推荐系统二---召回算法和业界最佳实践(一)
业界通用推荐系统框架结构如下:

Match & Rank
定义:Match基于当前user(profile、history)和context,快速在全库里找到TopN最相关的item,给Rank来做小范围综合多目标最大化
通常做法:用各种算法做召回,比如user/item/model-based CF,Content-based,Demographic-based,DNN-Embedding-based等,做粗排之后交由后面的Rank层做更精细的排序。
1、Match算法典型应用
(1) 猜你喜欢
多样推荐
(2) 相似推荐
看了还看
(3)搭配推荐
买了还买
Outline
2、Collaborative Filtering
“CF makes predictions (filtering) about a user’s interest by collecting preferences information from many users (collaborating)” —Wikipedia
(1)数学形式化:矩阵补全问题

(2)基于共现关系的 Collaborative Filtering 算法
•User-based CF •
多⽤于挖掘那些有共同兴趣的⼩团体,通常新颖性较好,但是准确性稍差
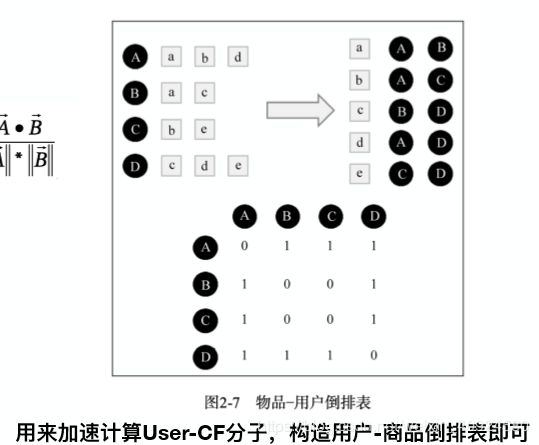
•Item-based CF •
侧重于挖掘item之间的关系,然后根据⽤户的历史⾏为来为⽤户⽣成推荐列表,相⽐user-based⽅法,item-based 的应⽤更为⼴泛。

实际计算中会有很多位置都为0,可以使用倒排表的形式
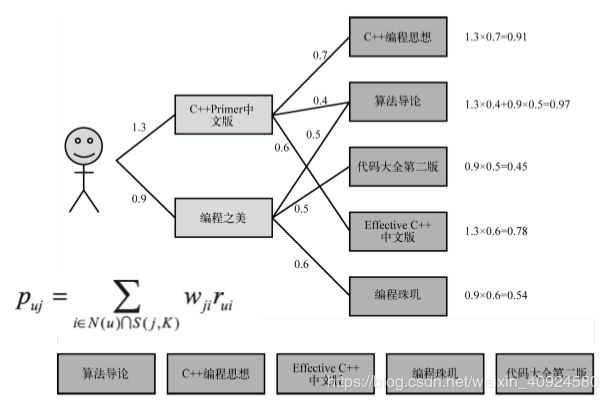

基于Item-based的算法调用示意图

(补足抄底是指match阶段数据不够,可能会使用热门进行补足)
Item CF算法最新实践
<1>、改进版I2I
•motivation:热门⽤户、哈利波特效应、⽤户⾏为缺乏考虑
•solution:热门⽤户降权、热门Item降权
1>降低热门用户的影响
2>缓解哈利波特效应

3>综合考虑:用户行为差;热门用户降权
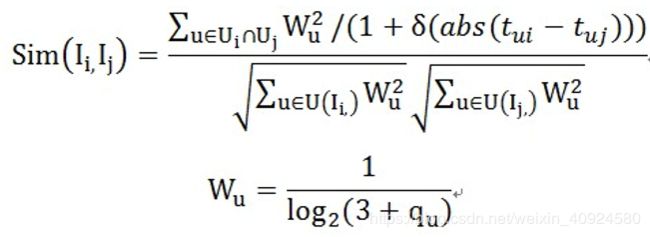
<2>、实时I2I
•motivation:新品推荐问题
•Solution:实时增量i2i

参考腾讯2015paper:http://net.pku.edu.cn/~cuibin/Papers/2015SIGMOD-tencentRec.pdf
<3>、Hybrid I2I -----learning to rank
•motivation:⽆监督学习,⽆法刻画场景差异(多目标?)
•solution:有监督Hybrid多种i2i算法

LTR框架如上,参考:
https://www.cda.cn/uploadfile/image/20151220/20151220115436_46293.pdf
利用LTR的思想重构I2I(以短视频推荐为例)
•Feature
1>Trigger-item Relavance: i2i_score/favor2favor sim/text sim… 2>Item Feature: video_ctr、video_pv、video_comment、
3>Trigger Feature: trigger_ctr、topic_ctr
•Model
1>Loss:Pairwise Loss,同时优化CTR、LikeR、FavorR
2>Lambdamart/Neural Nets

https://blog.csdn.net/huagong_adu/article/details/40710305
(3)Model Based CF
问题定义:使用trainingSet

参考:https://www.comp.nus.edu.sg/~xiangnan/sigir18-deep.pdf
<1>SVD

SVD is Suboptimal for CF
缺点:
1>Missing data和观测到的数据权重相同(>99% 稀疏性)
2>没有正则项,容易过拟合
参考链接:https://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
Adjust SVD
The “SVD” model in the context of recommendation: (latent vector)

•Matrix Factorization (MF) 推荐算法
1>⽤latent vector来表⽰user和item(ID embedding)
2>组合关系⽤ 内积 inner product (衡量user对于某⼀类商品的偏好)
参考:https://datajobs.com/data-science-repo/Recommender-Systems-[Netflix].pdf
•MF ⽤UserID来表⽰⽤户
可以叫做 user-based CF (i.e., find similar users for recom)
•另外⼀种做法是⽤⽤户评价过的item来表⽰⽤户
可以叫做 item-based CF (i.e., find similar items for recom)

SVD++: Fusing User-based and Item-based CF
•MF (user-based CF) ⽤UserID来表⽰⽤户
直接映射ID到隐空间
•FISM (item-based CF) ⽤⽤户评价的item来表⽰⽤户
映射items到隐空间
•SVD++ 混合了两种想法
Netflix 百万⼤奖⽐赛 单模型最佳
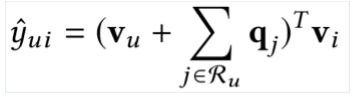
以上部分为信息不全时使用的模型
如何融⼊更多的信息(Side Info)
3 FM: Factorization Machines
•FM 受到前⾯所有的分解模型的启发
•每个特征都表⽰成embedding vector,并且构造⼆阶关系
•FM 允许更多的特征⼯程,并且可以表⽰之前所有模型为特殊的FM(⼤家思考⼀ 下)

Xi部分为线性部分,
参考:https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
4、Rating Prediction is Suboptimal
之前的⼯作都在优化L2 loss:
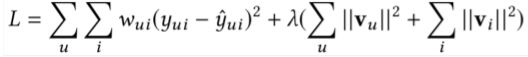
– 很多证据表明
⼀个低MSE模型不⼀定代表排序效果好。。
– Possible Reasons:
- 均⽅误差(e.g., RMSE) and 排序指标之间的分歧
#RMSE:(yui-y’ui) - 观察有偏 – ⽤户总是去对喜欢的电影打分
5、Towards Top-N Recommendation
•现在的⼯作开始逐步朝着优化pairwise ranking loss
1>Known as the Bayesian Personalized Ranking loss (Rendle, UAI’09). 优化相对序关系,⽽不是优化绝对值:

推荐练习:
https://www.zhihu.com/appview/p/32078473
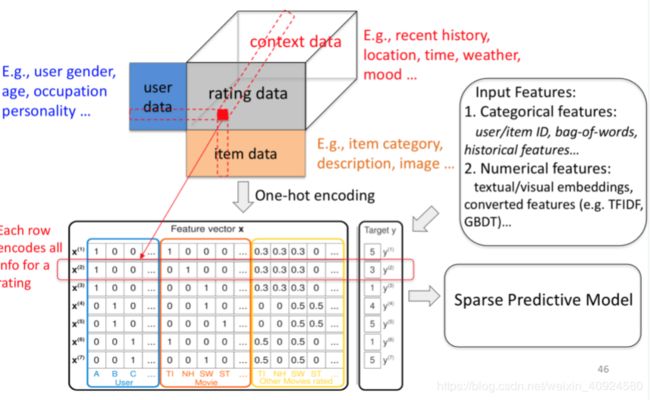
个性化推荐:本项目使用文本卷积神经网络,并使用MovieLens数据集完成电影推荐的任务。
推荐系统在日常的网络应用中无处不在,比如网上购物、网上买书、新闻app、社交网络、音乐网站、电影网站等等等等,有人的地方就有推荐。根据个人的喜好,相同喜好
人群的习惯等信息进行个性化的内容推荐。比如打开新闻类的app,因为有了个性化的内容,每个人看到的新闻首页都是不一样的。这当然是很有用的,在信息爆炸的今天,获取信息的途径和方式多种多样,人们花费时间最多的不再是去哪获取信息,而是要在众多的信息中寻找自己感兴趣的,这就是信息超载问题。为了解决这个问题,推荐系统应运而生。
协同过滤是推荐系统应用较广泛的技术,该方法搜集用户的历史记录、个人喜好等信息,计算与其他用户的相似度,利用相似用户的评价来预测目标用户对特定项目的喜好程度。优点是会给用户推荐未浏览过的项目,缺点呢,对于新用户来说,没有任何与商品的交互记录和个人喜好等信息,存在冷启动问题,导致模型无法找到相似的用户或商品。
为了解决冷启动的问题,通常的做法是对于刚注册的用户,要求用户先选择自己感兴趣的话题、群组、商品、性格、喜欢的音乐类型等信息,比如豆瓣FM:
**
模型设计
**

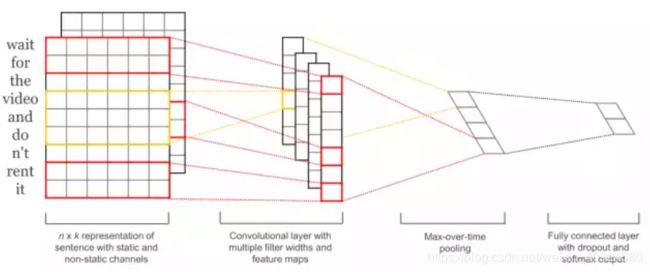
文本卷积网络:
通过研究数据集中的字段类型,我们发现有一些是类别字段,通常的处理是将这些字段转成one hot编码,但是像UserID、MovieID这样的字段就会变成非常的稀疏,输入的维度急剧膨胀,这是我们不愿意见到的,毕竟我这小笔记本不像大厂动辄能处理数以亿计维度的输入:)
所以在预处理数据时将这些字段转成了数字,我们用这个数字当做嵌入矩阵的索引,在网络的第一层使用了嵌入层,维度是(N,32)和(N,16)。
电影类型的处理要多一步,有时一个电影有多个电影类型,这样从嵌入矩阵索引出来是一个(n,32)的矩阵,因为有多个类型嘛,我们要将这个矩阵求和,变成(1,32)的向量。
电影名的处理比较特殊,没有使用循环神经网络,而是用了文本卷积网络,下文会进行说明。
从嵌入层索引出特征以后,将各特征传入全连接层,将输出再次传入全连接层,最终分别得到(1,200)的用户特征和电影特征两个特征向量。
我们的目的就是要训练出用户特征和电影特征,在实现推荐功能时使用。得到这两个特征以后,就可以选择任意的方式来拟合评分了。我使用了两种方式,一个是上图中画出的将两个特征做向量乘法,将结果与真实评分做回归,采用MSE优化损失。因为本质上这是一个回归问题,另一种方式是,将两个特征作为输入,再次传入全连接层,输出一个值,将输出值回归到真实评分,采用MSE优化损失。
实际上第二个方式的MSE loss在0.8附近,第一个方式在1附近,5次迭代的结果。
代码查看:https://github.com/yaoziove/Recommendation2