用scrapy爬取京东商品信息
scrapy是一个非常著名的爬虫框架,使用这个框架可以非常容易的生成一个网站爬虫程序框架,之后就可以在框架之上方便的进行爬虫的编写。
进来想要了解一些产品的市场信息,就用scrapy写了个简单的爬虫,写个笔记记录一下。
安装
使用python环境的话最好通过pip进行安装,这样操作简单方便,直接使用下面的命令即可:
$ pip install scrapy
scrapy框架提供了’scrapy’命令进行项目的创建及运行管理,所以首先看一下
$ scrapy --help
Scrapy 1.4.0 - no active project
Usage:
scrapy [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use “scrapy -h” to see more info about a command
创建项目
首先使用’scrapy startproject’创建项目
$ scrapy startproject crawler
New Scrapy project 'crawler', using template directory '/Users/wangq/virtualenv/test/lib/python2.7/site-packages/scrapy/templates/project', created in:
/Users/wangq/tmp/crawler
You can start your first spider with:
$ cd crawler
$ scrapy genspider example example.com
使用’scrapy genspider’创建爬虫
$ cd crawler
$ scrapy genspider jd list.jd.com
$ ls crawler/spiders/jd.py
crawler/spiders/jd.py
到此爬虫的框架就创建好了,爬虫的主要代码需要在jd.py中完成。
编写爬虫
爬虫代码框架
爬虫的代码主要是在crawler/spiders/jd.py中,打开这个文件看到内容如下:
# -*- coding: utf-8 -*-
import scrapy
class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['list.jd.com']
start_urls = ['http://list.jd.com/']
def parse(self, response):
pass
简单解释下:
name: 爬虫的名字
allowed_domains: 当时用了OffsiteMiddleware的时候这个配置可以限定爬虫爬取的站点的域名列表
start_urls: 指定爬虫开始运行时的爬取URL
在生成的代码中有一个parse()方法,每当爬虫获取一个新的页面爬去返回数据的时候就把这个数据通过response传递给**parse()**方法进行内容处理。
了解要爬取网页的结构
编写爬虫前先了解被爬取网页的结构信息,以及信息提取方法。这次我需要提取的信息主要是商品列表页面中的物品、价格、评论数这些基本信息,使用浏览器开发者功能查看对应的元素。

分析页面发现需要的条目的class都有’j-sku-item’属性值,知道这个规律后页就可以使用xpath获取到这个条目的具体内容了。
通过xpath获取选取的页面元素
每个div的class属性包含’j-sku-item’的元素可以通过xpath的这条规则来描述”//div[contains(@class, ‘j-sku-item’)]“,scrapy的response可以直接支持xpath,那么想要获取这个对应的元素就可以通过这行代码来获取了:
response.xpath("//div[contains(@class, 'j-sku-item')]"):
获取价格及评论信息
通常的静态内容网站数据都可以使用xpath来获取,但在爬京东的网站过程中发现价格及评论数据不是后端与页面一起处理好之后一起发送过来的,所以这两个信息无法使用xpath获取,但仔细分析网络请求可以发现这些信息是通过两个web调用来获取的,我们可以使用python的requests库来获取。
获取评论信息的调用:
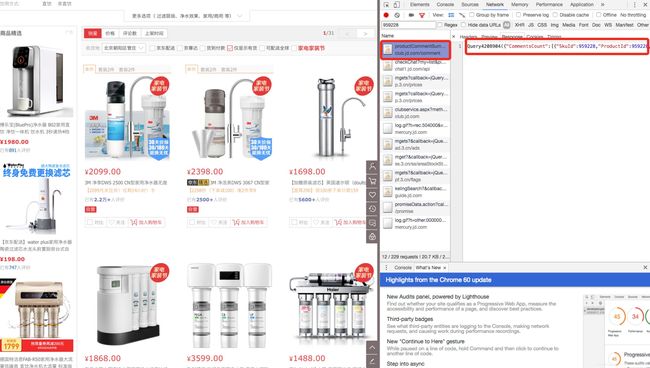
接下来可以使用curl来尝试获取评论信息的方法,最终发现访问可以通过类似的简化来完成:
https://club.jd.com/comment/productCommentSummaries.action?my=pinglun&referenceIds=959228,1722097,1722101
主要参数是referenceIds,这里可以指定需要获取的sku的列表。获取的代码如下:
def get_comments(sku_id_list):
"""
url: https://club.jd.com/comment/productCommentSummaries.action?my=pinglun&referenceIds=959228,1722097,1722101"
"""
ids = ','.join(sku_id_list)
url = "https://club.jd.com/comment/productCommentSummaries.action?my=pinglun&referenceIds=" + ids
rsp = requests.get(url)
return rsp.json()
获取价格信息的调用:
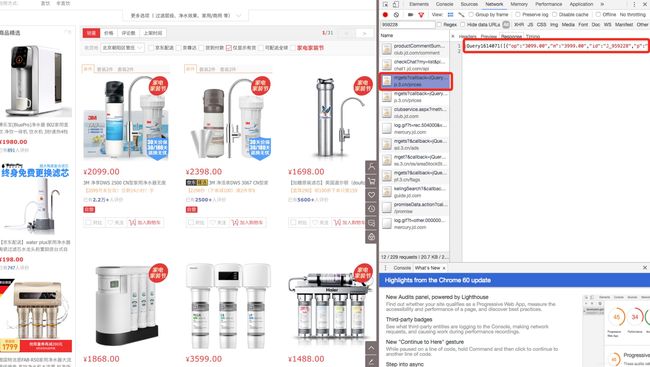
与获取评论信息类似,最终发现调用的接口可以简化成这个样子:
https://p.3.cn/prices/mgets?skuIds=J_959228%2CJ_1722101%2CJ_2064343
不同之处是每个sku前面加了一个”J_“字段。参照获取评论的方法代码如下:
def get_prices(sku_id_list):
"""
url: https://p.3.cn/prices/mgets?skuIds=J_959228%2CJ_1722101%2CJ_2064343
"""
str_id_list = map(lambda x: "J_"+x, sku_id_list)
ids = ','.join(str_id_list)
url = "https://p.3.cn/prices/mgets?skuIds=" + ids
rsp = requests.get(url)
return rsp.json()
分页处理
京东的商品条目很多的时候会分页展示,需要爬虫识别分页信息并自动抓取进行上面的处理。
首先先找到如何导向下一页的连接:

分页链接
获取链接的方式可以通过xpath抓取,把抓取的连接传给scrapy的Request()方法进行新页面的抓取,并指定抓取信息的处理回调即可。代码如下:
next_page = response.xpath("//a[@class='pn-next']/@href").get()
if next_page:
yield scrapy.Request("https://list.jd.com"+next_page, callback=self.parse)
抓取项目进行pipeline处理
每一条被爬取好的信息条目会发给pipeline模块进行处理,因此pipeline可以对数据做很多后期的处理工作,包括但不限于:
清洗抓起数据
验证抓取的数据
去重
存储数据
这次实践主要用pipeline进行数据的存储处理。默认情况下scrapy使用自带的pipeline进行处理,如果需要进行特殊处理则需要对pipeline进行配置。配置文件是crawler/settings.py。
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'crawler.pipelines.CrawlerPipeline': 300,
}
pipeline的配置通过ITEM_PIPELINES完成,可以指定多个pipeline,这样一个pipeline处理完之后可以交给后面的pipeline处理。每一个pipeline条目有一个0-1000之间的整数参数,这个参数指定了pipeline的执行顺序。
配置好pipeline之后可以在crawler/pipelines.py中编写代码进行存储处理。默认生成的代码中只包含process_item()方法,但对于需要打开文件或者数据库的场景处理会不太方便,我们可以增加open_spider()和close_spider()方法进行处理,比如
class CrawlerPipeline(object):
def open_spider(self, spider):
self.file = open('result.json', 'w')
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item)).decode("unicode_escape").encode('utf-8') + '\n'
self.file.write(line)
return item
编码问题
前面的process_item()方法中有一行处理编码的代码需要解释一下。在用下面这行代码不进行编码处理的情况下如果直接存储json.dumps()的结果时会存储成人类不能直接阅读的内容。
line = json.dumps(dict(item)) + ‘\n’
如下存储的其中一个条目,会发现”name”变成了”\uXXXX\uXXXX”的字符串。
{“sku”: “10391738071”, “category”: “3128”, “vendor”: “138857”, “name”: “\u98de\u5229\u6d66\uff08PHILIPS\uff09\u51c0\u6c34\u5668 WP4170/00\u7eaf\u6c34\u673a+WP4100/00\u524d\u7f6e\u8fc7\u6ee4\u5668\u5957\u88c5”, “price”: 4699.0, “comments”: 4}
原因是因为json.dumps()对于中文字符的处理会进行escape处理,为了存储需要首先进行unescape,就是进行decode(“unicode_escape”)。处理后的结果变成了utf-8编码,需要注意的是这还不够。如果这行代码写成下面的形式,则会发现些文件的时候无法写入文件。
line = json.dumps(dict(item)).decode(“unicode_escape”) + ‘\n’
产生的错误发生在file.write()中:
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 71-72: ordinal not in range(128)
这是因为直接写入文件时write()会认为所有的数据都是ascii码,但中文情况下显然是不成立的。因此需要对数据进行encode(),参照下面的代码写就没有问题了:
line = json.dumps(dict(item)).decode(“unicode_escape”).encode(‘utf-8’) + ‘\n’
注,有写地方会用sys.setdefaultencoding(‘utf-8’)来进行处理,但是不是万不得已并不推荐这种直接改变全局环境的做法,有可能会让程序产生意料不到的情况。
数据分析
这次抓取数据主要是分析在各个价格区间的产品用户使用情况,因此可以通过柱状图来展示。横坐标表示价格,用100元为一个区间进行统计。纵坐标显示在这100元的价格范围内的用户评论数量。
画图使用matplotlib编写,主要的代码逻辑如下:
PRICE_UNIT = 100
axis_price = range(PRICE_LOWER_RANGE, PRICE_UPPER_RANGE, PRICE_UNIT)
axis_comment = [0] * len(axis_price)
for item in get_all_sku(category=category):
idx = int(item.price/PRICE_UNIT)
# 当超过统计价格的上限区间后将结果合并到最高价格范围中
if idx >= len(axis_price):
axis_comment[-1] += item.comment
else:
axis_comment[idx] += item.comment
width=0.8*PRICE_UNIT
plt.bar(axis_price, axis_comment, width, color='blue', align='edge')
plt.show()
绘制结果如下:
