TextCNN进行文本分类多标签分类
TextCNN
数据集下载:链接:https://pan.baidu.com/s/14qRe9cxtSS51anKOcpy6dA
提取码:zygc
TextCNN是卷积神经网络的一种(其实就是一个简单的神经网络)。
卷积神经网络是指-至少在网络的一层中使用了卷积运算代替矩阵乘法运算。其具有以下三个优点:
• 稀疏交互:不是每个输出单元与输入单元都产生交互
• 参数共享:多个函数相同参数
• 等变表示:平移
使用卷积神经网络进行自然语言处理有以下三个优点:
• 共享卷积核 优化计算量
• 无需手动选择特征
• 深层次抽取信息丰富
但是也存在如下缺点:
• 对数据量有要求
• 需要大量计算资源 : gpu
• 难以直观解释
**
TextCNN与文本分类
**
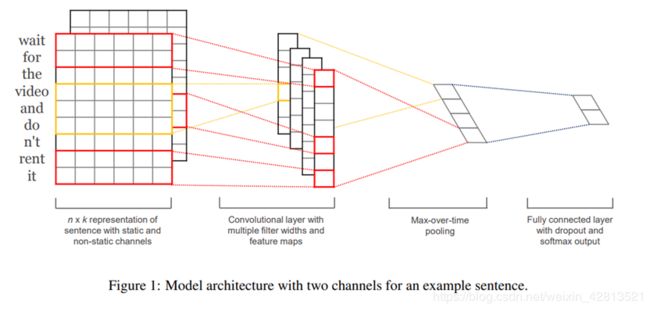
上图是TextCNN的结构模型,对于输入层来说可以有以下几种:
• CNN-rand
设计好 embedding_size 这个超参数后, 对不同单词的向量作随机初始化, 后续BP的时候作调整
• CNN-Static
拿 pre-trained vectors from word2vec, FastText or GloVe 直接用, 训练过程中不再调整词向量. 这也算是迁移学习的一种思想
• CNN-non-static
pre-trained vectors + fine tuning , 即拿word2vec训练好的词向量初始化, 训练过程中再对它们微调
• CNN-multiple channel
类比于图像中的RGB通道, 这里也可以用 static 与 non-static 搭两个通道来搞.
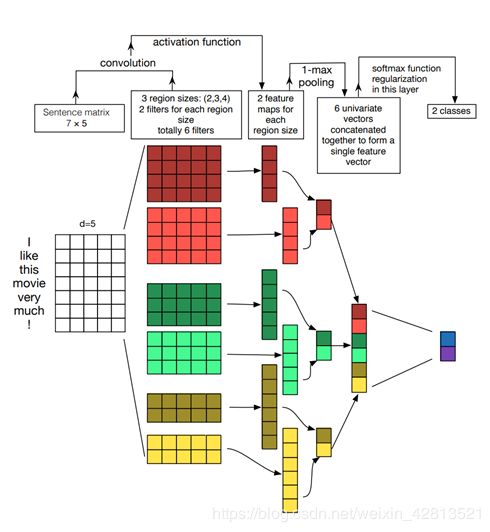
中间隐藏层一般都是选用不同size的卷积核(用来模拟单词之间的关系)然后接上全局平均池化,最后再接全连接层softmax进行分类。
具体如下:
Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
图像中可以利用 (R, G, B) 作为不同channel;
文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法
图像是二维数据;
文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。
特征:这里用的是词向量表示方式
数据量较大:可以直接随机初始化embeddings,然后基于语料通过训练模型网络来对embeddings进行更新和学习。
数据量较小:可以利用外部语料来预训练(pre-train)词向量,然后输入到Embedding层,用预训练的词向量矩阵初始化embeddings。(通过设置weights=[embedding_matrix])。
静态(static)方式:训练过程中不再更新embeddings。实质上属于迁移学习,特别是在目标领域数据量比较小的情况下,采用静态的词向量效果也不错。(通过设置trainable=False)
非静态(non-static)方式:在训练过程中对embeddings进行更新和微调(fine tune),能加速收敛。(通过设置trainable=True)
import os
import re
import sys
import jieba
import pandas as pd
import numpy as np
import tensorflow as tf
root='路径'
df = pd.read_csv(root,header=None).rename(columns={0:'label',1:'content'})
def load_stop_words(stop_word_path):
'''
加载停用词
:param stop_word_path:停用词路径
:return: 停用词表 list
'''
# 打开文件
file = open(stop_word_path, 'r', encoding='utf-8')
# 读取所有行
stop_words = file.readlines()
# 去除每一个停用词前后 空格 换行符
stop_words = [stop_word.strip() for stop_word in stop_words]
return stop_words
def clean_sentence(line):
line = re.sub(
"[a-zA-Z0-9]|[\s+\-\|\!\/\[\]\{\}_,.$%^*(+\"\')]+|[::+——()?【】《》“”!,。?、~@#¥%……&*()]+|题目", '',line)
words = jieba.cut(line, cut_all=False)
return words
stopwords_path='路径'
stop_words=load_stop_words(stopwords_path)
def sentence_proc(sentence):
'''
预处理模块
:param sentence:待处理字符串
:return: 处理后的字符串
'''
# 清除无用词
words = clean_sentence(sentence)
# 过滤停用词
words = [word for word in words if word not in stop_words]
# 拼接成一个字符串,按空格分隔
return ' '.join(words)
def proc(df):
df['content']=df['content'].apply(sentence_proc)
return df
df=proc(df)
***#Vocab***
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import MultiLabelBinarizer
vocab_size=30000
padding_size=200
text_preprocesser = Tokenizer(num_words=vocab_size, oov_token="" )
text_preprocesser.fit_on_texts(df['content'])
x = text_preprocesser.texts_to_sequences(df['content'])
word_dict = text_preprocesser.word_index
x = pad_sequences(x, maxlen=padding_size,padding='post', truncating='post')
#多分类
df['subject']=df['label'].apply(lambda x:x.split()[1])
#进行one-hot编码
from sklearn.preprocessing import LabelBinarizer
lb=LabelBinarizer()
lb.fit(df['subject'])
y=lb.transform(df['subject'])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(x,y,test_size=0.2,random_state=42)
#构建模型
import logging
from tensorflow.keras import Input
from tensorflow.keras.layers import Conv1D, MaxPool1D, Dense, Flatten, concatenate, Embedding
from tensorflow.keras.models import Model
from tensorflow.keras.utils import plot_model
from tensorflow.keras.callbacks import EarlyStopping
from pprint import pprint
# from utils.metrics import micro_f1,macro_f1
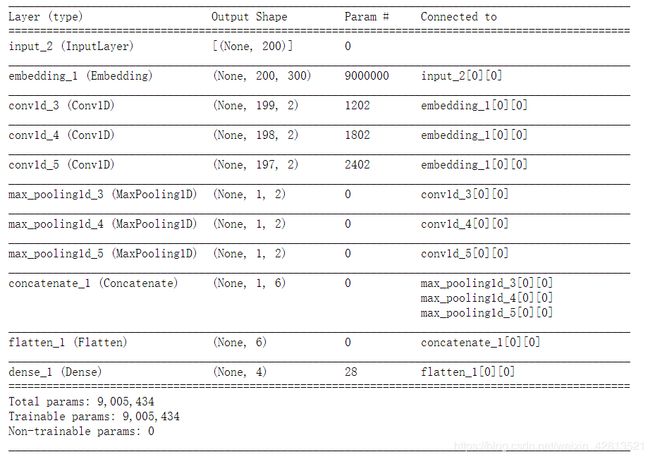
def TextCNN(max_sequence_length, max_token_num, embedding_dim, output_dim, model_img_path=None, embedding_matrix=None):
"""
TextCNN:
1.embedding layers,
2.convolution layer,
3.max-pooling,
4.softmax layer.
"""
x_input = Input(shape=(max_sequence_length,))
logging.info("x_input.shape: %s" % str(x_input.shape)) # (?, 60)
if embedding_matrix is None:
x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length)(x_input)
else:
x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length,
weights=[embedding_matrix], trainable=True)(x_input)
logging.info("x_emb.shape: %s" % str(x_emb.shape)) # (?, 60, 300)
pool_output = []
kernel_sizes = [2, 3, 4]
for kernel_size in kernel_sizes:
c = Conv1D(filters=2, kernel_size=kernel_size, strides=1)(x_emb)
p = MaxPool1D(pool_size=int(c.shape[1]))(c)
pool_output.append(p)
logging.info("kernel_size: %s \t c.shape: %s \t p.shape: %s" % (kernel_size, str(c.shape), str(p.shape)))
pool_output = concatenate([p for p in pool_output])
logging.info("pool_output.shape: %s" % str(pool_output.shape)) # (?, 1, 6)
x_flatten = Flatten()(pool_output) # (?, 6)
y = Dense(output_dim, activation='softmax')(x_flatten) # (?, 2)
logging.info("y.shape: %s \n" % str(y.shape))
model = Model([x_input], outputs=[y])
if model_img_path:
plot_model(model, to_file=model_img_path, show_shapes=True, show_layer_names=False)
model.summary()
return model
#设置参数
feature_size=padding_size
embed_size=300
num_classes=len(y[0])
filter_sizes='3,4,5'
dropout_rate=0.5
regularizers_lambda=0.01
learning_rate=0.01
batch_size=512
epochs=5
model=TextCNN(max_sequence_length=feature_size, max_token_num=vocab_size, embedding_dim=embed_size, output_dim=num_classes)
model.compile(tf.optimizers.Adam(learning_rate=learning_rate),
loss='categorical_crossentropy',
metrics=[micro_f1, macro_f1])
#训练
early_stopping = EarlyStopping(monitor='val_micro_f1', patience=10, mode='max')
history = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
workers=32,
use_multiprocessing=True,
callbacks=[early_stopping],
validation_data=(X_test, y_test))
#预测
y_pred=model.predict(X_test)
y_pred=np.argmax(y_pred,axis=1)
y_true=np.argmax(y_test,axis=1)
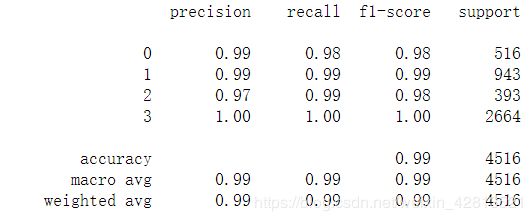
print(classification_report(y_true,y_pred))
所得到的结果如下图所示:

#训练的结果还不错,但这只是四分类,比较简单。。
如果进行多标签分类,需要修改上面的one-hot编码形式(改成多标签的形式),主干不变,将分类数改成你想分类的个数就可以了。