scrapy爬虫实战——爬取京东男装商品信息
一、scrapy爬虫实战项目要求——爬取京东男装商品信息
1.工具:使用scrapycrawl爬虫模板
2.内容:爬取商品名称、商家名称、评分、价格(对应每一种颜色和尺码,数量=1时的价格)、多张图片
3.提示:容易被封ip,需做好防范
二、完成爬虫项目的框架构思
1.创建爬虫项目:scrapy startproject jingdong
2.创建爬虫文件(由于京东网商品信息中网页链接较多,因此选用爬取链接更为方便的crawl爬虫模板):
scrapy genspider -t crawl jdspider "https://search.jd.com/Search?keyword=男装&enc=utf-8&suggest=1.his.0.0&wq=&pvid=c02b7f8cf5b3446aa601a21c61c5db8b"
3.修改settings配置文件:①设置ROBOTSTXT_OBEY = False,即不遵循目标网页的爬取规定,否则将无法爬取任何有用信息。
②设置下载延迟、浏览器信息头、代理ip
③开启管道(因为涉及到爬取文本信息和图片,因此要设置两个管道)
④设置图片下载路径
4.设置items文件:将需要获取的网页信息设置在items文件中
5.编写jdspider爬虫文件
6.设置pipelines管道文件:设置存储文本和图片的管道
核心思想:通过各种途径得到items文件中设置的所有内容
三、项目源代码及编程思想
1.settings
# -*- coding: utf-8 -*-
# Scrapy settings for jingdong project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'jingdong'
SPIDER_MODULES = ['jingdong.spiders']
NEWSPIDER_MODULE = 'jingdong.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'jingdong (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #不遵循目标网页规定
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3 #设置下载延时为3s,防止访问过快被网站识别为恶意程序
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
} #浏览器信息头,模拟浏览器的正常访问,可多设置几个不同浏览器的信息头并随机使用,可降低被网站拦截概率
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'jingdong.middlewares.JingdongSpiderMiddleware': 543,
#}
IMAGES_STORE = 'C:\\Users\\Administrator\\PycharmProjects\\jingdong\\jingdong\\pic'
#图片下载路径,注意此处需打两个反斜杠\\,因为\U为关键字
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'jingdong.middlewares.JingdongDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jingdong.pipelines.JingdongPipeline': 300, #文本存储管道
'jingdong.pipelines.JingdongImagePipeline': 1 #图片存储管道
}#分别设置文本和图片的管道,由于文本中需要存储图片存储路径,所以图片存储管道的优先级要高于文本管道
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
2.items
import scrapy
class JingdongItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() #商品名称
color = scrapy.Field() #商品颜色
size = scrapy.Field() #商品尺码
price = scrapy.Field() #商品价格
rate = scrapy.Field() #评分
business = scrapy.Field() #商家
image_urls = scrapy.Field() #爬取图片url
images = scrapy.Field() #本地存储图片url3.pipelines
import scrapy
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class JingdongPipeline(object):
def process_item(self, item, spider):
with open("jd2.txt","a+") as f:
f.write(item["size"]+item["color"]+" "+item["name"]+" "+item["business"]+" "+item["price"]+" "+item["rate"]+"\n")
return item
class JingdongImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for images_url in item['image_urls']:
yield scrapy.Request("http:"+images_url)
def item_completed(self, results, item, info):
images_path = [x['path'] for ok,x in results if ok]
if not images_path:
raise DropItem("item contains no images")
item['images'] = images_path
return item4.jdspider(此处为分段详解,最后会给出完整爬虫代码)
class JdspiderSpider(CrawlSpider):
name = 'jdspider'
#allowed_domains = ['https://search.jd.com']
start_urls = ['https://search.jd.com/Search?keyword=男装&enc=utf-8&wq=&pvid=6eafd16d86f9458c87ba95412966155e']
rules = (
Rule(LinkExtractor(tags=('a',), attrs=('href',),allow=r"//item\.jd\.com/\d+\.html"), callback='parse_item', follow=False),
)根据项目要求,所有需要爬取的数据均在详情页面中,所以需要在商品页面中解析出所有的商品详情页链接,在后续方法中进一步解析。
①allowed_domains = ['https://search.jd.com']
此处为京东网站的第一个爬虫障碍。由于scrapy爬取的京东商品详情页链接中没有“https:”,此域名的设置会导致无法爬取商品详情页链接。因此可以选择设置为allowed_domains = ['//search.jd.com']或者直接注释掉
②tags=('a',), attrs=('href',)
通过解析男装页面的HTML可知,所有商品详情页都在a标签的href属性中,因此如上所示设置即可。注意tags和attrs属性皆为元组,括号内最后要加上逗号“,”。
③allow=r"//item\.jd\.com/\d+\.html")
此处通过正则表达式设置解析商品详情页链接的规则。比如某男装详情页链接为//item.jd.com/43439763045.html,用正则表达式分析链接中的每一部分,即可得到所有详情链接。
④callback='parse_item'
此为回调函数,调用'parse_item'方法,将上面解析得到的详情链接传递给'parse_item'方法,从而对商品详情页进行进一步解析。
⑤follow=False
此处如果设为True,则会沿着爬取的商品详情页链接进一步深入,解析出满足条件的链接。因为我们只需要商品详情页的链接,所以不需要深入爬取,设为False即可。
def parse_item(self, response):
jd = JingdongItem()
sku_url = eval(re.findall(r"colorSize: \[\{.+]",response.text)[0].replace("colorSize: ",""))
for sku in sku_url:
skuid = sku["skuId"]
priceurl = "https://c0.3.cn/stock?skuId=%s&area=10_698_699_45967&venderId=10169893&buyNum=1&choseSuitSkuIds=&cat=1315,1342,1349&extraParam={'originid':'1'}&fqsp=0&pdpin=&pduid=1563945305409384606669&ch=1&callback=jQuery9945552"%skuid
rateurl = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds=%s&callback=jQuery1963680&_=1564219857332"%skuid
jd["color"] = sku["颜色"]
jd["name"] = response.xpath("//div[@id='spec-list']/ul/li/img/@alt").extract()[0]
jd["business"] = response.xpath("//div[@class='popbox-inner']/div/h3/a/@title").extract()[0]
jd["image_urls"] = response.xpath("//div[@id='spec-list']/ul/li/img/@src").extract()
print("+++++++价格链接++++++++++++",priceurl)
print("----------评分链接---------",rateurl)
print(jd["size"],"\n",jd["color"],"\n",jd["name"],"\n",jd["business"],"\n",jd["image_urls"],"\n")
requset = scrapy.Request(priceurl,meta={"item":jd,"rateurl":rateurl},callback=self.parse_item1)
yield requset根据项目要求,需要在详情页面中爬取商品名称、商家名称、评分、价格(对应每一种颜色和尺码,数量=1时的价格)、多张图片。其中商品名称、商家名称、图片下载路径可以在详情页面直接解析出来,但由于不同颜色和尺码的衣服所对应的价格可能不同,因此不能直接在HTML页面中直接进行解析。此处为爬虫项目的第二个障碍,需要在js文件中找到颜色、尺码和价格的对应关系。
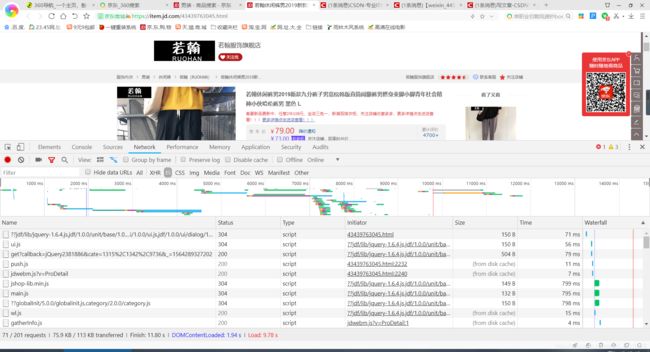
同时通过观察详情界面的代码可以发现,不光有HTML代码,同时也有js代码,其中有名为“colorsize”的列表中存在颜色、尺码和每一个产品的库存id的对应关系(如下所示)所以我们只需要在js文件中找到库存id(skuid)与价格(“p”)关系的文件链接,即可解析出每一种颜色、尺码与价格的对应关系,此处需要耐心查找。
colorSize: [{"尺码":"5xl","skuId":49093784956,"颜色":"TT55黑色"},{"尺码":"L","skuId":49093784950,"颜色":"TT55黑色"},{"尺码":"4xl","skuId":49093784955,"颜色":"TT55黑色"},{"尺码":"M","skuId":49093784951,"颜色":"TT55黑色"},{"尺码":"3XL","skuId":49093784961,"颜色":"TT55白色"},{"尺码":"2XL","skuId":49093784960,"颜色":"TT55白色"},{"尺码":"4xl","skuId":49093784962,"颜色":"TT55白色"},{"尺码":"3XL","skuId":49093784954,"颜色":"TT55黑色"},{"尺码":"XL","skuId":49093784952,"颜色":"TT55黑色"},{"尺码":"L","skuId":49093784957,"颜色":"TT55白色"},{"尺码":"2XL","skuId":49093784953,"颜色":"TT55黑色"},{"尺码":"M","skuId":49093784958,"颜色":"TT55白色"},{"尺码":"XL","skuId":49093784959,"颜色":"TT55白色"},{"尺码":"5xl","skuId":49093784963,"颜色":"TT55白色"}]同样的,评分的内容也与库存id(skuid)有关,需要从js文件中查找到有它们对应关系的文件链接,以下为根据链接编写的代码,链接可能会发生变化,仅供参考。
jd = JingdongItem()
sku_url = eval(re.findall(r"colorSize: \[\{.+]",response.text)[0].replace("colorSize: ",""))
for sku in sku_url:
skuid = sku["skuId"]
priceurl = "https://c0.3.cn/stock?skuId=%s&area=10_698_699_45967&venderId=10169893&buyNum=1&choseSuitSkuIds=&cat=1315,1342,1349&extraParam={'originid':'1'}&fqsp=0&pdpin=&pduid=1563945305409384606669&ch=1&callback=jQuery9945552"%skuid
rateurl = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds=%s&callback=jQuery1963680&_=1564219857332"%skuid先将详情页中使用正则表达式所有的sku解析出来,再将“colorsize:”替换为空,就只剩下由多个字典元素组成的列表。但此列表是字符串形式的,需要用eval转为列表形式,赋值给对象sku_url,从而进行循环取值。
"priceurl"和“rateurl”分别为价格和评价的js文件链接,将链接中库存id替换为sku_url中循环取出的skuid,即可组合成每一个商品对应的价格和评价链接。
jd["size"] = sku["尺码"]
jd["color"] = sku["颜色"]
jd["name"] = response.xpath("//div[@id='spec-list']/ul/li/img/@alt").extract()[0]
jd["business"] = response.xpath("//div[@class='popbox-inner']/div/h3/a/@title").extract()[0]
jd["image_urls"] = response.xpath("//div[@id='spec-list']/ul/li/img/@src").extract()
print("+++++++价格链接++++++++++++",priceurl)
print("----------评分链接---------",rateurl)
print(jd["size"],"\n",jd["color"],"\n",jd["name"],"\n",jd["business"],"\n",jd["image_urls"],"\n")
requset = scrapy.Request(priceurl,meta={"item":jd,"rateurl":rateurl},callback=self.parse_item1)
yield requset承接上图代码,在sku_url列表中循环解析出尺码和颜色,在详情页中解析出商品名称、商家名称和图片下载链接。
此时我们所剩余的任务有:在价格链接和评价链接中解析出价格和评价,通过图片下载链接下载图片到工程中。
由于需要解析两个链接,所以将解析完成的内容打包,与评价链接一起以键值对的形式暂存在requset的meta属性中,回调parse_item1函数解析价格链接。
def parse_item1(self,response):
jd = response.meta["item"]
rateurl = response.meta["rateurl"]
jd["price"] = re.findall(r'"p":"\d+',response.text)[0].split(":")[1]
request = scrapy.Request(rateurl,meta={"item":jd},callback=self.parse_item2)
return request此为解析价格链接的方法。先取出之前暂存的内容,再通过正则表达式解析出价格链接中的价格,最后将解析好的价格同上一个方法中解析好的内容共同暂存,调用最后一个方法parse_item2解析评价链接,思路同上。
def parse_item2(self,response):
data = json.loads(response.text)
jd = response.meta["item"]
jd["rate"] = data["goodRateShow"]
yield jd以上就是爬虫文件编写的全部思想,下面给出爬虫文件的完整代码以供参考。
# -*- coding: utf-8 -*-
import re
import json
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from jingdong.items import JingdongItem
class JdspiderSpider(CrawlSpider):
name = 'jdspider'
start_urls = ['https://search.jd.com/Search?keyword=男装&enc=utf-8&wq=&pvid=6eafd16d86f9458c87ba95412966155e']
rules = (
Rule(LinkExtractor(tags=('a',), attrs=('href',),allow=r"//item\.jd\.com/\d+\.html"), callback='parse_item', follow=False),
)
def parse_item(self, response):
jd = JingdongItem()
sku_url = eval(re.findall(r"colorSize: \[\{.+]",response.text)[0].replace("colorSize: ",""))
for sku in sku_url:
skuid = sku["skuId"]
priceurl = "https://c0.3.cn/stock?skuId=%s&area=10_698_699_45967&venderId=10169893&buyNum=1&choseSuitSkuIds=&cat=1315,1342,1349&extraParam={'originid':'1'}&fqsp=0&pdpin=&pduid=1563945305409384606669&ch=1&callback=jQuery9945552"%skuid
rateurl = "https://club.jd.com/comment/productCommentSummaries.action?referenceIds=%s&callback=jQuery1963680&_=1564219857332"%skuid
jd["size"] = sku["尺码"]
jd["color"] = sku["颜色"]
jd["name"] = response.xpath("//div[@id='spec-list']/ul/li/img/@alt").extract()[0]
jd["business"] = response.xpath("//div[@class='popbox-inner']/div/h3/a/@title").extract()[0]
jd["image_urls"] = response.xpath("//div[@id='spec-list']/ul/li/img/@src").extract()
print("+++++++价格链接++++++++++++",priceurl)
print("----------评分链接---------",rateurl)
print(jd["size"],"\n",jd["color"],"\n",jd["name"],"\n",jd["business"],"\n",jd["image_urls"],"\n")
requset = scrapy.Request(priceurl,meta={"item":jd,"rateurl":rateurl},callback=self.parse_item1)
yield requset
def parse_item1(self,response):
jd = response.meta["item"]
rateurl = response.meta["rateurl"]
jd["price"] = re.findall(r'"p":"\d+',response.text)[0].split(":")[1]
request = scrapy.Request(rateurl,meta={"item":jd},callback=self.parse_item2)
return request
def parse_item2(self,response):
data = json.loads(response.text)
jd = response.meta["item"]
jd["rate"] = data["goodRateShow"]
yield jd