python爬虫爬取qq音乐热歌榜的歌曲到本地
文章目录
- 项目目标
- 具体实现步骤
- 完整代码
- 运行结果
项目目标
爬取qq音乐热歌榜https://y.qq.com/n/yqq/toplist/26.html到本地文件夹
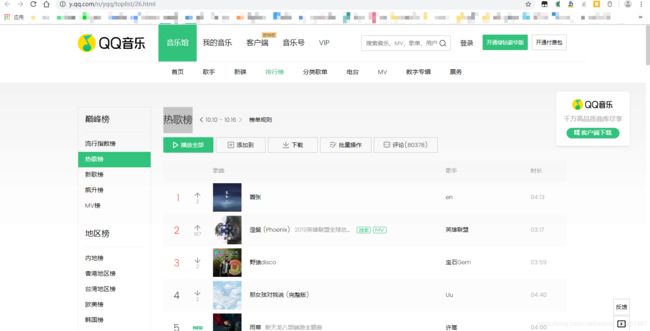
具体实现步骤
程序思路:用selenium库通过目标网页的前端获取资源地址,将地址指向的文件下载至本地
本程序的selenium要配合chrome浏览器使用,selenium使用方法可以参考Selenium2+python自动化45-18种定位方法(find_elements)
完整代码
# -*- coding: utf-8 -*-
# [url=home.php?mod=space&uid=238618]@Time[/url] : 2019/10/21 3:46 PM
# [url=home.php?mod=space&uid=686208]@AuThor[/url] : python-小智!!
# @FileName: qq_music.py
# @Software: IntelliJ IDEA
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from tqdm import tqdm
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import re
import json
import requests
import os
class QqMusic:
def __init__(self):
# 设置 chrome 无界面化模式
self.chrome_options = Options()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
chrome_driver = "C:/Users/LU/AppData/Local/Programs/Python/Python37-32/Scripts/chromedriver.exe" # 指定位置,selenium的位置
self.header = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
"accept-language": "zh-CN,zh;q=0.9",
"referer": "https://y.qq.com/n/yqq/toplist/26.html",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
self.driver = webdriver.Chrome(chrome_driver, options=self.chrome_options)
def loading_music(self):
self.driver.get("https://y.qq.com/n/yqq/toplist/26.html")
print(self.driver.title)
WebDriverWait(self.driver, 10).until(EC.presence_of_all_elements_located((By.CLASS_NAME, "songlist__songname_txt")))
lists = self.driver.find_elements_by_class_name("songlist__songname_txt")
pattern = re.compile(r"https://y.qq.com/n/yqq/song/(\S+).html") # 取出每首歌的具体链接
for i in range(len(lists)):
li = lists.__getitem__(i)
a = li.find_element_by_class_name("js_song")
href = a.get_attribute("href")
music_name = a.get_attribute("title")
m = pattern.match(href)
yield m.group(1), music_name
def cut_download_url(self):
"""
筛选和查找下载的url
:return:
"""
for music_url, music_name in self.loading_music():
data = json.dumps({"req":{"module": "CDN.SrfCdnDispatchServer", "method": "GetCdnDispatch",
"param": {"guid": "3802082216", "calltype": 0, "userip": ""}
},
"req_0": {
"module": "vkey.GetVkeyServer","method":"CgiGetVkey",
"param": {
"guid": "3802082216","songmid": [f'{music_url}'],
"songtype": [0],"uin": "0","loginflag": 1,"platform":"20"
}
},"comm": {"uin":0,"format":"json","ct":24,"cv":0}})
url = "https://u.y.qq.com/cgi-bin/musicu.fcg?callback=getplaysongvkey3131073469569151&" \
"g_tk=5381&jsonpCallback=getplaysongvkey3131073469569151&loginUin=0&hostUin=0&" \
f"format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&data={data}"
response = requests.get(url=f"{url}",
headers=self.header)
html = response.text
music_json = html.split("(")[1].split(")")[0]
music_json = json.loads(music_json)
req = music_json['req']['data']
sip = req["sip"][-1]
purl = music_json['req_0']['data']['midurlinfo'][0]['purl']
url = f"{sip}{purl}"
yield url, music_name
print(music_name)#打印歌曲名
def downloading(self, url, music_name):
"""
开始下载
:param url:
:param music_name:
:return:
"""
res = requests.get(f"{url}")
chunk_size = 1024
if not os.path.exists("qq_music"):#创建名为qq_music的文件夹
os.mkdir("qq_music")
fileName = re.sub('[\/:*?"<>|]','-',music_name)#去掉非法字符,用-代替非法字符
with open("qq_music/"+fileName+".m4a", 'wb') as f:
for data in res.iter_content(chunk_size=chunk_size):
f.write(data)
def run(self):
downloads = [x for x in self.cut_download_url()]
pbar = tqdm(total=len(downloads))#用tqdm模块实现进度条显示
for num, (url, music_name) in enumerate(downloads):
self.downloading(url, music_name)
pbar.update()
QqMusic().run()
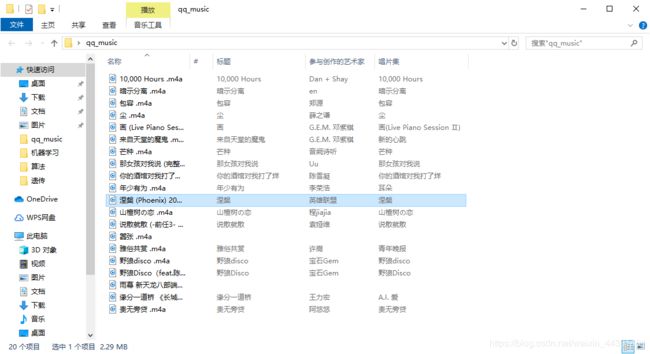
运行结果
注:本代码只用于学习交流使用
20191022时该代码可以正常使用
参考 https://y.qq.com/n/yqq/toplist/26.html