collections 模块
文章目录
- python内置数据类型
- collections 模块
- OrderedDict 有序字典
- defaultdict 默认字典
- namedtuple 可命名元组
- Counter 计数器
- deque 双端队列
python内置数据类型
python内置数据类型包括 int float complex str list tuple dict set,也就是启动python这些类就加载到内存中,不用导入就可以用。
有些数据类型不常用,放到了collections包中。使用时再导入。类似functools模块,把不常用的内置函数(方法)放到该模块
collections 模块
collections包源码
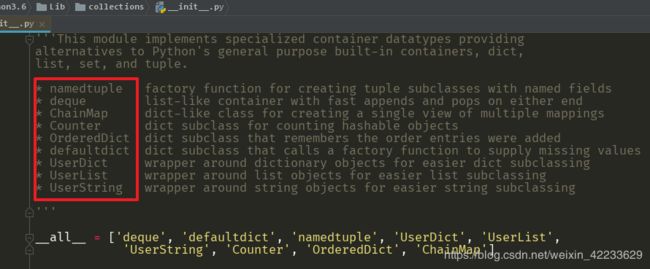
OrderedDict 有序字典
3.6前字典key都是无序的,在对dict迭代时,无法确定key的顺序,不能使用for循环,如果要保持key插入的顺序(类似列表每个值都有索引),可使用OrderedDict,
Dictionary that remembers insertion order
from collections import OrderedDict
d = dict({('a', 1), ('b', 2), ('c', 3)}) # 初始化字典
print(d)
od = OrderedDict([('a', 1), ('c', 2), ('d', 3)])
print(od)
for k in od:
print(k, od[k]) # 可以按键的顺序循环了
od['b'] = 'v3'
print(od)
运行结果
{'c': 3, 'b': 2, 'a': 1}
OrderedDict([('a', 1), ('c', 2), ('d', 3)])
a 1
c 2
d 3
OrderedDict([('a', 1), ('c', 2), ('d', 3), ('b', 'v3')])
defaultdict 默认字典
defaultdict括号里面的类型为设置的默认的可调用的数据类型,如list,dict,tuple 都是可调用的的(可调用的意思是加括号就可执行)。如果要放一个字符串,而字符串是不可调用的,可以用匿名函数代替。
- 例1,值为list类型:
from collections import defaultdict
values = [11, 22, 33, 44, 55, 66, 77, 88, 99, 90]
my_dict = defaultdict(list) # 默认字典,值的类型为list
print(my_dict) # defaultdict(, {}) # 空字典 默认值为列表
print(my_dict['b']) # [] 增加了键为‘b’,并且值为空列表
my_dict['a'].append(1) # 增加了‘a’键, 值为空列表并增加了1
print(my_dict) # defaultdict(, {'b': [], 'a': [1]})
for value in values:
if value > 66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
print(my_dict) # defaultdict(, {'b': [], 'a': [1], 'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]})
运行结果
defaultdict(<class 'list'>, {})
[]
defaultdict(<class 'list'>, {'b': [], 'a': [1]})
defaultdict(<class 'list'>, {'b': [], 'a': [1], 'k2': [11, 22, 33, 44, 55, 66], 'k1': [77, 88, 99, 90]})
- 例1,值为字典,元组类型:
d = defaultdict(dict)
print(d)
print(d['a'])
a = defaultdict(tuple)
print(a)
a['nn'] = (2, 4)
print(a)
运行结果
defaultdict(<class 'dict'>, {})
{}
defaultdict(<class 'tuple'>, {})
defaultdict(<class 'tuple'>, {'nn': (2, 4)})
- 例3,值为lambda函数类型:
d = defaultdict(lambda :'de')
print(d['kk'])
print(d['i']) # 如果没有设置就调用函数默认返回值
d['aa'] = 'jjjj'
print(d['aa']) # 如果设置了值就返回设置的值
运行结果
de
de
jjjj
源码内容:

这里的factory指的的工厂模式,设计模式的一种,类似工厂的流水线,设置了什么类型,该字典的值都是默认的类型。设计模式中的单例模式指类只能被实例化一次,下次实例化该类时就使用用第一次创建好的对象,一般不修改该对象空间的内容,以便重复使用,可以节省空间,优化配置。使用场景:如在打开项目时配置文件加载一次,也就是实例化一次文件中的类,以便后续项目中频繁的使用而不是每次使用时都创建一个实例。直接在一个大字典中找到该对象来调用。使用hash方式查找,这样速度就很快。
namedtuple 可命名元组
一般来说元组中的每个值都没有特定的意义,如果你希望以特定的格式来描述时,就可以用可命名元组,命名元祖维持了元组的特点:不可变(不能增减,修改值)。当元组有很多值,且希望用户看到每个值的含义。可以通过名字的形式访问他
例,通过某人的年月日访问生日:
from collections import namedtuple
birth = namedtuple('struct_time', ['year', 'month', 'day'])
print(birth)
b1 = birth(2018, 9, 5)
print(b1.year) # 2018
print(b1.month) # 9
print(b1.day) # 5
print(b1) # struct_time(year=2018, month=9, day=5)
运行结果
<class '__main__.struct_time'>
2018
9
5
struct_time(year=2018, month=9, day=5)
可命名元祖常用的场景是:
namedtuple就像一个只有属性而没有方法的一个类的对象。当定义一个类,这个类的属性永远不变且不可变时,而且没有其他方法的提高安全性,还可以用元组里面的名字访问属性值时,可以使用可命名元祖。
如上例year,month 都像一个属性的值,而b1像一个对象
例
class A:
pass
print(A, type(A)) # 类的type就是type,python中一切皆对象,广义来说,所有类都是type的对象。
B = A
print(B, type(B)) #
a = A()
print(a, type(a)) # <__main__.A object at 0x00000248FFF0E320> 为什么B的实例化对象不属于B呢?因为没有定义新的类B,B只是引用了变量A,实际还是指向的存有类A同一个内存地址
# 如需一旦实例化,就不能修改属性的值了, 如同不能元组中的值,就使用namedtuple。
from collections import namedtuple
birth = namedtuple('Struct_time', ['year', 'month', 'day'])
print(birth, type(birth)) #
# 实际是定义了Struct_time类,birth = Struct_time,变量引用, 类的名字始终叫Struct_time,这三个都是类Struct_time的属性
b1 = birth(2018, 9, 5) # birth的实例化对象
print(b1, type(b1)) # Struct_time(year=2018, month=9, day=5) Counter 计数器
Counter: 计数器,统计字符出现的次数
源码内容

from collections import Counter
c = Counter('ababddfgasdfdff')
print(c) # Counter({'d': 4, 'f': 4, 'a': 3, 'b': 2, 'g': 1, 's': 1})
b = Counter('kd9f8298487t5o3rkhsdf5df6566565')
print(b) # Counter({'5': 5, '6': 4, 'd': 3, 'f': 3, '8': 3, 'k': 2, '9': 2, '2': 1, '4': 1, '7': 1, 't': 1, 'o': 1, '3': 1, 'r': 1, 'h': 1, 's': 1})
c = Counter('which')
c.update('witch')
print(c['h']) # 3
d = Counter('watch')
c.update(d)
print(c['h']) # 4 更新的次数已经记下来了
deque 双端队列
在模块queue中的Queue,维持一个队列,严格先进先出,里面的值看不到,
例:
import queue
q = queue.Queue() # 维持一个队列,严格先进先出,里面的值看不到,不能插入值。
q.put(1)
q.put(2)
q.put('aaa')
q.put([1, 2, 3])
q.put({'k', 'v'})
print(q.get()) # 取出一个值就没了
print(q.get())
print(q.get())
print(q.get())
print(q.get())
运行结果
1
2
aaa
[1, 2, 3]
{'k', 'v'}
deque 双端队列基本用法
例:
from collections import deque
dq = deque()
dq.append(1)
dq.append(2)
print(dq) # deque([1, 2])
dq.appendleft(3)
dq.appendleft(7)
print(dq) # deque([7, 3, 1, 2])
dq.insert(2, 77)
print(dq) # deque([7, 3, 77, 1, 2])
print(dq.pop())
print(dq.popleft())
print(dq) # deque([3, 77, 1])
源码解释:

双端队列和普通的队列不一样的是,可以从左边,右边,中间取值和放值
和列表的底层运行机制的区别:
列表如果在左边或中间放一个值,整个列表的数据都会挪位置,给新值腾位置,其对应的索引也会变化,所以十分耗费时间。
图示

对于双端队列来说,在某个地方放值,速度很快。
双端队列是一种新的存储结构,在C语言中叫链表,
原理如下
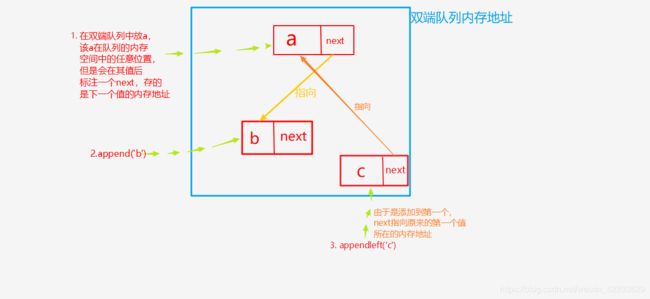

所以无论在什么地方插入值都是随便找个内存放,通过每个值的内存地址的指向就可以把整个队列串行起来就可以了,所以使用双端队列插入或删除值时,比列表快很多倍。值越多,对比越明显。但是使用索引查找值时时间差不多。