- 2018-11-10
菜菜_d868
姓名:邢彩颜公司:蔚蓝时代【日精进打卡第101天】【知-学习】1.读0六项精进【经典名句分享】努力不一定成功,但不努力一定不会成功行:今日休息【省-觉悟】躺一整天没有运动。【感谢】感谢420谦虚2组的成员,感恩父母,感谢我的领导、我的团队。感谢身边的朋友,【发愿】愿我身边的朋友健健康康。愿爱我的人每天都快乐,幸福。愿自己能够每天进步一点点。愿我的家人都健康快乐幸福。今日0善,累计103件.
- 2018-11-10感恩
田英_b32e
感恩1.感恩父母亲的养育之恩。愿父母健康长寿,安享晚年,获得暂时和究竟的安乐。2.感恩上师三宝的加持,一切都是上师的游舞和加持。3.感恩格西麦克罗奇的传播金刚智慧,我相信来自2500年前的古老智慧并践行它,让我的生活当中出现了不可思议的奇迹,随喜自己太荣幸了。4.感恩国家,国泰民安,生活在稳定的国家,才有我们的小家。5.感恩记录管理种子的工具——六时书。帮我记录好种子和坏种子,管理自己的种子库。6
- 语言和念头的力量竟如此惊人
单悟道
语言和念头的力量竟如此惊人法雨天香2018-11-10为什么「乌鸦嘴」特别灵验?为什么我们都喜欢听祝福和赞美的语言?美好的祝福,真的可以为人生带来正向的改变吗?语言力量的秘密究竟在哪里?其实,语言是一种「咒语」。我们每个人都是语言的「魔法师」,掌握着改变命运的钥匙……1每个人都是语言的「魔法师」「良言一句三冬暖,恶语一句九月霜。」这句话看似简单,但意义却相当深远。我们每个人都是魔法师,可以用言语对
- 2018-11-10
口乞太夕夕
你看见她努力学习,你不屑,你不知道她身上背负了多重的压力。你看见她拿国奖,你羡慕,你不知道如果她拿不到这笔奖学金,这笔学费对于她的家庭来说是多大的负担。谁不想舒舒服服的躺在床上玩手机睡懒觉,可是当她醒来,睁开眼,就会看到这残酷的现实。不是含着金汤匙出生的孩子,只有拼了命才能抢到饭。
- 2018-11-10
画神方振邦
美丽的夕阳太阳生起来非常美落下来时也非常的美,而太阳落山时有一个名字,叫做“夕阳”。一般夕阳出现的时候大概是在晚上六点钟左右,那时天还没黑,便可以看到它。先是飘来几朵云,太阳再慢慢落了下来藏在云中间。云就被染成了红色或者金黄色,非常的美丽!太阳是红色的,它把云也染成了红色。不一会儿它便像一个将军一样庄严的落下来,落到了山的后面。你仔细的看它,果真像神话中所说的金乌一样,非常威武、神气。虽然说它已经
- Docker for Mac 的安装
得力过
最近准备开始搭建自己的后台服务,鉴于之前在腾讯云上的蛋疼部署经历,遂想到了使用docker来集成开发与上线环境。首先是奔往官网,发现无法注册,原因是其使用了谷歌的recaptcha人机验证,加载不出来所以注册button是灰的。好吧得翻墙。。不需要翻墙的下载地址下载完mac版本Docker.dmg,双击打开安装。然后到应用程序下双击Docker启动图标:屏幕快照2018-11-10上午1.47.5
- 2018-11-10
e9e64ae285c1
今天妈妈去加班,我在奶奶家。我把老师留的作业都写完了。没有妈妈在身边,我自己独立完成作业,我很开心,下午,妈妈回来看到我写完作业,夸我懂事了,给我检查了一遍,我把写错的题改完了,我这一天过的很开心。
- 2018-11-10
王玉笙
每个人,都在忙忙碌碌的生活。一次次的失败,一次次的努力向前。为不喜欢的人或事,找借口,推托。就像是一句话所说的,为不喜欢找理由,为失败找借口。这就是现在的人的内心。
- 2018-11-10
古灵精怪小摩女
真实,是人生的最高境界。何为真实?就是不做作、不违背良心,纯乎心性而行。不作假,不自负也不自卑。不作非分之想,知足常乐。不违背良心,心无挂碍,日日安好。该作则作,不该作则止,无妄想和烦恼,做真实的自己。图片发自App图片发自App图片发自App图片发自App
- 2018-11-10
Jinling10
开了一天的会,8点多吃过饭,散了场,大家一行人说去附近的曾厝垵溜达。昨天去过的人纷纷推荐,厦门网红景点,据说很多小吃。我们极力要求回去换了鞋,放下电脑,然后一行人浩浩荡荡过去。大约走了十多分钟,到一热闹处,有去过的人说就那一片了。步行街,两边各种小店,小吃居多,还有首饰,特产,饮料甜品,茶叶店,咖啡屋等等。有些特色小玩具,小首饰,我们几个女士慢慢看,不一会儿发现,老板们及男士们已经不见踪影。一路上
- 2018-11-10
煙花
坚持分享第18天接了真正的来访者才发现,原来学的那些理论并不是很好用,因为真正的来访者都不是为咨询师而准备的,也不是为某个理论准备的,总会有很多的波折和挑战。因此才发现原来说的那些东西真的是太少了,曾经有一段时间不太喜欢约练,因为感觉约练总是那一些套路,在实际咨询的时候并不是这样的。可是连套路都不会的话,根本不知道怎样去做咨询,也不知道咨询的流程是什么。若想不套路就得把咨询做得很熟,让心理学专业知
- 2018-11-10
君芳_cba5
今天我带着豆豆一起去奶奶家吃饭。开始吃带鱼了。他婶婶说我先教给大家如何吃带鱼啊,豆豆在这儿忙着玩手机,没顾上听,然后开始吃的时候他不会自己就又哭又闹,不吃饭耍赖。奶奶就开始哄她叔叔说别管别管,让他自己嗯,想办法,他不愿意吃就别吃。然后明年就开始正哥哥哥哥他的意思是说哥哥不吃饭了,在那哭嘞。然后没有人理他,后来我想了想,这孩子比较要面子,我就说豆豆,你是不是不会吃带鱼呀?来,我教你。后来一堂说来逗逗
- 《能量人生》2018-11-10
化北I六段演讲
早上好!能量人生:每日一句正能量[玫瑰][玫瑰][玫瑰]用心感受生活(2018年11月10日农历十月初三星期六)生活,是生下来,活下去百变的生活,如一的命,不管走哪条路,是自己的选择坚持顺着这条路走下去,你会发现路旁的风景很美,生活也会在不经意间变换,越变越好。人的心,什么都装时叫心灵装一点时叫心眼,装的多时叫心计,装得更多时叫心机,装的太多时叫心事,装得再多时叫心病。健康,是最高的利益,满足,是
- 2018-11-10
其实_1d17
今日体验;做一件事,说一句话,都有原因的,都在追寻着不同的目标,得到想得到的东西。服务好客户,客户介绍朋友来创造阔建利益。
- 2018-11-10
阿满同学
1.付出不亚于任何人的努力2.要谦虚,不要骄傲3.要每天反省4.活着,就要感谢5.积善行,思利他6.不要有感性的烦恼今日分享:活着,就要感谢,感谢昨天。因为有昨天的因,才会有今天的果。无论今天怎样,也不管将来如何。只要记得现在做好该做的事就好。
- 2018-11-10(临兰亭)
品茶轩pcx
图片发自App图片发自App图片发自App图片发自App图片发自App图片发自App图片发自App
- 2018-11-10
某贞
起床以后就可以看到自己喜欢的人不喜欢的人倒了霉回到宿舍打打闹闹回到被窝里追剧晚上和朋友聚个小餐真希望我可以经常有这样的一天
- 2018-11-10
32774430182c
图片发自App一群人,一件事,一辈子!每个人的前面,都有一条通向远方的路,崎岖但充满希望.不是人人都能走到远方,因为总有人因为没倒掉鞋里的沙子而疲惫不堪半途而废.所以,主宰人感受的并非快乐和痛苦本身,而是心情.人生是一种承受,需要学会支撑。支撑事业,支撑家庭,甚至支撑起整个社会,有支撑就一定会有承受,支撑起多少重量,就要承受多大压力。今天我的女神们,个个闪亮现身随喜!小仙女儿不管是才艺还是美都无可
- 2018-11-10
石大姐姐
【1110今日剽悍】7379-晓岚【目标完成事项】1.听读书营往期分享。2.日常工作。3.陪孩子散步玩耍。4.辅导孩子完成作业。(完成英语练习)5.收拾书籍,搬到客厅。花费两小时。6.早睡。【感想】收拾书籍发现先生以前选的书,挺有阅读质量的,王小波/王安忆/张小娴/村上春树的经典著作。陪孩子玩耍时在听音频,桦哥向我表达他的成绩考得优秀时没有及时赞赏他。过后觉得挺愧疚,每次对他过于严厉,没有及时表达
- 2018-11-10 《朝话》8
王慢慢_
61青年修养问题三问:(一)何谓人格呢?(二)谈修养而自别于宗教修养,究竟其中分别如何?(三)心理卫生是从科学来的,我们应当接受,但现在谈的修养是否即等于心理卫生?青年留心修养问题,莫忽视,以为不必要;同时我更望留心乎修养的青年,对于我上面提出的问题,加以考虑。试各本所见作答,彼此讨论,或向人请教,不可颟顸笼统。62谈修养什么是修养?修养是一种功夫。什么功夫呢?是认识自己,使自己力量增强的功夫。或
- 2018-11-10
小胡子c
姓名:陈卫东组别:364期、403期、416期、456期公司:宁波华光精密仪器有限公司【日精进打卡第96天】【知~学习】《六项精进》背诵大纲2遍,共112遍《大学》诵读1遍,共123遍巜活法》学习活法巜改法》第一章:自己可以改变【经典名句分享】人生没有奋斗就不会随随便便成功【行~实践】一、修身:1.60kg臂力器做10个。俯卧撑38个。2.饭后河边散步、打篮球10分钟、打羽毛球20分钟二、齐家:1
- 面试|非常全面的面试技巧,简单实用值得收藏
持续行动_刻意学习
转:非常全面的面试技巧,几分钟就能读完,简单实用值得收藏甘粹作者2018-11-10对于很多应聘者来说,成功找到一份心仪的工作,无疑是给个人职业生涯增添不少光辉。成功的人,都是有所准备的人,其实所谓的捷径,只不过是人家比你准备得更充分。下面,我收集一些有用的面试技巧,希望对大家有所帮助。1.你是不是具备这份工作所必须的技能?做好这份工作你是不是具备必要的思维方式和职业动机?你是不是与所面试的单位有
- 2018-11-10晨间日记
静月荷
今天是什么日子起床:就寝:天气:心情:纪念日:任务清单昨日完成的任务,最重要的三件事:改进:习惯养成:周目标·完成进度学习·信息·阅读健康·饮食·锻炼人际·家人·朋友工作·思考最美好的三件事1.2.3.思考·创意·未来霍华德说:“人们普遍认为,拥有财富就意味着成功,而成功则意味着幸福快乐。”生活中,人们每天都在追求幸福、追求成功。日复一日,年复一年,从未停下追逐的脚步。然而,房子住的越来越大,日子
- 2018-11-10《断舍离》读后
陶醉了醉了
说实在话,断舍离这个词很久前就听到了,而且从16年下半年起就在了解和学习有关整理的课程,在实践中真切地感受到了物品与空间和人的关系和谐带来的好处,不只是物品更有思想和心灵方面的。家里之前有一本整理类的《断舍离》,据说作者是山下英子的粉,书中主要讲了物品整理的一些内容,小小一本书,一个小时就翻完了,大意是讲扔东西,扔东西前要感恩,注意物品的入口等等。现在,我终于将断舍离这本书认真地翻阅了一遍,感觉这
- 每日前端签到(第九十九天)
拿着号码牌徘徊
第九十九天(2018-11-10)[html]除了音频和视频,HTML5还支持哪些媒体标签?[css]CSS中的calc()有什么作用?[js]说说你对作用域链的理解[软技能]Web安全色所能够显示的颜色种类有多少种?题目一:一般用于定义不同的媒体资源,由于各浏览器对视频格式的支持不同,可以通过video/audio内嵌source来链接多种视频格式,实现浏览器兼容用于给音频和视频文件添加字幕文件
- 2018-11-10去同学家过生日
顺德琪佳妈
2018年11月10日农历十月初三星期六晴学经人员:琪佳妈、琪琪、佳佳。宝贝年龄:琪琪10岁,佳佳9岁。学经周期:3年9个月。学经方法:137累积法。学经内容:《易经》《孟子》《论语》《中国古典长诗》《中庸》《新概念英语》。养生汇报:早起,姜枣茶,159杂粮粥今天一早,琪琪问我:妈妈,我一个同学邀请我去他家过生日,我可不可以去?我说:你同学住哪里的?琪琪说:就住瀚城。我说:看你的作业完成情况吧。琪
- 2018-11-10
本草相宜
神秘绑架(1)夜,很静。在高速公路上的一辆出租车里,正发生着不为人知的事情。“不许动。”一个沉稳的男声。二十岁的简潇顿时感到冰冷的枪口抵在了太阳穴上。她心里一紧,知道大事不好。今天是她的生日,特意从大学赶回家想跟家人一起过生日,没想到,,,她绝望地想。出租车仍然在高速公路上飞驰,看得出驾驶座上的人技术很好,一手握枪,一手操控着方向盘。汽车里,是死一般的静寂。不知道过了多久,在简潇的心理防线即将崩溃
- 2018-11-10
Monsteryyx
人的一生中,似乎充满了这种矛盾的瞬间。在拥抱时,有了离别;收藏时,又有遗失;有些事记得,而有些事,彻底忘记。图片发自App当你面临众多选择时,是该选择随波逐流还是该选择坚持自我?在一本书上看到过六个字:不要怕,不要悔。是的,不要害怕去选择,不要后悔自己的选择。
- 2018-11-10
我心永恒_c1ee
鱼那么信任水,水却煮了鱼!鱼那么信任水,水却煮了鱼。叶子那么信任风,风却吹落了叶。人心的冷暖,总是一直变幻。熟悉的陌生了,陌生的走远了。人与人之间,全靠一颗心,情与情之间,全凭一寸真。落叶知秋,落难知友!人生不易,且行且珍惜。人生是一个过程,像朝阳至日暮,又好像,春花、夏夜、秋日、冬雪,一年四季的轮换。如果把短短几十年的人生分为两部分,那就是上半场和下半场。人生的上半场讲“升”:升学历,升职位,升
- 2018-11-10
行走在路上AAA
11月10日星期六小雨今天没预报有雨,可是,雨不停的下着。如同孩子的学习一样,计划着他能把作业好好的做完。可实际当中呢。它是分阶段完成。一场秋雨一场凉。现在已经有了寒意。落叶纷乱的飘下,随着雨。已经贴在地上了。陪伴是对孩子最好的负责任。可有的人不那么认为,因为孩子现在上六年级了。适度的放手,是对孩子无限的施展空间。其实我也考虑了。是该放手的时候了。作业是要做。而且是要加强的。但是我们是要讲究方法的
- 枚举的构造函数中抛出异常会怎样
bylijinnan
javaenum单例
首先从使用enum实现单例说起。
为什么要用enum来实现单例?
这篇文章(
http://javarevisited.blogspot.sg/2012/07/why-enum-singleton-are-better-in-java.html)阐述了三个理由:
1.enum单例简单、容易,只需几行代码:
public enum Singleton {
INSTANCE;
- CMake 教程
aigo
C++
转自:http://xiang.lf.blog.163.com/blog/static/127733322201481114456136/
CMake是一个跨平台的程序构建工具,比如起自己编写Makefile方便很多。
介绍:http://baike.baidu.com/view/1126160.htm
本文件不介绍CMake的基本语法,下面是篇不错的入门教程:
http:
- cvc-complex-type.2.3: Element 'beans' cannot have character
Cb123456
springWebgis
cvc-complex-type.2.3: Element 'beans' cannot have character
Line 33 in XML document from ServletContext resource [/WEB-INF/backend-servlet.xml] is i
- jquery实例:随页面滚动条滚动而自动加载内容
120153216
jquery
<script language="javascript">
$(function (){
var i = 4;$(window).bind("scroll", function (event){
//滚动条到网页头部的 高度,兼容ie,ff,chrome
var top = document.documentElement.s
- 将数据库中的数据转换成dbs文件
何必如此
sqldbs
旗正规则引擎通过数据库配置器(DataBuilder)来管理数据库,无论是Oracle,还是其他主流的数据都支持,操作方式是一样的。旗正规则引擎的数据库配置器是用于编辑数据库结构信息以及管理数据库表数据,并且可以执行SQL 语句,主要功能如下。
1)数据库生成表结构信息:
主要生成数据库配置文件(.conf文
- 在IBATIS中配置SQL语句的IN方式
357029540
ibatis
在使用IBATIS进行SQL语句配置查询时,我们一定会遇到通过IN查询的地方,在使用IN查询时我们可以有两种方式进行配置参数:String和List。具体使用方式如下:
1.String:定义一个String的参数userIds,把这个参数传入IBATIS的sql配置文件,sql语句就可以这样写:
<select id="getForms" param
- Spring3 MVC 笔记(一)
7454103
springmvcbeanRESTJSF
自从 MVC 这个概念提出来之后 struts1.X struts2.X jsf 。。。。。
这个view 层的技术一个接一个! 都用过!不敢说哪个绝对的强悍!
要看业务,和整体的设计!
最近公司要求开发个新系统!
- Timer与Spring Quartz 定时执行程序
darkranger
springbean工作quartz
有时候需要定时触发某一项任务。其实在jdk1.3,java sdk就通过java.util.Timer提供相应的功能。一个简单的例子说明如何使用,很简单: 1、第一步,我们需要建立一项任务,我们的任务需要继承java.util.TimerTask package com.test; import java.text.SimpleDateFormat; import java.util.Date;
- 大端小端转换,le32_to_cpu 和cpu_to_le32
aijuans
C语言相关
大端小端转换,le32_to_cpu 和cpu_to_le32 字节序
http://oss.org.cn/kernel-book/ldd3/ch11s04.html
小心不要假设字节序. PC 存储多字节值是低字节为先(小端为先, 因此是小端), 一些高级的平台以另一种方式(大端)
- Nginx负载均衡配置实例详解
avords
[导读] 负载均衡是我们大流量网站要做的一个东西,下面我来给大家介绍在Nginx服务器上进行负载均衡配置方法,希望对有需要的同学有所帮助哦。负载均衡先来简单了解一下什么是负载均衡,单从字面上的意思来理解就可以解 负载均衡是我们大流量网站要做的一个东西,下面我来给大家介绍在Nginx服务器上进行负载均衡配置方法,希望对有需要的同学有所帮助哦。
负载均衡
先来简单了解一下什么是负载均衡
- 乱说的
houxinyou
框架敏捷开发软件测试
从很久以前,大家就研究框架,开发方法,软件工程,好多!反正我是搞不明白!
这两天看好多人研究敏捷模型,瀑布模型!也没太搞明白.
不过感觉和程序开发语言差不多,
瀑布就是顺序,敏捷就是循环.
瀑布就是需求、分析、设计、编码、测试一步一步走下来。而敏捷就是按摸块或者说迭代做个循环,第个循环中也一样是需求、分析、设计、编码、测试一步一步走下来。
也可以把软件开发理
- 欣赏的价值——一个小故事
bijian1013
有效辅导欣赏欣赏的价值
第一次参加家长会,幼儿园的老师说:"您的儿子有多动症,在板凳上连三分钟都坐不了,你最好带他去医院看一看。" 回家的路上,儿子问她老师都说了些什么,她鼻子一酸,差点流下泪来。因为全班30位小朋友,惟有他表现最差;惟有对他,老师表现出不屑,然而她还在告诉她的儿子:"老师表扬你了,说宝宝原来在板凳上坐不了一分钟,现在能坐三分钟。其他妈妈都非常羡慕妈妈,因为全班只有宝宝
- 包冲突问题的解决方法
bingyingao
eclipsemavenexclusions包冲突
包冲突是开发过程中很常见的问题:
其表现有:
1.明明在eclipse中能够索引到某个类,运行时却报出找不到类。
2.明明在eclipse中能够索引到某个类的方法,运行时却报出找不到方法。
3.类及方法都有,以正确编译成了.class文件,在本机跑的好好的,发到测试或者正式环境就
抛如下异常:
java.lang.NoClassDefFoundError: Could not in
- 【Spark七十五】Spark Streaming整合Flume-NG三之接入log4j
bit1129
Stream
先来一段废话:
实际工作中,业务系统的日志基本上是使用Log4j写入到日志文件中的,问题的关键之处在于业务日志的格式混乱,这给对日志文件中的日志进行统计分析带来了极大的困难,或者说,基本上无法进行分析,每个人写日志的习惯不同,导致日志行的格式五花八门,最后只能通过grep来查找特定的关键词缩小范围,但是在集群环境下,每个机器去grep一遍,分析一遍,这个效率如何可想之二,大好光阴都浪费在这上面了
- sudoku solver in Haskell
bookjovi
sudokuhaskell
这几天没太多的事做,想着用函数式语言来写点实用的程序,像fib和prime之类的就不想提了(就一行代码的事),写什么程序呢?在网上闲逛时发现sudoku游戏,sudoku十几年前就知道了,学生生涯时也想过用C/Java来实现个智能求解,但到最后往往没写成,主要是用C/Java写的话会很麻烦。
现在写程序,本人总是有一种思维惯性,总是想把程序写的更紧凑,更精致,代码行数最少,所以现
- java apache ftpClient
bro_feng
java
最近使用apache的ftpclient插件实现ftp下载,遇见几个问题,做如下总结。
1. 上传阻塞,一连串的上传,其中一个就阻塞了,或是用storeFile上传时返回false。查了点资料,说是FTP有主动模式和被动模式。将传出模式修改为被动模式ftp.enterLocalPassiveMode();然后就好了。
看了网上相关介绍,对主动模式和被动模式区别还是比较的模糊,不太了解被动模
- 读《研磨设计模式》-代码笔记-工厂方法模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* 工厂方法模式:使一个类的实例化延迟到子类
* 某次,我在工作不知不觉中就用到了工厂方法模式(称为模板方法模式更恰当。2012-10-29):
* 有很多不同的产品,它
- 面试记录语
chenyu19891124
招聘
或许真的在一个平台上成长成什么样,都必须靠自己去努力。有了好的平台让自己展示,就该好好努力。今天是自己单独一次去面试别人,感觉有点小紧张,说话有点打结。在面试完后写面试情况表,下笔真的好难,尤其是要对面试人的情况说明真的好难。
今天面试的是自己同事的同事,现在的这个同事要离职了,介绍了我现在这位同事以前的同事来面试。今天这位求职者面试的是配置管理,期初看了简历觉得应该很适合做配置管理,但是今天面
- Fire Workflow 1.0正式版终于发布了
comsci
工作workflowGoogle
Fire Workflow 是国内另外一款开源工作流,作者是著名的非也同志,哈哈....
官方网站是 http://www.fireflow.org
经过大家努力,Fire Workflow 1.0正式版终于发布了
正式版主要变化:
1、增加IWorkItem.jumpToEx(...)方法,取消了当前环节和目标环节必须在同一条执行线的限制,使得自由流更加自由
2、增加IT
- Python向脚本传参
daizj
python脚本传参
如果想对python脚本传参数,python中对应的argc, argv(c语言的命令行参数)是什么呢?
需要模块:sys
参数个数:len(sys.argv)
脚本名: sys.argv[0]
参数1: sys.argv[1]
参数2: sys.argv[
- 管理用户分组的命令gpasswd
dongwei_6688
passwd
NAME: gpasswd - administer the /etc/group file
SYNOPSIS:
gpasswd group
gpasswd -a user group
gpasswd -d user group
gpasswd -R group
gpasswd -r group
gpasswd [-A user,...] [-M user,...] g
- 郝斌老师数据结构课程笔记
dcj3sjt126com
数据结构与算法
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
- yii2 cgridview加上选择框进行操作
dcj3sjt126com
GridView
页面代码
<?=Html::beginForm(['controller/bulk'],'post');?>
<?=Html::dropDownList('action','',[''=>'Mark selected as: ','c'=>'Confirmed','nc'=>'No Confirmed'],['class'=>'dropdown',])
- linux mysql
fypop
linux
enquiry mysql version in centos linux
yum list installed | grep mysql
yum -y remove mysql-libs.x86_64
enquiry mysql version in yum repositoryyum list | grep mysql oryum -y list mysql*
install mysq
- Scramble String
hcx2013
String
Given a string s1, we may represent it as a binary tree by partitioning it to two non-empty substrings recursively.
Below is one possible representation of s1 = "great":
- 跟我学Shiro目录贴
jinnianshilongnian
跟我学shiro
历经三个月左右时间,《跟我学Shiro》系列教程已经完结,暂时没有需要补充的内容,因此生成PDF版供大家下载。最近项目比较紧,没有时间解答一些疑问,暂时无法回复一些问题,很抱歉,不过可以加群(334194438/348194195)一起讨论问题。
----广告-----------------------------------------------------
- nginx日志切割并使用flume-ng收集日志
liyonghui160com
nginx的日志文件没有rotate功能。如果你不处理,日志文件将变得越来越大,还好我们可以写一个nginx日志切割脚本来自动切割日志文件。第一步就是重命名日志文件,不用担心重命名后nginx找不到日志文件而丢失日志。在你未重新打开原名字的日志文件前,nginx还是会向你重命名的文件写日志,linux是靠文件描述符而不是文件名定位文件。第二步向nginx主
- Oracle死锁解决方法
pda158
oracle
select p.spid,c.object_name,b.session_id,b.oracle_username,b.os_user_name from v$process p,v$session a, v$locked_object b,all_objects c where p.addr=a.paddr and a.process=b.process and c.object_id=b.
- java之List排序
shiguanghui
list排序
在Java Collection Framework中定义的List实现有Vector,ArrayList和LinkedList。这些集合提供了对对象组的索引访问。他们提供了元素的添加与删除支持。然而,它们并没有内置的元素排序支持。 你能够使用java.util.Collections类中的sort()方法对List元素进行排序。你既可以给方法传递
- servlet单例多线程
utopialxw
单例多线程servlet
转自http://www.cnblogs.com/yjhrem/articles/3160864.html
和 http://blog.chinaunix.net/uid-7374279-id-3687149.html
Servlet 单例多线程
Servlet如何处理多个请求访问?Servlet容器默认是采用单实例多线程的方式处理多个请求的:1.当web服务器启动的
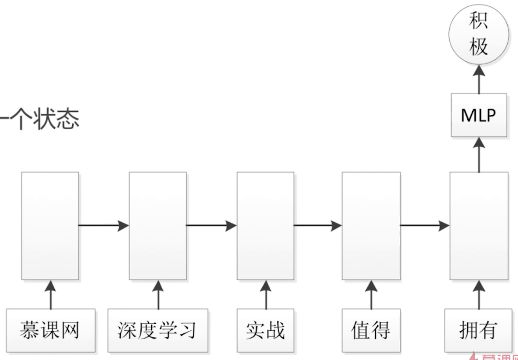

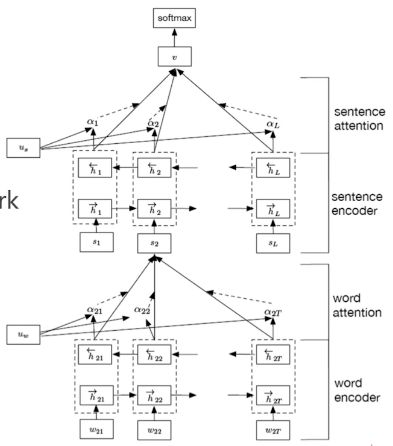

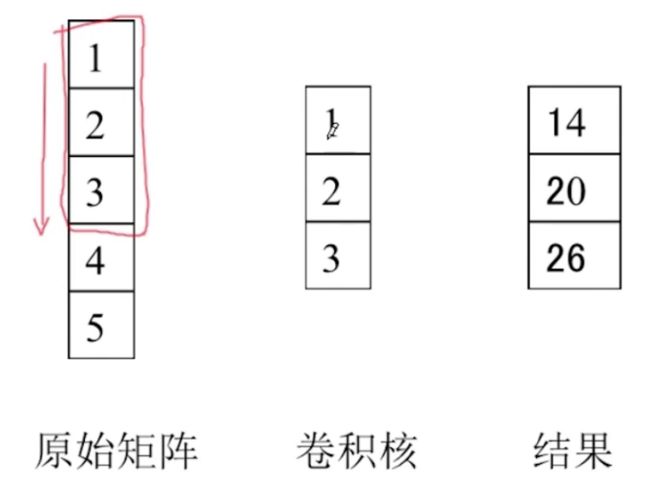
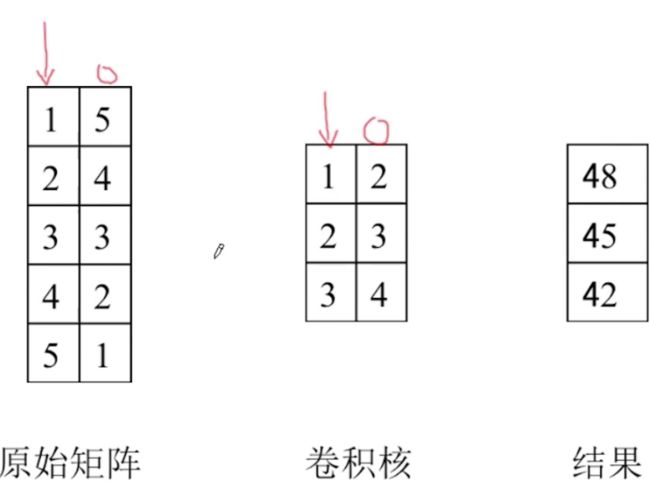
 Embedding压缩
Embedding压缩