JDK8新特性6——集合的Stream流式操作
目录
1. Stream流式思想概述
2. 初识Stream
3. 获取Stream流的两种方式
3.1 根据Collection获取流
3.2 通过Stream中的静态方法of获取流
4. Stream流的常用方法
4.1 Stream流的注意事项
4.1.1 Stream只能操作一次
4.1.2 Stream方法返回的是新的流
4.1.3 Stream不调用终结方法,中间的操作不会执行
4.2 forEach方法
4.3 count方法
4.4 filter方法
4.5 limit方法
4.6 skip方法
4.7 map方法
4.8 sorted方法
4.9 distinct方法
4.10 match方法
4.11 find方法
4.12 获取最大最小值
4.13 reduce方法
4.14 Stream流的map与reduce组合使用
4.15 mapToInt方法
4.16 静态方法concat方法
1. Stream流式思想概述
Stream流式思想类似于工厂车间的“生产流水线”,Stream流不是一种数据结构,不保存数据,而是对数据进行加工处理。Stream可以看做是流水线上的一道工序,在流水线上,通过多个工序让一个原材料加工成一个商品。
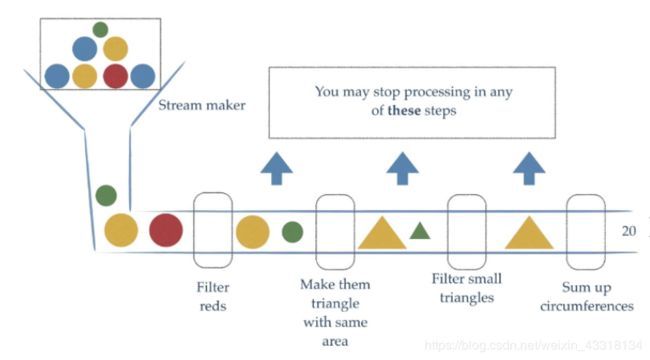
Stream流能够让我们能够快速的完成许多复杂的操作,如筛选、切片、映射、查找、去重、统计、匹配和规约等。
注意:Stream流与IO流没有任何关系。
2. 初识Stream
Stream 是用函数式编程方式在集合类上进行复杂操作的工具,其集成了Java 8中的众多新特性之一的聚合操作,开发者可以更容易地使用Lambda表达式,并且更方便地实现对集合的查找、遍历、过滤以及常见计算等。
我们先来看一个需求,在list
在JDK1.8之前的做法是:
private static List getDishNameByList(List dishs){
List list = new ArrayList<>();
for(Dish d : dishs){
if(d.getCalories() < 400){
list.add(d);
}
}
Collections.sort(list,(dish1,dish2) -> Integer.compare(dish1.getCalories(),dish2.getCalories()));
List names = new ArrayList<>();
for(Dish d : list){
names.add(d.getName());
}
return names;
} 使用stream的做法:
private static List getDishNameByStream(List dishs){
List collect = dishs.stream().filter(d -> d.getCalories() < 400)
.sorted(Comparator.comparing(Dish::getCalories)).map(Dish::getName)
.collect(toList());
return collect;
} 3. 获取Stream流的4种方式
3.1 根据Collection获取流
在Collection接口中有一个默认的方法:default Stream
通过其定义,可以知道所有Collection接口的接口都有一个stream方法,例如:
public class StreamDemo1 {
public static void main(String[] args) {
List list = new ArrayList();
Stream stream = list.stream();
Set set = new HashSet();
Stream stream1 = set.stream();
Map map = new HashMap();
Stream stream2 = map.keySet().stream();
Stream stream3 = map.values().stream();
Stream stream4 = map.entrySet().stream();
}
}注意:Map不属于Collection接口的子接口,所以Map实现类没有stream方法,但是map实例获取的key集合和value集合是Collection的子类,所以可以使用stream方法。
3.2 通过Stream中的静态方法of获取流
static Stream of(T... values) 可以知道of接受一个可变参数类型,可变参数的本质就是一个数组,也就是说,还可以接受一个数组参数,例如:
public static void main(String[] args) {
Stream stream = Stream.of("aa", "bb", "cc");
Integer[] arrar = {1, 2, 2, 3, 4, 5};
Stream objectStream = Stream.of(arrar);
} 注意:基本数据类型的数组不能使用这种方式流化,例如:
int[] arr = {1, 2, 2, 3, 4, 5};
Stream stream1 = Stream.of(arr); 对于上面int类型的数组,使用Stream的of方法流化的时候,是将整个int[]看做了一个object来操作,而不会操作数组中的元素,如果将泛型int[]改成int,编译就会报错。
3.3 通过Arrays中的stream() 获取一个数组流
Integer[] nums = new Integer[10];
Stream stream1 = Arrays.stream(nums); 3.4 创建无限流
3.4.1 通过迭代器iterate
Stream stream3 = Stream.iterate(0, (x) -> x + 2).limit(10); 3.4.2 通过generate
Stream stream4 = Stream.generate(Math::random).limit(2); 4. Stream流的常用方法
Stream流模型的操作很丰富,提供了很多实用的API,大概可以分为两种
1)终结方法:返回值类型不再是Stream,不再支持链式调用,
2)非终结方法:返回值类型依然是Stream,支持链式调用(除了终结方法之外,其余的都是非终结方法)
以下是常用的比较简单的一些方法:
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
4.1 Stream流的注意事项
4.1.1 Stream只能操作一次
例如:
Stream stream = Stream.of("aa", "bb", "cc");
stream.count();
stream.count(); 对于stream流对象,如果只调用一次count方法不会出问题,如果向上面那样调用2次,就会报错,错误信息如下:
 4.1.2 Stream方法返回的是新的流
4.1.2 Stream方法返回的是新的流
例如:返回值为false
Stream stream = Stream.of("aa", "bb", "cc");
Stream limit = stream.limit(1);
System.out.println(stream == limit); 4.1.3 Stream不调用终结方法,中间的操作不会执行
例如:
public static void main(String[] args) {
Stream stream = Stream.of("aa", "bb", "cc");
stream.filter((s) -> {
System.out.println(s);
return true;
});
} 当我们只调用Stream的拼接函数filter的时候,打印语句永远不会被执行,必须要调用终结方法,才能执行打印语句,例如:
public static void main(String[] args) {
Stream stream = Stream.of("aa", "bb", "cc");
stream.filter((s) -> {
System.out.println(s);
return true;
}).count();
} 4.2 forEach方法
forEach方法用来遍历流中的数据,方法定义
void forEach(Consumer var1);该方法接收一个Consumer接口函数,会将每一个元素交给该函数进行处理。
例如:
public static void main(String[] args) {
List list = new ArrayList();
Collections.addAll(list,"a","b","c","d","e","f");
list.stream().forEach(s->{
System.out.println(s);
});
// 上面的Lambda可以改成下面的方法引用的形式
list.stream().forEach(System.out::println);
} 同时我们也可以使用另一个集合去接收这个集合中的元素
List l = new ArrayList();
list.stream().forEach(l::add);注意:对于foreach方法,可以不使用stream转换,例如;
public static void main(String[] args) {
List list = new ArrayList();
Collections.addAll(list,"a","b","c","d","e","f");
list.forEach(s->{
System.out.println(s);
});
// 上面的Lambda可以改成下面的方法引用的形式
list.forEach(System.out::println);
} 4.3 count方法
Stream流提供count方法来统计其中的元素个数,方法定义为:long count(),该方法返回一个long值代表元素个数,
例如:
long count = list.stream().count();4.4 filter方法
filter用于过滤数据,返回符合条件的数据,在开发中,我们可以通过filter将一个流转换成另一个子集流,方法声明:
Stream filter(Predicate var1); 该接口接收一个Predicate函数式接口参数(可以是一个Lambda或方法引用)作为筛选条件。
例如:
list.stream().filter( s -> s.indexOf("h") != -1 ).forEach(System.out::println);注意:Lambda表达式,当只有一句话的return语句的时候,可以省略大括号省略return。
4.5 limit方法
limit方法可以对流进行截取,只取用前N个,方法定义:Stream
参数是long型,如果集合当前长度大于参数则进行截取,否则不进行操作。
例如:
list.stream().limit(4).forEach(System.out::println);4.6 skip方法
如果希望跳过前几个元素,可以使用skip方法获取一个截取之后的新流,方法定义为:Stream
例如:
list.stream().skip(4).forEach(System.out::println);4.7 map方法
如果需要将流的元素映射到另一个流中,可以使用map方法,方法定义为:
Stream map(Function var1); 该接口需要一个Function函数式接口参数,可以将当前流中的T类型的数据转换为另一种R类型的流。
例如:map将一个String流转成了Integer流
Stream strStream = list.stream();
Stream stream = strStream.map(Integer::parseInt); 4.8 sorted方法
如果需要将数据排序,可以使用sorted方法,方法定义为
Stream sorted(); // 自然顺序排序
Stream sorted(Comparator var1); // 自定义排序 例如:
public class StreamSorted {
public static void main(String[] args) {
List list = new ArrayList();
Collections.addAll(list,1,5,2,4,8,10);
list.stream().sorted() // 自然顺序排序
.sorted((i1,i2) -> i2-i1) // 降序排序
.forEach(System.out::println);
}
} 4.9 distinct方法
如果需要去除重复数据,可以使用distinct方法,方法定义:Stream
list.stream().distinct().forEach(System.out::println);注意:对于自定义类型的数据,去重需要类对象重写hashCode与equals方法。
4.10 match方法
如果需要判断数据是否匹配指定的条件,可以使用match相关方法,方法定义
boolean anyMatch(Predicate var1); // 匹配任意一个,只要有一个满足指定条件就可以
boolean allMatch(Predicate var1); // 匹配所有元素,元素是否全部满足指定条件
boolean noneMatch(Predicate var1); // 匹配所有元素,所有元素都不满足指定条件例如:
package com.bjc.jdk8.stream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class StreamMatch {
public static void main(String[] args) {
List list = new ArrayList();
Collections.addAll(list,1,5,2,4,8,10);
boolean b = list.stream().allMatch(i -> i > 0);
System.out.println(b);
boolean b1 = list.stream().anyMatch(i -> i > 5);
System.out.println(b1);
boolean b2 = list.stream().noneMatch(i -> i < 0);
System.out.println(b2);
}
}
返回结果均为true。
4.11 find方法
如果需要找到某些数据,可以使用find相关方法,方法定义:
Optional findFirst();
Optional findAny(); 注意:这两个方法都是查找流中的第一个元素
例如:
package com.bjc.jdk8.stream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class StreamFind {
public static void main(String[] args) {
List list = new ArrayList();
Collections.addAll(list,1,5,2,4,8,10);
Integer integer = list.stream().findFirst().get();
System.out.println(integer);
Integer integer1 = list.stream().findAny().get();
System.out.println(integer1);
}
}
输出结果都是1
4.12 获取最大最小值
如果需要获取最大值和最小值,可以使用max和min方法,方法定义:
Optional min(Comparator var1);
Optional max(Comparator var1); 例如:
public static void main(String[] args) {
List list = new ArrayList();
Collections.addAll(list,1,5,2,4,8,10);
Integer integer = list.stream().max((o1,o2) -> o1 - o2).get();
System.out.println(integer);
Integer integer1 = list.stream().min((o1,o2) -> o1 - o2).get();
System.out.println(integer1);
} 4.13 reduce方法
如果需要将所有数据归纳得到一个数据,可以使用reduce方法,方法定义:
T reduce(T var1, BinaryOperator var2); 第一个参数:默认值
第二个参数:数据处理逻辑,BinaryOperator继承自BiFunction,且BinaryOperator接口中无抽象的方法,所以,找父类的BiFunction的抽象方法
R apply(T var1, U var2);例如:带默认值的reduce
package com.bjc.jdk8.stream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Stream;
public class StreamReduce {
public static void main(String[] args) {
Stream stream = Stream.of(1, 3, 4, 5, 2, 7, 9);
Integer reduce = stream.reduce(0, (x, y) -> x + y);
System.out.println(reduce);
}
}
或者,不带默认值的reduce
package com.bjc.jdk8.stream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Optional;
import java.util.stream.Stream;
public class StreamReduce {
public static void main(String[] args) {
Stream stream = Stream.of(1, 3, 4, 5, 2, 7, 9);
Optional reduce = stream.reduce((x, y)->x+y);
System.out.println(reduce.get());
}
}
4.14 Stream流的map与reduce组合使用
通过Stream流的map与reduce的组合使用可以大大的简化我们对集合的操作
例如:定义如下对象流
Stream stream = Stream.of(
new Person("张三",22),
new Person("李四",23),
new Person("王五",21),
new Person("赵六",26),
new Person("钱七",25)
); 1)求出所有的年龄之和
// Integer reduce = stream.map(p->p.getAge()).reduce(0, (x, y) -> x+y);
Integer reduce1 = stream.map(Person::getAge).reduce(0, (x, y) -> x + y);
System.out.println(reduce);注意:因为Integer有一个sum方法可以求和,所以,上面的代码还可以改成如下形式:
Integer reduce1 = stream.map(Person::getAge).reduce(0, Integer::sum);2)找出最大年龄
Optional reduce = stream.map(Person::getAge).reduce(Integer::max);
Integer integer = reduce.get();
System.out.println(integer); 3)统计一个流中a出现的次数
例如:
Stream stream1 = Stream.of(
"a","b","c","a","a","f","a","d"
);
Optional option = stream1.map(str -> "a".equals(str) ? 1 : 0).reduce(Integer::sum);
Integer integer = option.get();
System.out.println(integer); 4.15 mapToInt方法
如果需要将Stream
IntStream mapToInt(ToIntFunction mapper);我们为什么要将Integer流转成int了,这是因为Integer占用的内存比int多,在Stream流操作中会自动装箱和拆箱,经过mapToInt方法转换之后,就将一个Integer类型的stream转成了一个IntStream,那么这个IntStream流与Stream流有什么关系了?如下图所示,两者有一个父接口Basestream,只是IntStream内部操作的是int数据,可以节省内存,减少自动拆箱装箱。

例如:
public class StreamMapToInt {
public static void main(String[] args) {
Stream stream = Stream.of(1, 2, 3, 4, 5, 6);
IntStream intStream = stream.mapToInt(Integer::intValue);
intStream.forEach(System.out::println);
}
} 4.16 静态方法concat方法
如果有两个流,希望合并成为一个流,那么可以使用Stream接口的静态方法concat,方法定义:
public static Stream concat(Stream a, Stream b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator) a.spliterator(), (Spliterator) b.spliterator());
Stream stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return stream.onClose(Streams.composedClose(a, b));
} 例如:
public class StreamConcat {
public static void main(String[] args) {
Stream stream = Stream.of("张三", "李四", "王五", "赵六");
Stream stream1 = Stream.of("钱七", "朱八", "宫九");
Stream concat = Stream.concat(stream, stream1);
concat.forEach(System.out::println);
}
} 注意:当使用concat合并流之后,合并之前的流不能使用了,否则会报如下错
