python爬虫之scrapy 框架学习复习整理二--scrapy.Request(自己提取url再发送请求)
文章目录
- 说明:
- 我的配置:
- 目标网站:
- 今天爬虫(手动提取url,发送get请求)
- 1、创建项目+初始化爬虫文件:
- 2、在setting中配置
- 3、修改items.py:
- 4、修改爬虫程序:spiders/scrapyd.py
- ①、scrapy.Request()
- ②、直接上我的代码:
- 5、管道处理(一般都在这里进行数据清洗和数据储存操作):pipelines.py
- 1、测试spider是什么:
- 2、保存到MongoDB数据库:
- 6、我刚学scrapy对itmes模块的一个疑问:
- 1、我改为item={}
- 2、我改为:item = ScrapydCnItem()
- 3、对比,得出我认为的结论:
说明:
今天主要学习一下翻页的功能,手动翻页的效果,前面的基础操作这里不不再依次讲解截图说明了,如果不太懂,可以参考我的上一篇scrapy博客:
https://blog.csdn.net/weixin_42081389/article/details/102390279
我的配置:
windows10系统
python3.6
目标网站:
http://lab.scrapyd.cn/
因为这个网站是get,响应的页面就能找到下一页的url,我记得之前测试翻页是用的腾讯招聘网站,但是现在腾讯招聘的页面改成异步获取的json数据了,如果真的爬取,我觉得直接使用requests模块比较方便,如果用scrapy,可以直接把开始的start_urls列表换成一个异步url列表集,我感觉使用scrapy那样爬取多此一举了。
比如这样,url列表集:
start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1570587185160&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex={}&pageSize=10&language=zh-cn&area=cn'.format(i) for i in range(1,101)]
不过这样的我不写,这样的和我的第一个博客没有什么区别,只不过初始化的url列表数量多了而已。
今天爬虫(手动提取url,发送get请求)
1、创建项目+初始化爬虫文件:
scrapy startpoject scrapyd_cn
cd scrapyd_cn
scapy genspider scrapyd lab.scrapyd.cn/
生成文件:
2、在setting中配置
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'
ROBOTSTXT_OBEY = False
_LEVEL = 'DEBUG'
LOG_LEVEL = "WARNING"
ITEM_PIPELINES = {
'scrapyd_cn.pipelines.ScrapydCnPipeline': 300,
}
3、修改items.py:
这里我们只要三维数据,需要三个字段即可。

import scrapy
class ScrapydCnItem(scrapy.Item):
# define the fields for your item here like:
text = scrapy.Field()
author = scrapy.Field()
url = scrapy.Field()
# pass
4、修改爬虫程序:spiders/scrapyd.py
①、scrapy.Request()
这个只是和之前比这多了一个翻页功能,这个scrapy.Request()
里面有俩个必须要传递的参数,一个是url,一个是返回的函数,这里的parse是本身的方法中,继续处理数据直至页面结束,可以自己写多个方法,根据项目和网站需要定义方法,和需要的返回方法中。
# 翻页
yield scrapy.Request(url=next_page, callback=self.parse)
其中还有几个常用的参数:
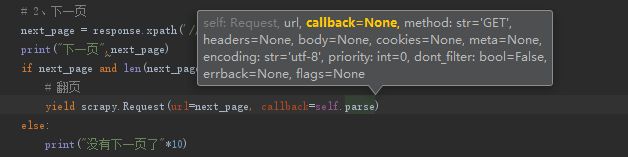
scrapy.Request()中几个常用参数解释:
url:必填:
callback:必填:请求之后返回到方法中处理然后数据
enthod:默认是get,如果是post需要自己手动更改,我这里是get,忽略了。
cookies:字典类型,有些网站需要cookies,可以携带上单个的cookies。
headers:字典类型,请求头,我的这个在setting里面加入了user-agent,这里不加也可以。
meta:这个很常用,这里是方法之间传递参数的
dont_filter:是否开启过滤,默认关闭,开启之后爬取过的url,下一次不会再爬取
errback:和callback类似,但是是处理对应的请求url报错时会进入errback,可以进入将报错的url打印出来或者单独保留下来,后续手动测试查找报错原因
②、直接上我的代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapyd_cn.items import ScrapydCnItem
class ScrapydSpider(scrapy.Spider):
name = 'scrapyd'
allowed_domains = ['lab.scrapyd.cn']
start_urls = ['http://lab.scrapyd.cn//']
def parse(self, response):
# 1、提取每一页的数据
div_list = response.xpath('//*[@id="main"]/div[@class="quote post"]')
for div in div_list:
# extract_first() 和 get() 返回的结果是一样的。
text = div.xpath('./span[@class="text"]/text()').get()
# author = div.xpath('.//*[@class="author"]/text()').extract_first()
author = div.xpath('.//*[@class="author"]/text()').get()
url = div.xpath('.//a[contains(text(),"详情")]/@href').get()
# print("div", text, author, url)
item = ScrapydCnItem()
item['text'] = text
item['author'] = author
item['url'] = url
yield item
# 2、下一页
next_page = response.xpath('//*[@id="main"]//li[@class="next"]/a/@href').get()
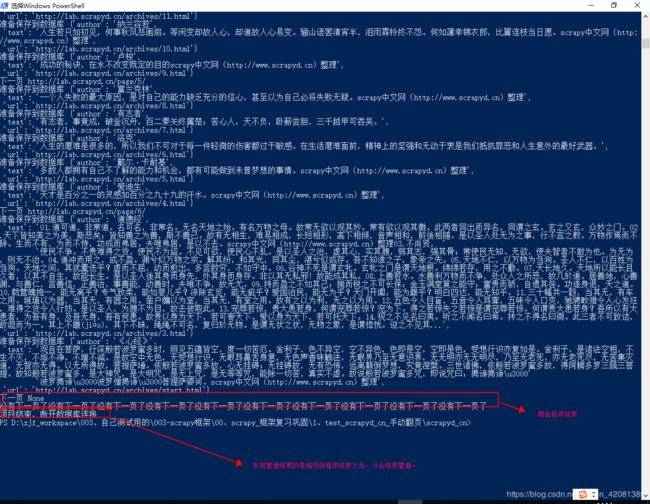
print("下一页",next_page)
if next_page and len(next_page) > 5:
# 翻页
yield scrapy.Request(url=next_page, callback=self.parse)
else:
print("没有下一页了"*10)
5、管道处理(一般都在这里进行数据清洗和数据储存操作):pipelines.py
1、测试spider是什么:
下面是我测试的方法,之前使用过name属性进行过对不同的数据进行清洗和储存。你也可以自己研究测试。
class ScrapydCnPipeline(object):
def process_item(self, item, spider):
# print("pipelines.py",item,spider)
# 1、测试spider是什么?,结果发现spdier就是我们爬虫程序,因为一个项目里面可以有多个爬虫程序,
# print("pipelines.py",dir(spider)) # 打印出spider含有的属性和方法
# ['allowed_domains', 'close', 'crawler', 'custom_settings', 'from_crawler', 'handles_request', 'log', 'logger', 'make_requests_from_url', 'name', 'parse', 'set_crawler', 'settings', 'start_requests', 'start_urls', 'update_settings']
# print("pipelines.py", spider.name)
# 发现我的爬虫程序的name是唯一的,如果一个项目有多个爬虫程序时,可以根据name进行分别进行建立不同的方法处理(比如不同的爬虫数据,需要存入不同的数据库中,或者需要的字段还不一致)
# pipelines.py scrapyd
# 2、处理返回的数据
return item
2、保存到MongoDB数据库:
代码:
from pymongo import MongoClient
class ScrapydCnPipeline(object):
def open_spider(self, spider):
print("准备创建一个数据库")
# 这个会在项目开始时第一次进入pipelines.py进入,之后不再进入
# 建立于MongoClient 的连接:
self.client = MongoClient('localhost', 27017)
# 得到数据库
self.db = self.client['111_test_database_scrapyd_cn']
# 得到一个集合
self.collection = self.db['111_test_collection_scrapyd_cn']
def close_spider(self, spider):
print('项目结束,断开数据库连接')
# 这个会在结束时开始时第一次进入pipelines.py进入,之后不再进入
self.client.close()
def process_item(self, item, spider):
# print("pipelines.py",item,spider)
# 1、测试spider是什么?,结果发现spdier就是我们爬虫程序,因为一个项目里面可以有多个爬虫程序,
# print("pipelines.py",dir(spider)) # 打印出spider含有的属性和方法
# ['allowed_domains', 'close', 'crawler', 'custom_settings', 'from_crawler', 'handles_request', 'log', 'logger', 'make_requests_from_url', 'name', 'parse', 'set_crawler', 'settings', 'start_requests', 'start_urls', 'update_settings']
# print("pipelines.py", spider.name)
# 发现我的爬虫程序的name是唯一的,如果一个项目有多个爬虫程序时,可以根据name进行分别进行建立不同的方法处理(比如不同的爬虫数据,需要存入不同的数据库中,或者需要的字段还不一致)
# pipelines.py scrapyd
# 2、处理返回的数据
# print("process_item", item, spider)
# print("type", type(item))
# 储存到数据库
print("准备保存到数据库",item)
self.collection.save(dict(item))
return item
打印出的页面显示:

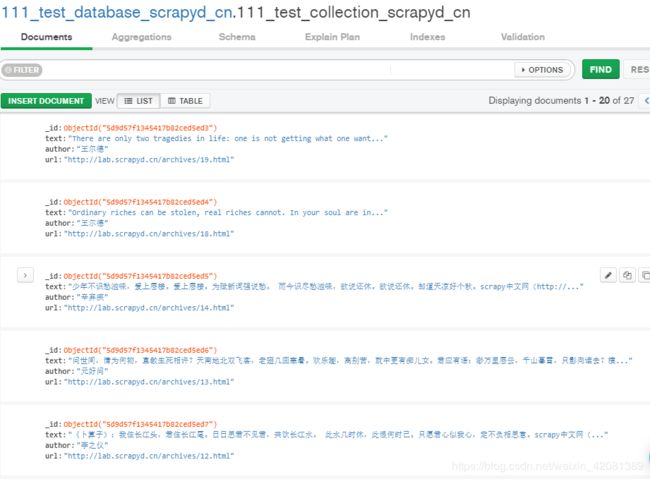
数据MongoDB存入成功:
6、我刚学scrapy对itmes模块的一个疑问:
不知道刚学scrapy时有没有和我一样,有这样一个疑问,爬虫程序中,我不继承items中的ScrapydCnItem类,直接用一个字典代替,其实,我的理解,如果不涉及过的爬虫数据类型保存,是一样的,但是如果涉及过多的类型数据保存,会影响数据的混乱保存。比如进入管道中的,一个程序中,我就有好几种数据分别保存到不同的数据库,这时,继承items中的dict数据进入管道pipelines.py就可以用
isinstance(item,ScrapydCnItem)
返回的是True和False,进行保存自己需要的数据类型,到对应的需求数据库中。
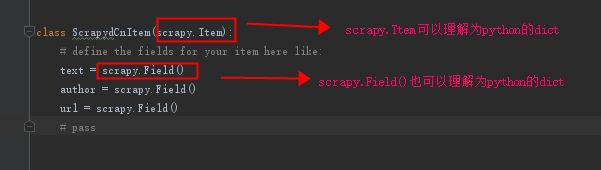
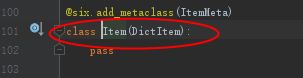
scrapy.Item进入源文件是继承一个dict类:
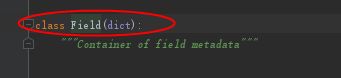
scrapy.Field() 进入源文件也是继承一个dict
爬虫文件中,我测试发现定义一个字典返回的管道数据中储存,结果和定义的items的类ScrapydCnItem最后进入管道的结果是一样的,但是类型不一样,最后我找到一个可以理解这定义这个items中ScrapydCnItem类dict的原因:
1、我改为item={}
爬虫spider/scrapyd.py中,改为item = {}:
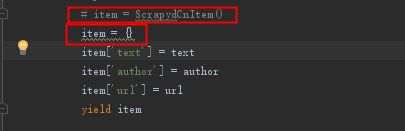
pipelines.py中打印到处item类型,和print(“isinstance”,isinstance(item,ScrapydCnItem))
其中这个ScrapydCnItem类,是items.py中的目标数据字段的类。
from scrapyd_cn.items import ScrapydCnItem

上面的打印结果:

2、我改为:item = ScrapydCnItem()
爬虫spider/scrapyd.py中
pipelines.py中,用来打印出我的疑问

打印出管道中的结果:
3、对比,得出我认为的结论:
通过上面俩个打印出的结论,我也就自己给出了我的疑问答案,那就是,items的文件,在爬虫程序中继承过来的字段类型,看着是字典,但是可以根据这个进行不同的数据类型(根据继续的items中的类来体现),根据isinstance(item,ScrapydCnItem),ScrapydCnItem要改为你实际需求的数据类名,进行不同数据类型分开保存。
这也就是我自己对这个items中的定义目标数据字段的理解。