sklearn+pyqt5实现kmeans算法的使用界面可视化
实习中同事分给我的一个需求:把sklearn中的kmeans算法封装起来,使用界面可视化,提供给不会改代码的领导使用
对pyqt5一窍不通的我经过几天的摸索终于完成任务!参考的内容大多来自于这个帖子:
https://mp.weixin.qq.com/s/Wy1iTYoX7_O81ChMflXXfg 感谢!
首先展示一下封装-可视化后的最终效果:
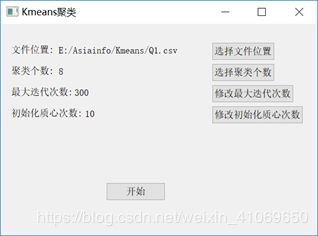
如上图,我在使用界面暴露了聚类个数、最大迭代次数、初始化质心次数这几个参数并设置了默认值,以供使用者自行修改
点击【开始】后执行kmeans算法过程,执行成功之后将结果输出为聚类结果.csv和聚类中心.csv
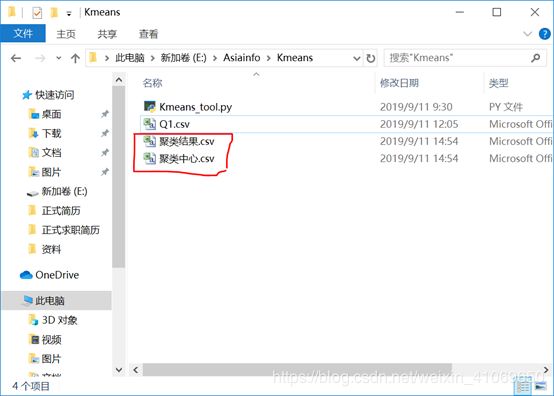
在这个过程中,使用者不需要去代码中修改数据集位置和kmeans算法运行的参数,只需要在可视化界面里面点点点就可以了,下面贴出代码。
首先是可视化页面的代码,首先是界面主体
#界面主体
self.resize(600, 400)
self.setWindowTitle('Kmeans聚类')
插入文件按钮的写法
#选择文件部分设置三个对象:标签1、标签1_、按钮1
#标签1显示“文件位置4个字”
self.lb1 = QLabel("文件位置:", self)
self.lb1.move(20, 40)
#标签1_用来储存文件路径并显示
self.lb1_ = QLabel(self)
self.lb1_.setGeometry(110, 40, 300, 20)
#按钮1用来连接打开文件函数、选择文件位置
self.bt1 = QPushButton('选择文件位置', self)
self.bt1.move(400, 35)
self.bt1.clicked.connect(self.openfile)#连接到打开文件函数这个按钮对应的打开文件函数
#解析上传文件
def openfile(self):
inputfile = QFileDialog.getOpenFileName(self, '打开文件','./')
path=inputfile[0]
self.lb1_.setText(path)
#print(str(path))
#return path我不会截动态图,效果不方便展示,读者可自行复制上述代码运行观察效果。
其他的几个修改参数按钮的设计规则和上个按钮一样,都是两个标签、一个按钮对应一个函数
整个界面主体的函数
def initUI(self):
# 界面主体
self.resize(600, 400)
self.setWindowTitle('Kmeans聚类')
#选择文件部分设置三个对象:标签1、标签1_、按钮1
self.lb1 = QLabel("文件位置:", self)
self.lb1.move(20, 40)
self.lb1_ = QLabel(self)
self.lb1_.setGeometry(110, 40, 300, 20)
self.bt1 = QPushButton('选择文件位置', self)
self.bt1.move(400, 35)
self.bt1.clicked.connect(self.openfile)#连接到打开文件函数
# 选择聚类个数设置三个对象:标签2、标签2_、按钮2
self.lb2 = QLabel("聚类个数:", self)
self.lb2.move(20, 80)
self.lb2_ = QLabel("8",self)
self.lb2_.setGeometry(110, 80, 180, 20)
self.bt2 = QPushButton('选择聚类个数', self)
self.bt2.move(400, 75)
self.bt2.clicked.connect(self.choice_clusters) # 连接到选择聚类中心函数
# 选择最大迭代次数,设置三个对象:标签3、标签3_、按钮3
self.lb3= QLabel("最大迭代次数:", self)
self.lb3.move(20, 120)
self.lb3_ = QLabel("300",self)
self.lb3_.setGeometry(140, 120, 180, 20)
self.bt3 = QPushButton('修改最大迭代次数', self)
self.bt3.move(400, 115)
self.bt3.clicked.connect(self.choice_max_iter) # 连接到选择最大迭代次数函数
# 选择初始化质心次数,设置三个对象:标签4、标签4_、按钮4
self.lb4 = QLabel("初始化质心次数:", self)
self.lb4.move(20, 160)
self.lb4_ = QLabel("10", self)
self.lb4_.setGeometry(160, 160, 180, 20)
self.bt4 = QPushButton('修改初始化质心次数', self)
self.bt4.move(400, 155)
self.bt4.clicked.connect(self.choice_n_init) # 连接到选择最大迭代次数函数
#执行聚类过程
self.bt5 = QPushButton('开始', self)
self.bt5.move(200,300)
self.bt5.clicked.connect(self.kmeans_building)
self.show()
它们对应的操作函数,这几个函数与上面几个按钮一一对应,注意观察
#解析上传文件
def openfile(self):
inputfile = QFileDialog.getOpenFileName(self, '打开文件','./')
path=inputfile[0]
self.lb1_.setText(path)
#print(str(path))
#return path
#选择聚类个数
def choice_clusters(self):
text, ok = QInputDialog.getInt(self, '聚类个数', '请输入聚类个数:', min=1)
if ok:
types_num =int(text)
self.lb2_.setText(str(types_num))
#print(types_num)
#return types_num
#选择最大迭代次数
def choice_max_iter(self):
text, ok = QInputDialog.getInt(self, '修改最大迭代次数', '请输入最大迭代次数:', min=10)
if ok:
iter_num =int(text)
self.lb3_.setText(str(iter_num))
#选择初始化质心次数
def choice_n_init(self):
text, ok = QInputDialog.getInt(self, '修改初始化质心次数', '请输入初始化质心次数:', min=1)
if ok:
init_num =int(text)
self.lb4_.setText(str(init_num))
# kmeans使用函数
def kmeans_building(self):
#取标签1_ 2_ 3_ 4_里面的值
inputfile=str(self.lb1_.text())
types_num=int(self.lb2_.text())
iter_num = int(self.lb3_.text())
init_num=int(self.lb4_.text())
#读取数据
data = pd.read_csv(inputfile, encoding='gb18030', error_bad_lines=True, engine='python')
data2=data.copy()
#数据空值填充
data = self.fillNan(data)
#数据标准化
data = self.standardize(data)
#sklearn中的kmeans算法执行
kmodel = KMeans(n_clusters=types_num,max_iter=iter_num,n_init=init_num).fit(data) # 训练模型
r1 = pd.Series(kmodel.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(kmodel.cluster_centers_) # 找出聚类中心
r3 = self.reStandardize(data2,r2)#将聚类中心还原为标准化前的数值
result_1 = pd.concat([r3, r1], axis=1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
result_1.columns = list(data.columns) + [u'聚类个数'] # 重命名表头
# 把聚类中心文件输出到原始文件的路径下
path = inputfile.split('/')[:-1]
path.append('')
path = '/'.join(path)
result_1.to_csv(path + '聚类中心.csv', encoding='gb18030', index=True)
# 把聚类结果文件输出到原始文件的路径下
result_2 = pd.concat([data2, pd.Series(kmodel.labels_, index=data.index)], axis=1) # 详细输出每个样本对应的类别
result_2.columns = list(data.columns) + [u'聚类类别'] # 重命名表头
result_2.to_csv(path + '聚类结果.csv', encoding='gb18030', index=True) # 保存分类结果
#加入进度条
progress = QProgressDialog(self)
progress.setWindowTitle("请稍等")
progress.setLabelText("正在操作...")
progress.setCancelButtonText("取消")
progress.setMinimumDuration(5)
progress.setWindowModality(Qt.WindowModal)
progress.setRange(0, len(result_2))
for i in range(len(result_2)):
progress.setValue(i)
if progress.wasCanceled():
QMessageBox.warning(self, "提示", "操作失败")
break
else:
progress.setValue(len(result_2))
QMessageBox.information(self, "提示", "操作成功")
其中kmeans使用函数主要跟sklearn的使用有关,非常简单,可以去找别的帖子看一下,在此不再详细讲。
最后附上完整代码
#!/usr/bin/python
# -*- coding: utf-8 -*-
from PyQt5.QtWidgets import QLabel, QWidget, QApplication, QPushButton, QFileDialog, QInputDialog, QProgressDialog,QMessageBox
from PyQt5.QtCore import Qt
import sys
import pandas as pd
from sklearn.cluster import KMeans
class Kmeans_(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
# 界面主体
self.resize(600, 400)
self.setWindowTitle('Kmeans聚类')
#选择文件部分设置三个对象:标签1、标签1_、按钮1
self.lb1 = QLabel("文件位置:", self)
self.lb1.move(20, 40)
self.lb1_ = QLabel(self)
self.lb1_.setGeometry(110, 40, 300, 20)
self.bt1 = QPushButton('选择文件位置', self)
self.bt1.move(400, 35)
self.bt1.clicked.connect(self.openfile)#连接到打开文件函数
# 选择聚类个数设置三个对象:标签2、标签2_、按钮2
self.lb2 = QLabel("聚类个数:", self)
self.lb2.move(20, 80)
self.lb2_ = QLabel("8",self)
self.lb2_.setGeometry(110, 80, 180, 20)
self.bt2 = QPushButton('选择聚类个数', self)
self.bt2.move(400, 75)
self.bt2.clicked.connect(self.choice_clusters) # 连接到选择聚类中心函数
# 选择最大迭代次数,设置三个对象:标签3、标签3_、按钮3
self.lb3= QLabel("最大迭代次数:", self)
self.lb3.move(20, 120)
self.lb3_ = QLabel("300",self)
self.lb3_.setGeometry(140, 120, 180, 20)
self.bt3 = QPushButton('修改最大迭代次数', self)
self.bt3.move(400, 115)
self.bt3.clicked.connect(self.choice_max_iter) # 连接到选择最大迭代次数函数
# 选择初始化质心次数,设置三个对象:标签4、标签4_、按钮4
self.lb4 = QLabel("初始化质心次数:", self)
self.lb4.move(20, 160)
self.lb4_ = QLabel("10", self)
self.lb4_.setGeometry(160, 160, 180, 20)
self.bt4 = QPushButton('修改初始化质心次数', self)
self.bt4.move(400, 155)
self.bt4.clicked.connect(self.choice_n_init) # 连接到选择最大迭代次数函数
#执行聚类过程
self.bt5 = QPushButton('开始', self)
self.bt5.move(200,300)
self.bt5.clicked.connect(self.kmeans_building)
self.show()
# 标准化函数
def standardize(self,df):
for i in df.columns:
df[i] = (df[i] - df[i].mean(axis=0)) / (df[i].std(axis=0))
return df
#反标准化函数
def reStandardize(self,df1,df2):
mean_value=[]
std_value=[]
for i in df1.columns:
mean=df1[i].mean(axis=0)
mean_value.append(mean)
std=df1[i].std(axis=0)
std_value.append(std)
for indexs in df2.index:
df2.loc[indexs]=df2.loc[indexs]*std_value+mean_value
return df2
# 填充空值函数
def fillNan(self,dataframe):
for i in dataframe.columns:
dataframe[i] = dataframe[i].fillna(dataframe[i].mean())
return dataframe
#解析上传文件
def openfile(self):
inputfile = QFileDialog.getOpenFileName(self, '打开文件','./')
path=inputfile[0]
self.lb1_.setText(path)
#print(str(path))
#return path
#选择聚类个数
def choice_clusters(self):
text, ok = QInputDialog.getInt(self, '聚类个数', '请输入聚类个数:', min=1)
if ok:
types_num =int(text)
self.lb2_.setText(str(types_num))
#print(types_num)
#return types_num
#选择最大迭代次数
def choice_max_iter(self):
text, ok = QInputDialog.getInt(self, '修改最大迭代次数', '请输入最大迭代次数:', min=10)
if ok:
iter_num =int(text)
self.lb3_.setText(str(iter_num))
#选择初始化质心次数
def choice_n_init(self):
text, ok = QInputDialog.getInt(self, '修改初始化质心次数', '请输入初始化质心次数:', min=1)
if ok:
init_num =int(text)
self.lb4_.setText(str(init_num))
# kmeans使用函数
def kmeans_building(self):
#取标签里面的值
inputfile=str(self.lb1_.text())
types_num=int(self.lb2_.text())
iter_num = int(self.lb3_.text())
init_num=int(self.lb4_.text())
#读取数据
data = pd.read_csv(inputfile, encoding='gb18030', error_bad_lines=True, engine='python')
data2=data.copy()
#数据空值填充
data = self.fillNan(data)
#数据标准化
data = self.standardize(data)
#sklearn中的kmeans算法执行
kmodel = KMeans(n_clusters=types_num,max_iter=iter_num,n_init=init_num).fit(data) # 训练模型
r1 = pd.Series(kmodel.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(kmodel.cluster_centers_) # 找出聚类中心
r3 = self.reStandardize(data2,r2)#将聚类中心还原为标准化前的数值
result_1 = pd.concat([r3, r1], axis=1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
result_1.columns = list(data.columns) + [u'聚类个数'] # 重命名表头
# 把聚类中心文件输出到原始文件的路径下
path = inputfile.split('/')[:-1]
path.append('')
path = '/'.join(path)
result_1.to_csv(path + '聚类中心.csv', encoding='gb18030', index=True)
# 把聚类结果文件输出到原始文件的路径下
result_2 = pd.concat([data2, pd.Series(kmodel.labels_, index=data.index)], axis=1) # 详细输出每个样本对应的类别
result_2.columns = list(data.columns) + [u'聚类类别'] # 重命名表头
result_2.to_csv(path + '聚类结果.csv', encoding='gb18030', index=True) # 保存分类结果
#加入进度条
progress = QProgressDialog(self)
progress.setWindowTitle("请稍等")
progress.setLabelText("正在操作...")
progress.setCancelButtonText("取消")
progress.setMinimumDuration(5)
progress.setWindowModality(Qt.WindowModal)
progress.setRange(0, len(result_2))
for i in range(len(result_2)):
progress.setValue(i)
if progress.wasCanceled():
QMessageBox.warning(self, "提示", "操作失败")
break
else:
progress.setValue(len(result_2))
QMessageBox.information(self, "提示", "操作成功")
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = Kmeans_()
sys.exit(app.exec_())这个帖子写的比较匆忙,后续会不断完善,有问题可以提出来互相探讨。