《Python自然语言处理(第二版)-Steven Bird等》学习笔记:第04章 编写结构化程序
第04章 编写结构化程序
- 4.1 回到基础
- 赋值
- 等式
- 条件语句
- 4.2 序列
- 序列类型上的操作
- 合并不同类型的序列
- 产生器表达式
- 4.3 风格的问题
- 过程风格与声明风格
- 计数器的一些合理用途
- 4.4 函数:结构化编程的基础
- 函数的输入和输出
- 参数传递
- 变量的作用域
- 参数类型检查
- 功能分解
- 文档说明函数
- 4.5 更多关于函数
- 作为参数的函数
- 累计函数
- 高阶函数
- 参数的命名
- 4.6 程序开发
- Python模块的结构
- 多模块程序
- 误差源头
- 调试技术
- 防御性编程
- 4.7 算法设计
- 递归
- 权衡空间与时间
- 动态规划
- 4.8 Python 库的样例
- Matplotlib绘图工具
- NetworkX
- CSV
- NumPy
- 其他Python 库
- 4.9 小结
4.1 回到基础
赋值
foo = 'Monty'
bar = foo
foo = 'Python' #bar 是foo 的一个副本,所以当用一个新的字符串'Python'覆盖foo 时,bar 的值不会受到影响。
bar
'Monty'
foo = ['Monty', 'Python']
bar = foo
foo[1] = 'Bodkin'
bar #bar = foo 行并不会复制变量的内容,只有它的“引用对象”
['Monty', 'Bodkin']
实际上,两个链表对象foo 和bar 引用计算机内存中的相同的位置;更新foo 将会修改bar,反之亦然。
empty = []
nested = [empty, empty, empty]
nested
[[], [], []]
nested[1].append('Python')
nested
[['Python'], ['Python'], ['Python']]
nested = [[]] * 3
nested
[[], [], []]
nested[1].append('Python') #修改链表中的一个元素,所有的元素都改变了
nested
[['Python'], ['Python'], ['Python']]
id(nested[0]),id(nested[1]),id(nested[2])
(80141320, 80141320, 80141320)
nested[1] = ['Monty'] #当我们分配一个新值给链表中的一个元素时,它并不会传送给其他元素
nested
[['Python'], ['Monty'], ['Python']]
注意:通过一个对象引用修改一个对象与通过覆盖一个对象引用之间的区别
等式
size = 5
python = ['Python']
snake_nest = [python] * size
snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]
True
snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]
True
import random
position = random.choice(range(size))
snake_nest[position] = ['Python']
snake_nest
[['Python'], ['Python'], ['Python'], ['Python'], ['Python']]
snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4] #==只能保证值相同
True
snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4] #is 既要求值相同,而且结构也需相同
False
[id(snake) for snake in snake_nest] #函数id()检测不同的位置
[79659272, 79659272, 79659272, 79659208, 79659272]
条件语句
mixed = ['cat', '', ['dog'], []]
for element in mixed:
if element: #一个非空字符串或链表被判定为真,而一个空字符串或链表的被判定为假。所以,不必在条件中写:len(element) > 0
print(element)
cat
['dog']
animals = ['cat', 'dog']
if 'cat' in animals:
print(1)
elif 'dog' in animals:
print(2) # 表达式中if 子句条件满足,Python 就不会比较elif 子句,所有程序永远不会输出2
1
if 'cat' in animals:
print(1)
if 'dog' in animals:
print(2)
1
2
elif 子句比单独的if 子句潜在的给我们更多信息;当它被判定为真时,告诉我们不仅条件满足而且前面的if 子句的条件不满足。
sent = ['No', 'good', 'fish', 'goes', 'anywhere', 'without', 'a', 'porpoise', '.']
all(len(w) > 4 for w in sent)
False
any(len(w) > 4 for w in sent)
True
4.2 序列
元组由逗号操作符构造,而且通常使用括号括起来,元组可以有任何数目的成员。与链表和字符串一样,元组可以被索引和切片,并有长度。
t = 'walk', 'fem', 3
t
('walk', 'fem', 3)
t[0]
'walk'
len(t)
3
定义一个包含单个元素’snark’的元组是通过添加一个尾随的逗号,像这样:‘snark’。空元组是一个特殊的情况下,使用空括号()定义。
t= 'snark',
t
('snark',)
t= ()
t
()
raw = 'I turned off the spectroroute' #字符串
text = ['I', 'turned', 'off', 'the', 'spectroroute'] #链表
pair = (6, 'turned') #元组
raw[2], text[3], pair[1]
('t', 'the', 'turned')
raw[-3:], text[-3:], pair[-3:]
('ute', ['off', 'the', 'spectroroute'], (6, 'turned'))
len(raw), len(text), len(pair)
(29, 5, 2)
set(text) #定义一个集合
{'I', 'off', 'spectroroute', 'the', 'turned'}
序列类型上的操作
表4.1. 遍历序列的各种方式
| Python | 表达式评论 |
|---|---|
| for item in s | 遍历s 中的元素 |
| for item in sorted(s) | 按顺序遍历s 中的元素 |
| for item in set(s) | 遍历s 中的无重复的元素 |
| for item in reversed(s) | 按逆序遍历s 中的元素 |
| for item in set(s).difference(t) | 遍历在集合s 中不在集合t 的元素 |
| for item in random.shuffle(s) | 按随机顺序遍历s 中的元素 |
序列类型之间相互转换。例如:tuple(s)将任何种类的序列转换成一个元组,list(s)将任何种类的序列转换成一个链表。我们可以使用join()函数将一个字符串链表转换成单独的字符串,例如:’:’.join(words)。
raw = 'Red lorry, yellow lorry, red lorry, yellow lorry.'
import nltk
from nltk import word_tokenize
text = nltk.word_tokenize(raw)
fdist = nltk.FreqDist(text)
list(fdist)
['yellow', 'Red', '.', 'lorry', ',', 'red']
for key in fdist:
print(fdist[key])
2
1
1
4
3
1
words = ['I', 'turned', 'off', 'the', 'spectroroute']
words[2], words[3], words[4] = words[3], words[4], words[2]
words
['I', 'turned', 'the', 'spectroroute', 'off']
#传统方式
tmp = words[2]
words[2] = words[3]
words[3] = words[4]
words[4] = tmp
words
['I', 'turned', 'spectroroute', 'off', 'the']
words = ['I', 'turned', 'off', 'the', 'spectroroute']
tags = ['noun', 'verb', 'prep', 'det', 'noun']
list(zip(words, tags)) #zip()取两个或两个以上的序列中的项目,将它们“压缩”打包成单个的配对链表。
[('I', 'noun'),
('turned', 'verb'),
('off', 'prep'),
('the', 'det'),
('spectroroute', 'noun')]
list(enumerate(words)) #给定一个序列words,enumerate(words)返回一个包含索引和索引处项目的配对。
[(0, 'I'), (1, 'turned'), (2, 'off'), (3, 'the'), (4, 'spectroroute')]
text = nltk.corpus.nps_chat.words()
cut = int(0.9 * len(text)) #分割数据,90%的数据来“训练”一个系统,剩余10%进行测试
training_data, test_data = text[:cut], text[cut:]
text == training_data + test_data
True
len(training_data) / len(test_data)
9.0
合并不同类型的序列
words = 'I turned off the spectroroute'.split()
wordlens = [(len(word), word) for word in words]
wordlens.sort()
' '.join(w for (_, w) in wordlens) #下划线只是一个普通的Python变量,约定可以用下划线表示不会使用其值的变量。)
'I off the turned spectroroute'
lexicon = [
... ('the', 'det', ['Di:', 'D@']),
... ('off', 'prep', ['Qf', 'O:f'])
... ]
列表可以被修改,而元组不能
lexicon.sort()
lexicon[1] = ('turned', 'VBD', ['t3:nd', 't3`nd'])
lexicon
[('off', 'prep', ['Qf', 'O:f']), ('turned', 'VBD', ['t3:nd', 't3`nd'])]
del lexicon[0]
lexicon
[('turned', 'VBD', ['t3:nd', 't3`nd'])]
lexicon = tuple(lexicon)
lexicon
(('turned', 'VBD', ['t3:nd', 't3`nd']),)
lexicon[1] = ('turned', 'VBD', ['t3:nd', 't3`nd'])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
----> 1 lexicon[1] = ('turned', 'VBD', ['t3:nd', 't3`nd'])
TypeError: 'tuple' object does not support item assignment
产生器表达式
text = '''"When I use a word," Humpty Dumpty said in rather a scornful tone,
... "it means just what I choose it to mean - neither more nor less."'''
[w.lower() for w in nltk.word_tokenize(text)][:5] #产生器表达式
['``', 'when', 'i', 'use', 'a']
max([w.lower() for w in nltk.word_tokenize(text)])
'word'
max(w.lower() for w in nltk.word_tokenize(text))
'word'
4.3 风格的问题
Python 代码风格指南:http://www.python.org/dev/peps/pep-0008/
- 代码布局中每个缩进级别应使用4 个空格,避免使用tab 缩进,每行应少于80 个字符长,如果必要的话,可以在圆括号、方括号或花括号内换行
尽量避免键入空格来代替制表符
cv_word_pairs = [(cv, w) for w in rotokas_words
… for cv in re.findall(’[ptksvr][aeiou]’, w)]
cfd = nltk.ConditionalFreqDist(
… (genre, word)
… for genre in brown.categories()
… for word in brown.words(categories=genre))
ha_words = ['aaahhhh', 'ah', 'ahah', 'ahahah', 'ahh', 'ahhahahaha',
... 'ahhh', 'ahhhh', 'ahhhhhh', 'ahhhhhhhhhhhhhh', 'ha',
... 'haaa', 'hah', 'haha', 'hahaaa', 'hahah', 'hahaha']
if (len(syllables) > 4 and len(syllables[2]) == 3 and
… syllables[2][2] in [aeiou] and syllables[2][3] == syllables[1][3]):
… process(syllables)
if len(syllables) > 4 and len(syllables[2]) == 3 and
… syllables[2][2] in [aeiou] and syllables[2][3] == syllables[1][3]:
… process(syllables)
过程风格与声明风格
#过程,传统
tokens = nltk.corpus.brown.words(categories='news')
count = 0
total = 0
for token in tokens:
count += 1
total += len(token)
print(total / count)
4.401545438271973
#声明,优雅,效率高
total = sum(len(t) for t in tokens) #生成器表达式
print(total / len(tokens))
4.401545438271973
word_list = []
len_word_list = len(word_list)
i = 0
while i < len(tokens):
j = 0
while j < len_word_list and word_list[j] < tokens[i]:
j += 1
if j == 0 or tokens[i] != word_list[j]:
word_list.insert(j, tokens[i])
len_word_list += 1
i += 1
word_list = sorted(set(tokens)) #等效的声明版本使用熟悉的内置函数
fd = nltk.FreqDist(nltk.corpus.brown.words())
cumulative = 0.0
most_common_words = [word for (word, count) in fd.most_common()]
for rank, word in enumerate(most_common_words):
cumulative += fd.freq(word)
print("%3d %6.2f%% %s" % (rank + 1, cumulative * 100, word))
if cumulative > 0.25:
break
1 5.40% the
2 10.42% ,
3 14.67% .
4 17.78% of
5 20.19% and
6 22.40% to
7 24.29% a
8 25.97% in
text = nltk.corpus.gutenberg.words('milton-paradise.txt')
longest = ''
for word in text:
if len(word) > len(longest):
longest = word
longest
'unextinguishable'
更加清楚的解决方案是使用两个链表推导
maxlen = max(len(word) for word in text)
[word for word in text if len(word) == maxlen]
['unextinguishable',
'transubstantiate',
'inextinguishable',
'incomprehensible']
计数器的一些合理用途
使用一个循环变量中提取链表中连续重叠的n-grams:
sent = ['The', 'dog', 'gave', 'John', 'the', 'newspaper']
n = 3
[sent[i:i+n] for i in range(len(sent)-n+1)]
[['The', 'dog', 'gave'],
['dog', 'gave', 'John'],
['gave', 'John', 'the'],
['John', 'the', 'newspaper']]
确保循环变量范围的正确相当棘手的。因为这是NLP 中的常见操作,NLTK 提供了支持函数bigrams(text)、trigrams(text)和一个更通用的ngrams(text, n)。
建立一个m 行n 列的数组,其中每个元素是一个集合
import pprint
m, n = 3, 7
array = [[set() for i in range(n)] for j in range(m)]
array[2][5].add('Alice')
pprint.pprint(array)
[[set(), set(), set(), set(), set(), set(), set()],
[set(), set(), set(), set(), set(), set(), set()],
[set(), set(), set(), set(), set(), {'Alice'}, set()]]
4.4 函数:结构化编程的基础
#例4-1. 从文件读取文本
import re
def get_text(file):
"""Read text from a file, normalizing whitespace and stripping HTML markup."""
text = open(file).read()
text = re.sub('\s+', ' ', text)
text = re.sub(r'<.*?>', ' ', text)
return text
想从一个HTML 文件得到干净的文字,都可以用文件的名字作为唯一的参数调用get_text()。它会返回一个字符串,我们可以将它指定给一个变量,例如:contents = get_text(“test.html”)。
函数定义内的第一个字符串被称为docstring。
help(get_text)
Help on function get_text in module __main__:
get_text(file)
Read text from a file, normalizing whitespace and stripping HTML markup.
函数有助于提高我们的工作的可重用性、可读性和可靠性。
函数的输入和输出
def repeat(msg, num):
return ' '.join([msg] * num)
monty = 'Monty Python'
repeat(monty, 3)
'Monty Python Monty Python Monty Python'
def monty():
return "Monty Python"
monty()
'Monty Python'
repeat(monty(), 3)
'Monty Python Monty Python Monty Python'
repeat('Monty Python', 3)
'Monty Python Monty Python Monty Python'
def my_sort1(mylist): # good: modifies its argument, no return value
mylist.sort()
def my_sort2(mylist): # good: doesn't touch its argument, returns value
return sorted(mylist)
def my_sort3(mylist): # bad: modifies its argument and also returns it
mylist.sort()
return mylist
第三个是危险的,因为程序员可能没有意识到它已经修改了给它的输入。一般情况下,函数应该修改参数的内容(my_sort1())或返回一个值(my_s
ort2()),而不是两个都做(my_sort3())。
参数传递
将一个空字符串分配给w,将一个空链表分配给p。调用该函数后,w 没有变,而p 改变了
def set_up(word, properties):
word = 'lolcat'
properties.append('noun')
properties = 5
w = ''
p = []
set_up(w, p)
w
''
p
['noun']
比较一下
w = ''
word = w
word = 'lolcat'
w
''
p = []
properties = p
properties.append['noun']
properties = 5
p
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in ()
1 p = []
2 properties = p
----> 3 properties.append['noun']
4 properties = 5
5 p
TypeError: 'builtin_function_or_method' object is not subscriptable
变量的作用域
LGB规则:本地(local),全局(global),然后内置(built-in)
注意!一个函数可以使用global 声明创建一个新的全局变量。然而,这种
做法应尽可能避免。在函数内部定义全局变量会导致上下文依赖性而限制
函数的便携性(或重用性)。一般来说,你应该使用参数作为函数的输入,
返回值作为函数的输出。
参数类型检查
def tag(word):
if word in ['a', 'the', 'all']:
return 'det'
else:
return 'noun'
tag('the')
'det'
tag('knight')
'noun'
tag(["'Tis", 'but', 'a', 'scratch'])
'noun'
def tag(word):
assert isinstance(word, basestring), "argument to tag() must be a string"
if word in ['a', 'the', 'all']:
return 'det'
else:
return 'noun'
tag(["'Tis", 'but', 'a', 'scratch']) #防御性编程
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
in ()
----> 1 tag(["'Tis", 'but', 'a', 'scratch']) #防御性编程
in tag(word)
1 def tag(word):
----> 2 assert isinstance(word, basestring), "argument to tag() must be a string"
3 if word in ['a', 'the', 'all']:
4 return 'det'
5 else:
NameError: name 'basestring' is not defined
功能分解
#例4-2. 设计不佳的函数用来计算高频词。
from urllib import request
from bs4 import BeautifulSoup
def freq_words(url, freqdist, n):
html = request.urlopen(url).read().decode('utf8')
raw = BeautifulSoup(html).get_text()
for word in word_tokenize(raw):
freqdist[word.lower()] += 1
result = []
for word, count in freqdist.most_common(n):
result = result + [word]
print(result)
constitution = "https://www.baidu.com"
fd = nltk.FreqDist()
freq_words(constitution, fd, 30)
["''", '//', ':', ')', '(', 'https', '``', 'http', 'location.replace', ',', ';', 'location.href.replace']
C:\Program Files\Anaconda3\lib\site-packages\bs4\__init__.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 193 of the file C:\Program Files\Anaconda3\lib\runpy.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))
from urllib import request
from bs4 import BeautifulSoup
def freq_words(url, n):
html = request.urlopen(url).read().decode('utf8')
text = BeautifulSoup(html).get_text()
freqdist = nltk.FreqDist(word.lower() for word in word_tokenize(text))
return [word for (word, _) in fd.most_common(n)]
freq_words(constitution, 30)
C:\Program Files\Anaconda3\lib\site-packages\bs4\__init__.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 193 of the file C:\Program Files\Anaconda3\lib\runpy.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))
["''",
'//',
':',
')',
'(',
'https',
'``',
'http',
'location.replace',
',',
';',
'location.href.replace']
文档说明函数
docstring 中可以包括一个doctest块,说明使用的函数和预期的输出。这些都可以使用
Python 的docutils 模块自动测试。docstring 中应当记录函数的每个参数的类型和返回类型。
至少可以用纯文本来做这些。
例如4-4 一个完整的docstring 的演示,包括一行总结,一个更详细的解释,一个doctest 例
子以及特定参数、类型、返回值和异常的epytext 标记。
def accuracy(reference, test):
"""
Calculate the fraction of test items that equal the corresponding reference items.
Given a list of reference values and a corresponding list of test values,
return the fraction of corresponding values that are equal.
In particular, return the fraction of indexes
{0>> accuracy(['ADJ', 'N', 'V', 'N'], ['N', 'N', 'V', 'ADJ'])
0.5
:param reference: An ordered list of reference values
:type reference: list
:param test: A list of values to compare against the corresponding
reference values
:type test: list
:return: the accuracy score
:rtype: float
:raises ValueError: If reference and length do not have the same length
"""
if len(reference) != len(test):
raise ValueError("Lists must have the same length.")
num_correct = 0
for x, y in zip(reference, test):
if x == y:
num_correct += 1
return float(num_correct) / len(reference)
4.5 更多关于函数
作为参数的函数
sent = ['Take', 'care', 'of', 'the', 'sense', ',', 'and', 'the',
... 'sounds', 'will', 'take', 'care', 'of', 'themselves', '.']
def extract_property(prop):
return [prop(word) for word in sent]
extract_property(len) #传递内置函数len()
[4, 4, 2, 3, 5, 1, 3, 3, 6, 4, 4, 4, 2, 10, 1]
def last_letter(word):
return word[-1]
extract_property(last_letter) #用户定义的函数last_letter()
['e', 'e', 'f', 'e', 'e', ',', 'd', 'e', 's', 'l', 'e', 'e', 'f', 's', '.']
extract_property(lambda w: w[-1]) # lambda 表达式
['e', 'e', 'f', 'e', 'e', ',', 'd', 'e', 's', 'l', 'e', 'e', 'f', 's', '.']
累计函数
例4-5. 累计输出到一个链表
def search1(substring, words):
result = []
for word in words:
if substring in word:
result.append(word)
return result
def search2(substring, words):
for word in words:
if substring in word:
yield word
for item in search1('zz', nltk.corpus.brown.words()):
print(item, end=" ")
Grizzlies' fizzled Rizzuto huzzahs dazzler jazz Pezza Pezza Pezza embezzling embezzlement pizza jazz Ozzie nozzle drizzly puzzle puzzle dazzling Sizzling guzzle puzzles dazzling jazz jazz Jazz jazz Jazz jazz jazz Jazz jazz jazz jazz Jazz jazz dizzy jazz Jazz puzzler jazz jazzmen jazz jazz Jazz Jazz Jazz jazz Jazz jazz jazz jazz Jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz Jazz Jazz jazz jazz nozzles nozzle puzzle buzz puzzle blizzard blizzard sizzling puzzled puzzle puzzle muzzle muzzle muezzin blizzard Neo-Jazz jazz muzzle piazzas puzzles puzzles embezzle buzzed snazzy buzzes puzzled puzzled muzzle whizzing jazz Belshazzar Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie's Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie blizzard blizzards blizzard blizzard fuzzy Lazzeri Piazza piazza palazzi Piazza Piazza Palazzo Palazzo Palazzo Piazza Piazza Palazzo palazzo palazzo Palazzo Palazzo Piazza piazza piazza piazza Piazza Piazza Palazzo palazzo Piazza piazza pizza Piazza Palazzo palazzo dazzling puzzling Wozzek dazzling dazzling buzzing Jazz jazz Jazz Jazz jazz jazz jazz jazz Jazz jazz jazz jazz Fuzzy Lizzy Lizzy jazz fuzzy puzzles puzzling puzzling dazzle puzzle dazzling puzzled jazz jazz jazz jazzy whizzed frazzled quizzical puzzling poetry-and-jazz poetry-and-jazz jazz jazz jazz jazz jazz jazz jazz Jazz jazz jazz jazz poetry-and-jazz jazz jazz jazz Dizzy jazz jazz jazz jazz jazz poetry-and-jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz dazzled bedazzlement bedazzled Piazzo nozzles nozzles buzzing dazzles dizzy puzzling puzzling puzzling puzzle muzzle puzzled nozzle Pozzatti Pozzatti Pozzatti puzzled Pozzatti Pozzatti dazzling pizzicato Jazz jazz jazz jazz jazz nozzle grizzled fuzzy muzzle puzzled puzzle muzzle blizzard buzz dizzily drizzle drizzle drizzle sizzled puzzled puzzled puzzled fuzzed buzz buzz buzz buzz-buzz-buzz buzzes fuzzy frizzled drizzle drizzle drizzling drizzling fuzz jazz jazz fuzz puzzle puzzling Nozze mezzo puzzled puzzled dazzling muzzle muzzle muzzle buzzed whizzed sizzled palazzos puzzlement frizzling puzzled puzzled puzzled dazzling muzzles fuzzy jazz ex-jazz sizzle grizzly guzzled buzzing fuzz nuzzled Kizzie Kizzie Kizzie Kezziah Kizzie Kizzie Buzz's Buzz Buzz Buzz Buzz Buzz Buzz Buzz Buzz dizzy piazza buzzing Puzzled dizziness dazzled Piazza Carrozza fuzzy dizzy buzzing buzzing puzzled puzzling puzzled puzzled Quizzical pizza
for item in search2('zz', nltk.corpus.brown.words()):
print(item, end=" ")
Grizzlies' fizzled Rizzuto huzzahs dazzler jazz Pezza Pezza Pezza embezzling embezzlement pizza jazz Ozzie nozzle drizzly puzzle puzzle dazzling Sizzling guzzle puzzles dazzling jazz jazz Jazz jazz Jazz jazz jazz Jazz jazz jazz jazz Jazz jazz dizzy jazz Jazz puzzler jazz jazzmen jazz jazz Jazz Jazz Jazz jazz Jazz jazz jazz jazz Jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz Jazz Jazz jazz jazz nozzles nozzle puzzle buzz puzzle blizzard blizzard sizzling puzzled puzzle puzzle muzzle muzzle muezzin blizzard Neo-Jazz jazz muzzle piazzas puzzles puzzles embezzle buzzed snazzy buzzes puzzled puzzled muzzle whizzing jazz Belshazzar Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie's Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie Lizzie blizzard blizzards blizzard blizzard fuzzy Lazzeri Piazza piazza palazzi Piazza Piazza Palazzo Palazzo Palazzo Piazza Piazza Palazzo palazzo palazzo Palazzo Palazzo Piazza piazza piazza piazza Piazza Piazza Palazzo palazzo Piazza piazza pizza Piazza Palazzo palazzo dazzling puzzling Wozzek dazzling dazzling buzzing Jazz jazz Jazz Jazz jazz jazz jazz jazz Jazz jazz jazz jazz Fuzzy Lizzy Lizzy jazz fuzzy puzzles puzzling puzzling dazzle puzzle dazzling puzzled jazz jazz jazz jazzy whizzed frazzled quizzical puzzling poetry-and-jazz poetry-and-jazz jazz jazz jazz jazz jazz jazz jazz Jazz jazz jazz jazz poetry-and-jazz jazz jazz jazz Dizzy jazz jazz jazz jazz jazz poetry-and-jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz jazz dazzled bedazzlement bedazzled Piazzo nozzles nozzles buzzing dazzles dizzy puzzling puzzling puzzling puzzle muzzle puzzled nozzle Pozzatti Pozzatti Pozzatti puzzled Pozzatti Pozzatti dazzling pizzicato Jazz jazz jazz jazz jazz nozzle grizzled fuzzy muzzle puzzled puzzle muzzle blizzard buzz dizzily drizzle drizzle drizzle sizzled puzzled puzzled puzzled fuzzed buzz buzz buzz buzz-buzz-buzz buzzes fuzzy frizzled drizzle drizzle drizzling drizzling fuzz jazz jazz fuzz puzzle puzzling Nozze mezzo puzzled puzzled dazzling muzzle muzzle muzzle buzzed whizzed sizzled palazzos puzzlement frizzling puzzled puzzled puzzled dazzling muzzles fuzzy jazz ex-jazz sizzle grizzly guzzled buzzing fuzz nuzzled Kizzie Kizzie Kizzie Kezziah Kizzie Kizzie Buzz's Buzz Buzz Buzz Buzz Buzz Buzz Buzz Buzz dizzy piazza buzzing Puzzled dizziness dazzled Piazza Carrozza fuzzy dizzy buzzing buzzing puzzled puzzling puzzled puzzled Quizzical pizza
def permutations(seq):
if len(seq) <= 1:
yield seq
else:
for perm in permutations(seq[1:]):
for i in range(len(perm)+1):
yield perm[:i] + seq[0:1] + perm[i:]
list(permutations(['police', 'fish', 'buffalo']))
[['police', 'fish', 'buffalo'],
['fish', 'police', 'buffalo'],
['fish', 'buffalo', 'police'],
['police', 'buffalo', 'fish'],
['buffalo', 'police', 'fish'],
['buffalo', 'fish', 'police']]
高阶函数
def is_content_word(word):
return word.lower() not in ['a', 'of', 'the', 'and', 'will', ',', '.']
sent = ['Take', 'care', 'of', 'the', 'sense', ',', 'and', 'the',
... 'sounds', 'will', 'take', 'care', 'of', 'themselves', '.']
list(filter(is_content_word, sent))
['Take', 'care', 'sense', 'sounds', 'take', 'care', 'themselves']
[w for w in sent if is_content_word(w)]
['Take', 'care', 'sense', 'sounds', 'take', 'care', 'themselves']
lengths = list(map(len, nltk.corpus.brown.sents(categories='news')))
sum(lengths) / len(lengths)
21.75081116158339
lengths = [len(sent) for sent in nltk.corpus.brown.sents(categories='news')]
sum(lengths) / len(lengths)
21.75081116158339
参数的命名
def repeat(msg='' , num=1):
return msg * num
repeat(num=3) #关键字参数
''
repeat(msg='Alice') #关键字参数
'Alice'
repeat(num=5, msg='Alice') #关键字参数
'AliceAliceAliceAliceAlice'
def generic(*args, **kwargs): #定义一个函数,接受任意数量的未命名和命名参数,并通过一个就地的参数链表*args 和一个就地的关键字参数字典**kwargs 来访问它们。
print(args)
print( kwargs)
generic(1, "African swallow", monty="python") #当*args 作为函数参数时,它实际上对应函数所有的未命名参数。
(1, 'African swallow')
{'monty': 'python'}
处理可变数目的参数的函数zip()
song = [['four', 'calling', 'birds'],
... ['three', 'French', 'hens'],
... ['two', 'turtle', 'doves']]
list(zip(song[0], song[1], song[2]))
[('four', 'three', 'two'),
('calling', 'French', 'turtle'),
('birds', 'hens', 'doves')]
list(zip(*song)) #*song 仅仅是一个方便的记号,相当于输入了song[0],song[1],song[2]
[('four', 'three', 'two'),
('calling', 'French', 'turtle'),
('birds', 'hens', 'doves')]
def freq_words(file, min=1, num=10):
text = open(file).read()
tokens = word_tokenize(text)
freqdist = nltk.FreqDist(t for t in tokens if len(t) >= min)
return freqdist.most_common(num)
fw = freq_words(‘ch01.rst’, 4, 10)
fw = freq_words(‘ch01.rst’, min=4, num=10)
fw = freq_words(‘ch01.rst’, num=10, min=4)
设置了verbose 标志将会报告其进展情况:
def freq_words(file, min=1, num=10, verbose=False):
freqdist = FreqDist()
if verbose: print("Opening", file)
text = open(file).read()
if verbose: print("Read in %d characters" % len(file))
for word in word_tokenize(text):
if len(word) >= min:
freqdist[word] += 1
if verbose and freqdist.N() % 100 == 0: print(".", sep="")
if verbose: print
return freqdist.most_common(num)
4.6 程序开发
Python模块的结构
Python 模块只是一些单独的.py 文件,from module import * 导入这个模块
多模块程序
一个多模块程序的结构:主程序从其他模块导入函数;独特的分析任务在主程序本地进行,而一般的载入和可视化任务被分离开以便可以重用和抽象。
误差源头
- 首先,输入的数据可能包含一些意想不到的字符。
- 第二,提供的函数可能不会像预期的那样运作。
- 第三,我们对Python 语义的理解可能出错。
调试技术
Python 提供了一个调试器,它允许你监视程序的执行,指定程序暂停运行的行号(即断点),逐步调试代码段和检查变量的值。
import pdb
# import mymodule
# pdb.run('mymodule.myfunction()')
防御性编程
4.7 算法设计
- 分而治之,如:对一个数组排序,我们将其分成两半并对每一半进行排序(递归);将每个排好序的一半合并成一个完整的链表(再次递归);这个算法被称为“归并排序“。
- 预排序
递归
解决一个大小为n 的问题,可以将其分成两半,然后处理一个或多个大小为n/2 的问题。一种一般的方式来实现这种方法是使用递归。
#迭代
def factorial1(n):
result = 1
for i in range(n):
result *= (i+1)
return result
#递归
def factorial2(n):
if n == 1:
return 1
else:
return n * factorial2(n-1)
def size1(s):
return 1 + sum(size1(child) for child in s.hyponyms())
def size2(s):
layer = [s]
total = 0
while layer:
total += len(layer)
layer = [h for c in layer for h in c.hyponyms()]
return total
from nltk.corpus import wordnet as wn
dog = wn.synset('dog.n.01')
size1(dog)
190
size2(dog)
190
例4-6. 构建一个字母查找树:一个递归函数建立一个嵌套的字典结构,每一级嵌套包
含给定前缀的所有单词,子查找树含有所有可能的后续词。
def insert(trie, key, value):
if key:
first, rest = key[0], key[1:]
if first not in trie:
trie[first] = {}
insert(trie[first], rest, value)
else:
trie['value'] = value
trie = {}
insert(trie, 'chat', 'cat')
insert(trie, 'chien', 'dog')
insert(trie, 'chair', 'flesh')
insert(trie, 'chic', 'stylish')
trie = dict(trie) # for nicer printing
trie['c']['h']['a']['t']['value']
'cat'
pprint.pprint(trie, width=40)
{'c': {'h': {'a': {'i': {'r': {'value': 'flesh'}},
't': {'value': 'cat'}},
'i': {'c': {'value': 'stylish'},
'e': {'n': {'value': 'dog'}}}}}}
迭代的解决方案往往比递归解决方案的更高效。
权衡空间与时间
例4-7. 一个简单的全文检索系统
def raw(file):
contents = open(file).read()
contents = re.sub(r'<.*?>', ' ', contents)
contents = re.sub('\s+', ' ', contents)
return contents
def snippet(doc, term):
text = ' '*30 + raw(doc) + ' '*30
pos = text.index(term)
return text[pos-30:pos+30]
print("Building Index...")
files = nltk.corpus.movie_reviews.abspaths()
idx = nltk.Index((w, f) for f in files for w in raw(f).split())
query = ''
while query != "quit":
query = input("query> ") # use raw_input() in Python 2
if query in idx:
for doc in idx[query]:
print(snippet(doc, query))
else:
print("Not found")
Building Index...
query> efsdfds
Not found
query> we
the problems with the movie ? well , its main problem is tha.........................................
" and you get something that well describes him and his art
例4-8. 预处理已标注的语料库数据,将所有的词和标注转换成整数
def preprocess(tagged_corpus):
words = set()
tags = set()
for sent in tagged_corpus:
for word, tag in sent:
words.add(word)
tags.add(tag)
wm = dict((w,i) for (i,w) in enumerate(words))
tm = dict((t,i) for (i,t) in enumerate(tags))
return [[(wm[w], tm[t]) for (w,t) in sent] for sent in tagged_corpus]
from timeit import Timer
vocab_size = 10000
setup_list = "import random; vocab = range(%d)" % vocab_size
setup_set = "import random; vocab = set(range(%d))" % vocab_size
statement = "random.randint(0, %d) in vocab" % (vocab_size * 2)
print(Timer(statement, setup_list).timeit(100))
print(Timer(statement, setup_set).timeit(100))
动态规划
动态规划(Dynamic programming)是一种自然语言处理中被广泛使用的算法设计的一般方法。动态规划用于解决包含多个重叠的子问题的问题。
例4-9. 四种方法计算梵文旋律:(一)迭代;(二)自底向上的动态规划;(三)自上而下的动态规划;(四)内置默记法。
def virahanka1(n):
if n == 0:
return [""]
elif n == 1:
return ["S"]
else:
s = ["S" + prosody for prosody in virahanka1(n-1)]
l = ["L" + prosody for prosody in virahanka1(n-2)]
return s + l
def virahanka2(n):
lookup = [[""], ["S"]]
for i in range(n-1):
s = ["S" + prosody for prosody in lookup[i+1]]
l = ["L" + prosody for prosody in lookup[i]]
lookup.append(s + l)
return lookup[n]
def virahanka3(n, lookup={0:[""], 1:["S"]}):
if n not in lookup:
s = ["S" + prosody for prosody in virahanka3(n-1)]
l = ["L" + prosody for prosody in virahanka3(n-2)]
lookup[n] = s + l
return lookup[n]
from nltk import memoize
@memoize
def virahanka4(n):
if n == 0:
return [""]
elif n == 1:
return ["S"]
else:
s = ["S" + prosody for prosody in virahanka4(n-1)]
l = ["L" + prosody for prosody in virahanka4(n-2)]
return s + l
virahanka1(4)
virahanka2(4)
virahanka3(4)
virahanka4(4)
4.8 Python 库的样例
Matplotlib绘图工具
from numpy import arange
from matplotlib import pyplot
colors = 'rgbcmyk' # red, green, blue, cyan, magenta, yellow, black
def bar_chart(categories, words, counts):
"Plot a bar chart showing counts for each word by category"
ind = arange(len(words))
width = 1 / (len(categories) + 1)
bar_groups = []
for c in range(len(categories)):
bars = pyplot.bar(ind+c*width, counts[categories[c]], width,
color=colors[c % len(colors)])
bar_groups.append(bars)
pyplot.xticks(ind+width, words)
pyplot.legend([b[0] for b in bar_groups], categories, loc='upper left')
pyplot.ylabel('Frequency')
pyplot.title('Frequency of Six Modal Verbs by Genre')
pyplot.show()
genres = ['news', 'religion', 'hobbies', 'government', 'adventure']
modals = ['can', 'could', 'may', 'might', 'must', 'will']
import nltk
cfdist = nltk.ConditionalFreqDist(
(genre, word)
for genre in genres
for word in nltk.corpus.brown.words(categories=genre)
if word in modals)
counts = {}
for genre in genres:
counts[genre] = [cfdist[genre][word] for word in modals]
bar_chart(genres, modals, counts)

from matplotlib import use, pyplot
use('Agg')
pyplot.savefig('modals.png')
print('Content-Type: text/html')
print()
print('')
print(' ')
print('')
')
print('')
Content-Type: text/html
C:\Program Files\Anaconda3\lib\site-packages\ipykernel\__main__.py:2: UserWarning:
This call to matplotlib.use() has no effect because the backend has already
been chosen; matplotlib.use() must be called *before* pylab, matplotlib.pyplot,
or matplotlib.backends is imported for the first time.
The backend was *originally* set to 'module://ipykernel.pylab.backend_inline' by the following code:
File "C:\Program Files\Anaconda3\lib\runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "C:\Program Files\Anaconda3\lib\runpy.py", line 85, in _run_code
exec(code, run_globals)
File "C:\Program Files\Anaconda3\lib\site-packages\ipykernel\__main__.py", line 3, in
app.launch_new_instance()
File "C:\Program Files\Anaconda3\lib\site-packages\traitlets\config\application.py", line 653, in launch_instance
app.start()
File "C:\Program Files\Anaconda3\lib\site-packages\ipykernel\kernelapp.py", line 474, in start
ioloop.IOLoop.instance().start()
File "C:\Program Files\Anaconda3\lib\site-packages\zmq\eventloop\ioloop.py", line 162, in start
super(ZMQIOLoop, self).start()
File "C:\Program Files\Anaconda3\lib\site-packages\tornado\ioloop.py", line 887, in start
handler_func(fd_obj, events)
File "C:\Program Files\Anaconda3\lib\site-packages\tornado\stack_context.py", line 275, in null_wrapper
return fn(*args, **kwargs)
File "C:\Program Files\Anaconda3\lib\site-packages\zmq\eventloop\zmqstream.py", line 440, in _handle_events
self._handle_recv()
File "C:\Program Files\Anaconda3\lib\site-packages\zmq\eventloop\zmqstream.py", line 472, in _handle_recv
self._run_callback(callback, msg)
File "C:\Program Files\Anaconda3\lib\site-packages\zmq\eventloop\zmqstream.py", line 414, in _run_callback
callback(*args, **kwargs)
File "C:\Program Files\Anaconda3\lib\site-packages\tornado\stack_context.py", line 275, in null_wrapper
return fn(*args, **kwargs)
File "C:\Program Files\Anaconda3\lib\site-packages\ipykernel\kernelbase.py", line 276, in dispatcher
return self.dispatch_shell(stream, msg)
File "C:\Program Files\Anaconda3\lib\site-packages\ipykernel\kernelbase.py", line 228, in dispatch_shell
handler(stream, idents, msg)
File "C:\Program Files\Anaconda3\lib\site-packages\ipykernel\kernelbase.py", line 390, in execute_request
user_expressions, allow_stdin)
File "C:\Program Files\Anaconda3\lib\site-packages\ipykernel\ipkernel.py", line 196, in do_execute
res = shell.run_cell(code, store_history=store_history, silent=silent)
File "C:\Program Files\Anaconda3\lib\site-packages\ipykernel\zmqshell.py", line 501, in run_cell
return super(ZMQInteractiveShell, self).run_cell(*args, **kwargs)
File "C:\Program Files\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2717, in run_cell
interactivity=interactivity, compiler=compiler, result=result)
File "C:\Program Files\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2821, in run_ast_nodes
if self.run_code(code, result):
File "C:\Program Files\Anaconda3\lib\site-packages\IPython\core\interactiveshell.py", line 2881, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "", line 2, in
from matplotlib import pyplot
File "C:\Program Files\Anaconda3\lib\site-packages\matplotlib\pyplot.py", line 72, in
from matplotlib.backends import pylab_setup
File "C:\Program Files\Anaconda3\lib\site-packages\matplotlib\backends\__init__.py", line 14, in
line for line in traceback.format_stack()
from ipykernel import kernelapp as app
NetworkX
NetworkX 包定义和操作被称为图的由节点和边组成的结构。它可以从https://networkx.lanl.gov/ 得到。NetworkX 可以和Matplotlib 结合使用可视化如WordNet 的网络结构(语义网络)。
Anaconda Jupyter不同版本Python下共存使用
- 1、打开conda prompt ,一般默认的是base,可以使用conda env list 列出当前系统中存在多少环境,使用activate env_name 来激活你想要使用的环境,
- 2、接下来就是开挂似的conda create --name python34 python=3.4
- 3、激活环境 activate python34
- 4、python -m pip install ipykernel
- 5、python -m ipykernel install --user
以下几个软件工具包必须完整安装:
- nltk
- graphviz软件:http://www.graphviz.org Windows 环境下需安装graphviz-2.38.msi,将C:\Program Files (x86)\Graphviz2.38\bin增加到环境变量path中
- networkx:建议安装1.9.1版本(报错:AttributeError: ‘module’ object has no attribute ‘graphviz_layout’)
- pygraphviz:连接graphviz与networkx的API接口(可以在?http://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载wheel文件, pygraphviz-1.3.1-cp34-none-win_amd64.whl
- matplotlib:Python绘图框架(可以在http://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载wheel文件)
- Biopython:生物信息的Python包(可以在http://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载wheel文件)
安装完上述工具包后:
- 输入jupyter notebook就打开了当前环境的jupyter notebook
import networkx as nx
import matplotlib
from nltk.corpus import wordnet as wn
#版本升级后需要显示导入nexworkx的函数,例如graphviz_layout
from networkx.drawing.nx_agraph import graphviz_layout
def traverse(graph, start, node):
graph.depth[node.name] = node.shortest_path_distance(start)
for child in node.hyponyms():
graph.add_edge(node.name, child.name)
traverse(graph, start, child)
def hyponym_graph(start):
G = nx.Graph()
G.depth = {}
traverse(G, start, start)
return G
def graph_draw(graph):
nx.draw_graphviz(graph,
node_size = [16 * graph.degree(n) for n in graph],
node_color = [graph.depth[n] for n in graph],
with_labels = False)
matplotlib.pyplot.show()
dog = wn.synset('dog.n.01')
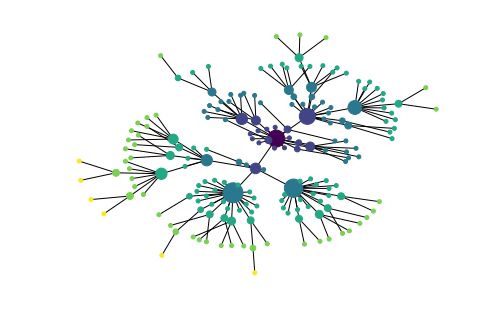
graph = hyponym_graph(dog)
graph_draw(graph)
CSV
import csv
input_file = open("lexicon.csv", "rb")
for row in csv.reader(input_file):
print(row)
NumPy
from numpy import array
cube = array([ [[0,0,0], [1,1,1], [2,2,2]],
[[3,3,3], [4,4,4], [5,5,5]],
[[6,6,6], [7,7,7], [8,8,8]] ])
cube[1,1,1]
4
cube[2].transpose()
array([[6, 7, 8],
[6, 7, 8],
[6, 7, 8]])
cube[2,1:]
array([[7, 7, 7],
[8, 8, 8]])
#矩阵的奇异值分解,潜在语义分析中使用的操作,它能帮助识别一个文档集合中的隐含概念。
from numpy import linalg
a=array([[4,0], [3,-5]])
u,s,vt = linalg.svd(a)
u
array([[-0.4472136 , -0.89442719],
[-0.89442719, 0.4472136 ]])
s
array([6.32455532, 3.16227766])
vt
array([[-0.70710678, 0.70710678],
[-0.70710678, -0.70710678]])
其他Python 库
http://pypi.python.org/
4.9 小结
- Python 赋值和参数传递使用对象引用,例如:如果a 是一个链表,我们分配b = a,然后任何a 上的操作都将修改b,反之亦然。
- is 操作测试是否两个对象是相同的内部对象,而==测试是否两个对象是相等的。两者的区别和标识符与类型的区别相似。
- 字符串、链表和元组是不同类型的序列对象,支持常见的操作如:索引、切片、len()、sorted()和使用in 的成员测试。
- 我们可以通过以写方式打开文件来写入文本到一个文件:ofile = open(‘output.txt’,‘w’),然后加入内容到文件:ofile.write(“Monty Python”),最后关闭文件ofile.close()。
- 声明式的编程风格通常会产生更简洁更可读的代码;手动递增循环变量通常是不必要的。枚举一个序列,使用enumerate()。
- 函数是一个重要的编程抽象,需要理解的关键概念有:参数传递、变量的范围和docstrings。
- 函数作为一个命名空间:函数内部定义的名称在该函数外不可见,除非这些名称被宣布为是全局的。
- 模块允许将材料与本地的文件逻辑的关联起来。一个模块作为一个命名空间:在一个模块中定义的名称——如变量和函数——在其他模块中不可见,除非这些名称被导入。
- 动态规划是一种在NLP 中广泛使用的算法设计技术,它存储以前的计算结果,以避免不必要的重复计算。
致谢
《Python自然语言处理》123 4,作者:Steven Bird, Ewan Klein & Edward Loper,是实践性很强的一部入门读物,2009年第一版,2015年第二版,本学习笔记结合上述版本,对部分内容进行了延伸学习、练习,在此分享,期待对大家有所帮助,欢迎加我微信(验证:NLP),一起学习讨论,不足之处,欢迎指正。

参考文献
http://nltk.org/ ↩︎
Steven Bird, Ewan Klein & Edward Loper,Natural Language Processing with Python,2009 ↩︎
(英)伯德,(英)克莱因,(美)洛普,《Python自然语言处理》,2010年,东南大学出版社 ↩︎
Steven Bird, Ewan Klein & Edward Loper,Natural Language Processing with Python,2015 ↩︎