPageable, bytes);
memset(h_bPageable, 0, bytes);
memset(h_bPinned, 0, bytes);
// output device info and transfer size
cudaDeviceProp prop;
checkCuda( cudaGetDeviceProperties(&prop, 0) );
printf("\nDevice: %s\n", prop.name);
printf("Transfer size (MB): %d\n", bytes / (1024 * 1024));
// perform copies and report bandwidth
profileCopies(h_aPageable, h_bPageable, d_a, nElements, "Pageable");
profileCopies(h_aPinned, h_bPinned, d_a, nElements, "Pinned");
printf("n");
// cleanup
cudaFree(d_a);
cudaFreeHost(h_aPinned);
cudaFreeHost(h_bPinned);
free(h_aPageable);
free(h_bPageable);
return 0;
} The data transfer rate can depend on the type of host system (motherboard, CPU, and chipset) as well as the GPU. On my laptop which has an Intel Core i7-2620M CPU (2.7GHz, 2 Sandy Bridge cores, 4MB L3 Cache) and an NVIDIA NVS 4200M GPU (1 Fermi SM, Compute Capability 2.1, PCI-e Gen2 x16), running BandwidthTest produces the following results. As you can see, pinned transfers are more than twice as fast as pageable transfers.
数据传输速率可以取决于主机系统(主板、CPU和芯片组)的类型以及GPU。在我的笔记本电脑上,它有一个Intel Core i7-2620M CPU(2.7GHz,2个Sandy Bridge内核,4MB L3缓存)和一个NVIDIA NVS 4200M GPU(1个Fermi SM,计算能力2.1,PCI-E Gen2 x16),运行BandwidthTest会产生以下结果。如您所见,固定传输比可分页传输快两倍多。
Device: NVS 4200M
Transfer size (MB): 16
Pageable transfers
Host to Device bandwidth (GB/s): 2.308439
Device to Host bandwidth (GB/s): 2.316220
Pinned transfers
Host to Device bandwidth (GB/s): 5.774224
Device to Host bandwidth (GB/s): 5.958834On my desktop PC with a much faster Intel Core i7-3930K CPU (3.2 GHz, 6 Sandy Bridge cores, 12MB L3 Cache) and an NVIDIA GeForce GTX 680 GPU (8 Kepler SMs, Compute Capability 3.0) we see much faster pageable transfers, as the following output shows. This is presumably because the faster CPU (and chipset) reduces the host-side memory copy cost.
在我的台式电脑上,Intel Core i7-3930K CPU(3.2 GHz,6个Sandy Bridge内核,12MB L3缓存)和Nvidia Geforce GTX 680 GPU(8 Kepler SMS,计算能力3.0),我们可以看到更快的可分页传输,如下输出所示。这可能是因为更快的CPU(和芯片组)降低了主机端内存复制成本。
Device: GeForce GTX 680
Transfer size (MB): 16
Pageable transfers
Host to Device bandwidth (GB/s): 5.368503
Device to Host bandwidth (GB/s): 5.627219
Pinned transfers
Host to Device bandwidth (GB/s): 6.186581
Device to Host bandwidth (GB/s): 6.670246You should not over-allocate pinned memory. Doing so can reduce overall system performance because it reduces the amount of physical memory available to the operating system and other programs. How much is too much is difficult to tell in advance, so as with all optimizations, test your applications and the systems they run on for optimal performance parameters.
您不应该过度分配固定内存。这样做可以降低整个系统的性能,因为它会减少操作系统和其他程序可用的物理内存量。多少是太多很难提前知道,所以对于所有优化,测试应用程序和它们运行的系统以获得最佳性能参数。