爬虫(一)request和BeautifulSoup
先说明,我也是新手。我也是昨晚突然有兴趣才看的爬虫。我是在知乎找的教程。改动很少(有一句扑街了,我改了)。
主要是想记录理解的东西。Show the Code:
import requests
from bs4 import BeautifulSoup
comments = []
r = requests.get('http://tieba.baidu.com/f?kw=%E5%8D%8E%E5%8D%97%E5%86%9C%E4%B8%9A%E5%A4%A7%E5%AD%A6&fr=index&red_tag=y3160164477')
soup = BeautifulSoup(r.content, 'lxml')
Tags = soup.find_all('li', attrs={"class": ' j_thread_list clearfix'})
for li in Tags:
comment = {}
b = li.find('span', attrs={"class": "frs-author-name-wrap"})
comment["author"] = b.text.strip()
a = li.find('a', attrs={"class": "j_th_tit "})
comment["title"] = a.text.strip()
c = li.find('div', attrs={"class": "threadlist_abs threadlist_abs_onlyline "})
comment["read"] = c.text.strip()
d = li.find('span', attrs={"class": "threadlist_rep_num center_text"})
comment["reply"] = d.text.strip()
comments.append(comment)
with open(r'C:\Users\xin\Desktop\6.txt', 'a+', encoding='utf-8') as f:
for word in comments:
f.write('标题:{} \t发帖人:{} \t发帖内容:{} \t帖子回复量:{} \t\n'.format(word["title"],
word["author"], word["read"], word["reply"]))逐步的解释。
import requests
from bs4 import BeautifulSoup不多说,要先安装requests和bs4,命令行输入pip install requests这种形式安装。然后import。我们装的是bs4库,但只需要里面的BeautifulSoup。
comments = []
r = requests.get('http://tieba.baidu.com/f?kw=%E5%8D%8E%E5%8D%97%E5%86%9C%E4%B8%9A%E5%A4%A7%E5%AD%A6&fr=index&red_tag=y3160164477')comments是用来保存每个信息comment的。
request.get(url)就是向你说明的url发送一个请求。具体的操作我没仔细了解,想着以后遇到了再细看。但发送请求这个操作很容易了解,毕竟我们想要抓取的内容实质上是放在一个服务器上面的,因此我们得需要先请求内容。这个网址是华农贴吧的,23333。
这个时候r其实就是我们加载的网页了。我们打开华农贴吧。看到第一帖子是:

然后Chrome按F12可以查看代码。在Chrome的代码界面左上角,有个箭头,或者我们直接按CTRL+Shift+C。接着按下我们要的数据。这一篇里面我们要标题,作者,回复数,还有发帖的内容。鼠标按在回复量上面,我们可以看到有一行代码被选择。我们右键Copy它对应的Xpath:
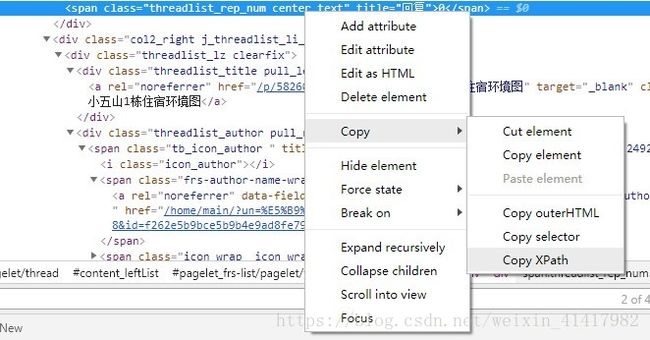
紧接着继续复制其他元素的Xpath。我们最后有:

可以看到这四个数据都在一个目录下,就是下面。所以我们可以知道,每一个帖子的基本内容都是用一个来囊括。所以我们需要先找到所有的标签内容。
soup = BeautifulSoup(r.content, 'lxml')
Tags = soup.find_all('li', attrs={"class": ' j_thread_list clearfix'})这里是BeautifulSoup的使用方法。文档写着:
“features=’lxml’ for HTML and features=’lxml-xml’ for “XML.”
我们r.content是属于HTML的,因为是网页,所以使用'lxml'。
有些是用r.text的。我查了区别,r.text是将网页变成文本形式了,也就是如果你要抓取图片的话就不能用r.text了。r.content是以二进制的形式读取网页。我们这里用r.content。
我们构建的soup是一个BeautifulSoup返回的对象,因此我们可以使用内置的函数find_all找到所有我们需要的内容。前文提到我们需要的数据都在标签下面,所以我们找到对应的代码(CTRL+F可以查找),有

所以我们要查找的内容是第一行的标签,标签里面的attr(属性)为class='j_thread_list clearfix'。给了条件,我们利用find_all找到所有的内容。
for li in Tags:
comment = {}
b = li.find('span', attrs={"class": "frs-author-name-wrap"})
comment["author"] = b.text.strip()
a = li.find('a', attrs={"class": "j_th_tit "})
comment["title"] = a.text.strip()
c = li.find('div', attrs={"class": "threadlist_abs threadlist_abs_onlyline "})
comment["read"] = c.text.strip()
d = li.find('span', attrs={"class": "threadlist_rep_num center_text"})
comment["reply"] = d.text.strip()
comments.append(comment)Tags包含很多个的内容。我们进行迭代,创建一个comment字典来保存每一条帖子的内容。这里我们不用find_all而是用find来匹配第一我们要求的内容。重新看回复的代码。为

我们需要找到一个的标签,它的属性attr为class=threadlist_rep_num center_text。然后它的文本也就是text,我们将它strip()(即去除句首句尾的换行符和空格),就是我们要的内容了。
with open(r'C:\Users\xin\Desktop\6.txt', 'a+', encoding='utf-8') as f:
for word in comments:
f.write('标题:{} \t发帖人:{} \t发帖内容:{} \t帖子回复量:{} \t\n'.format(word["title"],
word["author"], word["read"], word["reply"]))创建文件进行记录就不讲了…
最后的结果会是(会跟我现在截图的不一样,因为这是我昨晚爬的):

其实这里你可以发现它读取不了置顶的帖子,因为置顶的帖子它的属性不同其他帖子。但是我也不想继续细究,看完这个懂了之后我就去爬了58同城的二手房价格。
效果如图:
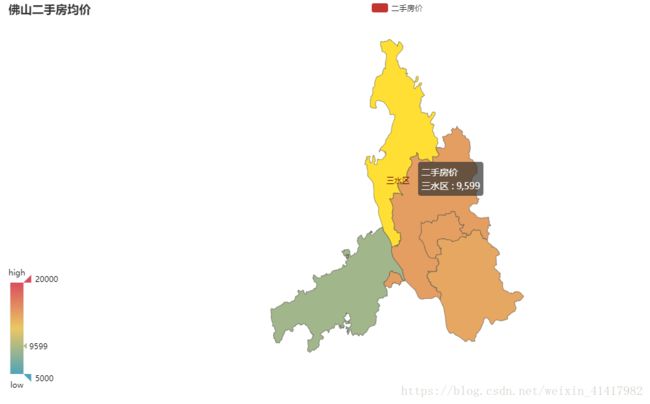
有空再细讲。