深度学习系列(十) 计算机视觉之目标检测(object detection)2020.6.29
前言
本节学习目标检测
图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置
- 边界框
- 锚框
- 多尺度
- SSD
1、边界框
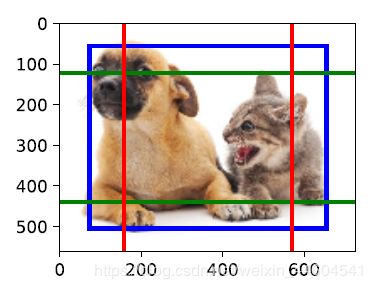
通常使⽤边界框(bounding box)来描述⽬标位置
可以由矩形左上⻆的x和y轴坐标与右下⻆的x和y轴坐标确定
举个例子
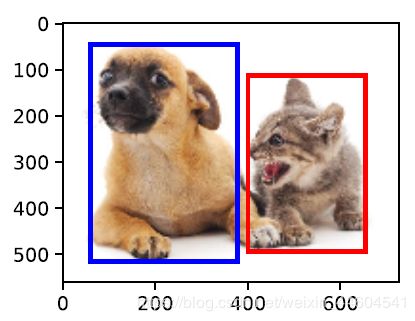
2、锚框
⽬标检测算法通常会在输⼊图像中采样⼤量的区域,然后判断这些区域中是否包含我们感兴趣的
⽬标,并调整区域边缘从而更准确地预测⽬标的真实边界框(ground-truth bounding box)
锚框
- 以每个像素为中心生成多个⼤小和宽⾼⽐(aspect ratio)不同的边界框
- 用Jaccard系数(Jaccard index)衡量锚框和真实边界框的相似度
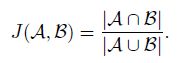
import d2lzh as d2l
from mxnet import contrib, gluon, image, nd
import numpy as np
"""实现锚框"""
np.set_printoptions(2)
# 数据
img = image.imread('../img/catdog.jpg').asnumpy()
h, w = img.shape[0:2]
X = nd.random.uniform(shape=(1, 3, h, w)) # 构造输入数据
Y = contrib.nd.MultiBoxPrior(X, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5]) #锚框:输⼊、⼀组⼤小和⼀组宽⾼⽐
print(Y.shape) #(批量大小,锚框个数,4)
# 绘图
def show_bboxes(axes, bboxes, labels=None, colors=None):
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxes):
color = colors[i % len(colors)]
rect = d2l.bbox_to_rect(bbox.asnumpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
text_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i],
va='center', ha='center', fontsize=9, color=text_color,
bbox=dict(facecolor=color, lw=0))
# 画出图像中以(250,250)为中⼼的所有锚框
d2l.set_figsize()
bbox_scale = nd.array((w, h, w, h))
fig = d2l.plt.imshow(img)
show_bboxes(fig.axes, boxes[250, 250, :, :] * bbox_scale,
['s=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2',
's=0.75, r=0.5'])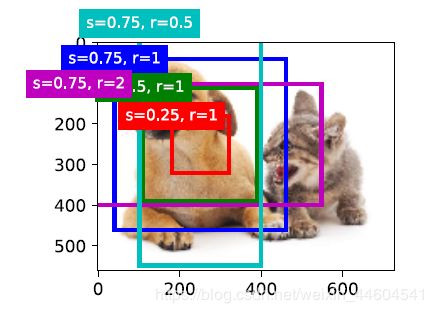
3、多尺度目标检测
- 在输⼊图像中均匀采样⼀小部分像素,并以采样的像素为中⼼⽣成锚框
- 在不同尺度下,可以⽣成不同数量和不同⼤小的锚框
import d2lzh as d2l
from mxnet import contrib, image, nd
"""实现多尺度目标检测"""
# 数据
img = image.imread('../img/catdog.jpg')
h, w = img.shape[0:2]
d2l.set_figsize()
# 多尺度
def display_anchors(fmap_w, fmap_h, s):
fmap = nd.zeros((1, 10, fmap_w, fmap_h)) # 前两维的取值不影响输出结果
anchors = contrib.nd.MultiBoxPrior(fmap, sizes=s, ratios=[1, 2, 0.5])
bbox_scale = nd.array((w, h, w, h))
d2l.show_bboxes(d2l.plt.imshow(img.asnumpy()).axes,
anchors[0] * bbox_scale)
display_anchors(fmap_w=4, fmap_h=4, s=[0.15]) #小目标
display_anchors(fmap_w=1, fmap_h=1, s=[0.8]) #放大小目标
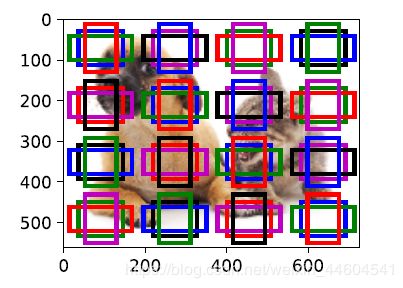
放大
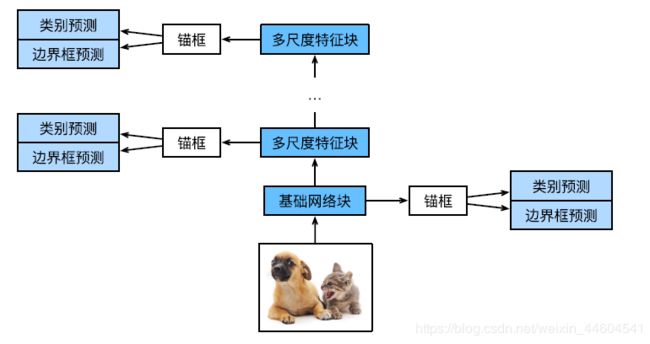
4、单发多框检测(SSD)
- 由⼀个基础⽹络块和若⼲个多尺度特征块串联而成
- 基础⽹络块⽤来从原始图像中抽取特征,因此⼀般会选择常⽤的深度卷积神经⽹络
- 每个多尺度特征块将上⼀层提供的特征图的⾼和宽缩小(如减半),并使特征图中每个单元在输⼊图像上的感受野变得更⼴阔
一个实现
import d2lzh as d2l
from mxnet import autograd, contrib, gluon, image, init, nd
from mxnet.gluon import loss as gloss, nn
import time
"""实现SSD"""
# 类别预测层
def cls_predictor(num_anchors, num_classes):
return nn.Conv2D(num_anchors * (num_classes + 1), kernel_size=3, padding=1)
# 边界框预测层
def bbox_predictor(num_anchors):
return nn.Conv2D(num_anchors * 4, kernel_size=3, padding=1)
# 连结多尺度的预测
def forward(x, block):
block.initialize()
return block(x)
def flatten_pred(pred):
return pred.transpose((0, 2, 3, 1)).flatten()
def concat_preds(preds):
return nd.concat(*[flatten_pred(p) for p in preds], dim=1)
# 高和宽减半块
def down_sample_blk(num_channels):
blk = nn.Sequential()
for _ in range(2):
blk.add(nn.Conv2D(num_channels, kernel_size=3, padding=1),
nn.BatchNorm(in_channels=num_channels),
nn.Activation('relu'))
blk.add(nn.MaxPool2D(2))
return blk
# 基础网络块
def base_net():
blk = nn.Sequential()
for num_filters in [16, 32, 64]:
blk.add(down_sample_blk(num_filters))
return blk
# 完整模型
def get_blk(i):
if i == 0:
blk = base_net()
elif i == 4:
blk = nn.GlobalMaxPool2D()
else:
blk = down_sample_blk(128)
return blk
# 每个模块的前向计算
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):
Y = blk(X)
anchors = contrib.ndarray.MultiBoxPrior(Y, sizes=size, ratios=ratio)
cls_preds = cls_predictor(Y)
bbox_preds = bbox_predictor(Y)
return (Y, anchors, cls_preds, bbox_preds)
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79],
[0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors = len(sizes[0]) + len(ratios[0]) - 1
# TinySSD
class TinySSD(nn.Block):
def __init__(self, num_classes, **kwargs):
super(TinySSD, self).__init__(**kwargs)
self.num_classes = num_classes
for i in range(5):
# 即赋值语句self.blk_i = get_blk(i)
setattr(self, 'blk_%d' % i, get_blk(i))
setattr(self, 'cls_%d' % i, cls_predictor(num_anchors, num_classes))
setattr(self, 'bbox_%d' % i, bbox_predictor(num_anchors))
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
# getattr(self, 'blk_%d' % i)即访问self.blk_i
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, 'blk_%d' % i), sizes[i], ratios[i],
getattr(self, 'cls_%d' % i), getattr(self, 'bbox_%d' % i))
# reshape函数中的0表示保持批量大小不变
return (nd.concat(*anchors, dim=1),
concat_preds(cls_preds).reshape(
(0, -1, self.num_classes + 1)), concat_preds(bbox_preds))
"""训练"""
# 数据
batch_size = 32
train_iter, _ = d2l.load_data_pikachu(batch_size)
# 初始化
ctx, net = d2l.try_gpu(), TinySSD(num_classes=1)
net.initialize(init=init.Xavier(), ctx=ctx)
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': 0.2, 'wd': 5e-4})
# 损失函数
cls_loss = gloss.SoftmaxCrossEntropyLoss()
bbox_loss = gloss.L1Loss() #掩码变量
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
cls = cls_loss(cls_preds, cls_labels)
bbox = bbox_loss(bbox_preds * bbox_masks, bbox_labels * bbox_masks)
return cls + bbox
# 准确率和平均绝对误差
def cls_eval(cls_preds, cls_labels):
# 由于类别预测结果放在最后一维,argmax需要指定最后一维
return (cls_preds.argmax(axis=-1) == cls_labels).sum().asscalar()
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return ((bbox_labels - bbox_preds) * bbox_masks).abs().sum().asscalar()
# 训练
for epoch in range(20):
acc_sum, mae_sum, n, m = 0.0, 0.0, 0, 0
train_iter.reset() # 从头读取数据
start = time.time()
for batch in train_iter:
X = batch.data[0].as_in_context(ctx)
Y = batch.label[0].as_in_context(ctx)
with autograd.record():
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors, cls_preds, bbox_preds = net(X)
# 为每个锚框标注类别和偏移量
bbox_labels, bbox_masks, cls_labels = contrib.nd.MultiBoxTarget(anchors, Y, cls_preds.transpose((0, 2, 1)))
# 根据类别和偏移量的预测和标注值计算损失函数
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks)
l.backward()
trainer.step(batch_size)
acc_sum += cls_eval(cls_preds, cls_labels)
n += cls_labels.size
mae_sum += bbox_eval(bbox_preds, bbox_labels, bbox_masks)
m += bbox_labels.size
if (epoch + 1) % 5 == 0:
print('epoch %2d, class err %.2e, bbox mae %.2e, time %.1f sec' % (
epoch + 1, 1 - acc_sum / n, mae_sum / m, time.time() - start))
# 预测
img = image.imread('../img/pikachu.jpg')
feature = image.imresize(img, 256, 256).astype('float32')
X = feature.transpose((2, 0, 1)).expand_dims(axis=0)
def predict(X):
anchors, cls_preds, bbox_preds = net(X.as_in_context(ctx))
cls_probs = cls_preds.softmax().transpose((0, 2, 1))
output = contrib.nd.MultiBoxDetection(cls_probs, bbox_preds, anchors)
idx = [i for i, row in enumerate(output[0]) if row[0].asscalar() != -1]
return output[0, idx]
output = predict(X)
# 置信度不低于0.3的边界框筛选为最终输出
d2l.set_figsize((5, 5))
def display(img, output, threshold):
fig = d2l.plt.imshow(img.asnumpy())
for row in output:
score = row[1].asscalar()
if score < threshold:
continue
h, w = img.shape[0:2]
bbox = [row[2:6] * nd.array((w, h, w, h), ctx=row.context)]
d2l.show_bboxes(fig.axes, bbox, '%.2f' % score, 'w')
display(img, output, threshold=0.3)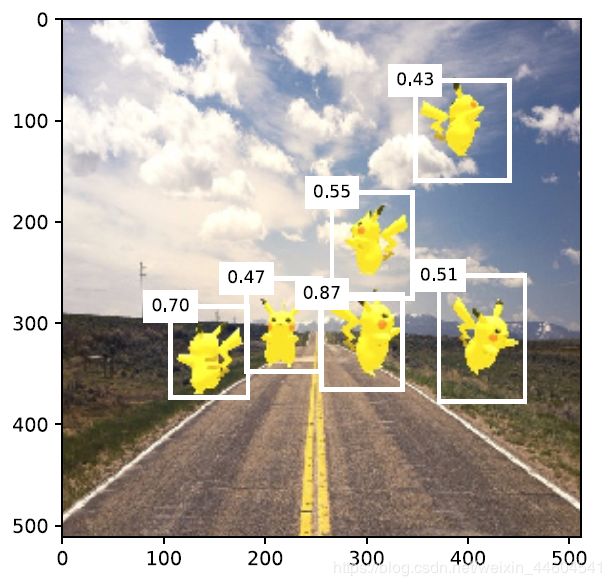
结语
大概了解了目标检测的原理
尝试了SSD的实现
里面还有好些细节没有搞明白
留待后面回头再看