(十六)从零开始学人工智能-深度学习基础3
文章目录
- 一、生成对抗网络基础
- 1.1 G A N GAN GAN概述
- 1.2 什么是生成对抗网络?
- 1.2.1 对抗生成网络背后的数学原理
- 1.2.2 重说GAN原理
- 1.2.3 小结
- 1.3 GANs应用举例
- 1.3.1 从生成MNIST开始
- 1.3.2 垃圾邮件识别
- 1.3.3 更多实际应用
- 1.3.4 小结
- 声明
- 参考文献
一、生成对抗网络基础
生成对抗网络(Generative Adversarial Networks, GANs)是由Ian Goodfellow等人在2014年的Generative Adversarial Networks一文中提出。Facebook的人工智能主管Yann Lecun对其的评价是:“机器学习在过去10年中最有趣的想法”。GANs的潜力巨大,因为它们可以学习模仿任何数据分布。 也就是说,GANs经过学习后,可以创造出类似于我们真实世界的一些东西,比如:图像、音乐、散文等等。从某种意义来说,它们是“机器人艺术家”,有些确实能够让人印象深刻。

基于GAN,可以将人脸粘贴到视频中的目标人物上
1.1 G A N GAN GAN概述
在讲 G A N GAN GAN之前,先讲一个小趣事,你知道 G A N GAN GAN是怎么被发明的吗?据 I a n Ian Ian G o o d f e l l o w Goodfellow Goodfellow自己说: 之前他一直在研究生成模型,可能是一时兴起,有一天他在酒吧喝酒时,在酒吧里跟朋友讨论起生成模型。然后 I a n Ian Ian G o o d f e l l o w Goodfellow Goodfellow想到 G A N GAN GAN的思想,跟朋友说你应该这么做这么做这么做,我打赌一定会有用。但是朋友不信,于是他直接从酒吧回去开始做实验,一晚上就写出了 G A N GAN GAN论文~
这个故事告诉我们,喝酒,不仅能打醉拳,也能写出顶级论文…
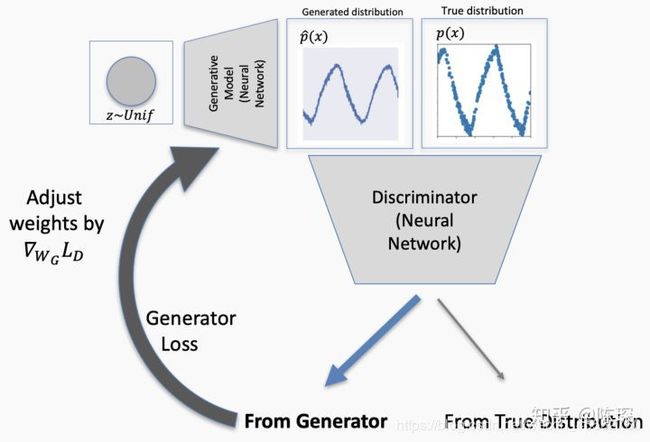
故事讲完,开干( G A N GAN GAN)吧: G A N GAN GAN包含有两个模型,一个是生成模型( g e n e r a t i v e generative generative m o d e l model model),一个是判别模型( d i s c r i m i n a t i v e discriminative discriminative m o d e l model model)。生成模型的任务是生成看起来自然真实的、和原始数据相似的数据。判别模型的任务是判断给定的实例看起来是自然真实的还是认为伪造的(真实实例来源于数据集,伪造实例来源于生成模型)。

这可以看做一种零和游戏。论文采用类比的手法通俗理解:生成模型像“一个造假团伙,试图生产和使用假币”,而判别模型像“检测假币的警察”。生成器( g e n e r a t o r generator generator)试图欺骗判别器( d i s c r i m i n a t o r discriminator discriminator),判别器则努力不被生成器欺骗。模型经过交替优化训练,两种模型都能得到提升,但最终我们要得到的是效果提升到很高很好的生成模型(造假团伙),这个生成模型(造假团伙)所生成的产品能达到真假难分的地步,这个过程就如上图的对抗过程。
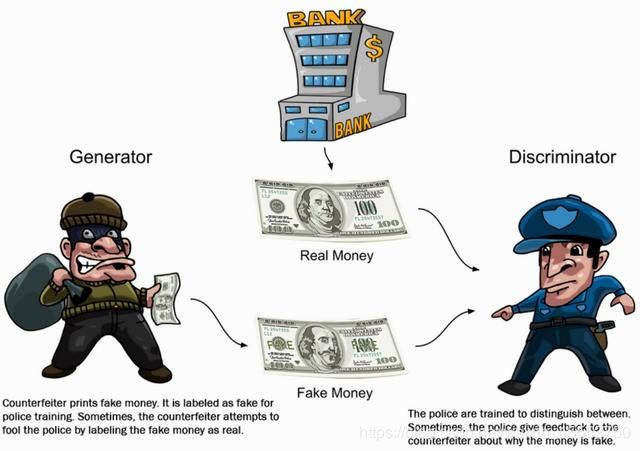
随着学术界和工业界都开始接收并欢迎 G A N GAN GAN的到来, G A N GAN GAN的崛起不可避免:
-
首先, G A N GAN GAN最厉害的地方是它的学习性质是无监督的。 G A N GAN GAN也不需要标记数据,这使 G A N GAN GAN功能强大,因为数据标记的工作非常枯燥。
-
其次, G A N GAN GAN的潜在用例使它成为交谈的中心。它可以生成高质量的图像,图片增强,从文本生成图像,将图像从一个域转换为另一个域,随年龄增长改变脸部外观等等。这个名单较长并还在快速增长。
-
第三,围绕 G A N GAN GAN不断的研究是如此令人着迷,以至于它吸引了其他(图像之外)所有行业的注意力。
1.2 什么是生成对抗网络?
要全面理解生成对抗网络,首先要理解的概念是监督式学习和非监督式学习。监督式学习是指基于大量带有标签的训练集与测试集的机器学习过程,比如监督式图片分类器需要一系列图片和对应的标签(“猫”,“狗”,…),而非监督式学习则不需要这么多额外的工作,它们可以自己从错误中进行学习,并降低未来出错的概率。监督式学习的缺点就是需要大量标签样本,这非常耗时耗力。非监督式学习虽然没有这个问题,但准确率往往更低。自然而然地希望能够通过提升非监督式学习的性能,从而减少对监督式学习的依赖。 G A N GAN GAN可以说是对于非监督式学习的一种提升。
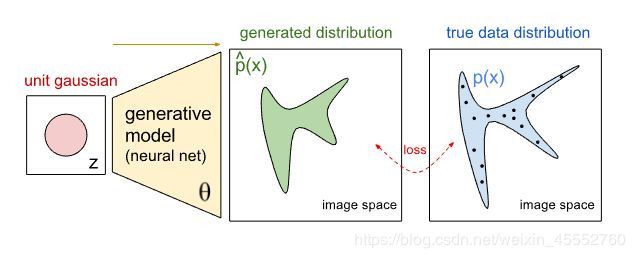
第二个需要理解的概念是“生成模型”, 如下图所示生成图片模型的概念示意图。这类模型能够通过输入的样本产生可能的输出。举个例子,一个生成模型可以通过视频的某一帧预测出下一帧的输出。另一个例子是搜索引擎,在你输入的同时,搜索引擎已经在推断你可能搜索的内容了。
基于上面的两个概念就可以设计生成对抗网络 G A N GAN GAN了。相比于传统的神经网络模型, G A N GAN GAN是一种全新的非监督式的架构(如下图所示)。 G A N GAN GAN包括了两套独立的网络,两者之间作为互相对抗的目标。第一套网络是我们需要训练的分类器(下图中的D),用来分辨是否是真实数据还是虚假数据;第二套网络是生成器(下图中的G),生成类似于真实样本的随机样本,并将其作为假样本。
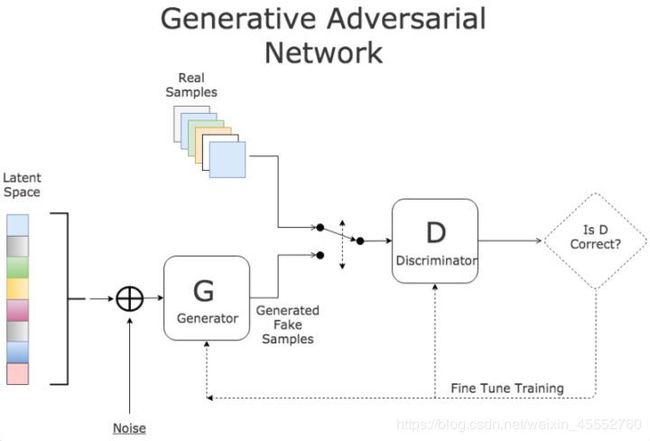
D作为一个图片分类器,对于一系列图片区分不同的动物。生成器G的目标是绘制出非常接近的伪造图片来欺骗D,做法是选取训练数据潜在空间中的元素进行组合,并加入随机噪音,例如在这里可以选取一个猫的图片,然后给猫加上第三只眼睛,以此作为假数据。
在训练过程中,D会接收真数据和G产生的假数据,它的任务是判断图片是属于真数据的还是假数据的。对于最后输出的结果,可以同时对两方的参数进行调优。如果D判断正确,那就需要调整G的参数从而使得生成的假数据更为逼真;如果D判断错误,则需调节D的参数,避免下次类似判断出错。训练会一直持续到两者进入到一个均衡和谐的状态。
训练后的产物是一个质量较高的自动生成器和一个判断能力较强强的分类器。前者可以用于机器创作(自动画出“猫”“狗”),而后者则可以用来机器分类(自动判断“猫”“狗”)。
小结: G A N GAN GAN算法流程简述
算法流程简述
- 初始化generator和discriminator。
- 每一次的迭代过程中:
- 固定generator, 只更新discriminator的参数。从你准备的数据集中随机选择一些,再从generator的output中选择一些,现在等于discriminator有两种input。接下来, discriminator的学习目标是, 如果输入是来自于真实数据集,则给高分;如果是generator产生的数据,则给低分,可以把它当做一个回归问题。
- 接下来,固定住discriminator的参数, 更新generator。将一个向量输入generator, 得到一个output, 将output扔进discriminator, 然后会得到一个分数,这一阶段discriminator的参数已经固定住了,generator需要调整自己的参数使得这个output的分数越大越好。
按这个过程听起来好像有两个网络,而实际过程中,generator和discriminator是同一个网络,只不过网络中间的某一层hidden-layer的输出是一个图片(或者语音,取决于你的数据集)。在训练的时候也是固定一部分hidden-layer,调其余的hidden-layer。
1.2.1 对抗生成网络背后的数学原理
以下这一段真的是太枯燥了,纯属为了内容完整性,不喜跳过… 一点不影响全文理解,哈哈哈~
------------------------------------------------------------高能开始分割线------------------------------------------------------------------------------
考虑一下,GAN到底生成的是什么呢?比如说,假如我们想要生成一些人脸图,实际上,我们是想找到一个分布,从这个分部内sample出来的图片,像是人脸,而不属于这个distribution的分布,生成的就不是人脸。而GAN要做的就是找到这个distribution。
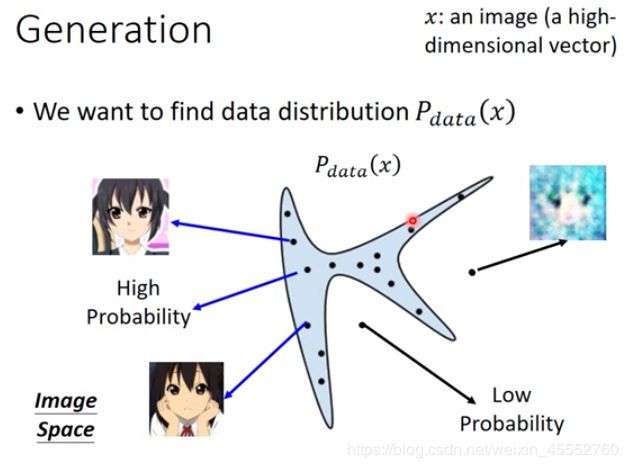
在GAN出生之前,我们怎么做这个事情呢?
之前用的是Maximum Likelihood Estimation,最大似然估计来做生成的,我们先从概率分布及参数估计说起,通过介绍极大似然估计、KL散度、JS散度,再详细介绍GAN生成对抗网络的数学原理。
无论是黑白图片或彩色图片, 都是使用 0 ~ 255 的数值表示像素. 将所有的像素值除以 255 我们就可以将一张图片转化为 0 ~ 1 的概率分布, 而且这种转化是可逆的, 乘以 255 就可以还原.
从某种意义上来讲, GAN 图片生成任务就是生成概率分布. 因此, 我们有必要结合概率分布来理解 GAN 生成对抗网络的原理.
回顾概率分布及参数估计
先来看一个例子:
假设一个抽奖盒子里有45个球,其编号是1-9共9个数字。每个编号的球拥有的数量是:
| 编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 数量 | 2 | 4 | 6 | 8 | 9 | 7 | 5 | 3 | 1 |
| 占比 | 0.044 | 0.088 | 0.133 | 0.178 | 0.200 | 0.156 | 0.111 | 0.066 | 0.022 |
占比是指用每个编号的数量除以所有编号的数量总和,在数理统计中,在不引起误会的情况下,这里的占比也可以被称为概率/频率。
使用向量 q q q表示上述的概率分布:
q = ( 1 , 4 , 6 , 8 , 9 , 7 , 5 , 3 , 1 ) / 45 = ( 0.044 , 0.088 , 0.133 , 0.178 , 0.200 , 0.156 , 0.111 , 0.066 , 0.022 ) \begin{aligned}q &=(1,4,6,8,9,7,5,3,1)/45 \\&=(0.044,0.088,0.133,0.178,0.200,0.156,0.111,0.066,0.022) \end{aligned} q=(1,4,6,8,9,7,5,3,1)/45=(0.044,0.088,0.133,0.178,0.200,0.156,0.111,0.066,0.022)
将上述分布使用图像绘制如下:

现在我们希望构建一个函数 p = p ( x ; θ ) p=p(x;\theta) p=p(x;θ),以 x x x为编号作为输入数据,输出编号 x x x的概率。 θ \theta θ是参与构建这个函数的参数,一经选定就不再变化。
假设上述概率分布服从二次抛物线函数:
p = p ( x ; θ ) = θ 1 ( x + θ 2 ) 2 + θ 3 \begin{aligned}p &=p(x;\theta) \\ &=\theta_1(x+\theta_2)^2+\theta_3 \\ \end{aligned} p=p(x;θ)=θ1(x+θ2)2+θ3
x = ( 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ) x=(1,2,3,4,5,6,7,8,9) x=(1,2,3,4,5,6,7,8,9)
使用 L 2 L_2 L2误差作为评价拟合效果的损失函数,总误差值为 e r r o r ( 标 量 e ) error(标量e) error(标量e):
e = Σ i = 1 9 ( p i − q i ) 2 e=\Sigma_{i=1}^9(p_i-q_i)^2 e=Σi=19(pi−qi)2
我们希望求得一个 θ ∗ \theta^* θ∗,使得 e e e的值越小越好,数学上表达为:
θ ∗ = a r g m i n θ ( e ) \theta^*=\mathop {argmin}_{\theta}(e) θ∗=argminθ(e)
argmin是argument minimum的缩写。
如何求 θ ∗ \theta^* θ∗不是本文的重点,这是生成对抗网络的任务。为了帮助理解,取其中一个可能的数值作为示例:
θ ∗ = ( θ 1 , θ 2 , θ 3 ) = ( − 0.01 , − 5.0 , 0.2 ) \theta^*=(\theta_1,\theta_2,\theta_3)=(-0.01,-5.0,0.2) θ∗=(θ1,θ2,θ3)=(−0.01,−5.0,0.2)
p = p ( x ; θ ) = − 0.01 ( x − 5.0 ) 2 + 0.2 p=p(x;\theta)=-0.01(x-5.0)^2+0.2 p=p(x;θ)=−0.01(x−5.0)2+0.2
绘制函数图像如下:
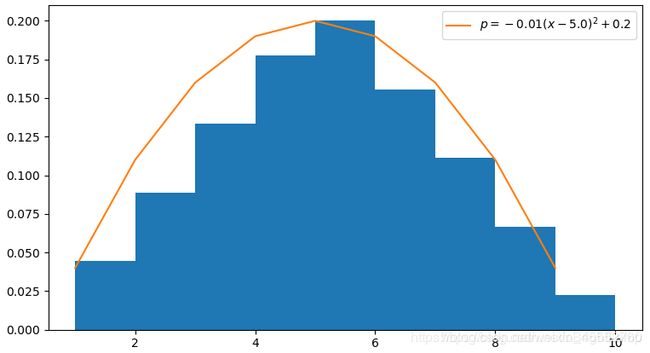
在生成对抗网络中,本例的估计函数 p ( x : θ ) p(x:\theta) p(x:θ)相当于生成模型(generator),损失函数相当于鉴别模型(discriminator)。
从最大似然估计讲起
最大似然估计的理念是:假如说我们的数据集分布是 P d a t a ( x ) P_{data}(x) Pdata(x),我们定义一个分布 P G ( x ; θ ) P_G(x;\theta) PG(x;θ),我们想要找到一组参数 θ \theta θ,使得 P G ( x ; θ ) P_G(x;\theta) PG(x;θ)越接近 P d a t a ( x ) 越 好 P_{data}(x)越好 Pdata(x)越好。例如,若 P G ( x ; θ ) P_G(x;\theta) PG(x;θ)是一个高斯混合模型,那么 θ \theta θ就是均值和方差。
具体怎么操作呢
- 从 P d a t a ( x ) P_{data}(x) Pdata(x)中采样出 x 1 , x 2 , x 3 , … , x m {x^1,x^2,x^3,\dots,x^m} x1,x2,x3,…,xm;
- 对每一个采样出来的 x x x,我们都可以计算出它的似然函数,也就是可以得到一组参数 θ \theta θ,进而就能知道 P G ( x ; θ ) P_G(x;\theta) PG(x;θ)长什么样,然后就可以进一步计算出这个分布里面采样出的某一个 x x x的几率;
- 把在某个分布可以产生 x i x_i xi的参数似然函数乘起来,可以得到总的似然函数:
L = ∏ i = 1 m P G ( x i ; θ ) L=\prod_{i=1}^mP_G(x^i;\theta) L=∏i=1mPG(xi;θ)
我们要找到一组 θ ∗ \theta^* θ∗,可以最大化 L L L。
在上面的例子中,我们很幸运的知道了所有可能的概率分布,并让求解最优化的概率分布估计函数 p ( x ; θ ) p(x;\theta) p(x;θ)成为可能。
如果上例的抽奖盒子(样本)中的45个球是从更大的抽奖池(总体)中选出来的,而我们不知道抽奖池中所有球的数量及其编号。那么,我们如何根据现有的45个球来估计抽奖池的概率分布呢?当然,我们可以直接用上例求得的样本估计函数来代表抽奖池的概率分布,但接下来会介绍一种更为常用的估计方法,即本节开篇提到的最大似然估计。
假设 p ( x ) = p ( x ; θ ) p(x)=p(x;\theta) p(x)=p(x;θ)是总体的概率分布函数,则编号 x = ( x 1 , x 2 , x 3 , ⋯ , x n ) x=(x_1,x_2,x_3,\cdots,x_n) x=(x1,x2,x3,⋯,xn)出现的概率为:
p = p ( x 1 ) , p ( x 2 ) , p ( x 3 ) , ⋯ , p ( x n ) p=p(x_1),p(x_2),p(x_3),\cdots,p(x_n) p=p(x1),p(x2),p(x3),⋯,p(xn)
在本例中, n = 9 n=9 n=9,即共9个编号。
设 d = ( d 1 , d 2 , d 3 , ⋯ , d m ) d=(d_1,d_2,d_3,\cdots,d_m) d=(d1,d2,d3,⋯,dm)是所有抽样的编号,在本例中, m = 45 m=45 m=45,即样本中共有45个抽样。假设所有的样本和抽样都是独立的,则样本出现的概率为:
ρ = p ( d 1 ) × p ( d 2 ) × p ( d 3 ) × ⋯ × p ( d m ) = ∏ i = 1 m ( p ( d i ) ) \rho=p(d_1)\times p(d_2)\times p(d_3)\times \cdots \times p(d_m)=\prod_{i=1}^m(p(d_i)) ρ=p(d1)×p(d2)×p(d3)×⋯×p(dm)=∏i=1m(p(di))
p ( x ) = p ( x ; θ ) p(x)=p(x;\theta) p(x)=p(x;θ)的函数结构是人为按经验选取的,比如线性函数,多元二次函数,更复杂的非线性函数等,一经选取则不再改变。现在我们需要求解一个参数集 θ ∗ \theta^* θ∗,使得 ρ \rho ρ的值越大越好。即
θ ∗ = a r g m a x θ ( ρ ) = a r g m a x θ ∏ i = 1 m p ( d i ; θ ) \theta^*=\mathop {argmax}_\theta(\rho)=\mathop {argmax}_\theta\prod_{i=1}^mp(d_i;\theta) θ∗=argmaxθ(ρ)=argmaxθ∏i=1mp(di;θ)
argmax是argument maximum的缩写。
通俗来讲,因为样本是实际已发生的事实,在函数结构已确定的情况下,我们需要尽量优化参数,使得样本的理论估计概率越大越好。
这里有一个前提,就是认为选定的函数结构应当能够有效评估样本分布。反之,如果使用线性函数去拟合正态概率分布(normal distribution),则无论如何选择参数都无法得到满意的效果。
连乘运算不方便,将之改为求和运算。由于 l o g log log对数函数的单调性,上面的式子等价于:
θ ∗ = a r g m a x θ l o g ∏ i = 1 m p ( d i ; θ ) = a r g m a x θ Σ i = 1 m l o g p ( d i ; θ ) \theta^*=\mathop {argmax}_\theta log\prod_{i=1}^mp(d_i;\theta)=\mathop {argmax}_\theta\Sigma_{i=1}^mlog \, p(d_i;\theta) θ∗=argmaxθlog∏i=1mp(di;θ)=argmaxθΣi=1mlogp(di;θ)
设样本分布为 q ( x ) q(x) q(x),对于给定样本,这个分布是已知的,可以通过统计抽样的计算得出,将上式转化成期望公式:
θ ∗ = a r g m a x θ Σ i = 1 m l o g p ( d i ; θ ) = a r g m a x θ Σ i = 1 n q ( x i ) l o g p ( x i ; θ ) \theta^*=\mathop {argmax}_\theta\Sigma_{i=1}^mlog\,p(d_i;\theta)=\mathop {argmax}_\theta\Sigma_{i=1}^n q(x_i)log\,p(x_i;\theta) θ∗=argmaxθΣi=1mlogp(di;θ)=argmaxθΣi=1nq(xi)logp(xi;θ)
注意上式中的两个求和符号, m m m变成了 n n n。在大多数情况下,编号数量会比抽样数量少,转为期望公式可以显著减少计算量。
在一些教程中,上式写法为:
θ ∗ = a r g m a x θ E x − q ( x ) l o g p ( x ; θ ) = a r g m a x θ ∫ q ( x ) l o g p ( x ; θ ) d x \theta^*=\mathop {argmax}_\theta E_{x-q(x)}log\,p(x;\theta)=\mathop {argmax}_\theta \int q(x)log\,p(x;\theta)dx θ∗=argmaxθEx−q(x)logp(x;θ)=argmaxθ∫q(x)logp(x;θ)dx
E x − q ( x ) E_{x-q(x)} Ex−q(x)表示按 q ( x ) q(x) q(x)的分布对 x x x求期望。因为积分表达式比较简洁,书写方便,下文开始将主要使用积分表达式。
以上就是最大似然估计(Maximum Likelihood Estimation)的理论和推导过程。和上例的参数估计方法相比,最大似然估计因为无需设计损失函数,降低了模型的复杂度,扩大了适用范围。
本例中的估计函数 p ( x ; θ ) p(x;\theta) p(x;θ)相当于生成对抗网络的生成模型,样本分布 q ( x ) q(x) q(x)相当于训练数据。
另一种解释-KL散度
结合上例,在样本已知的情况下, q ( x ) q(x) q(x)是一个已知且确定的分布。则 ∫ q ( x ) l o g q ( x ) d x \int q(x)log\,q(x)dx ∫q(x)logq(x)dx是一个常数项,不影响 θ ∗ \theta^* θ∗求解的结果,则可添加项
θ ∗ = a r g m a x θ ( ∫ q ( x ) l o g p ( x ; θ ) d x − ∫ q ( x ) l o g q ( x ) d x ) = a r g m a x θ ∫ q ( x ) ( l o g p ( x ; θ ) − l o g q ( x ) ) d x = a r g m a x θ ∫ q ( x ) l o g p ( x ; θ ) q ( x ) d x \begin{aligned}\theta^* &=\mathop {argmax}_\theta(\int q(x)log\,p(x;\theta)dx-\int q(x)log\,q(x)dx) \\ &=\mathop {argmax}_\theta \int q(x)(log\,p(x;\theta)-log\,q(x))dx \\ &=\mathop {argmax}_\theta \int q(x)log\frac{p(x;\theta)}{q(x)}dx \end{aligned} θ∗=argmaxθ(∫q(x)logp(x;θ)dx−∫q(x)logq(x)dx)=argmaxθ∫q(x)(logp(x;θ)−logq(x))dx=argmaxθ∫q(x)logq(x)p(x;θ)dx
也可以写成这样:
θ ∗ = a r g m i n θ ( − ∫ q ( x ) l o g p ( x ; θ ) d x + ∫ q ( x ) l o g q ( x ) d x ) = a r g m i n θ ∫ q ( x ) l o g q ( x ) p ( x ; θ ) d x \begin{aligned}\theta^* &=\mathop {argmin}_\theta(-\int q(x)log\,p(x;\theta)dx+\int q(x)log\,q(x)dx) \\ &=\mathop {argmin}_\theta \int q(x)log\frac{q(x)}{p(x;\theta)}dx \end{aligned} θ∗=argminθ(−∫q(x)logp(x;θ)dx+∫q(x)logq(x)dx)=argminθ∫q(x)logp(x;θ)q(x)dx
K L KL KL散度(Kullback-Leibler divergence)是一种衡量两个概率分布的匹配程度的指标,两个分布差异越大,KL散度越大。它还有很多的名字,比如:relative entropy, relative information。
其定义如下:
D K L ( q ∣ ∣ p ) = ∫ q ( x ) l o g q ( x ) p ( x ) d x D_{KL}(q\mid\mid p)=\int q(x)log\frac{q(x)}{p(x)}dx DKL(q∣∣p)=∫q(x)logp(x)q(x)dx
当 p ( x ) = q ( x ) p(x)=q(x) p(x)=q(x)时,取最小值 D K L ( q ∣ ∣ p ) = 0 D_{KL}(q\mid\mid p)=0 DKL(q∣∣p)=0。
我们可以将上面的公式简化为:
θ ∗ = a r g m i n θ D K L ( q ∣ ∣ p ( x ; θ ) ) \theta^*=\mathop {argmin}_\theta D_{KL}(q\mid\mid p(x;\theta)) θ∗=argminθDKL(q∣∣p(x;θ))
KL散度的补充-JS散度
K L KL KL散度是非对称的,即 D K L ( q ∣ ∣ p ) D_{KL}(q\mid\mid p) DKL(q∣∣p)不一定等于 D K L ( p ∣ ∣ q ) D_{KL}(p\mid\mid q) DKL(p∣∣q)。为了解决这个问题,需要引入 J S JS JS散度。 J S JS JS散度(Jensen-Shannon divergence)的定义如下:
m = 1 2 ( p + q ) m=\frac{1}{2}(p+q) m=21(p+q)
D J S = 1 2 D K L ( p ∣ ∣ m ) + 1 2 D K L ( q ∣ ∣ m ) D_{JS}=\frac{1}{2}D_{KL}(p\mid\mid m)+\frac{1}{2}D_{KL}(q\mid\mid m) DJS=21DKL(p∣∣m)+21DKL(q∣∣m)
J S JS JS的值域是对称的,有界的,范围是 [ 0 , 1 ] [0,1] [0,1]。
如果 p , q p,\,q p,q完全相同,则 J S = 0 JS=0 JS=0,如果完全不相同,则 J S = 1 JS=1 JS=1。
注意, K L KL KL散度和 J S JS JS散度作为差异度量的时候,有一个问题:
如果两个分配 p p p, q q q离得很远,完全没有重叠的时候,那么 K L KL KL散度值是没有意义的,而 J S JS JS散度值是一个常数。这在学习算法中是比较致命的,因为这意味着在这一点的梯度为0,梯度消失了。
参考上述例子,对 J S JS JS进行反推:
D J S ( q ∣ ∣ p ) = 1 2 D K L ( q ∣ ∣ m ) + 1 2 D K L ( p ∣ ∣ m ) = 1 2 ∫ q ( x ) l o g q ( x ) q ( x ) + p ( x ; θ ) 2 d x + 1 2 ∫ p ( x ; θ ) l o g p ( x ; θ ) p ( x ; θ ) + q ( x ) 2 d x = 1 2 ∫ q ( x ) l o g 2 q ( x ) q ( x ) + p ( x ; θ ) d x + 1 2 ∫ p ( x ; θ ) l o g 2 p ( x ; θ ) p ( x ; θ ) + q ( x ) d x \begin{aligned}D_{JS}(q\mid\mid p) &=\frac{1}{2} D_{KL}(q\mid\mid m)+\frac{1}{2}D_{KL}(p\mid\mid m) \\ &=\frac{1}{2}\int q(x)log\frac{q(x)}{\frac{q(x)+p(x;\theta)}{2}}dx+\frac{1}{2}\int p(x;\theta)log\frac{p(x;\theta)}{\frac{p(x;\theta)+q(x)}{2}}dx \\ &=\frac{1}{2}\int q(x)log\frac{2q(x)}{q(x)+p(x;\theta)}dx+\frac{1}{2}\int p(x;\theta)log\frac{2p(x;\theta)}{p(x;\theta)+q(x)}dx \end{aligned} DJS(q∣∣p)=21DKL(q∣∣m)+21DKL(p∣∣m)=21∫q(x)log2q(x)+p(x;θ)q(x)dx+21∫p(x;θ)log2p(x;θ)+q(x)p(x;θ)dx=21∫q(x)logq(x)+p(x;θ)2q(x)dx+21∫p(x;θ)logp(x;θ)+q(x)2p(x;θ)dx
由于:
∫ q ( x ) l o g 2 q ( x ) q ( x ) + p ( x ; θ ) d x = ∫ q ( x ) ( l o g q ( x ) q ( x ) + p ( x ; θ ) + l o g 2 ) d x = ∫ q ( x ) l o g q ( x ) q ( x ) + p ( x ; θ ) d x + ∫ q ( x ) l o g 2 d x = ∫ q ( x ) l o g q ( x ) q ( x ) + p ( x ; θ ) d x + l o g 2 \begin{aligned}\int q(x)log\frac{2q(x)}{q(x)+p(x;\theta)}dx &=\int q(x)(log\frac{q(x)}{q(x)+p(x;\theta)}+log2)dx \\ &=\int q(x)log\frac{q(x)}{q(x)+p(x;\theta)}dx+\int q(x)log2dx \\ &=\int q(x)log\frac{q(x)}{q(x)+p(x;\theta)}dx+log2 \end{aligned} ∫q(x)logq(x)+p(x;θ)2q(x)dx=∫q(x)(logq(x)+p(x;θ)q(x)+log2)dx=∫q(x)logq(x)+p(x;θ)q(x)dx+∫q(x)log2dx=∫q(x)logq(x)+p(x;θ)q(x)dx+log2
同理可得:
D J S ( q ∣ ∣ p ) = 1 2 ∫ q ( x ) l o g q ( x ) q ( x ) + p ( x ; θ ) d x + 1 2 ∫ p ( x ; θ ) l o g p ( x ; θ ) p ( x ; θ ) + q ( x ) d x + l o g 2 \begin{aligned}D_{JS}(q\mid\mid p) &=\frac{1}{2}\int q(x)log\frac{q(x)}{q(x)+p(x;\theta)}dx+\frac{1}{2}\int p(x;\theta)log\frac{p(x;\theta)}{p(x;\theta)+q(x)}dx +log2 \end{aligned} DJS(q∣∣p)=21∫q(x)logq(x)+p(x;θ)q(x)dx+21∫p(x;θ)logp(x;θ)+q(x)p(x;θ)dx+log2
令:
d ( x ; θ ) = q ( x ) q ( x ) + p ( x ; θ ) d(x;\theta)=\frac{q(x)}{q(x)+p(x;\theta)} d(x;θ)=q(x)+p(x;θ)q(x)
则:
1 − d ( x ; θ ) = p ( x ; θ ) q ( x ) + p ( x ; θ ) 1-d(x;\theta)=\frac{p(x;\theta)}{q(x)+p(x;\theta)} 1−d(x;θ)=q(x)+p(x;θ)p(x;θ)
即:
D J S ( q ∣ ∣ p ) = 1 2 ∫ q ( x ) l o g d ( x ; θ ) d x + 1 2 ∫ p ( x ; θ ) l o g ( 1 − d ( x ; θ ) ) d x + l o g 2 D_{JS}(q\mid\mid p)=\frac{1}{2}\int q(x)log\,d(x;\theta)dx+\frac{1}{2}\int p(x;\theta)log(1-d(x;\theta))dx+log2 DJS(q∣∣p)=21∫q(x)logd(x;θ)dx+21∫p(x;θ)log(1−d(x;θ))dx+log2
令:
V ( x ; θ ) = ∫ q ( x ) l o g d ( x ; θ ) d x + ∫ p ( x ; θ ) l o g ( 1 − d ( x ; θ ) ) d x V(x;\theta)=\int q(x)log\,d(x;\theta)dx+\int p(x;\theta)log(1-d(x;\theta))dx V(x;θ)=∫q(x)logd(x;θ)dx+∫p(x;θ)log(1−d(x;θ))dx
则:
D J S ( q ∣ ∣ p ) = 1 2 V ( x ; θ ) + l o g 2 D_{JS}(q\mid\mid p)=\frac{1}{2}V(x;\theta)+log2 DJS(q∣∣p)=21V(x;θ)+log2
即:
θ ∗ = a r g m i n θ D J S ( q ∣ ∣ p ) = a r g m i n θ V ( x ; θ ) \theta^*=\mathop {argmin}_\theta D_{JS}(q\mid\mid p)=\mathop{argmin}_\theta V(x;\theta) θ∗=argminθDJS(q∣∣p)=argminθV(x;θ)
此时, θ ∗ \theta^* θ∗是令 p ( x ; θ ) p(x;\theta) p(x;θ)和 q ( x ) q(x) q(x)差异最小的参数,同样亦可通过 V ( x ; θ ) V(x;\theta) V(x;θ)求差异最大的参数。
JS散度参数求解的两步走迭代方法
从上面的讨论知道,我们需要一个参数 θ ∗ \theta^* θ∗,使得
θ ∗ = a r g m i n θ D J S ( q ∣ ∣ p ) = a r g m i n θ V ( x ; t h e t a ) \theta^*=\mathop {argmin}_\theta D_{JS}(q\mid\mid p)=\mathop {argmin}_\theta V(x;theta) θ∗=argminθDJS(q∣∣p)=argminθV(x;theta)
然而,因为涉及多重嵌套和积分,使用起来并不方便。
首先,我们假设 p ( x ; θ ) = p g ( x ) p(x;\theta)=p_g(x) p(x;θ)=pg(x)为已知条件,同时令 D = d ( x ; θ ) D=d(x;\theta) D=d(x;θ),考虑这个式子:
W ( x ; θ ) = q ( x ) l o g d ( x ; θ ) d x + p ( x ; θ ) l o g ( 1 − d ( x ; θ ) ) W(x;\theta)=q(x)log\,d(x;\theta)dx+p(x;\theta)log(1-d(x;\theta)) W(x;θ)=q(x)logd(x;θ)dx+p(x;θ)log(1−d(x;θ))
W ( x ; D ) = q ( x ) l o g D + p g ( x ) l o g ( 1 − D ) W(x;D)=q(x)log\,D+p_g(x)log(1-D) W(x;D)=q(x)logD+pg(x)log(1−D)
V ( x ; θ ) = V ( x ; D ) = ∫ W ( x ; D ) d x V(x;\theta)=V(x;D)=\int W(x;D)dx V(x;θ)=V(x;D)=∫W(x;D)dx
在 x x x已知的情况下,我们关注 D D D。
W ′ = d W d D = q ( x ) 1 D − p g ( x ) 1 1 − D W'=\frac{dW}{dD}=q(x)\frac{1}{D}-p_g(x)\frac{1}{1-D} W′=dDdW=q(x)D1−pg(x)1−D1
W ′ ′ = d W ′ d D = − q ( x ) 1 D 2 − p g ( x ) 1 ( 1 − D ) 2 W''=\frac{dW'}{dD}=-q(x)\frac{1}{D^2}-p_g(x)\frac{1}{(1-D)^2} W′′=dDdW′=−q(x)D21−pg(x)(1−D)21
因为 W ′ ′ < 0 W''\lt0 W′′<0,当 W ′ = 0 W'=0 W′=0时, W W W取得极大值:
W ′ = q ( x ) 1 D − p g ( x ) 1 1 − D = 0 W'=q(x)\frac{1}{D}-p_g(x)\frac{1}{1-D}=0 W′=q(x)D1−pg(x)1−D1=0
D = q ( x ) q ( x ) + p g ( x ) D=\frac{q(x)}{q(x)+p_g(x)} D=q(x)+pg(x)q(x)
因为:
D < q ( x ) q ( x ) + p g ( x ) , W ′ > 0 D\lt\frac{q(x)}{q(x)+p_g(x)},\, W'\gt0 D<q(x)+pg(x)q(x),W′>0
D > q ( x ) q ( x ) + p g ( x ) , W ′ < 0 D\gt\frac{q(x)}{q(x)+p_g(x)},\,W'\lt0 D>q(x)+pg(x)q(x),W′<0
这表明,当 D D D的函数按 W ′ = 0 W'=0 W′=0取值时, W W W在 x x x的每个取样点均获得最大值,积分后的面积获得最大值,即:
D ∗ = q ( x ) q ( x ) + p g ( x ) = a r g m a x D ∫ W ( x ; D ) d x = a r g m a x D V ( x ; D ) D^*=\frac{q(x)}{q(x)+p_g(x)}=\mathop {argmax}_D\int W(x;D)dx=\mathop {argmax}_DV(x;D) D∗=q(x)+pg(x)q(x)=argmaxD∫W(x;D)dx=argmaxDV(x;D)
m a x D V ( x ; D ) = ∫ q ( x ) l o g D ∗ ( x ) d x + ∫ p g ( x ) l o g ( 1 − D ∗ ( x ) ) d x \mathop {max}_DV(x;D)=\int q(x)log\,D^*(x)dx+\int p_g(x)log(1-D^*(x))dx maxDV(x;D)=∫q(x)logD∗(x)dx+∫pg(x)log(1−D∗(x))dx
在得到 V ( x ; D ) V(x;D) V(x;D)的最大值表达式后,我们固定 D ∗ D^* D∗,接着对 p ( x ; θ ) = p g ( x ) p(x;\theta)=p_g(x) p(x;θ)=pg(x)将这个最大值按最小方向优化:
V ( x ; θ ; D ∗ ) = ∫ q ( x ) l o g D ∗ ( x ) d x + ∫ p ( x ; θ ) l o g ( 1 − D ∗ ( x ) ) d x V(x;\theta;D^*)=\int q(x)log\,D^*(x)dx+\int p(x;\theta)log(1-D^*(x))dx V(x;θ;D∗)=∫q(x)logD∗(x)dx+∫p(x;θ)log(1−D∗(x))dx
θ ∗ = a r g m i n θ V ( x ; θ ∗ ; D ∗ ) \theta^*=\mathop {argmin}_\theta V(x;\theta^*;D^*) θ∗=argminθV(x;θ∗;D∗)
因此,通过两步走的方法,经过多次先后迭代求解 D ∗ D^* D∗和 θ ∗ \theta^* θ∗,我们可以逐渐得到一个趋近于 q ( x ) q(x) q(x)的 p ( x ; θ ∗ ) p(x;\theta^*) p(x;θ∗)。
生成对抗网络
从上述的讨论可知,我们可以得到一个和 q ( x ) q(x) q(x)非常接近的分布函数 p ( x ; θ ) p(x;\theta) p(x;θ)。这个分布函数的构建是为了寻找已知样本数据的内在规律。
然后我们往往并不关心这个分布函数,我们希望无中生有的构建一批数据 x ′ x' x′,使得 p ( x ′ ; θ ) p(x';\theta) p(x′;θ)趋近于 q ( x ) q(x) q(x)。
我们设计一个输出 x ′ x' x′的生成器 x ′ = G ( z ; β ) x'=G(z;\beta) x′=G(z;β),从随机概率分布中接收 z z z作为输入, x ′ x' x′的概率分布为 p g ( x ′ ) p_g(x') pg(x′)。
第一步,我们固定 p g ( x ′ ) p_g(x') pg(x′),求 D ∗ D^* D∗:
V ( x , x ′ ; D ) = ∫ q ( x ) l o g D ( x ) d x + ∫ p g ( x ′ ) l o g ( 1 − D ( x ′ ) ) d x V(x,x';D)=\int q(x)log\,D(x)dx+\int p_g(x')log(1-D(x'))dx V(x,x′;D)=∫q(x)logD(x)dx+∫pg(x′)log(1−D(x′))dx
D ∗ = a r g m a x D V ( x ; D ) D^*=\mathop {argmax}_DV(x;D) D∗=argmaxDV(x;D)
第二步,我们固定 D ∗ D* D∗,求 p g ( x ′ ; θ ∗ ) p_g(x';\theta^*) pg(x′;θ∗):
V ( x , x ′ , D ∗ ; θ ) = ∫ q ( x ) l o g D ∗ ( x ) d x + ∫ p g ( x ′ ; θ ) l o g ( 1 − D ∗ ( x ′ ) ) d x V(x,x',D^*;\theta)=\int q(x)log\,D^*(x)dx+\int p_g(x';\theta)log(1-D^*(x'))dx V(x,x′,D∗;θ)=∫q(x)logD∗(x)dx+∫pg(x′;θ)log(1−D∗(x′))dx
θ ∗ = a r g m i n θ V ( x , D ∗ ; θ ∗ ) \theta^*=\mathop {argmin}_\theta V(x,D^*;\theta^*) θ∗=argminθV(x,D∗;θ∗)
然后进行多次循环迭代,使得 p g ( x ′ ; θ ∗ ) p_g(x';\theta^*) pg(x′;θ∗)趋近于 q ( x ) q(x) q(x)。
仔细观察可以发现,这里求解过程和上例的是一样,只是输入的数据不一致。
在实际任务中,我们并不关心 p g ( x ′ ; θ ) p_g(x';\theta) pg(x′;θ),仅关注生成器 x ′ = G ( z ; β ) x'=G(z;\beta) x′=G(z;β)的优化。
因此,我们把算法改编如下:
第一步,我们固定 x ′ = G ( z ; β ) x'=G(z;\beta) x′=G(z;β),求 D ∗ D^* D∗:
V ( x , z ; D ) = ∫ q ( x ) l o g D ( x ) d x + ∫ q ( z ) l o g ( 1 − D ( G ( z ) ) ) d z V(x,z;D)=\int q(x)log\,D(x)dx+\int q(z)log(1-D(G(z)))dz V(x,z;D)=∫q(x)logD(x)dx+∫q(z)log(1−D(G(z)))dz
D ∗ = a r g m a x D V ( x , z ; D ) D^*=\mathop {argmax}_DV(x,z;D) D∗=argmaxDV(x,z;D)
第二步,我们固定 D ∗ D* D∗,求 G ( z ; β ∗ ) G(z;\beta^*) G(z;β∗):
V ( x , z , D ∗ ; β ) = ∫ q ( x ) l o g D ∗ ( x ) d x + ∫ q ( z ) l o g ( 1 − D ∗ ( G ( z ; β ) ) ) d z V(x,z,D^*;\beta)=\int q(x)log\,D^*(x)dx+\int q(z)log(1-D^*(G(z;\beta)))dz V(x,z,D∗;β)=∫q(x)logD∗(x)dx+∫q(z)log(1−D∗(G(z;β)))dz
β ∗ = a r g m i n β V ( x , z , D ∗ ; β ∗ ) \beta^*=\mathop {argmin}_\beta V(x,z,D^*;\beta^*) β∗=argminβV(x,z,D∗;β∗)
注意,本例的两个算法都没有给出严格的收敛证明。
由于求解形式和上例的 J S JS JS散度的参数求解算法非常的一致,我们可以期待这种算法能够起作用。为简单起见,记为:
V ( G , D ) = ∫ q ( x ) l o g D ( x ) d x + ∫ q ( z ) l o g ( 1 − D ( G ( z ) ) ) d z V(G,D)=\int q(x)log\,D(x)dx+\int q(z)log(1-D(G(z)))dz V(G,D)=∫q(x)logD(x)dx+∫q(z)log(1−D(G(z)))dz
G ∗ = a r g m i n G ( m a x D V ( G , D ) ) G^*=\mathop {argmin}_G(max_D V(G,D)) G∗=argminG(maxDV(G,D))
这就是 G A N GAN GAN生成对抗网络相关文献中常见的求解表达方式。
在 Ian J. Goodfellow 的论文 Generative Adversarial Networks 中, 作者先给出了 V ( G , D ) V(G,D) V(G,D)的表达式, 然后再通过 J S JS JS散度的理论来证明其收敛性. 有兴趣的读者可以参考阅读。
本文认为, 如果先介绍 J S JS JS散度, 再进行反推, 可以更容易的理解 G A N GAN GAN概念, 理解 G A N GAN GAN为什么要用这么复杂的损失函数.
生成对抗网络的工程实践
在工程实践中,我们遇到的一般是离散的数据,我们可以使用随机采样的方法逼近期望值。
首先我们从前置的随机分布 p z ( z ) p_z(z) pz(z)中取出 m m m个随机数 z = ( z 1 , z 2 , z 3 , ⋯ , z m ) z=(z_1,z_2,z_3,\cdots,z_m) z=(z1,z2,z3,⋯,zm), 其次我们在从真实数据分布 p ( x ) p(x) p(x)中取出 m m m个真实样本 p = ( x 1 , x 2 , x 3 , ⋯ , x m ) p=(x_1,x_2,x_3,\cdots,x_m) p=(x1,x2,x3,⋯,xm)。
由于我们的数据是随机选取的,概率越大就越有机会被选中。抽取的样本就隐含了自身的期望。因此我们可以使用平均数代替上式中的期望,公式改写如下:
V ( G , D ) = ∫ q ( x ) l o g D ( x ) d x + ∫ q ( z ) l o g ( 1 − D ( G ( z ) ) ) d z = 1 m Σ i = 1 m l o g D ( x i ) + 1 m Σ i = 1 m l o g ( 1 − D ( G ( z i ) ) ) \begin{aligned}V(G,D) &=\int q(x)log\,D(x)dx+\int q(z)log(1-D(G(z)))dz \\ &=\frac{1}{m}\Sigma_{i=1}^m log\,D(x_i)+\frac{1}{m}\Sigma_{i=1}^m log(1-D(G(z_i))) \end{aligned} V(G,D)=∫q(x)logD(x)dx+∫q(z)log(1−D(G(z)))dz=m1Σi=1mlogD(xi)+m1Σi=1mlog(1−D(G(zi)))
我们可以直接用上式训练鉴别器 D ( x ) D(x) D(x)。
在训练生成器时,因为前半部分和 z z z无关,我们可以只使用后半部分。
最后,我们用一张图来结束(总结这一部分),从数学的角度看GANs的训练过程:
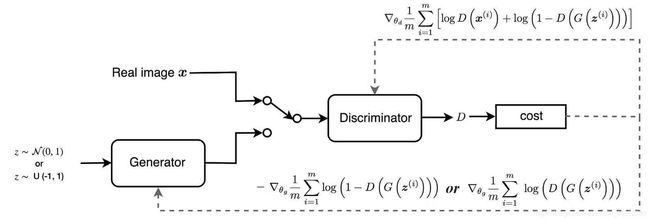
------------------------------------------------------------高能结束分割线------------------------------------------------------------------------------
1.2.2 重说GAN原理
真的,前面的数学原理实在是太枯燥了,编写的过程中多次想放弃,但是正值疫情期间,我的状态是这样的:

你说不得找点事干是不是,于是乎,。。。,就有了上面那一段,不管怎么样,忘了刚才这一段吧,让我们重新开始~

大白话GANs原理
知乎上有一个很好的解释:
假设一个城市治安混乱,很快,这个城市里就会出现无数的小偷。在这些小偷中,有的可能是盗窃高手,有的可能毫无技术可言。假如这个城市开始整饬其治安,突然开展一场打击犯罪的「运动」,警察们开始恢复城市中的巡逻,很快,一批「学艺不精」的小偷就被捉住了。之所以捉住的是那些没有技术含量的小偷,是因为警察们的技术也不行了,在捉住一批低端小偷后,城市的治安水平变得怎样倒还不好说,但很明显,城市里小偷们的平均水平已经大大提高了。

警察们开始继续训练自己的破案技术,开始抓住那些越来越狡猾的小偷。随着这些职业惯犯们的落网,警察们也练就了特别的本事,他们能很快能从一群人中发现可疑人员,于是上前盘查,并最终逮捕嫌犯;小偷们的日子也不好过了,因为警察们的水平大大提高,如果还想以前那样表现得鬼鬼祟祟,那么很快就会被警察捉住。

为了避免被捕,小偷们努力表现得不那么「可疑」,而魔高一尺、道高一丈,警察也在不断提高自己的水平,争取将小偷和无辜的普通群众区分开。随着警察和小偷之间的这种「交流」与「切磋」,小偷们都变得非常谨慎,他们有着极高的偷窃技巧,表现得跟普通群众一模一样,而警察们都练就了「火眼金睛」,一旦发现可疑人员,就能马上发现并及时控制——最终,我们同时得到了最强的小偷和最强的警察。

大白话GANs训练过程
类比上面的过程,生成对抗网络(GANs)由2个重要的部分构成:
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”

下面详细介绍一下过程:
第一阶段:固定「判别器D」,训练「生成器G」
我们使用一个还 OK 判别器,让一个「生成器G」不断生成“假数据”,然后给这个「判别器D」去判断。
一开始,「生成器G」还很弱,所以很容易被揪出来。
但是随着不断的训练,「生成器G」技能不断提升,最终骗过了「判别器D」。
到了这个时候,「判别器D」基本属于瞎猜的状态,判断是否为假数据的概率为50%。

第二阶段:固定「生成器G」,训练「判别器D」
当通过了第一阶段,继续训练「生成器G」就没有意义了。这个时候我们固定「生成器G」,然后开始训练「判别器D」。
「判别器D」通过不断训练,提高了自己的鉴别能力,最终他可以准确的判断出所有的假图片。
到了这个时候,「生成器G」已经无法骗过「判别器D」。

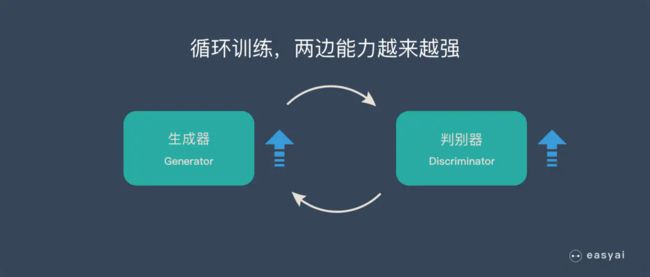
循环阶段一和阶段二
通过不断的循环,「生成器G」和「判别器D」的能力都越来越强。
最终我们得到了一个效果非常好的「生成器G」,我们就可以用它来生成我们想要的图片了。
下面的实际应用部分会展示很多“惊艳”的案例。
1.2.3 小结
从这个过程来看,GANs有什么优缺点呢?
三个优势:
- 能更好建模数据分布(图像更锐利、清晰)
- 理论上,GANs 能训练任何一种生成器网络。其他的框架需要生成器网络有一些特定的函数形式,比如输出层是高斯的。
- 无需利用马尔科夫链反复采样,无需在学习过程中进行推断,没有复杂的变分下界,避开近似计算棘手的概率的难题。
两个缺陷:
- 难训练,不稳定。生成器和判别器之间需要很好的同步,但是在实际训练中很容易D收敛,G发散。D/G 的训练需要精心的设计。
- 模式缺失(Mode Collapse)问题。GANs的学习过程可能出现模式缺失,生成器开始退化,总是生成同样的样本点,无法继续学习。
1.3 GANs应用举例
1.3.1 从生成MNIST开始
让我们用MNIST手写数字数据集探索一个具体的例子,以进一步描述上面的过程,Mnist数据如下图所示:

我们从如下结构网络生成手写数字:

GAN步骤:
- 开始时期生成器接收随机数并返回图像;
- 将生成的图像与实际图像流一起反馈给判别器;
- 鉴别器对假图像和真实图像进行判别并返回概率;
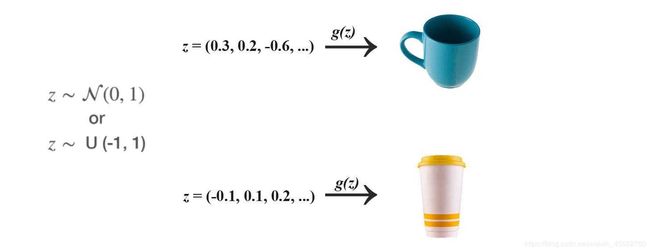
GAN过程中,开始时期从随机数开始,例如:
注:可能刚开始生成的图像很糟糕,但是经过鉴别器把关,不停的迭代,会得到一个不错的结果。
1.3.2 垃圾邮件识别
再来看一个知乎上(@陈琛)的一个例子:垃圾邮件分类。
不知道大家有印象没,垃圾邮件识别,我们在最开始的教程里也有提到过,现在从另一个角度再来看看。
假设有一个叫Gary的营销人员试图骗过David的垃圾邮件分类器来发送垃圾邮件。Gary希望能尽可能地发送多的垃圾邮件,David希望尽可能少的垃圾邮件通过。理想情况下会达到纳什均衡,尽管我们谁都不想收到垃圾邮件。
想了解纳什均衡,可以参看这篇博客。
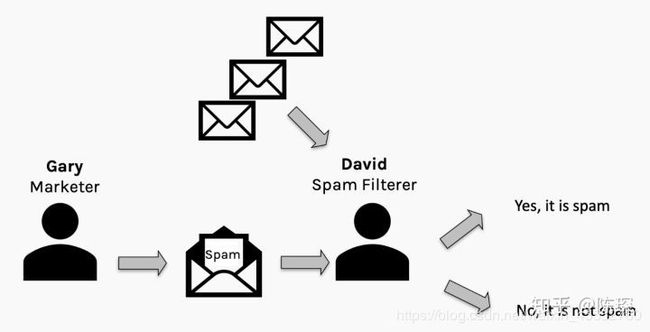
在收到邮件后,David可以查看spam filter的效果并通过”误报”或”漏报”来惩罚spam filter。

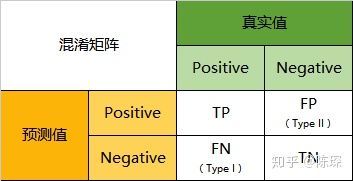
假设Gary通过自己发送给自己可以验证他的垃圾邮件哪些通过了,那么Gary和David就可以通过混淆矩阵(confusion matrix,名字听起来高大上,其实就是个表格而已)来评价自己的工作做的如何:
下面是Gary和David得到的混淆矩阵:
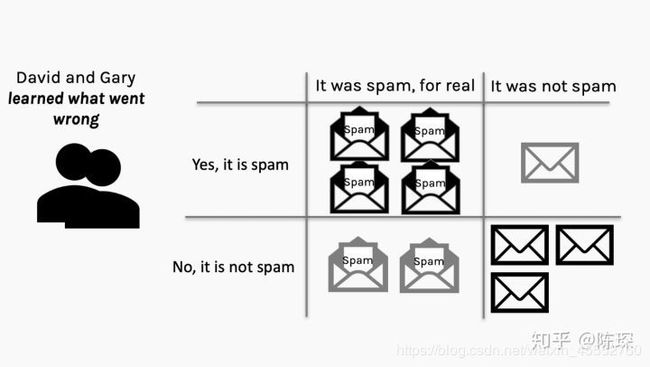
经此之后,Gary和David都知道出了什么问题,并从错误中学习。Gary会基于之前的成功经验尝试其他的方法来生成更好的垃圾邮件。David会看一下spam filter哪里出错了并改进过滤机制。

然后不断地重复这个过程,直到达到某种纳什均衡(当然,有可能最终导致模型崩溃,因为某一方找到了完美的伪装方法或者分辨垃圾邮件的方法)。
下面来详细看一下混淆矩阵的四个象限:
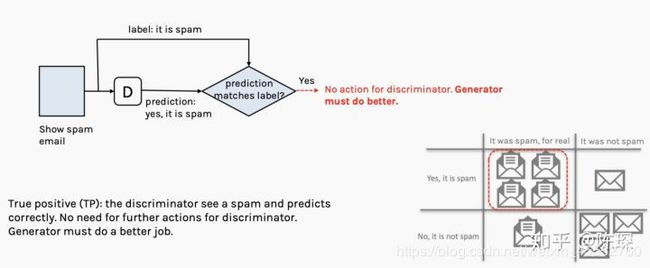
- True Positive:邮件是Gary生成的垃圾邮件并且被David判定为垃圾邮件。
generator:被抓包,工作做的不够好,需要优化。
discriminator:当前不需要做什么。
- False Negative:邮件不是垃圾邮件,但是被David判定为垃圾邮件。
generator:当前不需要做什么。
discriminator:工作做的不够好,需要优化。
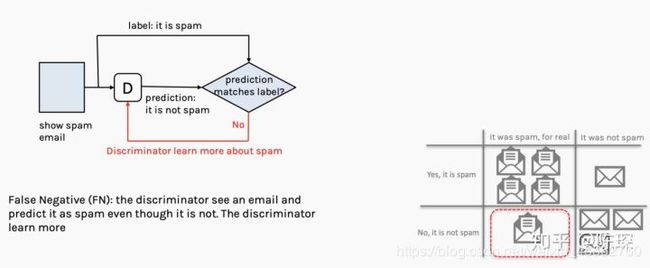
- False Positive:邮件是垃圾邮件,但是被David判定为正常邮件。
generator:当前不需要做什么。
discriminator:工作做的不够好,需要优化。

- True Negative:邮件不是垃圾邮件,David也判定是正常邮件。
generator:当前不需要做什么。
discriminator:当前不需要做什么。

基于上面讨论,图示Network如何训练的:

训练的步骤包括:
-
取batch的训练集x,和随机生成noise z;
-
计算loss;
-
使用back propagation更新generator和discriminator;
我们已经分析好了,在True Positive,False Negative,False Positive情况下需要更新:
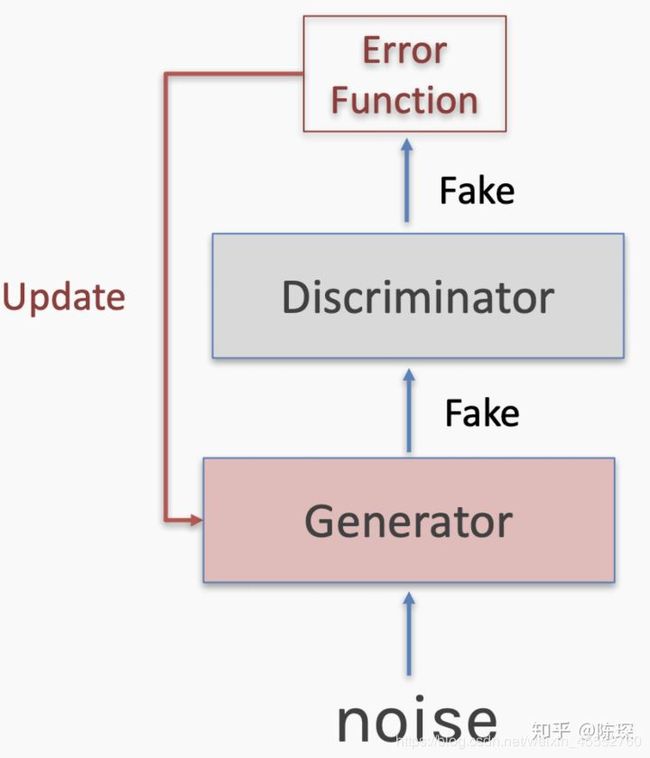
**True Positive:**意味着generator生成的fake数据被抓包,需要对generator进行优化。需要经过参数被固定的discriminator计算loss,更新generator的权重。注意一次只能对两个网络中的一个进行参数调整。
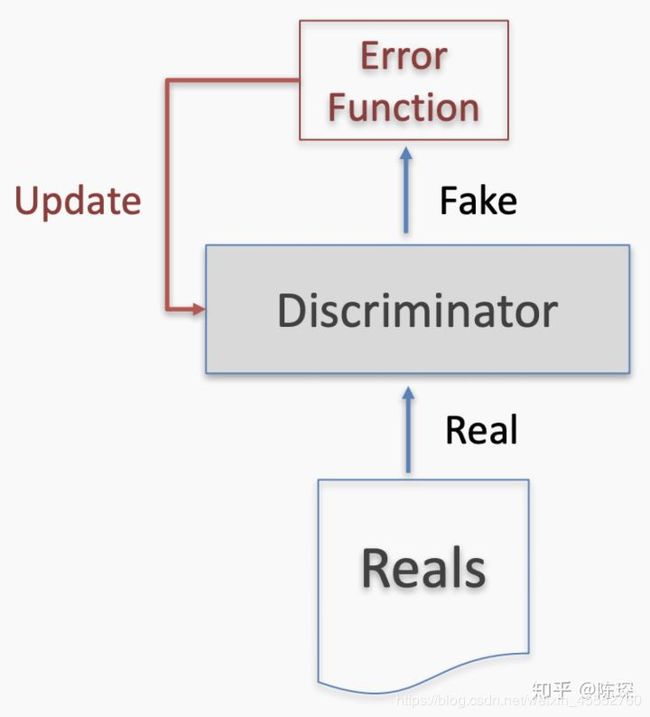
**False Negative:**意味着真的训练集被discriminator错认为fake数据。只更新discriminator的权重。
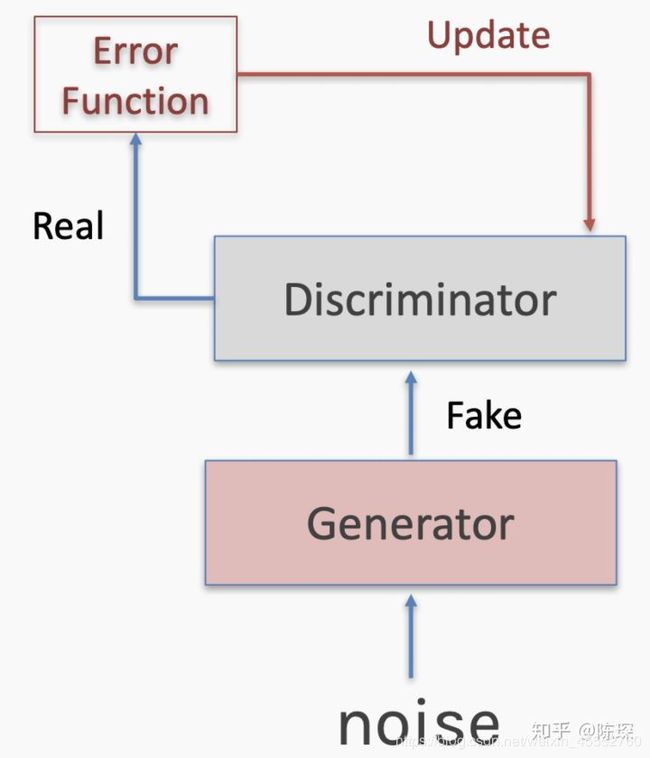
**False Positive:**generator生成的fake数据,被discriminator判定为真的训练集。只对discriminator进行更新。
如何结合上前一节介绍的数学原理?
现在让我们用更数学的角度来解释一下:
我们有一个已知的real的分布,generator生成了一个fake的分布。因为这个两个分布不完全相同,所以他们之间存在KL-divergence,也就是损失函数不为0。
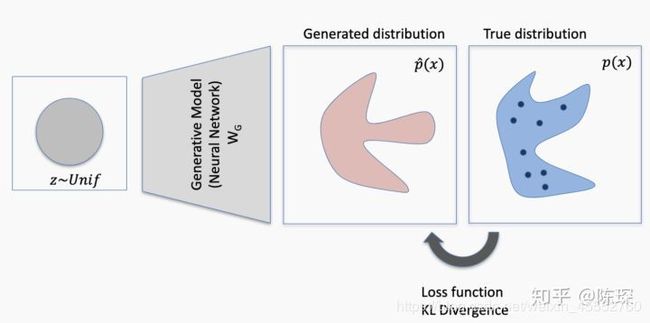
discriminator同时看到real的分布和fake的分布。如果discriminator能分清楚来自generator生成的与来自real分布的,就会生成loss并反向传播更新generator的权重。

generator更新完成后,生成的fake数据更符合real的分布。
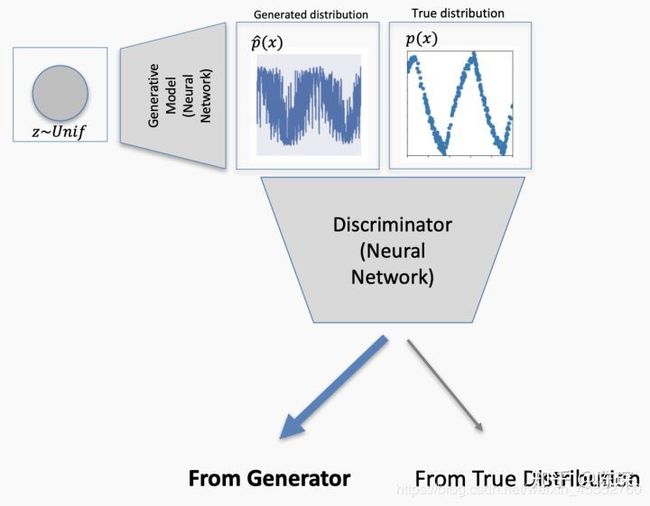
但是如果生成的data仍然不够接近real的分布,discriminator依然能识别出来了,因此再次对generator进行权重更新。
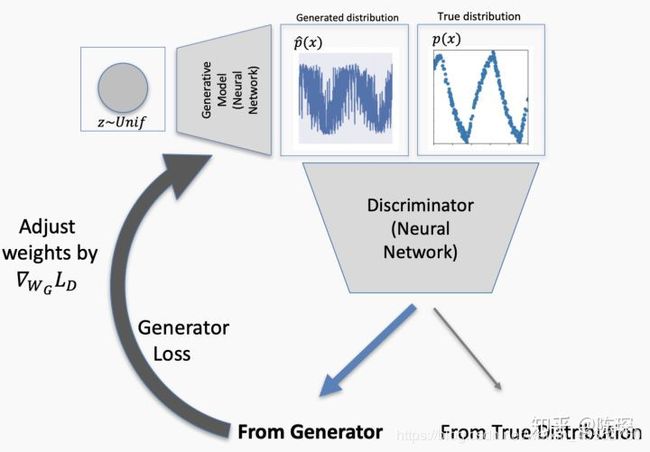
终于这次discriminator被骗过了,它认为generator生成的fake数据就是符合real分布的。这个就对应False Positive的情况,需要对discriminator进行更新。
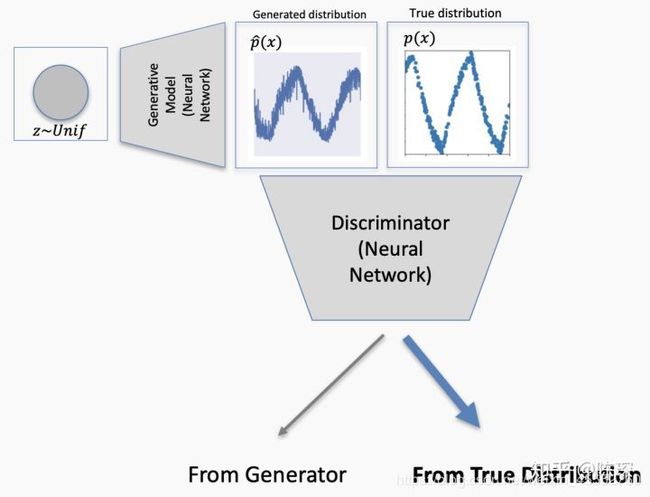
Loss反向传播来更新discriminator的权重。

继续这个过程,直到generator生成的分布与real分布无法区分时,网络达到纳什均衡。
1.3.3 更多实际应用
(Conditional) Synthesis—条件生成
最好玩的比如Text2Image、Image2Text。可以基于一段文字生成一张图片,比如这个Multi-Condition GAN(MA-GAN)的text-to-image的例子:

Data Augmentation—数据增强
GAN学习训练集样本的分布,然后进行采样生成新的样本,我们可以使用这些样本来增强训练集。一般我们都是通过对原训练集的图片进行旋转和扭曲来进行增强,这里GAN提供了一种新的方法。
Style Transfer和Manipulation-风格转换
将一张图片的style转移到另外一张图像上,这与neural style transfer非常类似。Neural Style Transfer可以认为是把Style Image的风格加入到Content Image里。因为只有一张Style Image,所以它其实学到的很难完全是Style的特征,因为一个画家的风格很难通过一幅作品就展现出来。GAN能够很好的从多个作品中学习到画家的真正风格特征。
第2/3列为neural style transfer的效果,第5列为cycleGAN:

可以看出对背景特别有效,比如对云的转换等:

GAN在动物和水果上的效果:

四季变换:

改变照片的景深:

对线稿填充变成真实的物体:

可以利用风格转换来渲染图像,变成游戏GTA风格的:

将白天变夜晚:

style transfer可以具体见这个survey。
Image Super-Resolution
即将图像从低分辨率LR恢复到高分辨率HR:

1.3.4 小结
更多应用,可参见这篇博客。
最后,如果你想了解更多关于GANs发展史及现有的流行模型,可参看这篇博文:生成对抗网络(GAN)的发展史。
声明
本博客所有内容仅供学习,不为商用,如有侵权,请联系博主谢谢。
参考文献
[1] GANs数学原理:https://zhuanlan.zhihu.com/p/54096381
[2] GANs数学原理:https://blog.csdn.net/oBrightLamp/article/details/86553074
[3] GANs原理:https://www.jianshu.com/p/bc781ac06c62
[4] 邮件识别:https://www.zhihu.com/question/63493495
[5] 更多应用:https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/